
增加attention的seq2seq和transformer有什么区别
seq2seq 是一个Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列。Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。很多自然语言处理任务,比如聊天机器人,机器翻译,自动文摘,智能问答等,传统的解决方案都是检索式(从候选集中选出答案),这对素材的完善程度要求很高。seq2seq模型
1.seq2seq是什么
seq2seq 是一个Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列。Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。
很多自然语言处理任务,比如聊天机器人,机器翻译,自动文摘,智能问答等,传统的解决方案都是检索式(从候选集中选出答案),这对素材的完善程度要求很高。seq2seq模型突破了传统的固定大小输入问题框架。采用序列到序列的模型,在NLP中是文本到文本的映射。其在各主流语言之间的相互翻译以及语音助手中人机短问快答的应用中有着非常好的表现。
RNN的encoder和decoder结构是什么?
2.增加attention的seq2seq
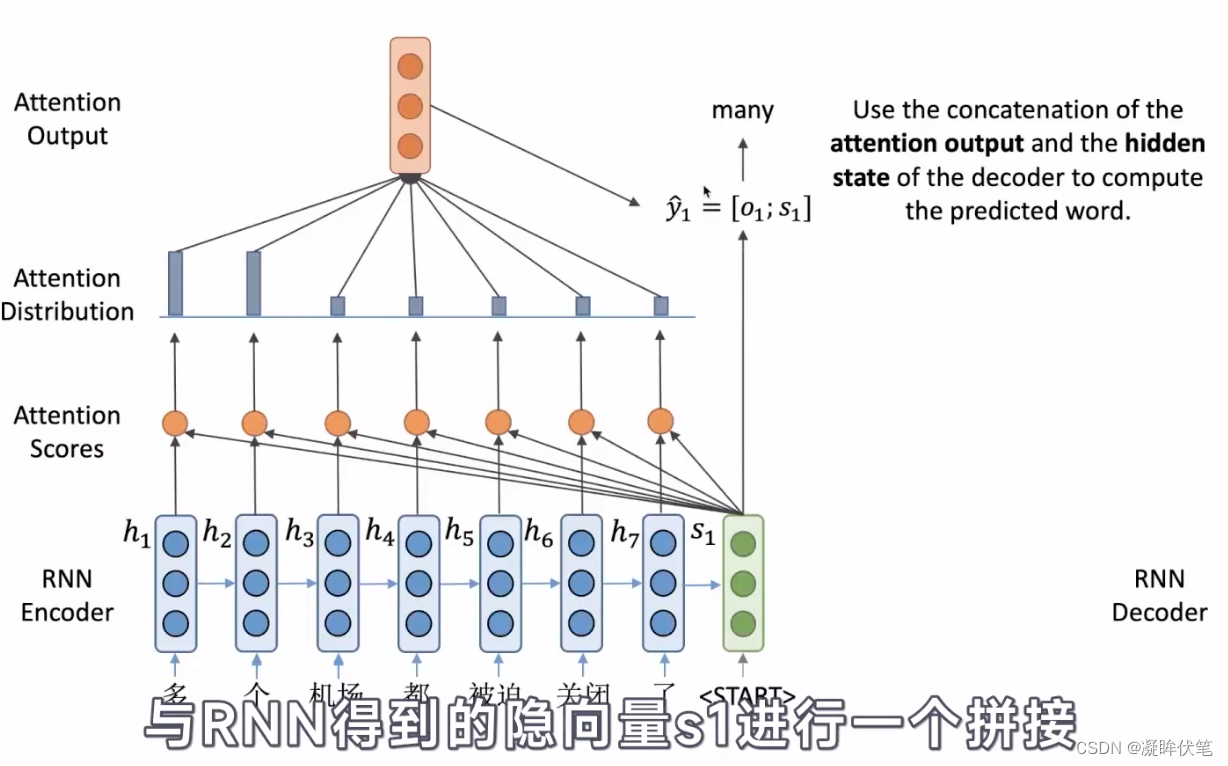
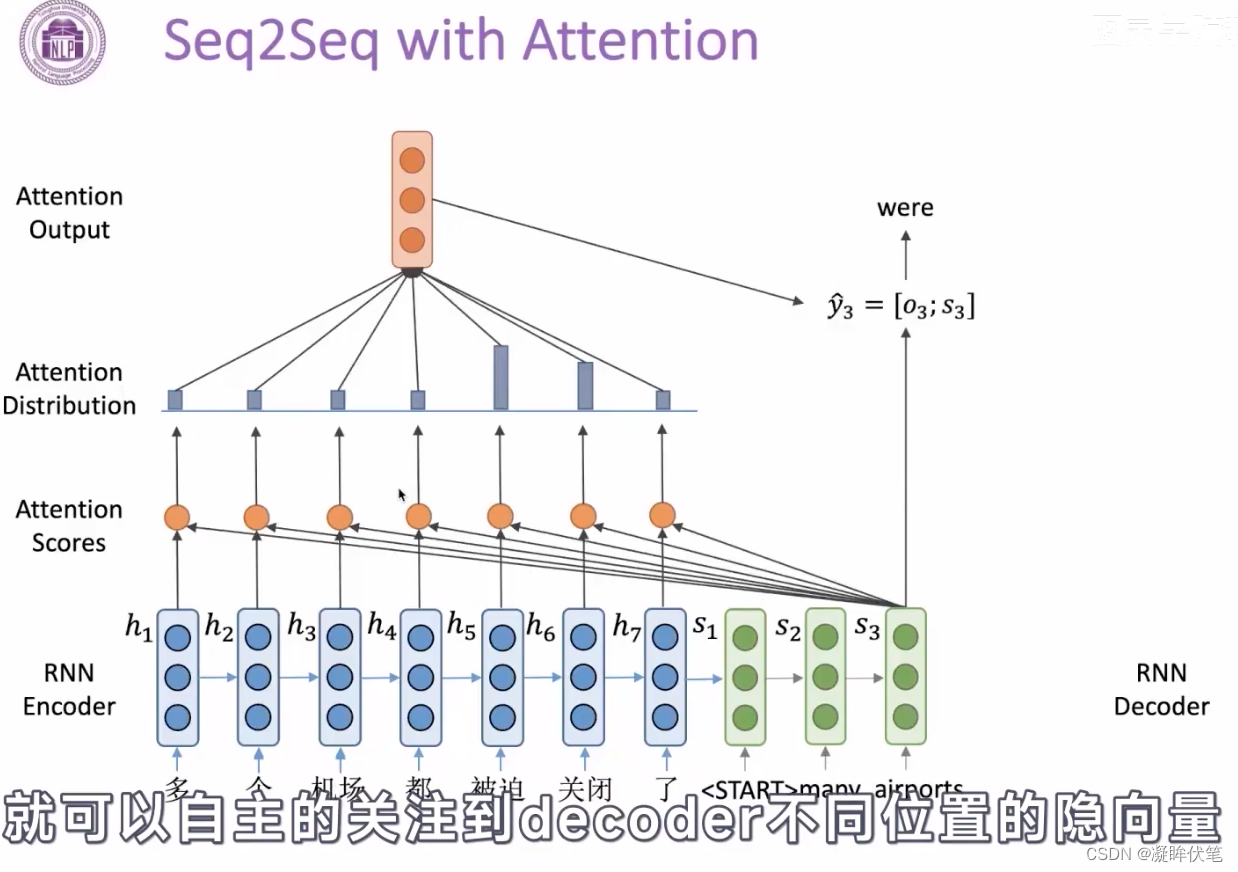
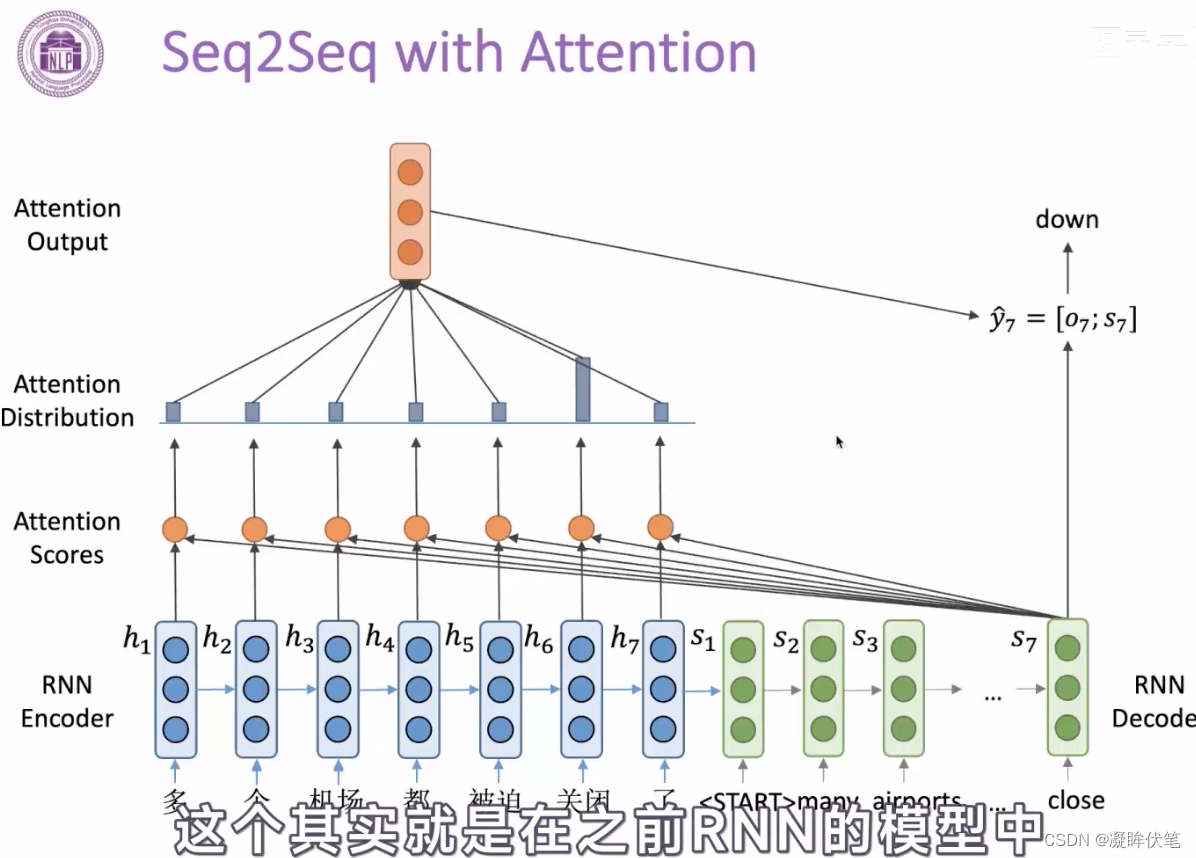
- 带注意力的解码器RNN接收的嵌入(embedding)和一个初始的解码器隐藏状态(hidden state)。
- RNN处理输入,产生输出和新的隐藏状态向量(h4),输出被摒弃不用。
- attention的步骤:使用编码器隐藏状态(hidden state)和h4向量来计算该时间步长的上下文向量(C4)。
- 把h4和C4拼接成一个向量。
- 把拼接后的向量连接全连接层和softmax完成解码
- 每个时间点上重复这个操作
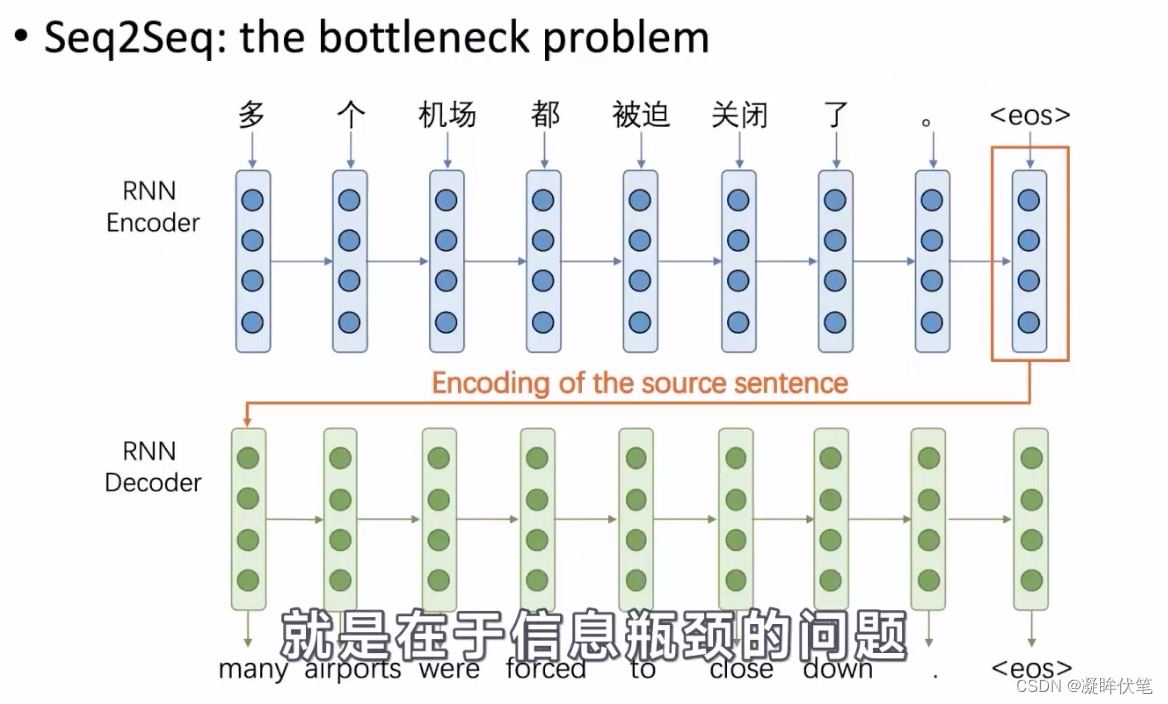
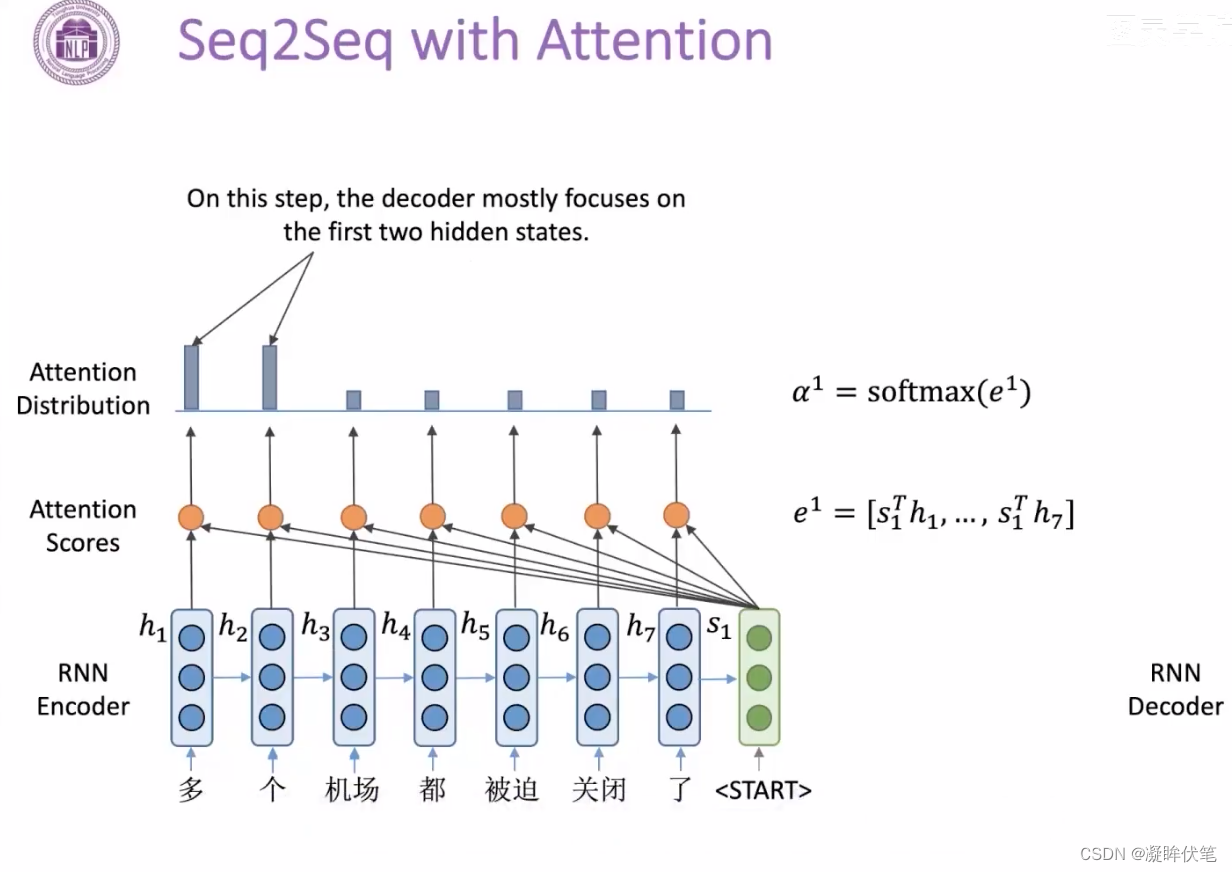
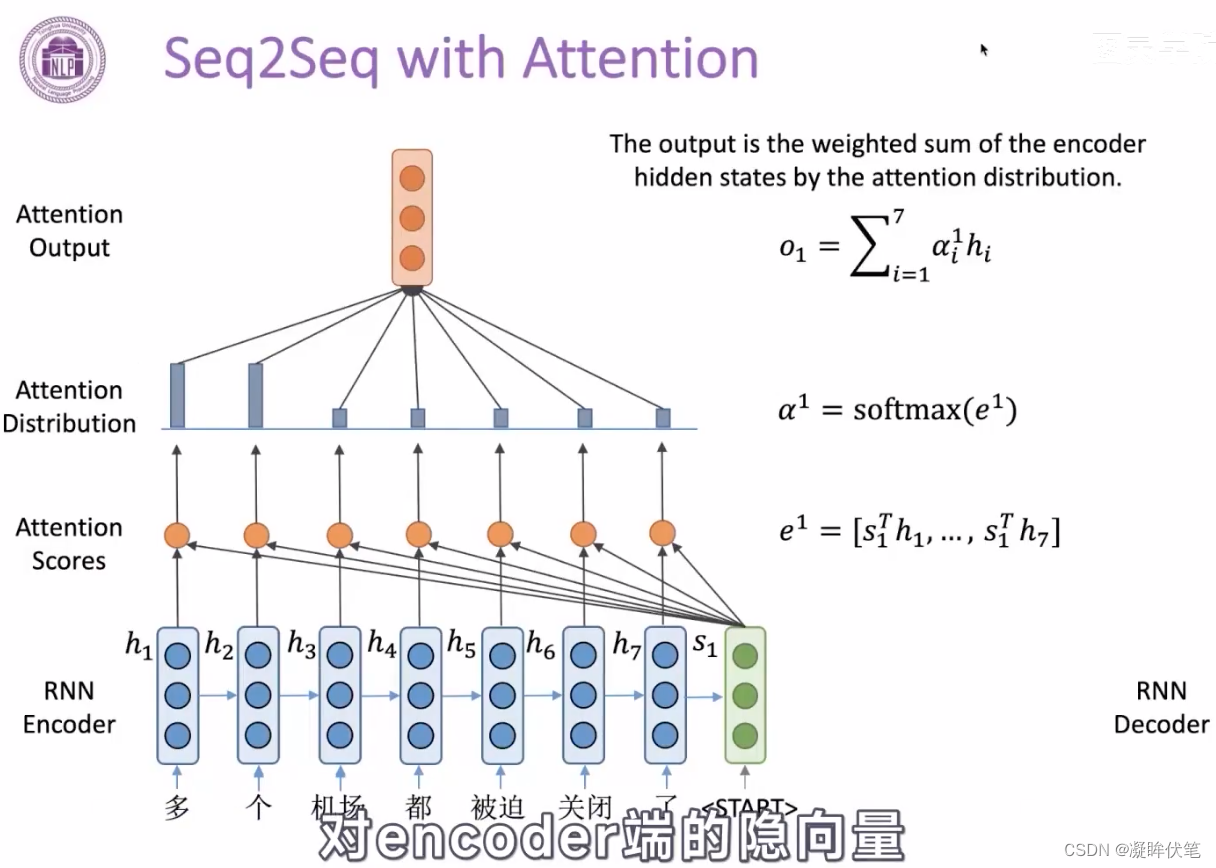
encoder之后的向量,不一定包含了所有信息,能让decoder输出。加入attention,让decoder自己选择需要什么信息,来缓解信息瓶颈的问题。

注意力机制,可以粗略地理解为是一种对于输入的信息,根据重要程度进行不同权重的加权处理(通常加权的权重来源于softmax后的结果)的机制



attention


attention计算的变体
1.通常情况下,query向量和value向量的维度相同时,可以使用直接点积相乘。
2.维度不同时,可以增加一个权重矩阵,让他们可以相乘

3.使用一层前馈神经网络,将两个向量,变成一个标量。

attention的优点
1.解决了encoder往decoder方向传递信息时的信息瓶颈的问题
2.缓解了rnn的梯度消失的问题,通过在encoder和decoder之间提供了一种直接连接的方式,防止了梯度在rnn中传播过程中过长,进而导致梯度消失
3.attention给神经网络增加了 一些可解释,通过权重大小,表示语义关系

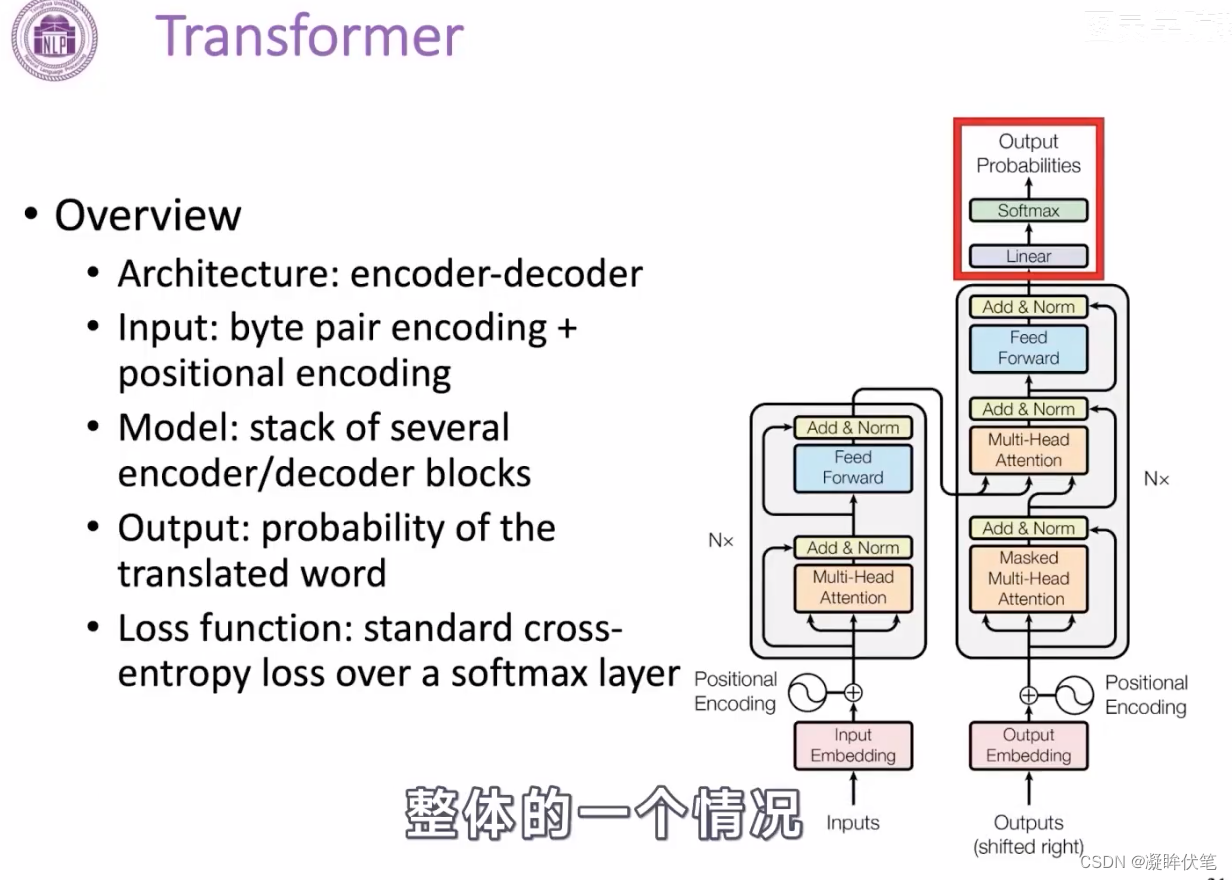
3.transformer
这是一个具体的模型结构。
为什么需要它?因为rnn是序列计算,顺序执行,不能并行。尽管后面用了GRU、lstm,rnn还需要加入attention,这一个机制不允许同时触达太多状态。计算速度上不去,是不行的。

整体情况:
通过堆叠的形式得到一个更深和表达能力更强的模型
输入编码:
之前RNN切词,通常使用空格等进行切分,这样切分存在的问题是跟词表长度有关,会导致词表数量很大,还会存在一些没出现在词表中的词;另外一个是一个单词的复数跟原单词可能表示不同的embedding。
这里全新的分词方式:BPE(byte pair encoding):



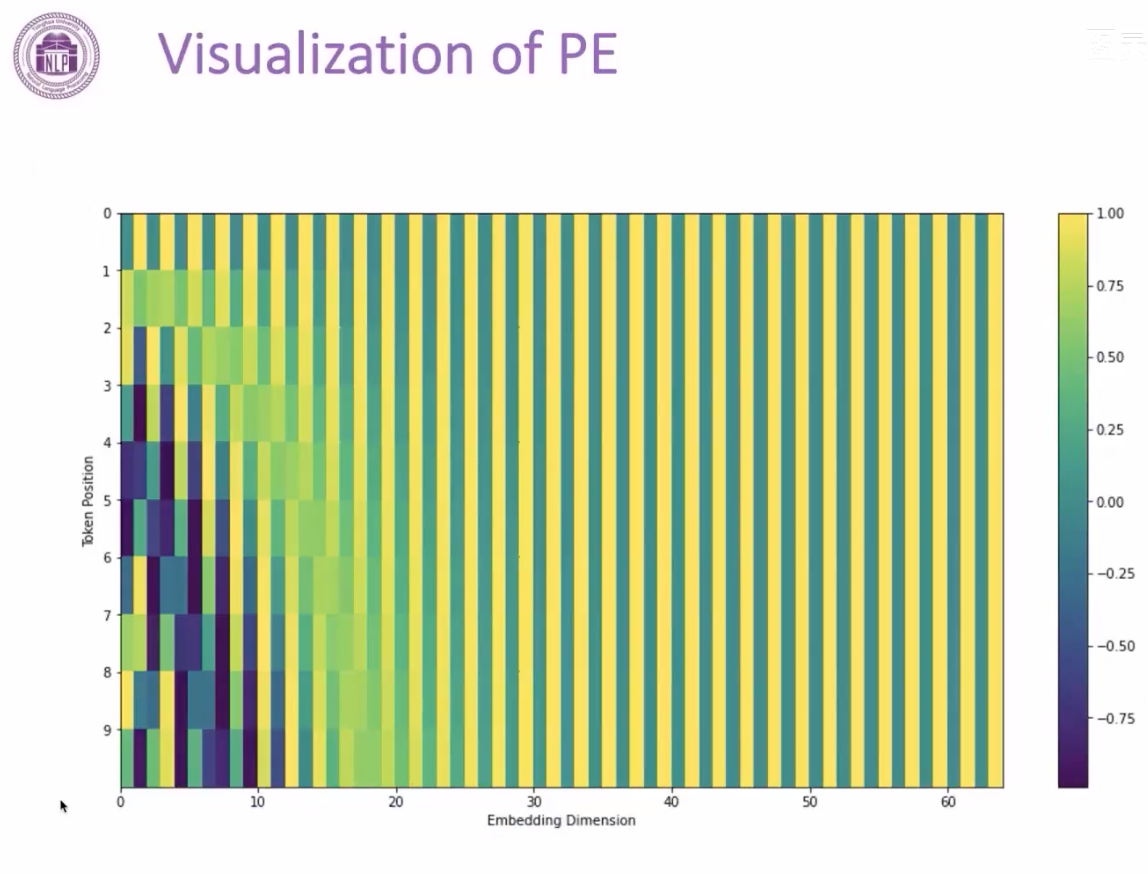
每个词的位置是取决于相对位置
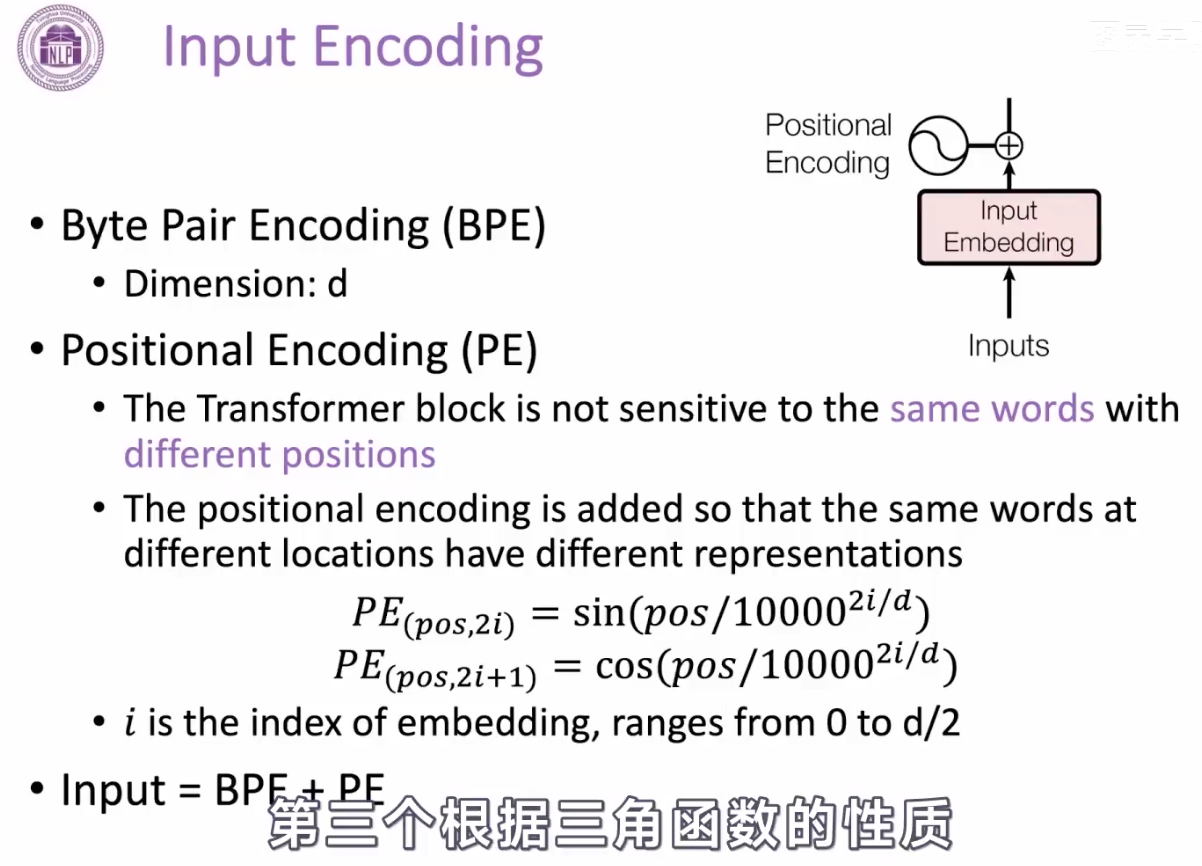
最终输入是BPE和PE按照位相加
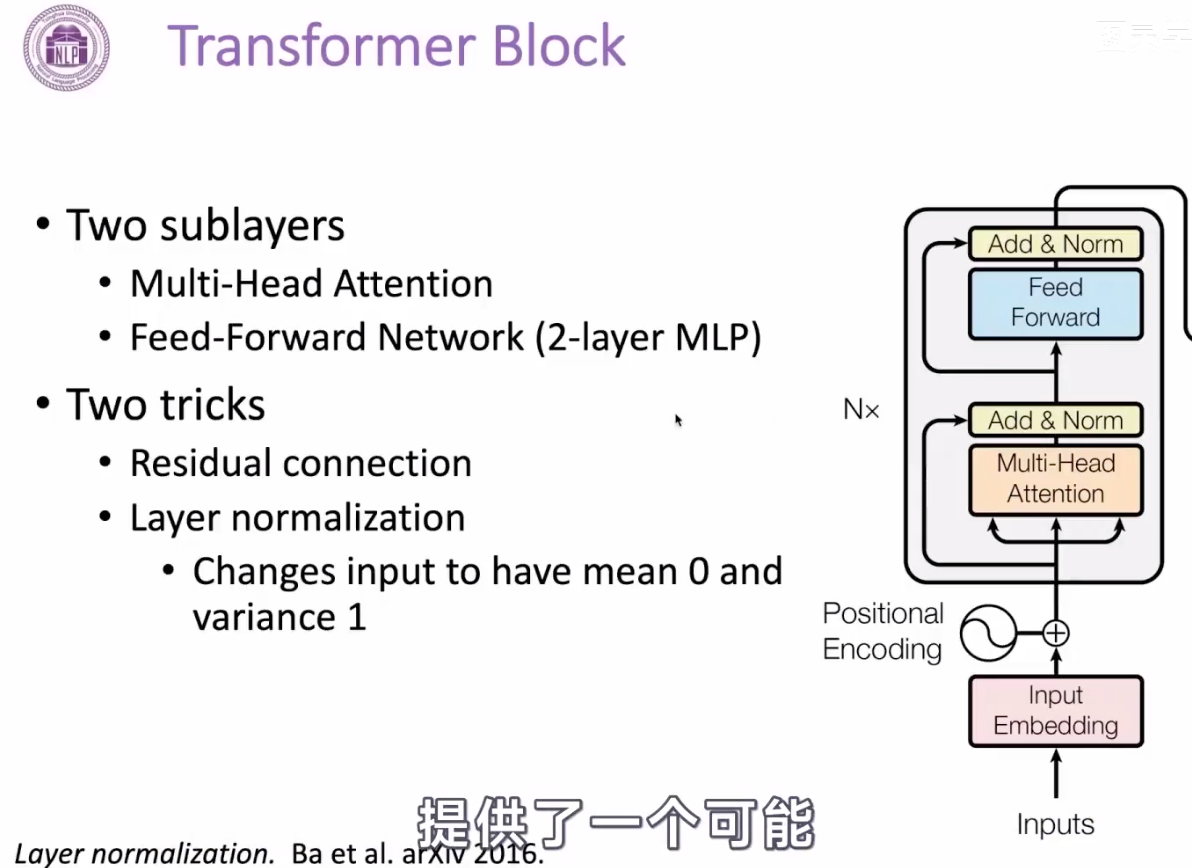
transformer 结构:
下面是encoder的结构,整体有两大块组成,分别是multi-head attention的网络,它是有两层mlp网络(带有激活函数的全连接网络);
除此之外,还有两个trick,一个是resnet的残差连接,这样避免网络过深之后,导致梯度消失的问题,这样的结构,在计算机视觉中起到很重要的作用,也为后面我们做更深的模型,提供了可能,保证了信息的传递。另一个是正则化,在隐向量处,将一个向量变成均值为0,方差为1的分布,这样也是为了防止梯度消失和梯度爆炸的问题。【留下一个问题:为什么这样的分布就不会有梯度消失或者爆炸的问题了呢?可以看看截图中的论文:layer normalization】
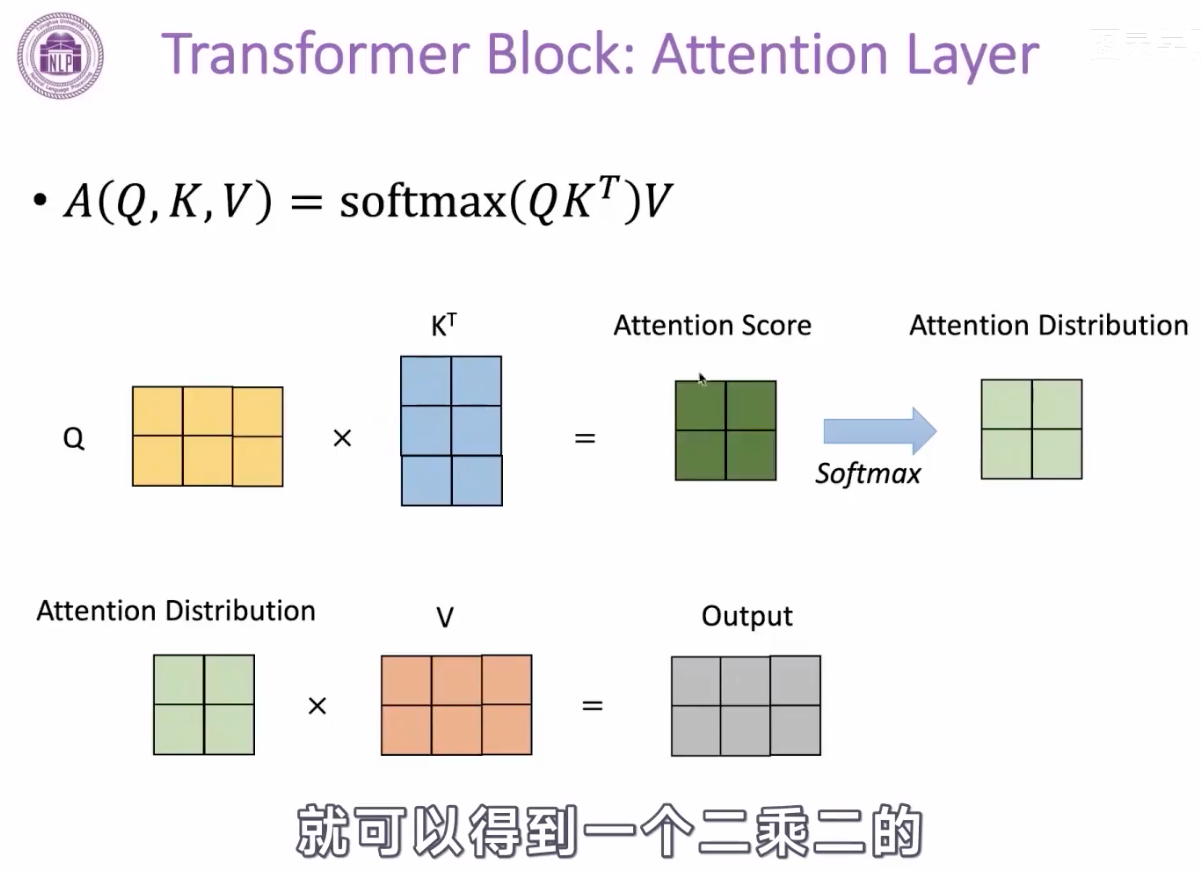
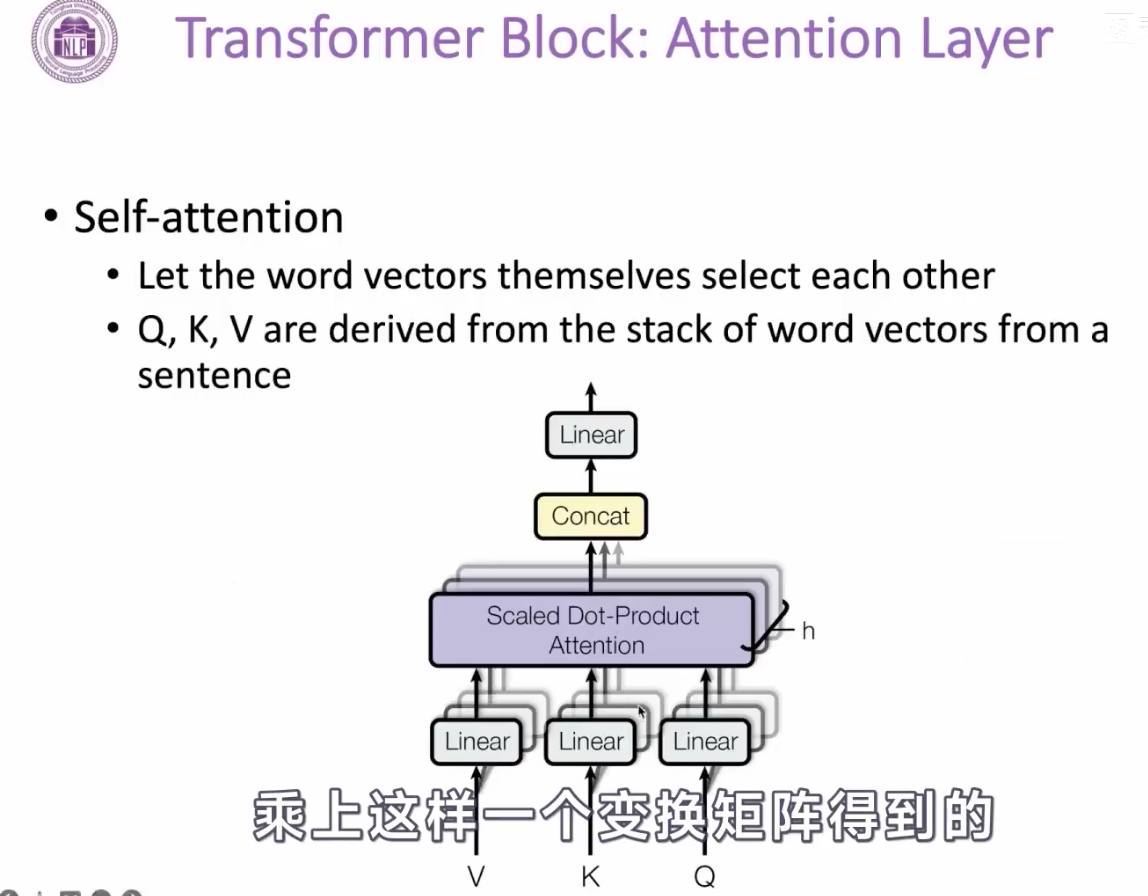
attention 机制
这里是计算的query向量和key向量的点击,作为attention值,然后再用softmax变成attention的加权分布,再跟Value向量相乘,起到加权的作用。【还是没整明白Q K V是哪里来的】
Q和K的计算可以并行,互不干扰,方便在gpu上并行计算。

按行计算softmax。
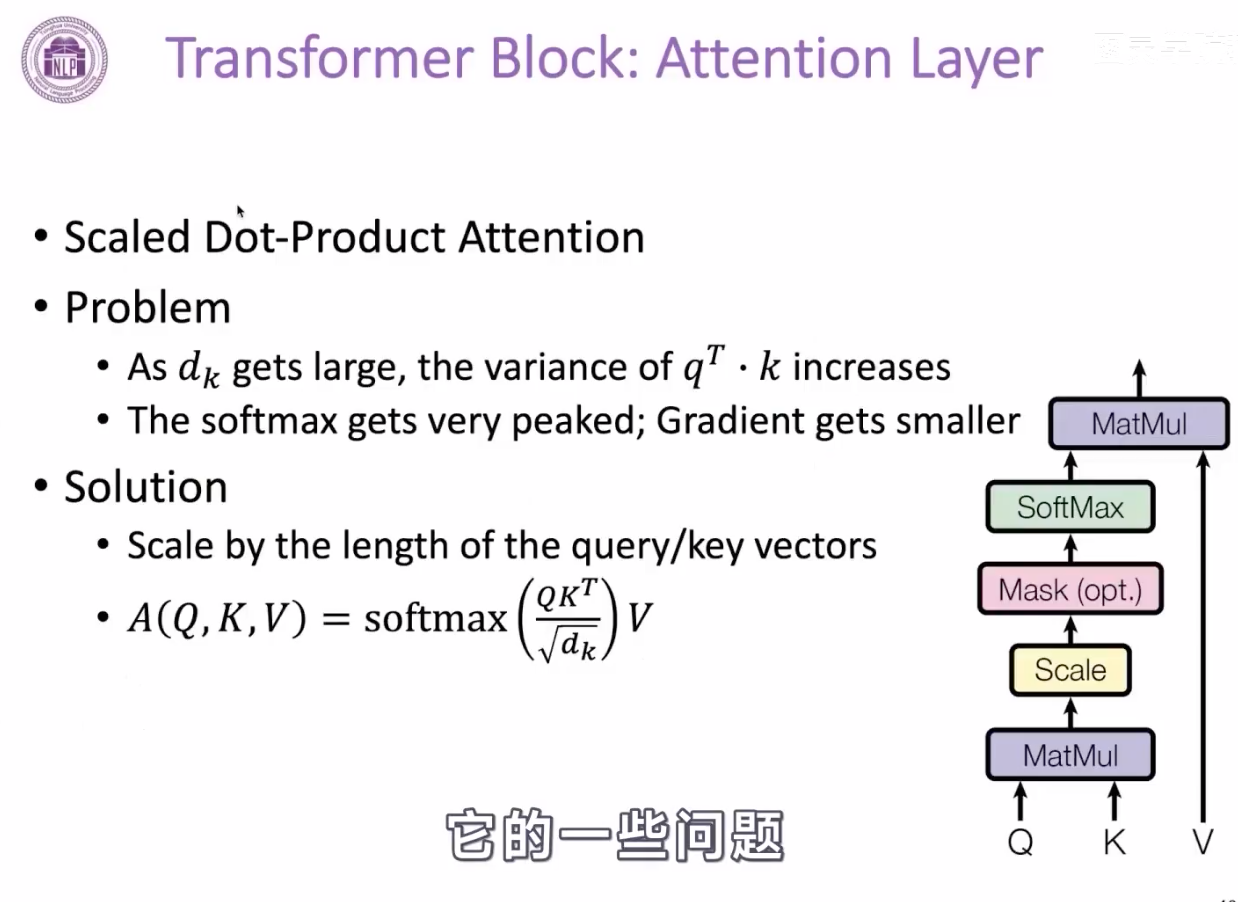
增加scale系数,
因为注意力的分数计算方式是 Q和K的点积,如果没有随着Q维度的增加,即dk增加,Q和K的点积的标量的方差,会随着dk维度的增加而增大,这就导致softmax的后的分布显得很尖锐,某个位置可能会变成1 ,其它大部分的位置都是0,这样导致的结果,可能是梯度越来越小,不利于参数更新。
解决方案是:Q*K^T之后,除以一个根号dk,使得这个注意力分数的方差依然是1,来防止上述问题的出现。
bert效果好的原因:
1.单向的语言模型,获取不到足够的信息去做语言预测任务,2双向的语言模型,会存在泄露信息,存在过拟合的问题,于是又了bert,随机mask掉15%的词,当做完形填空一样去预测这些mask的位置,15%的选择是trick-off的原则,学习mask的编码,相当于有监督学习;太少了,接受到了有监督信号太少,这样导致预训练的时间会变长。太大了,模型接受到的信号太少了,有用的文本就太少了,不足以支持我们还原出mask的词。

mask也会带来问题:下游任务不会出现mask,这就导致预训练和下游任务的数据分布不同,导致效果变差。
为了解决这个问题,80%的时间去mask一个词,10%的时间随机替换这个词,10%的时间用原来的文本。来解决预训练和finetuning差异的问题。
mask LM是词与词之间的一个任务
bert:next sentence prediction,是学习句子之间的关系
bert存在的问题:
预训练和finetuning之间存在gap;下游任务不出现mask;15%的词受到有监督,其它词不会受到监督;只能处理512个词;

bert的改进:
训练了一个更加稳定的模型;架构没动

预训练的时候,增加一个二分类判别器;预训练后,会丢弃到二分类

4区别
参考:
1.https://www.bilibili.com/video/BV1rS411F735?p=22&vd_source=2e3106349b9444378baccafe2d93e018
2.https://www.cnblogs.com/liuxiaochong/p/14399416.html

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)