
【大数据离线项目一:基于Apache HIve的大数据离线项目的项目背景,技术框架,业务流程】
基于Apache HIve的大数据离线项目的相关技术分享,项目背景的目的,技术框架,业务流程,设备选型,连接数据库。
前言:
💞💞大家好,我是书生♡。本阶段主要和大家分享一下基于Apache HIve的大数据离线项目的相关技术分享。本篇文章主要是关于大数据离线项目的项目背景,技术框架,业务流程!感谢大家关注点赞。
💞💞前路漫漫,希望大家坚持下去,不忘初心,成为一名优秀的程序员
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬
目录
1. 项目背景和目的
1.1 项目的目的
本项目是基于电商进行大数据项目,主要的目的如下:
- 深入了解客户需求:
通过大数据分析,电商平台能够深入了解客户的购买行为、偏好和需求,从而根据客户的实际需求进行精准的产品推荐和定制化营销。消费者行为分析可以帮助电商企业更好地理解消费者需求,提供更精准的个性化推荐和定制化服务。 - 实时监控业务运营:
电商平台可以实时监控产品销售状况、库存情况、物流配送情况等关键指标,及时发现问题并进行调整和优化。实时监控和分析数据有助于电商企业快速做出决策,提高运营效率,降低成本,提升竞争力。 - 风险管理和安全保障:
电商平台面临着各种风险挑战,如欺诈交易、数据泄露、网络攻击等。通过大数据分析,电商企业可以建立健全的风险管理体系,识别和预防潜在风险,确保交易的安全和客户信息的保密。 - 市场竞争分析:
深入了解市场上的竞争态势、消费趋势和行业动态,及时调整产品结构和定价策略,抢占市场份额,提升品牌竞争力。 - 优化用户体验:
通过大数据支持的实时数据分析,电商平台可以根据用户行为建立个性化的客户画像,从而提升行业营销效果,优化用户体验。 - 支持多渠道交易网络:
大数据可以帮助企业构建多渠道的交易网络,便于企业及时发现客户需求,实现合理分配供需和收益分配。
1.2 项目的背景
随着电商行业的迅速发展,累计了大量数据。为了从已有的数据中挖掘出有价值的信息,搭建大数据处理平台。主要对各业务线的数据进行分析,从而便于精细化管理,最终提高用户数量及活跃度,提高商品销量,降低运营成本。
详细描述:
- 信息技术的高速发展:
随着信息技术的不断进步,特别是云计算、分布式存储和计算能力的提升,使得处理海量数据成为可能。这为电商行业积累了大量的用户数据、交易数据、行为数据等,为大数据开发提供了丰富的数据源。 - 互联网的普及和电商行业的快速发展:
互联网的普及和电商行业的迅猛发展为电商企业带来了庞大的用户群体和交易量。与此同时,消费者对购物体验、个性化推荐、快速配送等需求也不断提高,促使电商企业需要通过大数据分析来满足这些需求。 - 数据驱动决策的趋势:
在当今的商业环境中,数据已成为企业决策的重要依据。通过大数据分析,电商企业可以更准确地把握市场动态、用户需求、竞争态势等信息,为企业的战略决策提供支持。 - 消费者行为的复杂性:
消费者在选择商品、浏览网站、进行交易等行为中会产生大量的数据。这些数据具有高度的复杂性和多样性,需要通过大数据分析技术来提取有价值的信息,以便为电商企业制定精准的营销策略。
2. 行业背景
2.1 电商发展
电商的发展阶段
电商从最开始到现在分为四个阶段:
- 初创阶段 – 20世纪90年代
- 发展阶段 --21世纪初
- 成熟阶段 --2010年代
- 新零售阶段–2016年以后
什么是电商4.0
电商4.0 是在以往的基础上进行近一步的发展形成的,主要包括:
-
线上服务:通过互联网平台提供的购物、支付、物流等服务。
-
线下体验:在实体店铺中提供的商品展示、进行试用、售后服务等体验。
-
新物流:通过物流技术和网络优化提高物流效率和服务质量。
目前电商主营业务线有五条:
门店 B2C电商 批发 大客户团购 商品自营
2.2 需求说明
本次项目共计有四大需求: 销售需求 会员需求 供应链需求 商城需求
- 销售需求:
划分为线上销售流程和线下销售流程,业务部门需要全面分析线上线下的销售情况,包括销售、取消、退款的金额、成本、单量、SKU以及活动的情况。
- 会员需求:
因为生鲜电商业务,包括线上和线下,所以会员也分为线上会员和线下会员。
主要统计会员的注册、消费、充值、余额情况。注意线上会员也可以在线下消费,使用相同的手机号即可。
- 供应链需求
划为要货到货流程与商品划拨流程,为精细化运营,业务部门严格管控供应链,要求计算:库存的数量、金额、SKU、周转、动销、损耗数量和金额、盘点差异以及要货、收货、配送、退货、退配、调入、调出、系统调整的数量和金额。
- 商城需求
商城需求指的是对商城的访问日志进行分析,主要是流量数据和交易数据。如何评价线上平台的好坏,UV/PV/新访客数量/跳出数/浏览时长等都是非常重要的指标
3. 项目架构详解
3.1 数仓架构
3.1.1 传统数仓架构
最开始的传统数仓架构:主张自上而下的建设企业级数据仓库EDW (Enterprise DataWarehouse),这个过程中信息存储符合第三范式,结构如下: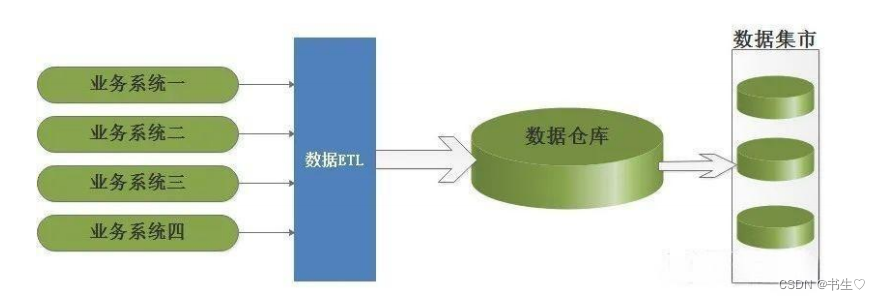
“上”即数据的上游,“下”即数据的下游
即从分散异构的数据源-> 数据仓库 -> 数据集市。以数据源头为导向,然后一步步探索获取尽量符合预期的数据
后来对传统数仓进行改进,有了较为完善的传统化数仓:
提出自下而上的建立数据仓库,整个过程中信息存储采用维度建模而非三范式。 Kimball 模型从流程上看是自下而上的,即从数据集市->数据仓库 -分散异构的数据源
是以最终任务为导向,将数据按照目标拆分出不同的表需求,数据会抽取为事实-维度模型,数据源经 ETL 转化
为事实表和维度表导入数据集市,架构体系中,数据集市与数据仓库是紧密结合的,数据集市是数据仓库中一个逻辑上的主题域。
缺点:
随着数据集市的不断增多,独立建设的数据集市由于遵循不同的标准和建设原则,以致多个数据集市的数据混乱和不一致。
3.1.2 离线大数据数仓架构
离线大数据数仓架构,采用推出全新的CIF架构, 核心将数仓架构划分为不同的层次以满足不同场景的需求。
例如:我们本项目中将数据分为5层,分别在不同的层中进行操作。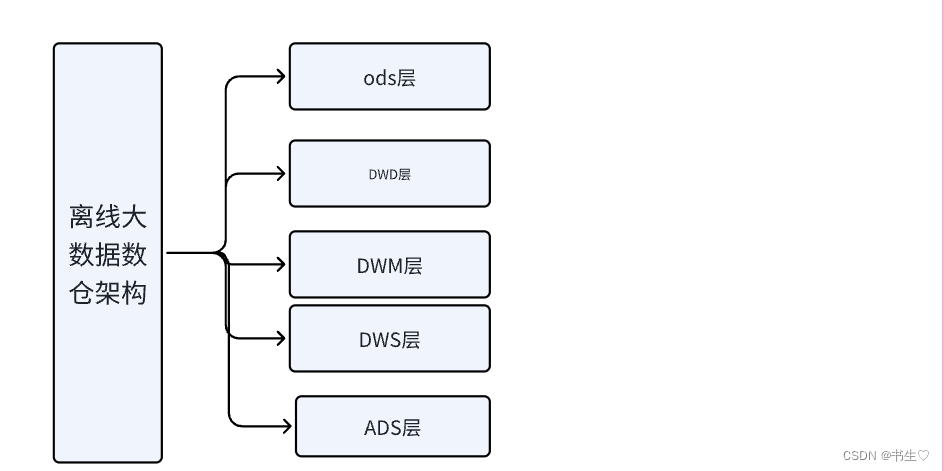
大数据中的数据仓库构建就是基于经典数仓架构而来,使用大数据中的工具来替代经典数仓中的传统工具,架构建设上没有根本区别
3.2 离线大数据数仓架构
集群管理工具:Cloudera Manager
数据源:业务系统的Mysql与SQLServer数据库;
数据抽取: 使用DataX实现关系型数据库和大数据集群的双向同步;
数据存储:HDFS
计算引擎:Hive
交互查询引擎:Presto
OLAP: PG
数据可视化: Fine Report
调度系统:DolphinScheduler(海豚调度)
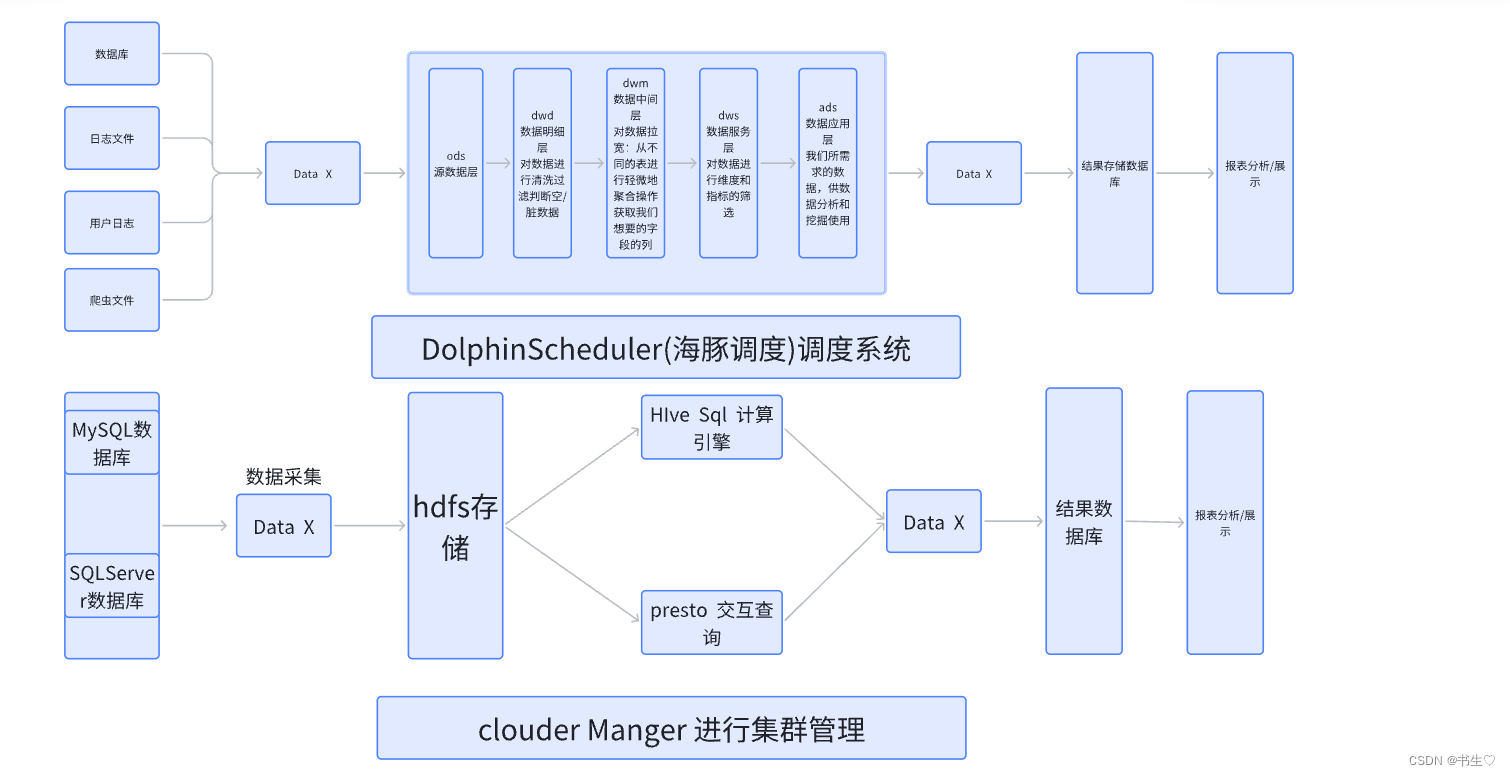
ods:源数据层,mysql,日志等数据首先被导入到该层。另外dim层层也是属于这个层的,区别在于,ods层的数据要后面要进行处理,而dim层的数据可能会在每一层都被使用,一般在dim层的数据都是不易改变的,哪怕是改变,也是小规模的小数据的改变。
dwd:数据明细层,对空/脏数据数据进行处理。
dwm:数据中间层,只要是根据需求将我们所需的字段连接在一个表中,这个步骤我们一般成为“ 拉宽 ”。
dws: 数据服务层 ,将数据进一步进行筛选,根据维度和指标,获取我们所需求的字段。
ads:数据应用层,也被称为app层、dal层、dm层,叫法繁多。将我们该层的数据交给报表进行分析。一般来说此层的数据都是我们筛选完成我们需求所要的数据。
3. 3 项目服务器架构选型
我们的大数据平台主要有四种,其中使用最多的CDH:
最终选择: CDH平台。
兼容性 稳定性 强大的管理平台 基础功能免费(公司使用最新版的需要付费,个人的话使用6版本是免费的)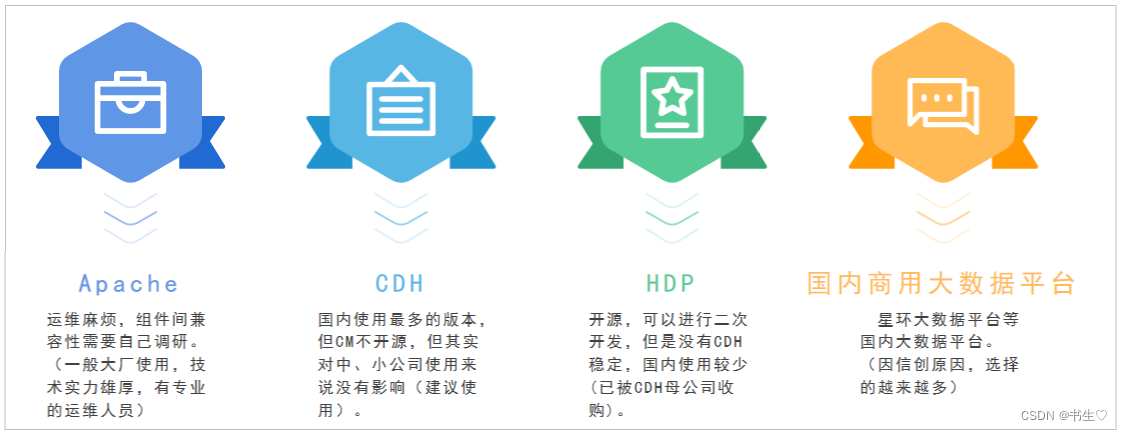
3. 4 集群数据规模
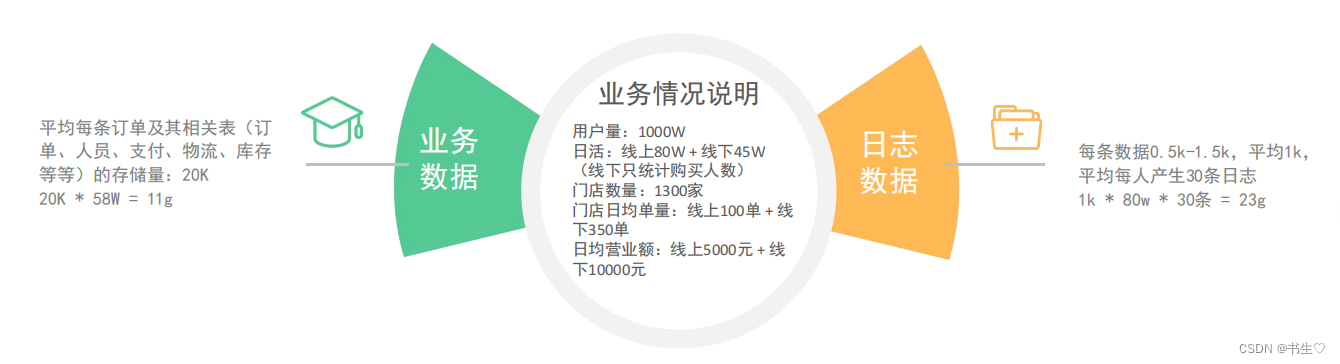
我们在这里做一个假设的数据集群规模:目的是计算需要多大的存储空间。
- 假设全国用户数量有1000w
- 每日活跃度:线上80w+线下50w(线下只考虑购买物品的)
- 假设门店数量为1300家
- 门店每日平均单量为:线上100单,线下350单
- 每日营业额:线上5000元,线下每日10000元
平均每条订单及其相关表(订单、人员、支付、物流、库存等等)的存储量:20K
每条数据0.5k-1.5k,平均1k,平均每人产生30条日志 30k
| 每日订单的数据量 | 门店数量 * 每日门店单量 * 每条的数据量 —> 1300 *(100+350)*20k= 11G(估算) |
|---|---|
| 每天的日志数据量 | 每日活跃(线上的)* 每条的数据量 * 每人产生的日志数量 —> 1* 80w *30=23G(估算) |
| 每日数据增加量 | 每天订单数据量+每天的日志数据量 —> 11G+23G=34G |
| 历史服务数据量 | 日志数据考虑压缩 ,实际增加量为11G+23G*0.4=20G (0.4 为数据压缩率 |
| 历史数据量为 | (230.4) 365 (天)1(年)=3T (日志数据只保留一年) 11G 365 *5 * 0.5 =10T (订单数据保留5年) |
| – | (0.5是因为历史上没有这么多的用户和订单) |
| 半年内不扩容服务器来算 | 20G * 180 天=3.6T |
| 加上数仓各层中间结果数据 | (3T+ 10T + 3.6T)* 1.5 + 3T * 4年 * 0.5 * 0.5 = 28T 第一个0.5是因为历史上没有这么多的用户,第二个0.5是数仓分层) |
| – | (3T * 4年 * 0.5 * 0.5 这个是删除掉原数据的日志数据的中间处理结果 |
| 保存3副本 | 28T * 3 = 84T |
| 预留20%-30%Buf | 84T / 0.75 = 112T |
计算得出 ,总需要空间为:112T ,假设每台服务器为 10 T存储的。
所以存储+计算服务器需要大概11台(晚上跑批任务,白天进行数据清洗以及查询、交互分析)。
因为有Presto基于内存的计算任务,所以计算节点需要再加5台。
另外加上管理服务器3台,测试服务器3台,大概需要22台。
3. 5 软件版本
| 软件 | 版本 |
|---|---|
| postgreSql | 11.9 |
| JAVA | 1.8 |
| Hadoop | hadoop -3.0.0-cdh 6.2.1 |
| zookeeper | zookeeper-3.4.5-cdh 6.2.1 |
| Hive | hive-2.1.1-cdh 6.2.1 |
| Doliphin Scheduler | 3.0.5 |
| Datax | v202210 |
| FIne report | v10.0 |
| impala | impala-3.1.0-cdh 6.2.1 |
3. 6 项目架构亮点
Ø 选用目前全球适用范围最为广泛的商用大数据平台: CDH
Ø 接入阿里推出的数据迁移工具DataX
Ø 数据报表采用目前国内使用广泛的组件FineReport
3.7.项目亮点
- 技术:
1- 数仓项目采用纯SQL方案, 完成整个数仓建设工作
2- 丰富的SQL调优方案 - 业务:
1- 完整的从0到1的全行业通用的数仓建设方案
2- 丰富的电商主题域开发模型
3.8 项目设计流程
1- 从数仓架构体系建设到数仓数据接入
2- 基于Hive SQL完成主题建设和数据处理
3- 从ODS层开发到ADS层建设, 实现数仓分层逐步开发
4- 从销售主题域链接到其他各主题域开发, 实现电商核心主题域开发
5- 最后完成数仓可视化平台,实现业务决策
4. 项目环境部署
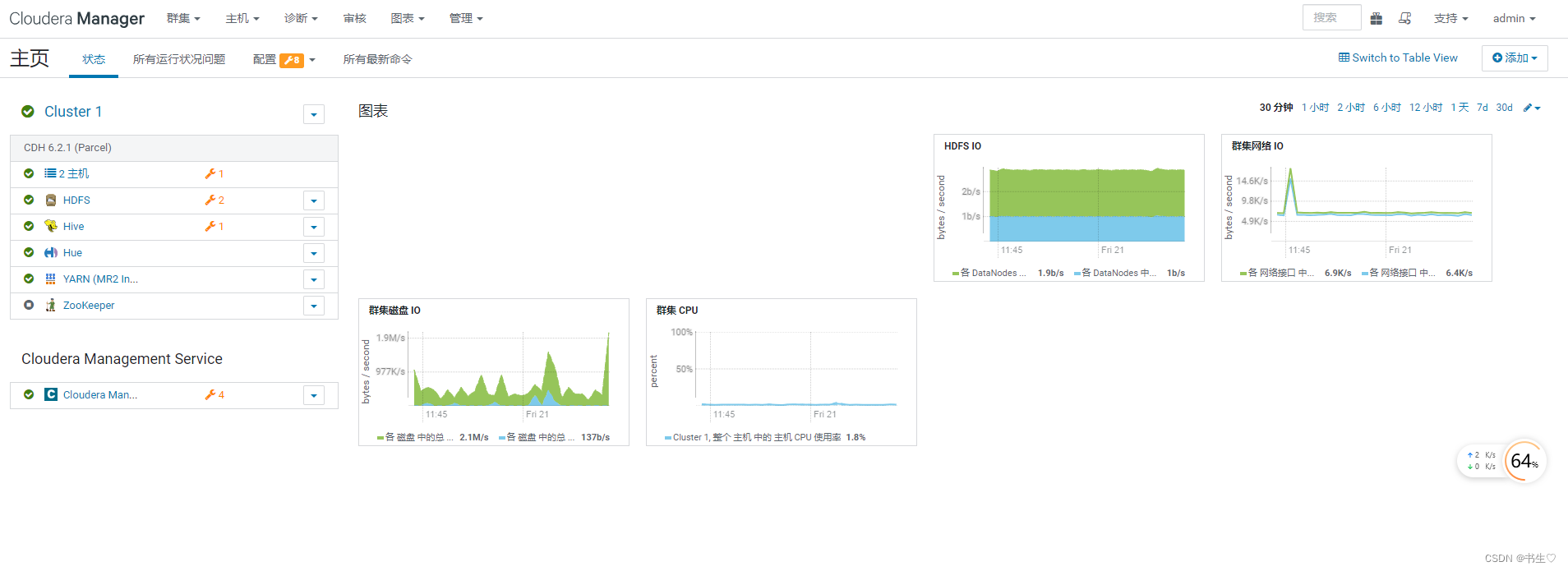
对于CDH,我们不必像hadoop一样自己去配置环境,只要使用cdh配置好的,在页面中点击启动就可以。
Clouder Manger 页面链接: http://hadoop01:7180/cmf/home
我们只需要点击Cluster1 直接启动全部服务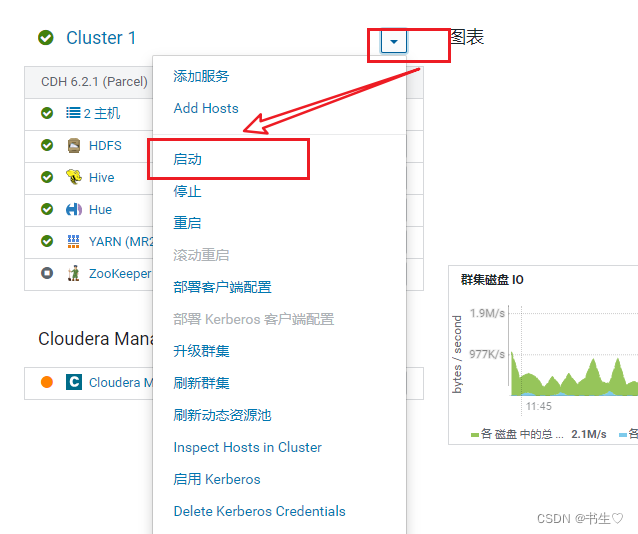
5. 连接数据库 (Datagrip)
5. 1连接Datagrip
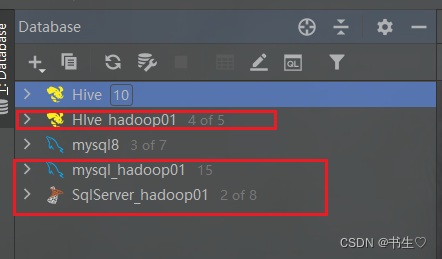
分别连接,hive,mysql,SQLserver 三个数据库。
注意:hive是我们的数仓,其他两个根据业务/公司的数据存储,不一定在mysql和SQLserver中,根据不同的数据存储软件去连接。
5.2 解决中文乱码问题
我们在创建表的时候,会给一些字段添加注释,可能会是中文的。
但是我们的数据库无法识别中文的字符是因为默认的字符集不一致,因此我们要修改mysql的字符集。
修改字符集一定要在mysql中,因为我们的元数据是存储在mysql中的
# 在MySQL中执行以下操作: 修改HIVE元数据的编码
use hive;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
# 修改后, 通过CM重启一下HIVE,然后删除表重新建表即可

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 31
31 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)