
darknet训练图像分类优化器研究
图像分类流程:函数forward_backward_network_gpu();
·
目录
update_network_gpu(network net):
更多见darknet学习笔记
优化方法
优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
深度学习面试题03:改进版梯度下降法Adagrad、RMSprop、Momentum、Adam
深度学习面试题04:随机梯度下降法、批量梯度下降法、小批量梯度下降
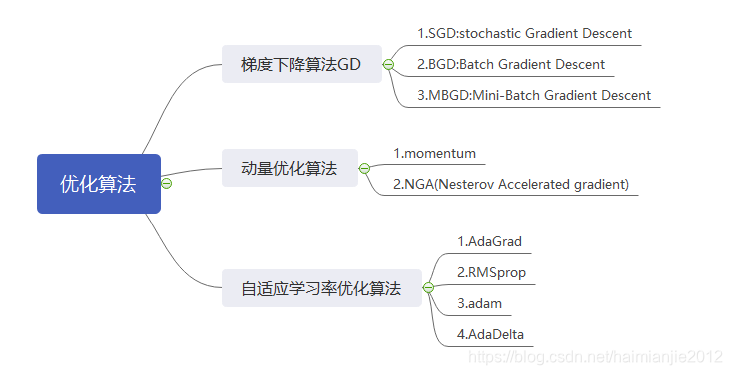
优化方法与参数更新的关系:
优化方法就是通过迭代的方式计算损失函数的最小值,而迭代的过程就是参数更新的过程。
为什么优化器不同准确率不同?
训练图像分类流程
训练图像分类流程:
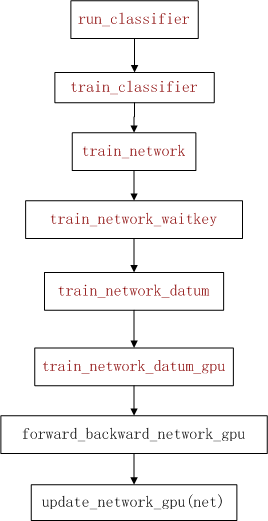
函数forward_backward_network_gpu();

update_network_gpu(network net):
void update_network_gpu(network net)
{
cuda_set_device(net.gpu_index);
int i;
int update_batch = net.batch*net.subdivisions * get_sequence_value(net);
float rate = get_current_rate(net);
for(i = 0; i < net.n; ++i){
layer l = net.layers[i];
l.t = get_current_batch(net);
if(l.update_gpu){
l.update_gpu(l, update_batch, rate, net.momentum, net.decay);
}
}
}update_gpu()
update_gpu是一个函数指针,不同情形下指向不同的函数:
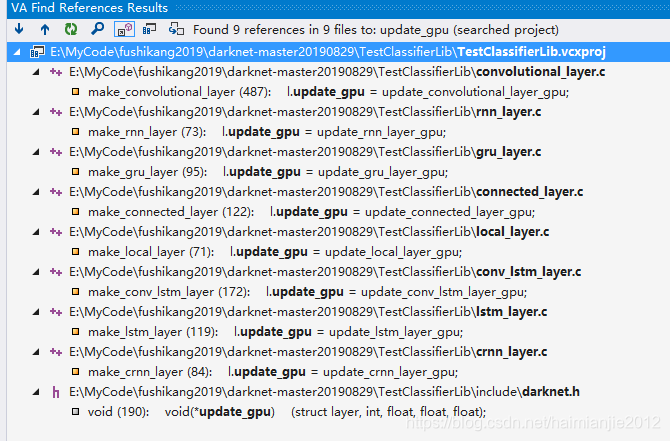
卷积层的参数更新函数,update_convolutional_layer_gpu():
void update_convolutional_layer_gpu(layer l, int batch, float learning_rate_init, float momentum, float decay)
{
float learning_rate = learning_rate_init*l.learning_rate_scale;
fix_nan_and_inf(l.weight_updates_gpu, l.nweights);
fix_nan_and_inf(l.weights_gpu, l.nweights);
if (l.adam) {
adam_update_gpu(l.weights_gpu, l.weight_updates_gpu, l.m_gpu, l.v_gpu, l.B1, l.B2, l.eps, decay, learning_rate, l.nweights, batch, l.t);
adam_update_gpu(l.biases_gpu, l.bias_updates_gpu, l.bias_m_gpu, l.bias_v_gpu, l.B1, l.B2, l.eps, decay, learning_rate, l.n, batch, l.t);
if (l.scales_gpu) {
adam_update_gpu(l.scales_gpu, l.scale_updates_gpu, l.scale_m_gpu, l.scale_v_gpu, l.B1, l.B2, l.eps, decay, learning_rate, l.n, batch, l.t);
}
}
else {
axpy_ongpu(l.nweights, -decay*batch, l.weights_gpu, 1, l.weight_updates_gpu, 1);
axpy_ongpu(l.nweights, learning_rate / batch, l.weight_updates_gpu, 1, l.weights_gpu, 1);
scal_ongpu(l.nweights, momentum, l.weight_updates_gpu, 1);
axpy_ongpu(l.n, learning_rate / batch, l.bias_updates_gpu, 1, l.biases_gpu, 1);
scal_ongpu(l.n, momentum, l.bias_updates_gpu, 1);
if (l.scales_gpu) {
axpy_ongpu(l.n, learning_rate / batch, l.scale_updates_gpu, 1, l.scales_gpu, 1);
scal_ongpu(l.n, momentum, l.scale_updates_gpu, 1);
}
}
}参数更新分两条路走:如果l.adam为真,采用adam更新;否则采用其他方法更新。
net->adam = option_find_int_quiet(options, "adam", 0);
if(net->adam){
net->B1 = option_find_float(options, "B1", .9);
net->B2 = option_find_float(options, "B2", .999);
net->eps = option_find_float(options, "eps", .000001);
}分支1adam:
adam_update_gpu
extern "C" void adam_update_gpu(float *w, float *d, float *m, float *v, float B1, float B2, float eps, float decay, float rate, int n, int batch, int t)
{
scal_ongpu(n, B1, m, 1);
scal_ongpu(n, B2, v, 1);
axpy_ongpu(n, -decay*batch, w, 1, d, 1);
axpy_ongpu(n, (1 - B1), d, 1, m, 1);
mul_ongpu(n, d, 1, d, 1);
axpy_ongpu(n, (1 - B2), d, 1, v, 1);
adam_gpu(n, w, m, v, B1, B2, rate, eps, t);
fill_ongpu(n, 0, d, 1);
CHECK_CUDA(cudaPeekAtLastError());
}
extern "C" void mul_ongpu(int N, float * X, int INCX, float * Y, int INCY)
{
mul_kernel<<<cuda_gridsize(N), BLOCK, 0, get_cuda_stream() >>>(N, X, INCX, Y, INCY);
CHECK_CUDA(cudaPeekAtLastError());
}
__global__ void mul_kernel(int N, float *X, int INCX, float *Y, int INCY)
{
int i = (blockIdx.x + blockIdx.y*gridDim.x) * blockDim.x + threadIdx.x;
if(i < N) Y[i*INCY] *= X[i*INCX];
}
extern "C" void fill_ongpu(int N, float ALPHA, float * X, int INCX)
{
fill_kernel<<<cuda_gridsize(N), BLOCK, 0, get_cuda_stream()>>>(N, ALPHA, X, INCX);
CHECK_CUDA(cudaPeekAtLastError());
}__global__ void fill_kernel(int N, float ALPHA, float *X, int INCX)
{
int i = (blockIdx.x + blockIdx.y*gridDim.x) * blockDim.x + threadIdx.x;
if(i < N) X[i*INCX] = ALPHA;
}
分支2:
因为resnet34.txt中没有adam,B1,B2,eps等参数,所以基于resnet训练采axpy_ongpu()方法更新。下面是resnet34.txt模型优化参数的代码段:
axpy_ongpu(l.nweights, -decay*batch, l.weights_gpu, 1, l.weight_updates_gpu, 1);
axpy_ongpu(l.nweights, learning_rate / batch, l.weight_updates_gpu, 1, l.weights_gpu, 1);
scal_ongpu(l.nweights, momentum, l.weight_updates_gpu, 1);
axpy_ongpu(l.n, learning_rate / batch, l.bias_updates_gpu, 1, l.biases_gpu, 1);
scal_ongpu(l.n, momentum, l.bias_updates_gpu, 1);
if (l.scales_gpu) {
axpy_ongpu(l.n, learning_rate / batch, l.scale_updates_gpu, 1, l.scales_gpu, 1);
scal_ongpu(l.n, momentum, l.scale_updates_gpu, 1);
}axpy_ongpu()
extern "C" void axpy_ongpu(int N, float ALPHA, float * X, int INCX, float * Y, int INCY)
{
axpy_ongpu_offset(N, ALPHA, X, 0, INCX, Y, 0, INCY);
}
extern "C" void axpy_ongpu_offset(int N, float ALPHA, float * X, int OFFX, int INCX, float * Y, int OFFY, int INCY)
{
axpy_kernel<<<cuda_gridsize(N), BLOCK, 0, get_cuda_stream()>>>(N, ALPHA, X, OFFX, INCX, Y, OFFY, INCY);
CHECK_CUDA(cudaPeekAtLastError());
}其核心代码为:
axpy_kernel<<<cuda_gridsize(N), BLOCK, 0, get_cuda_stream()>>>(N, ALPHA, X, OFFX, INCX, Y, OFFY, INCY);axpy_kernel()实现:
__global__ void axpy_kernel(int N, float ALPHA, float *X, int OFFX, int INCX, float *Y, int OFFY, int INCY)
{
int i = (blockIdx.x + blockIdx.y*gridDim.x) * blockDim.x + threadIdx.x;
if(i < N) Y[OFFY+i*INCY] += ALPHA*X[OFFX+i*INCX];
}scal_ongpu()
extern "C" void scal_ongpu(int N, float ALPHA, float * X, int INCX)
{
scal_kernel<<<cuda_gridsize(N), BLOCK, 0, get_cuda_stream()>>>(N, ALPHA, X, INCX);
CHECK_CUDA(cudaPeekAtLastError());
}scal_kernel()
__global__ void scal_kernel(int N, float ALPHA, float *X, int INCX)
{
int i = (blockIdx.x + blockIdx.y*gridDim.x) * blockDim.x + threadIdx.x;
if(i < N) X[i*INCX] *= ALPHA;
}

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 0
0 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)