
K8S-1.33.1 - 阿里云ubuntu24.04 -k8s集群25年最新版安装文档
K8S-1.33.1-阿里云ubuntu24.04-使用docker作为容器运行时-25年最新版安装文档
k8s-阿里云ubuntu24.04-cri-docker容器运行时
一.所有机器系统环境准备
1.购买服务器
购买了8c16g 三台服务器
172.31.0.61
172.31.1.61
172.31.2.61
云服务器很难做多主节点的k8s集群,主控制平面节点负载均衡并无较好的解决方案
https://help.aliyun.com/zh/vpc/user-guide/highly-available-virtual-ip-address-havip
以下内容除非特殊说明,默认三台机器都要做的
1.apt更新
vi /etc/apt/sources.list
在最后
添加如下内容:
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
再执行:
apt update
apt upgrade
之后执行确定
1.DNS设置
https://help.aliyun.com/zh/ecs/user-guide/how-do-i-customize-the-dns-settings-of-a-linux-instance
阿里云为 ECS 实例提供高可用、高性能的默认 DNS 服务器(IP 地址为 100.100.2.136 和 100.100.2.138),该服务由阿里云自动维护,您无需为ECS实例进行额外配置。
请注意,阿里云默认的DNS服务器可以解析阿里云服务的内网域名,如果删除默认DNS服务器,会导致ECS实例无法访问一系列服务,例如OSS Bucket内网域名等。建议您将自定义的DNS服务器地址放在阿里云默认DNS服务器地址前(越前优先级越高),将阿里云默认DNS服务器作为备选DNS服务器。
2.关闭自动更新
systemctl stop unattended-upgrades
systemctl disable unattended-upgrades
apt remove unattended-upgrades
3.启用ipv4数据包转发
默认情况下,Linux 内核不允许 IPv4 数据包在接口之间路由。 大多数 Kubernetes 集群网络实现都会更改此设置(如果需要),但有些人可能希望管理员为他们执行此操作。 (有些人可能还期望设置其他 sysctl 参数、加载内核模块等;请参阅你的特定网络实施的文档。)
# 设置所需的 sysctl 参数,参数在重新启动后保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
EOF
# 应用 sysctl 参数而不重新启动
sudo sysctl --system
#使用以下命令验证 net.ipv4.ip_forward 是否设置为 1:
sysctl net.ipv4.ip_forward
4.交换分区
阿里云上Ubuntu系统已经禁止了交换分区、包括使用systemd作为cgroupfs 驱动、关闭防火墙、安全组内配置端口互通、配置apt阿里镜像源、DNS设置,都不用做
5.host配置
官方文档中提到了“节点之中不可以有重复的主机名、MAC 地址或 product_uuid”
#设置主机名及host
#172.31.0.61执行:
hostnamectl set-hostname k8s-ubuntu-prd-master01 && bash
#172.31.1.61执行
hostnamectl set-hostname k8s-ubuntu-prd-node01 && bash
#172.31.2.61执行
hostnamectl set-hostname k8s-ubuntu-prd-node02 && bash
#所有机器添加master域名映射,以下需要修改为自己的
echo "172.31.0.61 cluster-endpoint" >> /etc/hosts
至此,所有系统环境准备完成,剩下的就是安装软件
二.下载准备
1.docker-engine
进入https://docs.docker.com/engine/install/ubuntu/
选择从package包安装
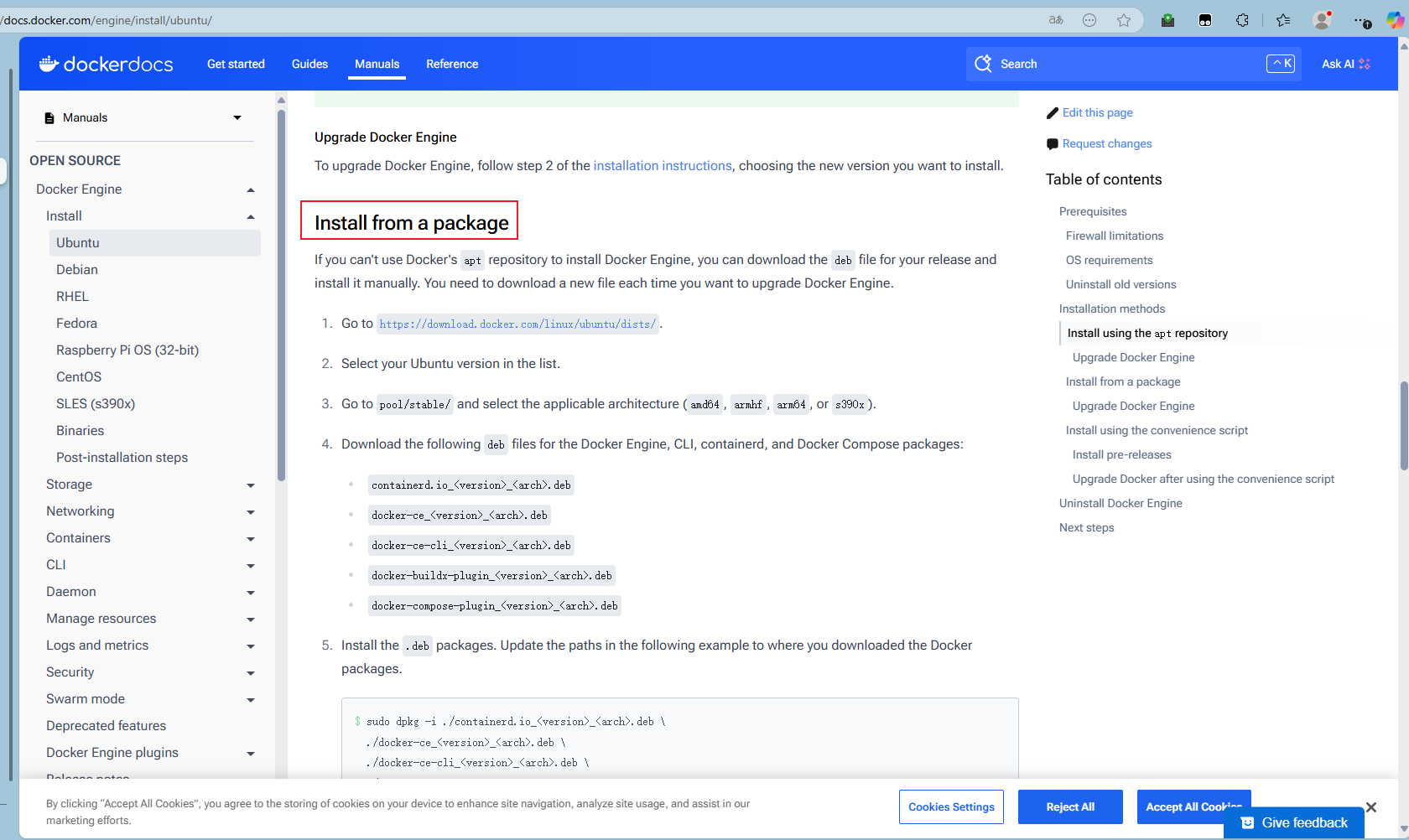
依照教程:
#进入
https://download.docker.com/linux/ubuntu/dists/
#选择版本,我们是Ubuntu24.04
/noble/pool/stable/amd64/
#进入下载最新版


#我这里选择下载
containerd.io_1.7.27-1_amd64.deb
docker-ce_28.2.2-1~ubuntu.24.04~noble_amd64.deb
docker-ce-cli_28.2.2-1~ubuntu.24.04~noble_amd64.deb
docker-buildx-plugin_0.24.0-1~ubuntu.24.04~noble_amd64.deb
docker-compose-plugin_2.36.2-1~ubuntu.24.04~noble_amd64.deb
#在各台机器上执行
mkdir -p /app/k8s/docker
#进入目录,上传下载的deb包
#之后执行
dpkg -i containerd.io_1.7.27-1_amd64.deb docker-ce_28.2.2-1~ubuntu.24.04~noble_amd64.deb docker-ce-cli_28.2.2-1~ubuntu.24.04~noble_amd64.deb docker-buildx-plugin_0.24.0-1~ubuntu.24.04~noble_amd64.deb docker-compose-plugin_2.36.2-1~ubuntu.24.04~noble_amd64.deb
#查看docker状态
systemctl status docker.service
阿里docker镜像加速地址通过如下链接查看
https://cr.console.aliyun.com/cn-shanghai/instances/mirrors
阿里云无法拉取calico镜像,故添加https://docker.m.daocloud.io镜像加速地址
#更改docker配置
vi /etc/docker/daemon.json
#输入如下配置,注意如果max-size不等于10m,会和k8s默认10m最大日志冲突,会不断刷出报错日志:
{
"registry-mirrors": ["https://ihsxva0f.mirror.aliyuncs.com","https://docker.m.daocloud.io","https://registry.docker-cn.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3"
},
"storage-driver": "overlay2"
}
#重新启动
systemctl daemon-reload
systemctl restart docker
关于私有镜像仓库
https://cr.console.aliyun.com/cn-shanghai/instance/dashboard
后续我会经常用到私有仓库,注意registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/是我自己的内网仓库,实际使用中应该替换为你们个人的仓库
#私网登录镜像仓库
docker login --username=**** registry-vpc.cn-shanghai.aliyuncs.com
****
2.cri-docker
最终我们进入GitHub-releases页面:
https://github.com/Mirantis/cri-dockerd/releases
#选择下载
cri-dockerd-0.3.18.amd64.tgz
#在各台机器上执行
mkdir -p /app/k8s/cri-docker
#进入目录,上传下载的tgz包
#执行
tar xf cri-dockerd-0.3.18.amd64.tgz
#拷贝解压后的文件到/usr/bin目录下
cp cri-dockerd/cri-dockerd /usr/bin/
#测试
cri-dockerd --version
接下来我们需要建立一个cri-dockerd服务、开机自启;另外我们需要pause:3.10沙箱

#我们使用谷歌镜像手动拉取pause镜像
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.10
#列出当前镜像
docker images
#为pause:3.10打tag,之后推到我们自己的私有镜像仓库上
docker tag 873ed7510279 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/pause:3.10
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/pause:3.10
https://github.com/Mirantis/cri-dockerd/tree/master/packaging/systemd
接下来新建vi /etc/systemd/system/cri-docker.service
添加如下内容:
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
ExecStart=/usr/bin/cri-dockerd --pod-infra-container-image=registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/pause:3.10 --network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin --container-runtime-endpoint=unix:///var/run/cri-dockerd.sock --cri-dockerd-root-directory=/var/lib/dockershim --docker-endpoint=unix:///var/run/docker.sock --cri-dockerd-root-directory=/var/lib/docker
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
vi /etc/systemd/system/cri-docker.socket
添加如下内容:
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=/var/run/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
systemctl daemon-reload
systemctl enable cri-docker.service
systemctl enable cri-docker.socket
systemctl restart cri-docker.service
ls /var/run | grep docker
3.安装kubeadm
https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
#安装使用 Kubernetes apt 仓库所需要的包:
apt install -y apt-transport-https ca-certificates curl gpg
# 如果 `/etc/apt/keyrings` 目录不存在,则应在 curl 命令之前创建它,请阅读下面的注释。
# sudo mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.33/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
# 此操作会覆盖 /etc/apt/sources.list.d/kubernetes.list 中现存的所有配置。
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.33/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
apt update
apt install -y kubelet kubeadm kubectl
apt-mark hold kubelet kubeadm kubectl
4.拉取所需镜像
参考
#查看需要哪些镜像
kubeadm config images list
#输出结果如下
registry.k8s.io/kube-apiserver:v1.33.1
registry.k8s.io/kube-controller-manager:v1.33.1
registry.k8s.io/kube-scheduler:v1.33.1
registry.k8s.io/kube-proxy:v1.33.1
registry.k8s.io/coredns/coredns:v1.12.0
registry.k8s.io/pause:3.10
registry.k8s.io/etcd:3.5.21-0
#我们无法直接拉取这些所需镜像
#解决方法、使用阿里云谷歌镜像仓库拉取到本地,之后再打tag推送到私有云镜像仓库,其中pause镜像我们已经这样拉取过了
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.33.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.33.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.33.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.33.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.12.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.21-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.10
#注意coredns的目录结构
#由于向后兼容的原因,使用 imageRepository 所指定的定制镜像库可能与默认的 registry.k8s.io 镜像路径不同。例如,某镜像的子路径可能是 registry.k8s.io/subpath/image, 但使用自定义仓库时默认为 my.customrepository.io/image。
#使用docker images 查看tag
docker tag c6ab243b29f8 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-apiserver:v1.33.1
docker tag ef43894fa110 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-controller-manager:v1.33.1
docker tag 398c985c0d95 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-scheduler:v1.33.1
docker tag b79c189b052c registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-proxy:v1.33.1
docker tag 1cf5f116067c registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/coredns:v1.12.0
docker tag 499038711c08 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/etcd:3.5.21-0
docker tag 873ed7510279 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/pause:3.10
#将镜像推送到自己的私有仓库上
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-apiserver:v1.33.1
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-controller-manager:v1.33.1
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-scheduler:v1.33.1
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-proxy:v1.33.1
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/coredns:v1.12.0
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/etcd:3.5.21-0
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/pause:3.10
#其他机器直接从私有仓库上拉取镜像
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-apiserver:v1.33.1
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-controller-manager:v1.33.1
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-scheduler:v1.33.1
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-proxy:v1.33.1
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/coredns:v1.12.0
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/etcd:3.5.21-0
#最终确保我们使用的三台机器都有如下镜像
registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-apiserver:v1.33.1
registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-controller-manager:v1.33.1
registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-scheduler:v1.33.1
registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-proxy:v1.33.1
registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/coredns:v1.12.0
registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/etcd:3.5.21-0
registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/pause:3.10
三.初始化
1.init(只在主节点上运行)
kubeadm init \
--apiserver-advertise-address=172.31.0.61 \
--control-plane-endpoint=cluster-endpoint \
--image-repository=registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.168.0.0/16 \
--cri-socket=unix:///var/run/cri-dockerd.sock
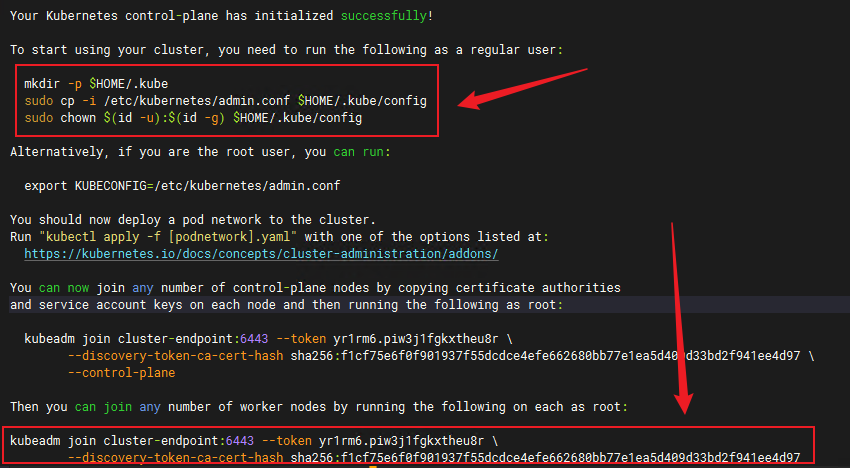
运行成功,我们在子节点上执行生成的最后一句以加入集群,记得加上–cri-socket参数指定容器运行时:
kubeadm join cluster-endpoint:6443 --token yr1rm6.piw3j1fgkxtheu8r \
--discovery-token-ca-cert-hash sha256:f1cf75e6f0f901937f55dcdce4efe662680bb77e1ea5d409d33bd2f941ee4d97 \
--cri-socket=unix:///var/run/cri-dockerd.sock
此时,使用kubectl命令报错,注意日志中的:
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
在主节点还需执行如下命令,才能使用kubectl命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
2.安装网络插件calico
https://docs.tigera.io/calico/latest/getting-started/kubernetes/self-managed-onprem/onpremises
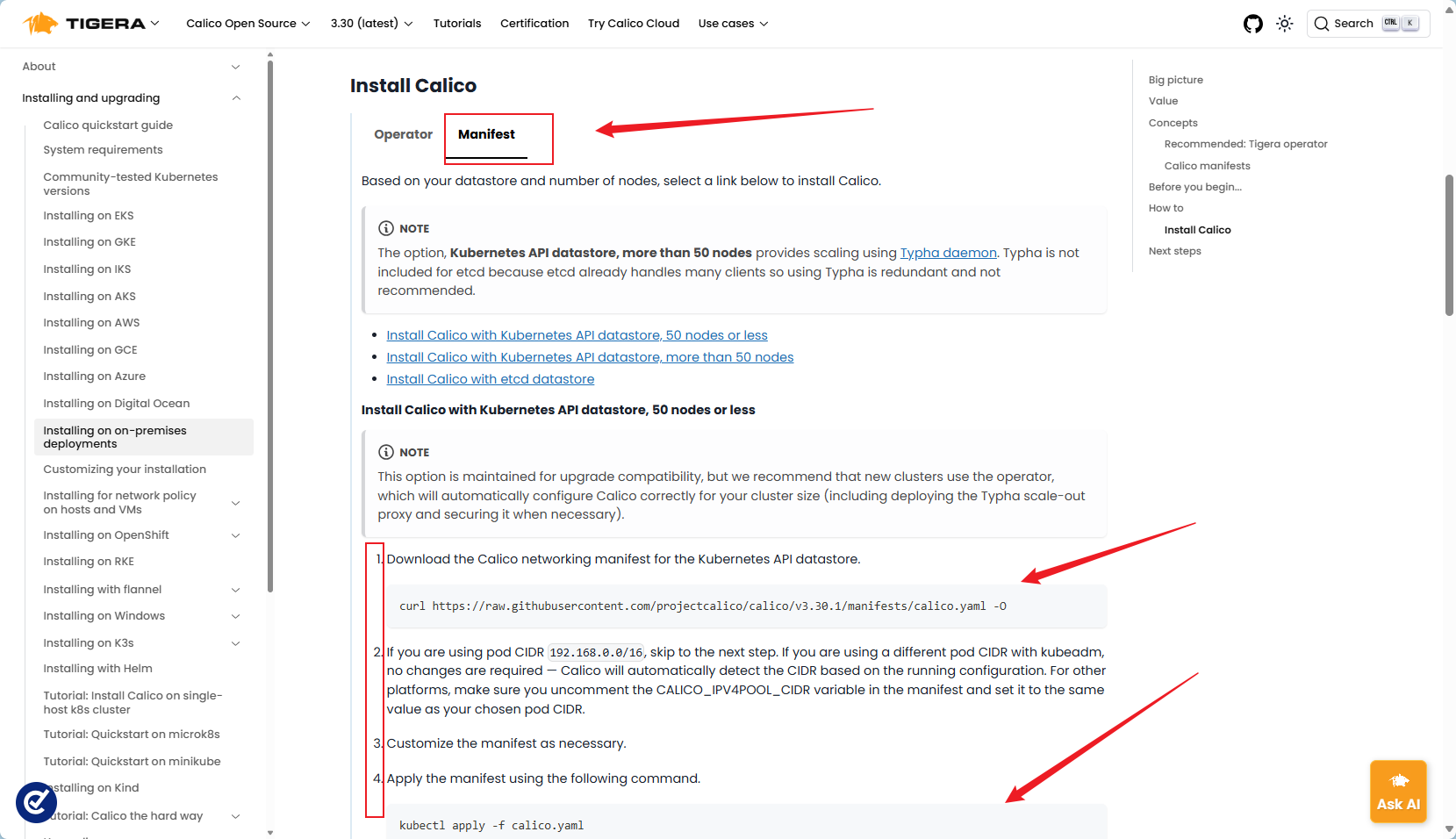
我们选择第二种部署方式,先把yaml文件下载下来
#浏览器访问:
https://raw.githubusercontent.com/projectcalico/calico/v3.30.1/manifests/calico.yaml
#另存为calico.yaml
#搜索“image”查找所有的所需镜像(手动拉取,docker.io多访问几次),打tag后推送到私有仓库
v3.30.1共查找到依赖以下镜像,统一手动拉取
docker pull docker.io/calico/cni:v3.30.1
docker pull docker.io/calico/node:v3.30.1
docker pull docker.io/calico/kube-controllers:v3.30.1
docker tag 9ac26af2ca9c registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/calico-node:v3.30.1
docker tag 0d2cd976ff6e registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/calico-cni:v3.30.1
docker tag 6df5d7da55b1 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/calico-kube-controllers:v3.30.1
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/calico-node:v3.30.1
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/calico-cni:v3.30.1
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/calico-kube-controllers:v3.30.1
#在工作节点上执行,确保所有三台机器上都有所需镜像
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/calico-node:v3.30.1
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/calico-cni:v3.30.1
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/calico-kube-controllers:v3.30.1
#修改所有calico.yaml文件中的image,变成私有镜像仓库镜像,更改内容后在主节点执行
kubectl apply -f calico.yaml
过段时间查看 kubectl get pod -A
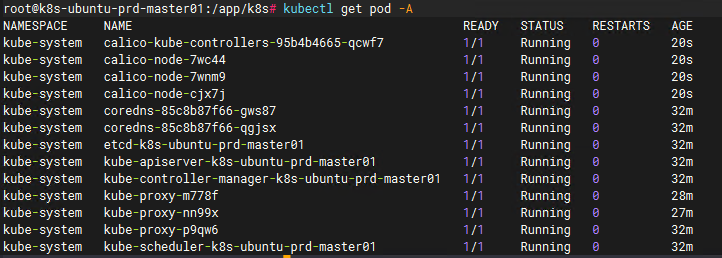
至此,k8s已经完全安装完成
三.安装metrics-server
1.metrics-server
资源监控应用、安装后可使用
kubectl top pod
kubectl top node
也会自动丰富dash-board可视化页面
安装metrics-server。
官网文档:资源指标管道 | Kubernetes
官网github:https://github.com/kubernetes-sigs/metrics-server#installation
1)下载yaml文件
https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
以下是修改后的内容:
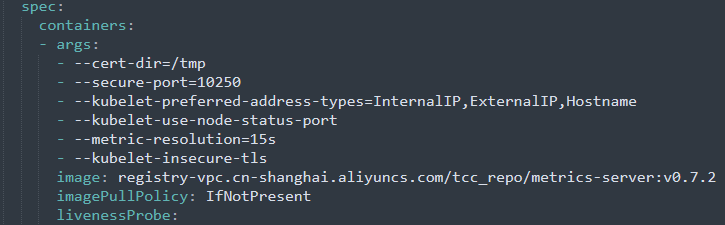
修改了两个地方都是在Deployment.spec.template.containers路径下:
- args增加参数:- --kubelet-insecure-tls #表示不验证客户端证书
- image改为私有阿里镜像仓库:registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/metrics-server:v0.7.2
2)之后在每台机器上都拉取registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/metrics-server:v0.7.2;
再在主节点使用kubectl apply -f XXX.yaml 即可
过段时间就可以使用kubectl top pod 命令了,不过要等到先有应用服务跑起来之后
四.配置k8s免登私有仓库
1.发现问题
docker login后,可以直接pull我们的私有仓库,但是k8s的yaml里写的私有仓库地址镜像却在apply时提示拉取失败(要登录认证)
(解决方法其一,就是每次部署时,事先把所需镜像手动拉取到部署机)
2.配置添加项目所在命名空间的私有仓库秘钥,以便拉取镜像时完成认证过程
#应执行命令
kubectl create secret docker-registry harbor-secret(别名) --namespace=项目所在命名空间 --docker-server=Harbor地址 --docker-username=账户 --docker-password=Harbor密码
#实测master节点执行就够了
#注意只可在本命名空间下使用
#执行如下命令:
kubectl create secret docker-registry ali-registry-vpc-secret --docker-server=registry-vpc.cn-shanghai.aliyuncs.com --docker-username=**** --docker-password=****
4.更新服务yaml文件,添加引用创建的秘钥
spec:
imagePullSecrets:
- name: ali-registry-vpc-secret
containers:
- name: sync-customer-ticket
image: registry-vpc.cn-shanghai.aliyuncs.com/tcc_app/sync-customer-ticket:v1.0.5
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6080
5.kubectl apply -f xxx.yaml -n xx发现自动拉取私有镜像成功
五.后续
在长期使用过程中,日志被docker配置自动清理,但相关镜像会占用空间
1.镜像垃圾清理
这属于docker范畴
#清理命令如下
docker system df
docker system prune
docker image prune -a
docker builder prune
#部分镜像会被自动清理,但建议保留,使用如下命令拉回来
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-scheduler:v1.33.1
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/calico-kube-controllers:v3.30.1
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/etcd:3.5.21-0
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/metrics-server:v0.7.2
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-apiserver:v1.33.1
2.集群证书更换
以下内容来自验证于即将过期的老集群v1.20.9:
主节点证书需要每年更新,如果选择升级集群则不用
https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/kubeadm/kubeadm-certs/
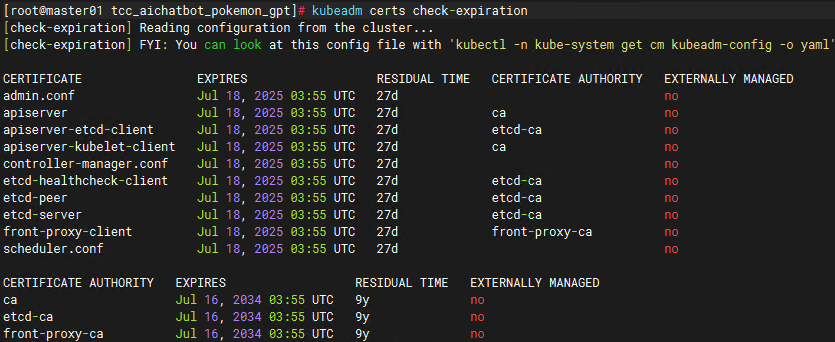
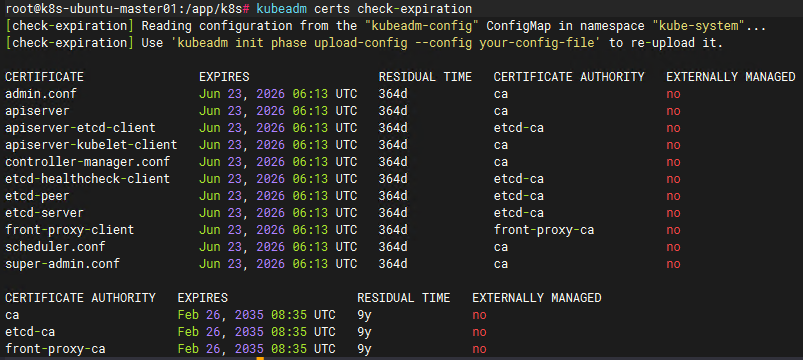
查看剩余时间:
kubeadm certs check-expiration
手动更新证书
kubeadm certs renew all
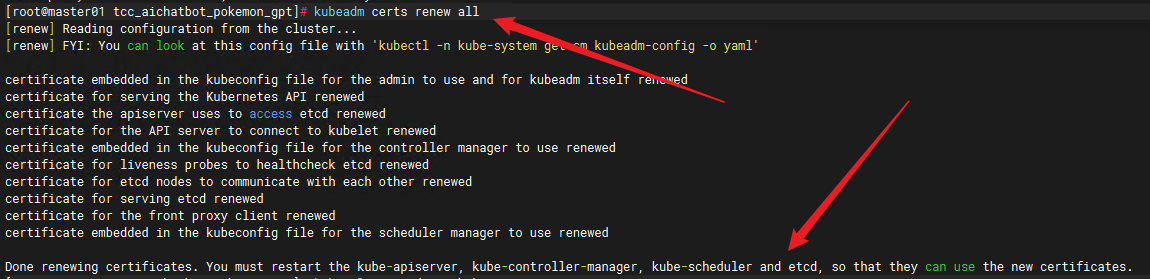
更新完成后、查看有效期
提示:
Done renewing certificates. You must restart the kube-apiserver, kube-controller-manager, kube-scheduler and etcd, so that they can use the new certificates.
文档中也告诉了我们要重启主节点pod。
先用nginx断掉主节点的流量
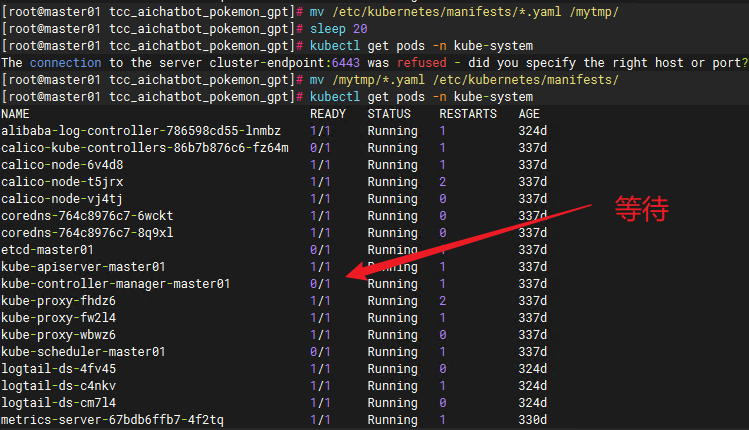
#重启kubelet
systemctl restart kubelet
#以下目的是重启静态pod
#建立一个临时目录
mkdir /mytmp
#移走
mv /etc/kubernetes/manifests/*.yaml /mytmp/
#等待
sleep 20
#移动回来
mv /mytmp/*.yaml /etc/kubernetes/manifests/
#删除临时目录
rm -r /mytmp
#所有机器上重启docker可使全部容器重启(忽略此步)
#systemctl restart docker

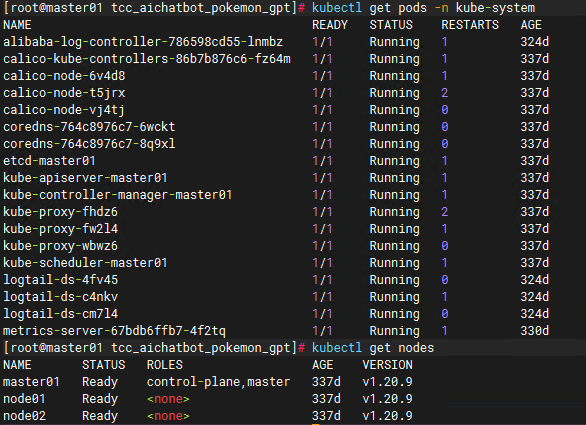
复制管理员证书

sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config

验证证书有效期:
kubeadm certs check-expiration
验证集群pod/node状态:
kubectl get pods -n kube-system
kubectl get nodes
3.集群升级
现在需要将1.32.2 升级到1.33.2
1)升级控制节点
#打开定义k8s apt仓库的文件,参考:(https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/kubeadm/change-package-repository/#verifying-if-the-kubernetes-package-repositories-are-used)
vi /etc/apt/sources.list.d/kubernetes.list
#将 URL 中的版本更改为下一个可用的小版本,例如:
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.33/deb/ /
#执行:
apt update
#查看预期版本
apt-cache madison kubeadm
升级 kubeadm
# 用最新的补丁版本号替换 1.33.x-* 中的 x
sudo apt-mark unhold kubeadm && \
sudo apt-get update && sudo apt-get install -y kubeadm='1.33.x-*' && \
sudo apt-mark hold kubeadm
#验证下载操作正常,并且 kubeadm 版本正确:
kubeadm version
#验证升级计划:
sudo kubeadm upgrade plan
#执行升级(提示镜像拉取失败)
sudo kubeadm upgrade apply v1.33.2
#查看所需镜像(在所有机器上手动拉取)
kubeadm config images list
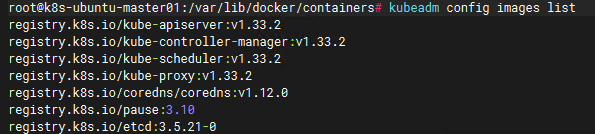
手动拉取所需镜像
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.33.2
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.33.2
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.33.2
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.33.2
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.12.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.21-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.10
将镜像打包到私有镜像仓库
docker tag ee794efa53d8 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-apiserver:v1.33.2
docker tag 661d404f36f0 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-proxy:v1.33.2
docker tag cfed1ff74892 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-scheduler:v1.33.2
docker tag ff4f56c76b82 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-controller-manager:v1.33.2
docker tag 1cf5f116067c registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/coredns:v1.12.0
docker tag 499038711c08 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/etcd:3.5.21-0
docker tag 873ed7510279 registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/pause:3.10
推送到私有镜像仓库上(这里是执行init时的镜像仓库)
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-apiserver:v1.33.2
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-proxy:v1.33.2
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-scheduler:v1.33.2
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-controller-manager:v1.33.2
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/coredns:v1.12.0
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/etcd:3.5.21-0
docker push registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/pause:3.10
#执行升级
kubeadm upgrade apply v1.33.2
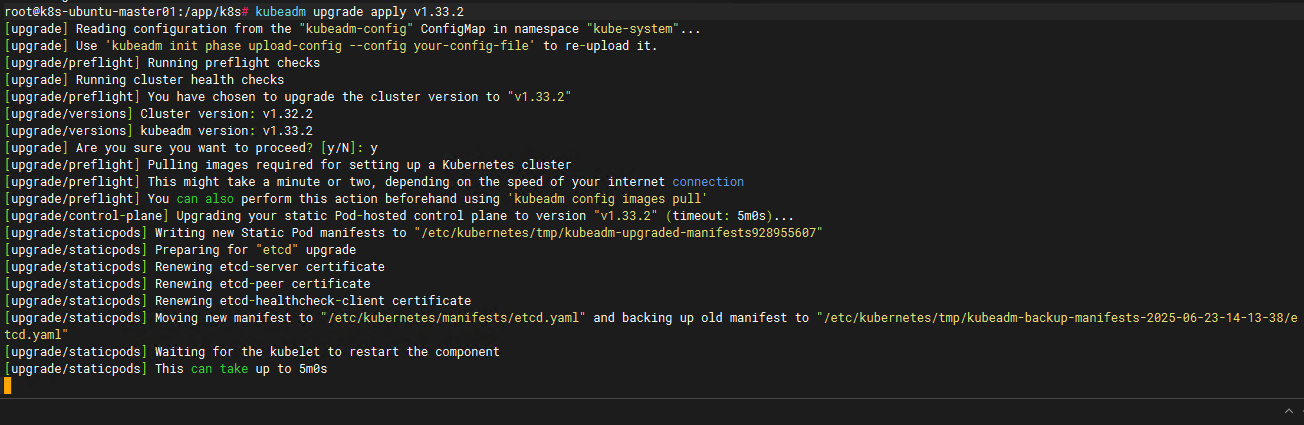
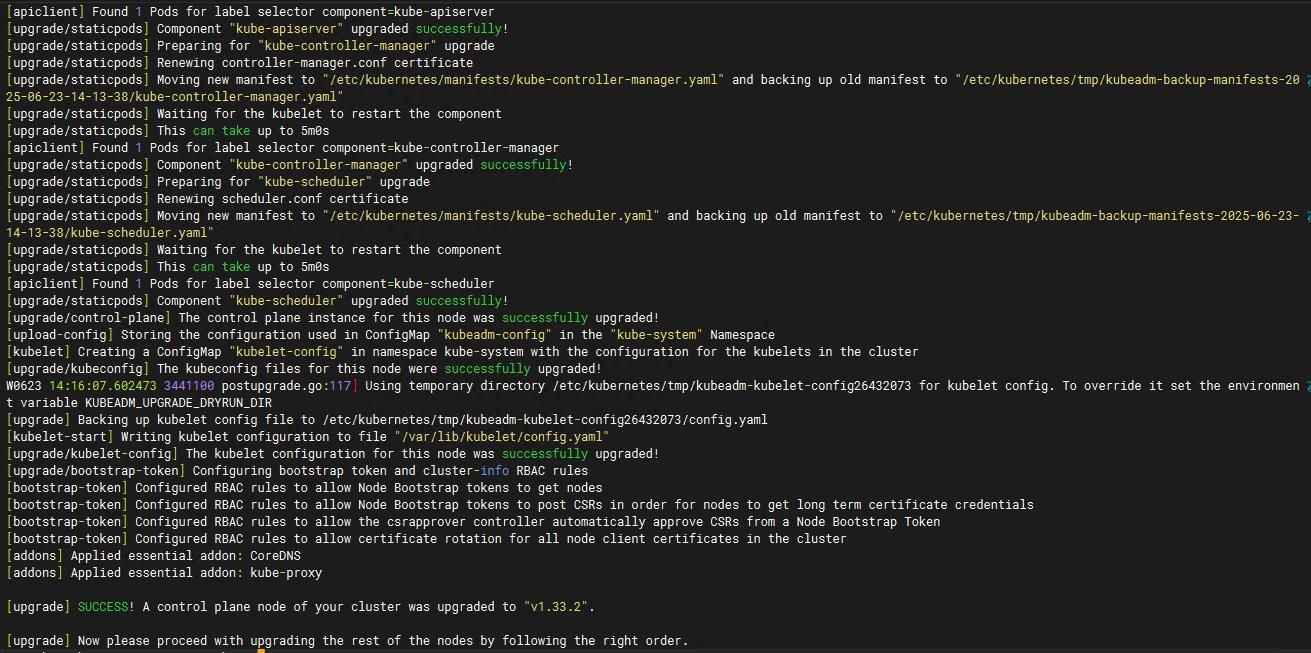
升级成功
升级 kubelet 和 kubectl:
# 用最新的补丁版本替换 1.33.x-* 中的 x
sudo apt-mark unhold kubelet kubectl && \
sudo apt-get update && sudo apt-get install -y kubelet='1.33.x-*' kubectl='1.33.x-*' && \
sudo apt-mark hold kubelet kubectl
#重启kubelet
sudo systemctl daemon-reload
sudo systemctl restart kubelet
其他:
升级网络插件(依照calico相关官方文档。)(本次未升级)
验证可以重新下载最新版本的yaml文件并apply部署以完成升级
安装:
https://docs.tigera.io/calico/latest/getting-started/kubernetes/self-managed-onprem/onpremises
升级:
注意替换yaml文件中的镜像为私有镜像
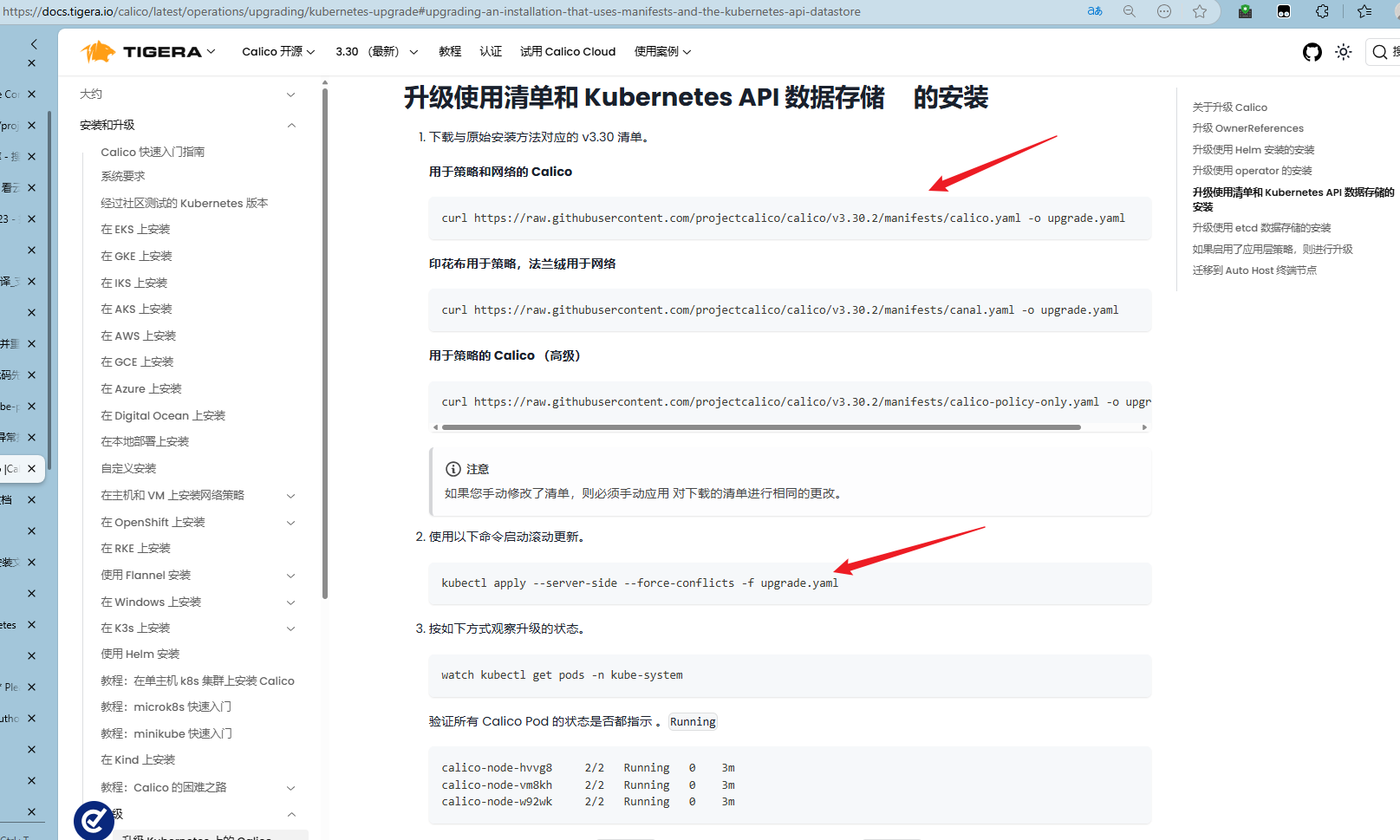
2)升级node节点
#打开定义k8s apt仓库的文件,参考:(https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/kubeadm/change-package-repository/#verifying-if-the-kubernetes-package-repositories-are-used)
vi /etc/apt/sources.list.d/kubernetes.list
#将 URL 中的版本更改为下一个可用的小版本,例如:
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.33/deb/ /
#执行:
apt update
#执行升级kubeadm
sudo apt-mark unhold kubeadm && \
sudo apt-get update && sudo apt-get install -y kubeadm='1.33.2-*' && \
sudo apt-mark hold kubeadm
#拉取镜像
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-apiserver:v1.33.2
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-proxy:v1.33.2
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-scheduler:v1.33.2
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/kube-controller-manager:v1.33.2
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/coredns:v1.12.0
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/etcd:3.5.21-0
docker pull registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo/pause:3.10
#对于工作节点,下面的命令会升级本地的 kubelet 配置:
sudo kubeadm upgrade node

# 在控制平面节点上执行此命令
# 将 <node-to-drain> 替换为你正腾空的节点的名称
#kubectl drain <node-to-drain> --ignore-daemonsets
kubectl drain k8s-ubuntu-node01 --ignore-daemonsets --delete-emptydir-data
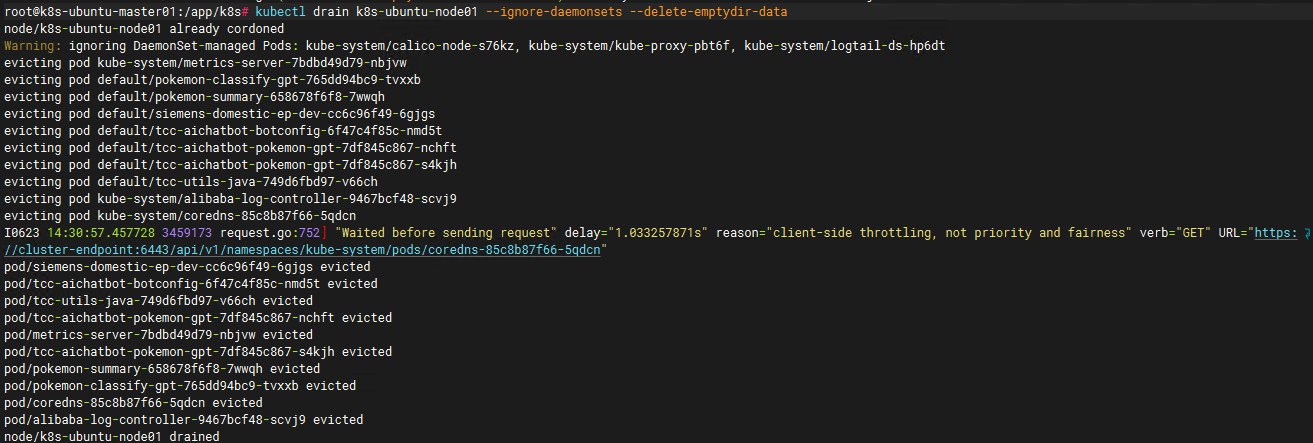
腾空了node01节点,接下来升级node01上的kubelet kubectl
sudo apt-mark unhold kubelet kubectl && \
sudo apt-get update && sudo apt-get install -y kubelet='1.33.2-*' kubectl='1.33.2-*' && \
sudo apt-mark hold kubelet kubectl
sudo systemctl daemon-reload
sudo systemctl restart kubelet
#恢复node01节点
kubectl uncordon k8s-ubuntu-node01
这样 工作节点1升级完成
其他工作节点依次执行
3)验证

验证证书成功自动更换
4)其他
查询日志
journalctl -xeu kubelet
发现calico和kube-proxy报错:Missing actuated resource record
解决记录:
需要重启calico和kube-proxy
#重启calico
delete -> apply部署网络插件calico时的yaml文件
#重启kube-proxy
kubectl delete pod -n kube-system -l k8s-app=kube-proxy
4.停机测试
将集群所有机器执行强制停机后启动
重启后集群及服务自动恢复
六.命令记录
1.kubeadm init
root@k8s-ubuntu-prd-master01:/app/k8s/cri-docker# kubeadm init \
--apiserver-advertise-address=172.31.0.61 \
--control-plane-endpoint=cluster-endpoint \
--image-repository=registry-vpc.cn-shanghai.aliyuncs.com/tcc_repo \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.168.0.0/16 \
--cri-socket=unix:///var/run/cri-dockerd.sock
[init] Using Kubernetes version: v1.33.1
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [cluster-endpoint k8s-ubuntu-prd-master01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 172.31.0.61]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-ubuntu-prd-master01 localhost] and IPs [172.31.0.61 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-ubuntu-prd-master01 localhost] and IPs [172.31.0.61 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "super-admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests"
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 501.632727ms
[control-plane-check] Waiting for healthy control plane components. This can take up to 4m0s
[control-plane-check] Checking kube-apiserver at https://172.31.0.61:6443/livez
[control-plane-check] Checking kube-controller-manager at https://127.0.0.1:10257/healthz
[control-plane-check] Checking kube-scheduler at https://127.0.0.1:10259/livez
[control-plane-check] kube-controller-manager is healthy after 1.5140283s
[control-plane-check] kube-scheduler is healthy after 2.485140357s
[control-plane-check] kube-apiserver is healthy after 4.001583813s
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node k8s-ubuntu-prd-master01 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node k8s-ubuntu-prd-master01 as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: yr1rm6.piw3j1fgkxtheu8r
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join cluster-endpoint:6443 --token yr1rm6.piw3j1fgkxtheu8r \
--discovery-token-ca-cert-hash sha256:f1cf75e6f0f901937f55dcdce4efe662680bb77e1ea5d409d33bd2f941ee4d97 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join cluster-endpoint:6443 --token yr1rm6.piw3j1fgkxtheu8r \
--discovery-token-ca-cert-hash sha256:f1cf75e6f0f901937f55dcdce4efe662680bb77e1ea5d409d33bd2f941ee4d97
2.kubeadm certs renew all
[root@master01 tcc_aichatbot_pokemon_gpt]# kubeadm certs renew all
[renew] Reading configuration from the cluster...
[renew] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
certificate embedded in the kubeconfig file for the admin to use and for kubeadm itself renewed
certificate for serving the Kubernetes API renewed
certificate the apiserver uses to access etcd renewed
certificate for the API server to connect to kubelet renewed
certificate embedded in the kubeconfig file for the controller manager to use renewed
certificate for liveness probes to healthcheck etcd renewed
certificate for etcd nodes to communicate with each other renewed
certificate for serving etcd renewed
certificate for the front proxy client renewed
certificate embedded in the kubeconfig file for the scheduler manager to use renewed
Done renewing certificates. You must restart the kube-apiserver, kube-controller-manager, kube-scheduler and etcd, so that they can use the new certificates.

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)