
目标检测论文:FoveaBox: Beyond Anchor-based Object Detector及其PyTorch实现
FoveaBox: Beyond Anchor-based Object DetectorPDF: https://arxiv.org/pdf/1904.03797v1.pdfPyTorch代码: https://github.com/shanglianlm0525/ObjectDetection-networkPyTorch代码:
FoveaBox: Beyond Anchor-based Object Detector
PDF: https://arxiv.org/pdf/1904.03797v1.pdf
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
创新点:
1 提出了fovea的概念,重新定义正负样本,正样本比GT更小,负样本更远离GT.
2 FPN结构不同层负责不同尺度的目标.
3 Anchor-Free
1 FoveaBox网络结构:
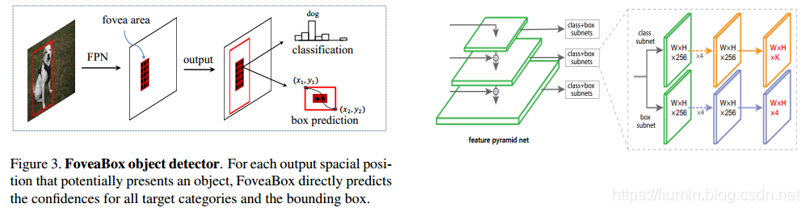
2 方法介绍
2-1 尺度划分 (Scale Assignment)
FPN输出5个层P3, P4, P5, P6, P7,每个层分别负责尺度为
的,目标,其中 S l S_{l} Sl分别为为 3 2 2 32^{2} 322, 6 4 2 64^{2} 642, 12 8 2 128^{2} 1282, 25 6 2 256^{2} 2562, 51 2 2 512^{2} 5122. η η η将控制每个层预测的目标尺度.如果 η ≤ 2 η \leq \sqrt{2} η≤2, 每层目标尺度不重叠,如果 η > 2 η>\sqrt{2} η>2,不同层预测的目标将会重叠,即同一个目标将会被多个层预测.
2-2 Fovea定义(Object Fovea)
因为目标真实的边框上的点通常远离目标中心,和背景较为接近,因此FoveaBox先计算出目标中心,然后对目标的真实边框向目标中心收缩一点,作为正样本, 同时向外扩展一点,作为负样本,中间的点忽略掉.
positive area (fovea)定义为:
其中
正负样本的划分 为σ1 = 0:3;和 σ2 = 0:4
2-3 预测边框(Box Prediction)
FoveaBox 回归每一个 cell 的坐标映射回原始图像之后和对应的 ground truth 的偏移量.
3 实验结果
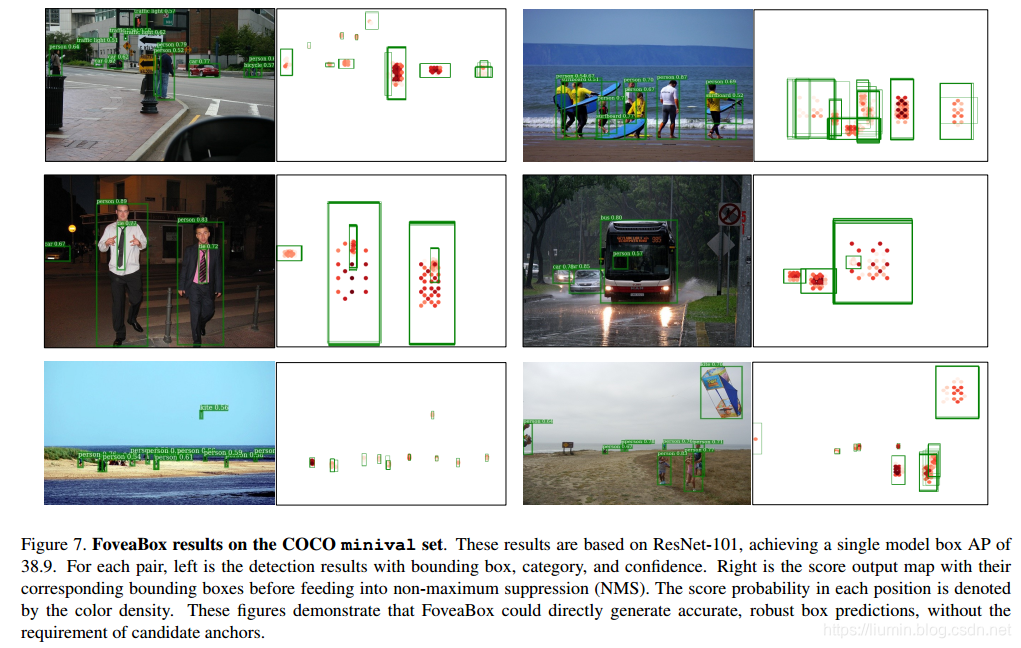
PyTorch代码:
import torch
import torch.nn as nn
import torchvision
def Conv3x3ReLU(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=3,stride=1,padding=1),
nn.ReLU6(inplace=True)
)
def locLayer(in_channels,out_channels):
return nn.Sequential(
Conv3x3ReLU(in_channels=in_channels, out_channels=in_channels),
Conv3x3ReLU(in_channels=in_channels, out_channels=in_channels),
Conv3x3ReLU(in_channels=in_channels, out_channels=in_channels),
Conv3x3ReLU(in_channels=in_channels, out_channels=in_channels),
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1),
)
def confLayer(in_channels,out_channels):
return nn.Sequential(
Conv3x3ReLU(in_channels=in_channels, out_channels=in_channels),
Conv3x3ReLU(in_channels=in_channels, out_channels=in_channels),
Conv3x3ReLU(in_channels=in_channels, out_channels=in_channels),
Conv3x3ReLU(in_channels=in_channels, out_channels=in_channels),
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1),
)
class FoveaBox(nn.Module):
def __init__(self, num_classes=80):
super(FoveaBox, self).__init__()
self.num_classes = num_classes
resnet = torchvision.models.resnet50()
layers = list(resnet.children())
self.layer1 = nn.Sequential(*layers[:5])
self.layer2 = nn.Sequential(*layers[5])
self.layer3 = nn.Sequential(*layers[6])
self.layer4 = nn.Sequential(*layers[7])
self.lateral5 = nn.Conv2d(in_channels=2048, out_channels=256, kernel_size=1)
self.lateral4 = nn.Conv2d(in_channels=1024, out_channels=256, kernel_size=1)
self.lateral3 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=1)
self.upsample4 = nn.ConvTranspose2d(in_channels=256, out_channels=256, kernel_size=4, stride=2, padding=1)
self.upsample3 = nn.ConvTranspose2d(in_channels=256, out_channels=256, kernel_size=4, stride=2, padding=1)
self.downsample6 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=2, padding=1)
self.downsample6_relu = nn.ReLU6(inplace=True)
self.downsample5 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=2, padding=1)
self.loc_layer3 = locLayer(in_channels=256,out_channels=4)
self.conf_layer3 = confLayer(in_channels=256,out_channels=self.num_classes)
self.loc_layer4 = locLayer(in_channels=256, out_channels=4)
self.conf_layer4 = confLayer(in_channels=256, out_channels=self.num_classes)
self.loc_layer5 = locLayer(in_channels=256, out_channels=4)
self.conf_layer5 = confLayer(in_channels=256, out_channels=self.num_classes)
self.loc_layer6 = locLayer(in_channels=256, out_channels=4)
self.conf_layer6 = confLayer(in_channels=256, out_channels=self.num_classes)
self.loc_layer7 = locLayer(in_channels=256, out_channels=4)
self.conf_layer7 = confLayer(in_channels=256, out_channels=self.num_classes)
self.init_params()
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.layer1(x)
c3 =x = self.layer2(x)
c4 =x = self.layer3(x)
c5 = x = self.layer4(x)
p5 = self.lateral5(c5)
p4 = self.upsample4(p5) + self.lateral4(c4)
p3 = self.upsample3(p4) + self.lateral3(c3)
p6 = self.downsample5(p5)
p7 = self.downsample6_relu(self.downsample6(p6))
loc3 = self.loc_layer3(p3)
conf3 = self.conf_layer3(p3)
loc4 = self.loc_layer4(p4)
conf4 = self.conf_layer4(p4)
loc5 = self.loc_layer5(p5)
conf5 = self.conf_layer5(p5)
loc6 = self.loc_layer6(p6)
conf6 = self.conf_layer6(p6)
loc7 = self.loc_layer7(p7)
conf7 = self.conf_layer7(p7)
locs = torch.cat([loc3.permute(0, 2, 3, 1).contiguous().view(loc3.size(0), -1),
loc4.permute(0, 2, 3, 1).contiguous().view(loc4.size(0), -1),
loc5.permute(0, 2, 3, 1).contiguous().view(loc5.size(0), -1),
loc6.permute(0, 2, 3, 1).contiguous().view(loc6.size(0), -1),
loc7.permute(0, 2, 3, 1).contiguous().view(loc7.size(0), -1)],dim=1)
confs = torch.cat([conf3.permute(0, 2, 3, 1).contiguous().view(conf3.size(0), -1),
conf4.permute(0, 2, 3, 1).contiguous().view(conf4.size(0), -1),
conf5.permute(0, 2, 3, 1).contiguous().view(conf5.size(0), -1),
conf6.permute(0, 2, 3, 1).contiguous().view(conf6.size(0), -1),
conf7.permute(0, 2, 3, 1).contiguous().view(conf7.size(0), -1),], dim=1)
out = (locs, confs)
return out
if __name__ == '__main__':
model = FoveaBox()
print(model)
input = torch.randn(1, 3, 800, 800)
out = model(input)
print(out[0].shape)
print(out[1].shape)

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 1
1 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)