
【pytorch】2.3 神经网络核心组件与结构(举例: MNIST 手写数字识别)
MNIST 手写数字识别
·
一、神经网络核心组件与结构
神经网络核心组件包括:
- 层:神经网络的基本结构,将输入张量转换为输出张量。
- 模型:层构成的网络
- 损失函数:参数学习的目标函数,通过最小化损失函数来学习各种参数
- 优化器:如何使损失函数最小,这就涉及优化器
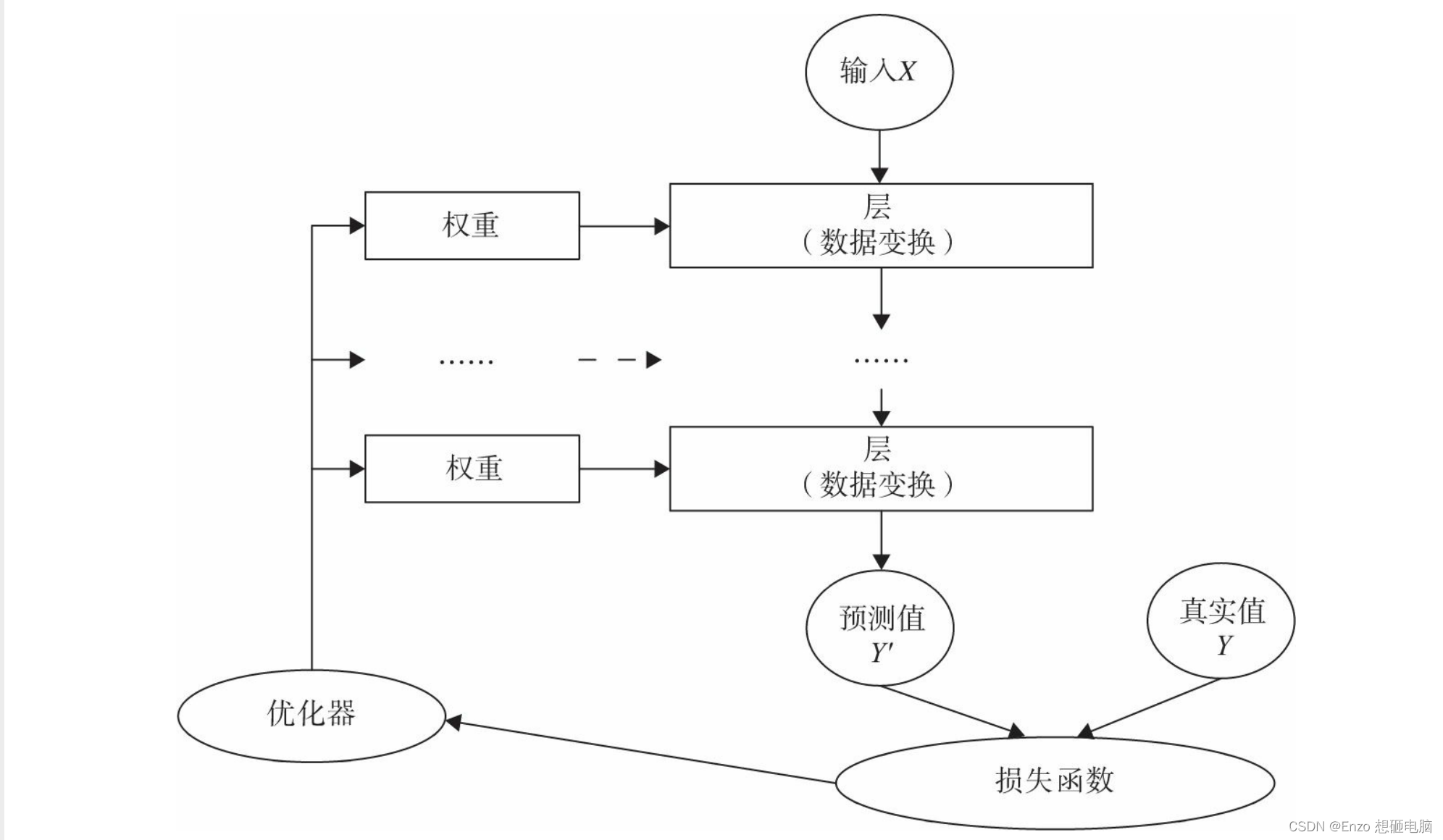
使用PyTorch构建神经网络使用的主要工具(或类)及相互关系,如下图: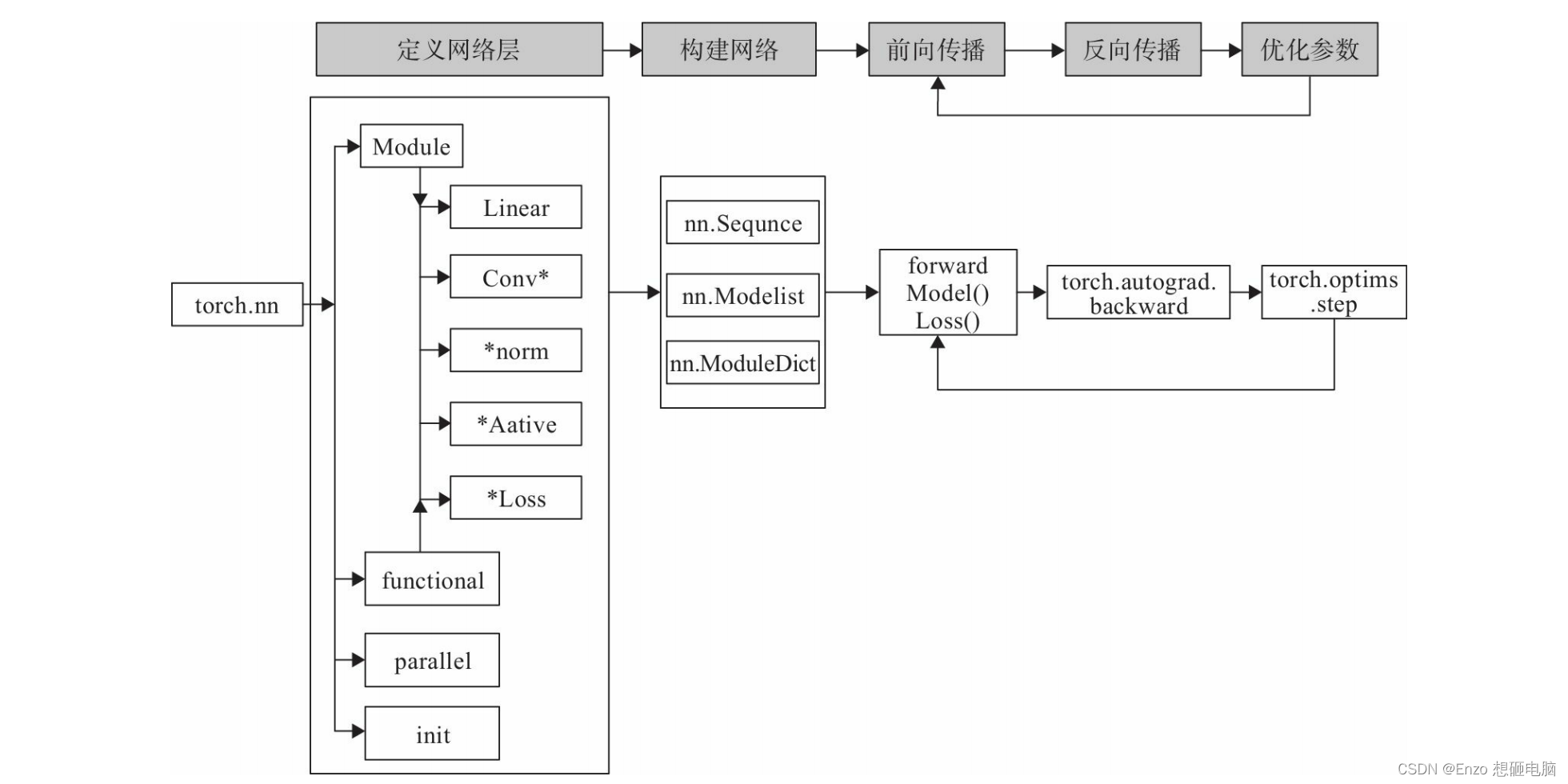
由上图可知:
1)构建网络层可以基于Module类或函数(nn.functional)
- Module类
torch.nn.Module和 functional函数torch.nn.functional)都是 torch.nn 模块下的 - nn 中的大多数层(Layer)在functional中都有与之对应的函数
2)nn.functional 中函数 与 nn.Module中的Layer的主要区别是后者继承Module类,会自动提取可学习的参数。而nn.functional更像是纯函数。两者功能相同,且性能也没有很大区别,那么如何选择呢?
- 像卷积层、全连接 层、Dropout层等因含有可学习参数,一般使用nn.Module
- 激活函数、池化层不含可学习参数,可以使用nn.functional中对应的函数
二、构建网络模型实例 - MNIST 手写数字识别
下面通过 “对手写数字进行识别” 的实例来说明如何使用nn构建一个 网络模型。
在这个基础上,后续我们将对nn的各模块 进行详细介绍。
主要步骤:
1)利用PyTorch内置函数mnist下载数据。
2)利用torchvision对数据进行预处理,调用torch.utils建立一个数据迭代器。
3)可视化源数据。
4)利用nn工具箱构建神经网络模型。
5)实例化模型,并定义损失函数及优化器。
6)训练模型。
7)可视化结果。
import numpy as np
import torch
import torch.nn as nn
from torchvision.datasets import mnist
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
train_batch_size = 64
test_batch_size = 128
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
train_set = mnist.MNIST("./mnist_data", train=True, download=True, transform=transform)
test_set = mnist.MNIST("./mnist_data", train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=train_batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=test_batch_size, shuffle=True)
examples = enumerate(test_loader)
batch_idex, (example_data, example_label) = next(examples)
sample_set = np.array(example_data)
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.imshow(sample_set[i][0])
plt.title("Ground Truth: {}".format(example_label[i]))
plt.show()
plt.pause(10)
plt.close()
class Net(nn.Module):
""" 使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起 """
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Net, self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, n_hidden_1), nn.BatchNorm1d(n_hidden_1))
self.layer2 = nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2), nn.BatchNorm1d(n_hidden_2))
self.layer3 = nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = self.layer3(x)
return x
model = Net(28 * 28, 300, 100, 10)
model.to(device)
lr = 0.01
num_epoches = 20
momentum = 0.5
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
eval_losses = []
eval_acces = []
for epoch in range(num_epoches):
if epoch % 5 == 0:
optimizer.param_groups[0]['lr'] *= 0.1
model.train()
for imgs, labels in train_loader:
imgs, labels = imgs.to(device), labels.to(device)
predict = model(imgs.view(imgs.size(0), -1))
loss = criterion(predict, labels)
# back propagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
eval_loss = 0
eval_acc = 0
model.eval()
for imgs, labels in test_loader:
imgs, labels = imgs.to(device), labels.to(device)
predict = model(imgs.view(imgs.size(0), -1))
loss = criterion(predict, labels)
# record loss
eval_loss += loss.item()
# record accurate rate
result = torch.argmax(predict, axis=1)
acc_num = (result == labels).sum().item()
acc_rate = acc_num / imgs.shape[0]
eval_acc += acc_rate
eval_losses.append(eval_loss / len(test_loader))
eval_acces.append(eval_acc / len(test_loader))
print('epoch: {}'.format(epoch))
print('loss: {}'.format(eval_loss / len(test_loader)))
print('accurate rate: {}'.format(eval_acc / len(test_loader)))
print('\n')
plt.title('evaluation loss')
plt.plot(np.range(len(eval_losses)), eval_losses)
plt.show()

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)