
循环神经网络及其存在的问题
传统的文本处理任务一般将tfidf向量作为特征输入,这样做存在一个问题就是忽略了文本序列中每个单词的顺序。同时在神经网络例如BP建模过程中通常接受的是一个固定的向量,当输入变长的文本需要先通过滑动窗口的形式转换成一个固定向量,虽然这样可以捕捉一些局部信息,但是两个长距离单词之间的依赖关系难以捕捉到。因此,未解决上述问题,循环神经网络(RNN)诞生,RNN可以很好的解决变长的文本数据和有序的输入序列
传统的文本处理任务一般将tfidf向量作为特征输入,这样做存在一个问题就是忽略了文本序列中每个单词的顺序。同时在神经网络例如BP建模过程中通常接受的是一个固定的向量,当输入变长的文本需要先通过滑动窗口的形式转换成一个固定向量,虽然这样可以捕捉一些局部信息,但是两个长距离单词之间的依赖关系难以捕捉到。
因此,未解决上述问题,循环神经网络(RNN)诞生,RNN可以很好的解决变长的文本数据和有序的输入序列。可以对文章中从前到后的单词进行顺序编码,将前面有用的信息存储在状态向量,从而拥有一定的记忆能力,可以更好的理解之后的文本。网络结构如下
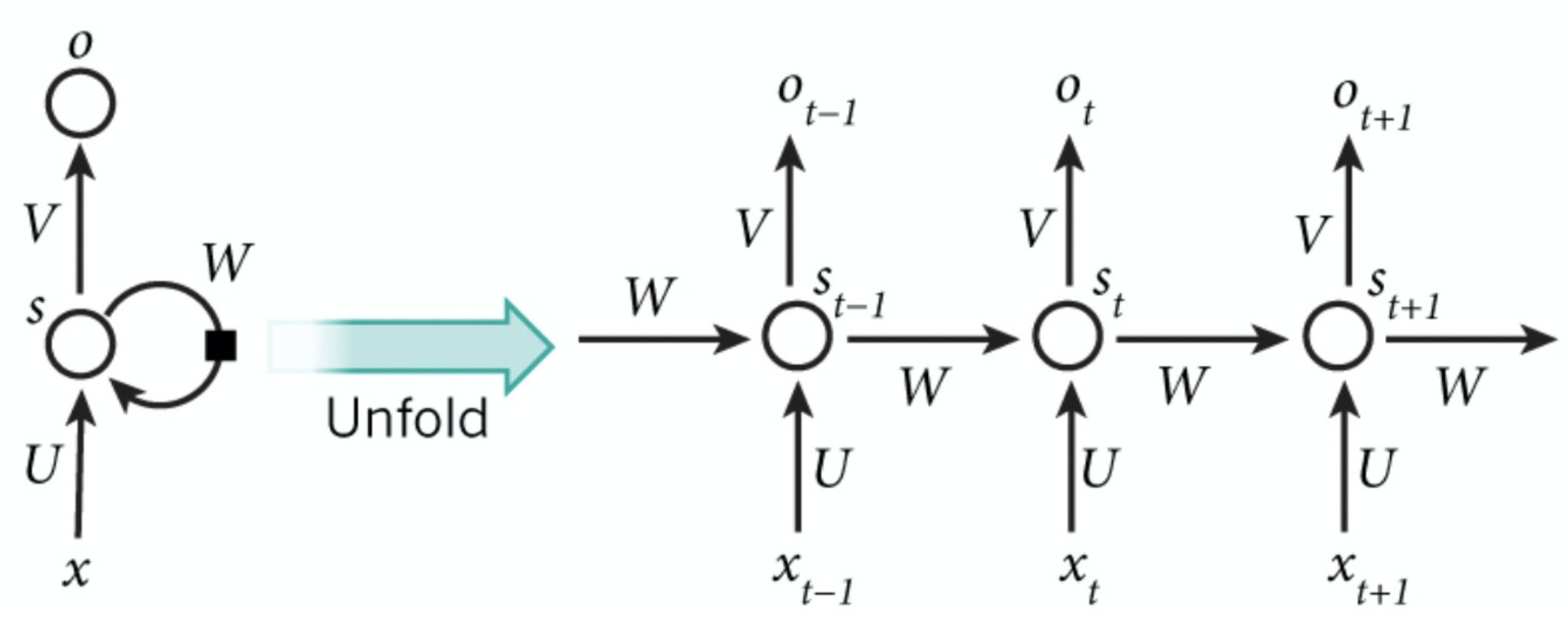
UUU为输入到隐层的权重矩阵,WWW为隐层从上一时刻到下一时刻的状态转移矩阵,VVV为隐层到输出层的权重矩阵。
RNN的求解可以采用基于BPTT(基于时间的反向传播)算法实现。如果将RNN按照时间展开成T层的前馈神经网络,和普通的反向传播算法基本没有区别。RNN设计初衷是捕获长距离输入之间的依赖,但是实践发现RNN并不能成功的捕捉到长距离的依赖关系,原因在于深度神经网络中的梯度消失和梯度爆炸现象。
传统的神经网络可以表示成连乘的形式
∂nett∂net1=∂nett∂nett−1∂nett−1∂nett−2...∂net2∂net1\frac{\partial net_t}{\partial net_1} = \frac{\partial net_t}{\partial net_{t-1}} \frac{\partial net_{t-1}}{\partial net_{t-2}} ... \frac{\partial net_{2}}{\partial net_1}∂net1∂nett=∂nett−1∂nett∂nett−2∂nett−1...∂net1∂net2
其中nett=Uxt+Wht−1net_t = Ux_t + Wh_{t-1}nett=Uxt+Wht−1, ht=f(nett)h_t = f(net_t)ht=f(nett), y=g(Vht)y = g(Vh_t)y=g(Vht), ∂nett∂nett−1=∂nett∂ht−1∂ht−1∂nett−1=W⋅f′(nett)\frac{\partial net_t}{\partial net_{t-1}} = \frac{\partial net_t}{\partial h_{t-1}} \frac{\partial h_{t-1}}{\partial net_{t-1}} = W·f^{'}(net_t)∂nett−1∂nett=∂ht−1∂nett∂nett−1∂ht−1=W⋅f′(nett)
由于预测误差会按照网络进行反向传播,很容易想到,依赖于我们的激活函数和网络参数,如果参数矩阵中的值太大或者激活函数为Relu等,会产生梯度爆炸。如果参数矩阵中的值太大或使用sigmoid/tanh等,会产生梯度消失。
梯度消失比梯度爆炸受到了更多的关注有两方面的原因。
- 其一,梯度爆炸容易发现,梯度值会变成NaN,导致程序崩溃。
- 其二,用预定义的阈值裁剪梯度可以简单有效的解决梯度爆炸问题。梯度消失出现的时候不那么明显而且不好处理。
梯度消失如何解决?
- 长短时记忆模型LSTM
- 门控单元 GRU
- 合适的初始化矩阵W
- 正则化
- 选择ReLU而不是sigmoid和tanh作为激活函数
梯度爆炸如何解决?
- 梯度剪裁,梯度大于某个阈值进行等比收缩
- 修正激活函数等
欢迎关注微信公众号(算法工程师面试那些事儿),本公众号聚焦于算法工程师面试,期待和大家一起刷leecode,刷机器学习、深度学习面试题等,共勉~


技术共进,成长同行——讯飞AI开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)