
华为云 和 阿里云 跨服务器搭建Hadoop集群
后端码匠Hadoop开发环境搭建CentOS6 7 8更换阿里yum源阿里云Linux安装镜像源地址:http://mirrors.aliyun.com配置方法:1.备份mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup2.下载新的CentOS-Base.repo到/etc/yum.repos.
目录
华为云 和 阿里云 跨服务器搭建Hadoop集群
说明
我有三个服务器:华为云102、阿里云103、阿里云104,跨服务器(机房)搭建一个hadoop集群

期间遇到的问题
CentOS6 7 8更换阿里yum源
阿里云Linux安装镜像源地址:http://mirrors.aliyun.com
配置方法:
1.备份
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2.下载 新的CentOS-Base.repo到/etc/yum.repos.d
CentOS 6
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
CentOS 7
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
CentOS 8
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-8.repo
执行 2 可能遇到
CentOS 7 下载yum源报错:正在解析主机 mirrors.aliyun.com (mirrors.aliyun.com)... 失败:未知的名称或服务。
解决方法
解决方法 :
登录root用户,用vim /etc/resolv.conf ,打开rsolv.conf,添加DNS地址
nameserver 8.8.8.8
nameserver 8.8.4.4
nameserver 223.5.5.5
nameserver 223.6.6.6
(nameserver 223.5.5.5 和 nameserver 223.6.6.6选择其中一个添加即可)
若未解决,查看网络配置,使用
ifconfig或ip addr查看网卡名,用 vim
/etc/sysconfig/network-scripts/ifcfg-(网卡名),查看网络参数是否正常
3.更新缓存
yum clean all && yum makecache
yum update -y
此时换源操作已完成
保障ping 百度能ping通
ping www.baidu.com.cn
配置到这发现我这边服务器是ping不通百度,能ping ip 但是域名不行 网上找了好多教程没有对的,(鄙视乱写的)
我自己的解决方案
vim /etc/resolv.conf
改为
nameserver 8.8.8.8
改完之后就可以ping通www.baidu.com
修改服务器名称
如果你需要的话,我目前是单台服务器,后期肯定会上多台服务器,方便日后的配置管理
vim /etc/hostname
快速开发: tab键提示命令
安装JDK
压缩包下载 关注后端码匠 回复 电脑环境获取 ,也可以自己去oracle官网下载
配置环境变量
vim /etc/profile
cd /etc/profile.d
vim my_env.sh
#JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
安装Hadoop
解压缩
tar -zxvf hadoop-3.1.1.tar.gz -C /opt/module/
pwd
/opt/module/hadoop-3.1.1
cd /etc/profile.d
vim my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
source /etc/profile
删除文件夹命令
rmdir dir
rm -rf dir/
测试分词统计
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount wcinput/ ./wcoutput
[root@linuxmxz hadoop-3.1.1]# cd wcoutput
[root@linuxmxz wcoutput]# ll
总用量 4
-rw-r--r-- 1 root root 41 4月 1 11:24 part-r-00000
-rw-r--r-- 1 root root 0 4月 1 11:24 _SUCCESS
[root@linuxmxz wcoutput]# cat part-r-00000
abnzhang 1
bobo 1
cls 2
mike 1
s 1
sss 1
编写集群分发脚本 xsync
scp(secure copy) 安全拷贝
scp可以实现服务器与服务器之间的数据拷贝(from server 1 to server2)
scp -r p d i r / pdir/ pdir/fname u s e r @ h o s t : user@host: user@host:pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
例如
本机向远程推数据
scp -r jdk1.8.0_212/ root@ip:/opt/module/
本机上远程拉数据
scp -r root@ip:/opt/module/hadoop-3.1.1 ./
本机操作另外两个机器进行传输
scp -r root@ip:/opt/module/* root@ip:/opt/module/
删除文件夹 rm -rf wcinput/ wcoutput/ 删除两个文件夹
rsync远程同步工具
rsync只对差异文件进行更新,scp是将所有文件都复制过去
基本语法
rsync -av p d i r / pdir/ pdir/fname u s e r @ user@ user@host: p d i r / pdir/ pdir/fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径名称
rsync -av hadoop-3.1.1/ root@ip:/opt/module/hadoop-3.1.1/
xsync 集群分发脚本
#! /bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if 【 $pcount -lt 1 】
then
echo No Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 递归遍历所有目录
for file in $@
do
#4 判断文件是否存在
if 【 -e $file 】
then
#5. 获取全路径
pdir=$(cd -P $(dirname $file); pwd)
echo pdir=$pdir
#6. 获取当前文件的名称
fname=$(basename $file)
echo fname=$fname
#7. 通过ssh执行命令:在$host主机上递归创建文件夹(如果存在该文件夹)
ssh $host "source /etc/profile;mkdir -p $pdir"
#8. 远程同步文件至$host主机的$USER用户的$pdir文件夹下
rsync -av $pdir/$fname $USER@$host:$pdir
else
echo $file Does Not Exists!
fi
done
done
无密访问
adduser codingce
passwd codingcec
chown -R codingce:codingce hadoop-3.1.1/
chmod 770 hadoop-3.1.1/
ls -al 查询所有的底层文件
ssh-keygen -t rsa
cat id_rsa #私钥
cat id_rsa_pub #公钥
# 把公钥放在 .ssh 文件夹
[codingce@linuxmxz .ssh]# ssh-copy-id 66.108.177.66
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
codingce@39.108.177.66's password:
Number of key(s) added: 1
# 操作之后就可以通过 ssh ip 直接访问改服务器 还得做下对自己免密码登录。
ssh ip
集群配置(着急直接看这)
集群部署规划
-
注意 NameNode 和 SecondaryNameNode 不要安装在同一台服务器上
-
ResourceManager 也很耗内存, 不要和 NameNode、SecondaryNameNode配置在同一台服务器上
配置host
hadoop102
就是这块踩了一下午坑
[root@linuxmxz hadoop-3.1.1]# vim /etc/hosts
#内网102 另外两台是外网
内网ip hadoop102
外网ip hadoop103
外网ip hadoop104
Hadoop103
[root@linuxmxz hadoop-3.1.1]# vim /etc/hosts
外网ip hadoop102
内网ip hadoop103
外网ip hadoop104
Hadoop104
[root@linuxmxz hadoop-3.1.1]# vim /etc/hosts
外网ip hadoop102
外网ip hadoop103
内网ip hadoop104
核心配置文件
核心配置文件 core-site.xml
[root@linuxmxz hadoop]# cd $HADOOP_HOME/etc/hadoop
[codingce@linuxmxz hadoop]$ vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.1/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 codingce -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>codingce</value>
</property>
</configuration>
HDFS 配置文件
配置 hdfs-site.xml
[codingce@linuxmxz hadoop]$ vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
YARN 配置文件
配置 yarn-site.xml
[codingce@linuxmxz hadoop]$ vim yarn-site.xml
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP RED_HOME</value>
</property>
</configuration>
MapReduce 配置文件
配置 mapred-site.xml
[codingce@linuxmxz hadoop]$ vim mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.1</value>
</property>
</configuration>
分发配置
# 一
[codingce@linuxmxz hadoop]$ rsync -av core-site.xml codingce@66.108.177.66:/opt/module/hadoop-3.1.1/etc/hadoop/
sending incremental file list
core-site.xml
sent 599 bytes received 47 bytes 1,292.00 bytes/sec
total size is 1,176 speedup is 1.82
[codingce@linuxmxz hadoop]$ rsync -av core-site.xml codingce@119.23.69.66:/opt/module/hadoop-3.1.1/etc/hadoop/
sending incremental file list
core-site.xml
sent 599 bytes received 47 bytes 1,292.00 bytes/sec
total size is 1,176 speedup is 1.82
# 二
[codingce@linuxmxz hadoop]$ rsync -av hdfs-site.xml codingce@119.23.69.66:/opt/module/hadoop-3.1.1/etc/hadoop/
sending incremental file list
hdfs-site.xml
sent 511 bytes received 47 bytes 1,116.00 bytes/sec
total size is 1,088 speedup is 1.95
[codingce@linuxmxz hadoop]$ rsync -av hdfs-site.xml codingce@66.108.177.66:/opt/module/hadoop-3.1.1/etc/hadoop/
sending incremental file list
hdfs-site.xml
sent 511 bytes received 47 bytes 1,116.00 bytes/sec
total size is 1,088 speedup is 1.95
# 三
[codingce@linuxmxz hadoop]$ rsync -av yarn-site.xml codingce@66.108.177.66:/opt/module/hadoop-3.1.1/etc/hadoop/
sending incremental file list
yarn-site.xml
sent 651 bytes received 47 bytes 1,396.00 bytes/sec
total size is 1,228 speedup is 1.76
[codingce@linuxmxz hadoop]$ rsync -av yarn-site.xml codingce@119.23.69.66:/opt/module/hadoop-3.1.1/etc/hadoop/
sending incremental file list
yarn-site.xml
sent 651 bytes received 47 bytes 1,396.00 bytes/sec
total size is 1,228 speedup is 1.76
# 四
[codingce@linuxmxz hadoop]$ rsync -av mapred-site.xml codingce@119.23.69.66:/opt/module/hadoop-3.1.1/etc/hadoop/
sending incremental file list
sent 73 bytes received 12 bytes 170.00 bytes/sec
total size is 1,340 speedup is 15.76
[codingce@linuxmxz hadoop]$ rsync -av mapred-site.xml codingce@66.108.177.66:/opt/module/hadoop-3.1.1/etc/hadoop/
sending incremental file list
sent 73 bytes received 12 bytes 170.00 bytes/sec
total size is 1,340 speedup is 15.76
群起集群
配置 workers
[codingce@linuxmxz hadoop]$ vim workers
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[codingce@linuxmxz hadoop]$ rsync -av workers codingce@39.108.177.65:/opt/module/hadoop-3.1.1/etc/hadoop/
sending incremental file list
workers
sent 143 bytes received 41 bytes 368.00 bytes/sec
total size is 30 speedup is 0.16
[codingce@linuxmxz hadoop]$ rsync -av workers codingce@119.23.69.213:/opt/module/hadoop-3.1.1/etc/hadoop/
sending incremental file list
workers
sent 143 bytes received 41 bytes 122.67 bytes/sec
total size is 30 speedup is 0.16
启动集群
(1) 如果集群是第一次启动,需要在 hadoop102 节点格式化 NameNode(注意:格式
化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找 不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停 止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式
化。)
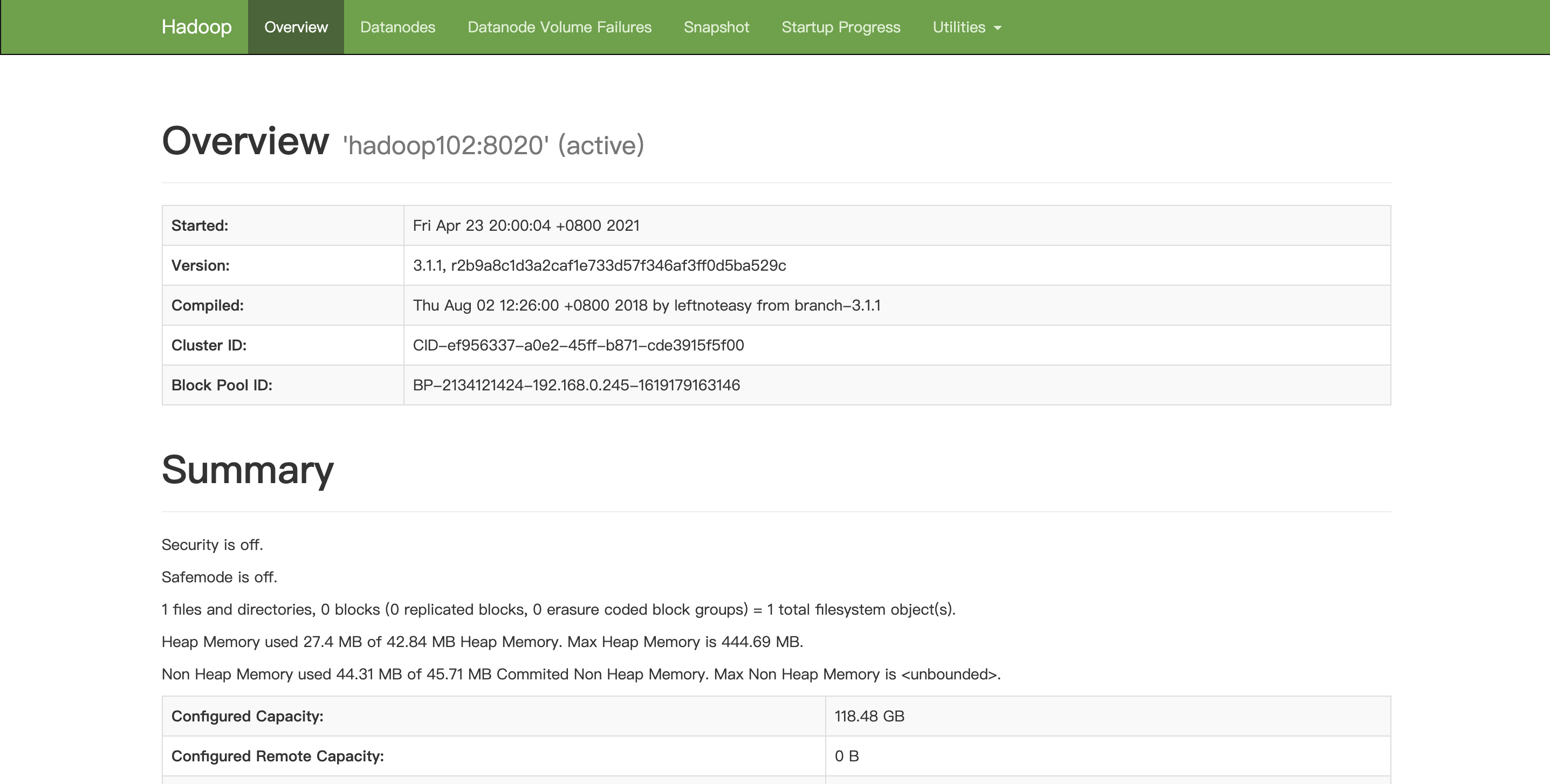
[codingce@linuxmxz hadoop-3.1.1]$ hdfs namenode -format
(2) 启动 HDFS
[codingce@linuxmxz hadoop-3.1.1]$ sbin/start-dfs.sh
Starting namenodes on [39.108.177.65]
Starting datanodes
39.108.177.65: datanode is running as process 17487. Stop it first.
119.23.69.213: datanode is running as process 7274. Stop it first.
Starting secondary namenodes [119.23.69.213]
[codingce@linuxmxz hadoop-3.1.1]$
[codingce@linuxmxz ~]$ jps
23621 NodeManager
23766 Jps
23339 DataNode
[codingce@linuxmxz hadoop-3.1.1]$ ssh 66.108.177.66
[codingce@hyf hadoop-3.1.1]$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[codingce@hyf ~]$ jps
19204 Jps
18533 NodeManager
17487 DataNode
[codingce@hyf ~]$ ssh 119.23.69.66
[codingce@zjx ~]$ jps
7824 NodeManager
7274 DataNode
7965 Jps
(3) 在配置了 ResourceManager 的节点(hadoop103)启动 YARN
sbin/start-dfs.sh
stop-dfs.sh
stop-yarn.sh
sbin/start-yarn.sh
netstat -tlpn 查询所有开放的ip
集群停止
停止hdfs,任意节点执行:
stop-dfs.sh
停止yarn,在yarn主节点执行:
stop-yarn.sh
如果是伪分布式环境,也可以直接执行:
stop-all.sh
单独启动某些进程
如果启动集群的过程,有些进程没有启动,可以尝试单独启动对应的进程:
单独启动hdfs的相关进程
hdfs --daemon start hdfs进程
hdfs --daemon start namenode
hdfs --daemon start datanode
hdfs --daemon start secondarynamenode
单独启动yarn的相关进程
yarn --daemon start yarn的相关进程
yarn --daemon start resourcemanager
yarn --daemon start nodemanager

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)