
毕业设计:基于python的旅游评论情感分析系统
毕业设计:基于python的旅游评论情感分析系统利用自然语言处理技术和机器学习算法对旅游评论进行情感倾向分析。能够实现对旅游评论的高效、准确情感分析,为旅游企业和消费者提供有价值的信息。为计算机毕业设计提供了一个创新的方向,结合了深度学习和自然语言处理技术,为毕业生提供了一个有意义的研究课题。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,这是一个具有挑战性和创新性的研究课题。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于python的旅游评论情感分析系统
项目背景
随着在线旅游平台的普及,用户对旅游目的地、酒店、景点等发表的评论日益增多。这些评论中蕴含了丰富的情感信息,对于旅游企业和消费者都具有极高的价值。然而,人工分析大量评论既耗时又低效。旅游评论情感分析系统能够自动分析评论中的情感倾向,为旅游企业提供市场洞察,帮助消费者做出更明智的选择。此外,该系统还有助于推动情感分析技术在旅游领域的应用和发展。
设计思路
基于情感词典的情感分类方法主要依赖于构建情感词典,通过引入多种类情感词、表情符号以及领域特定的情感词典等方法来改进情感词典的规模和准确性。此外,一些研究还尝试基于深度学习框架构建领域特定的情感词典。还有人通过构建歧义词搭配词典来解决歧义词对情感分类准确性的影响。此外,基于机器学习的情感分类方法利用大量标注和未标注语料,使用机器学习算法抽取文本特征,并识别用户文本的情感类别。常用的机器学习算法包括支持向量机(SVM)和朴素贝叶斯(NB)。这些方法在不同领域和任务中得到了广泛应用,如情感分析、舆情挖掘和用户评论评价等。
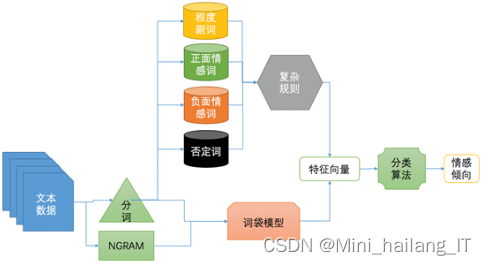
LSTM旨在解决传统神经网络中长期依赖问题所导致的梯度消失或爆炸现象。LSTM网络由一个基本单元组成,其中包括三个门:遗忘门(forget gate),输入门(input gate)和输出门(output gate)。这些门控制了信息的流动,并决定哪些信息将被保留、哪些信息将被遗忘。LSTM的核心是细胞状态(Cell State),它类似于一个内部记忆单元,用来记录和传递网络中的信息。
LSTM是一种具有门控机制和细胞状态的神经网络结构,用于解决传统神经网络中长期依赖问题。通过使用遗忘门、输入门和输出门,LSTM网络能够选择性地保留或遗忘信息,并利用细胞状态在长序列中传递重要的信息。这样,LSTM网络能够更好地处理长期依赖关系,避免梯度消失或爆炸的问题。
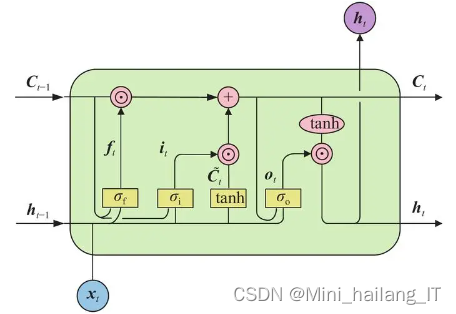
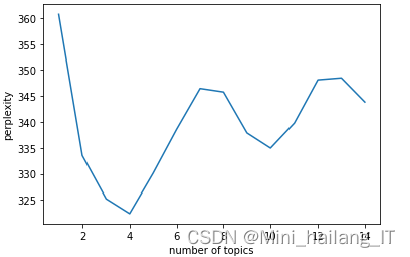
LDA(Latent Dirichlet Allocation)模型是一种生成性概率模型,用于对文本集合进行建模和分析。该模型假设每个文本由多项式的主题分布表示,每个主题由多项式的词分布表示。LDA引入了Dirichlet分布作为主题分布和词分布的先验分布,以更好地处理学习主题模型时的过拟合效应。
LDA的生成过程如下:首先,为每个文本随机生成一个主题分布,然后根据主题分布,在文本的每个位置随机生成一个主题,接着根据主题的词分布,在该位置生成一个随机的词。这个过程对所有文本重复进行。LDA概率图模型,其中实心节点代表观察变量,空心节点代表潜在变量,有向边代表概率关系,矩形表示重复的次数。
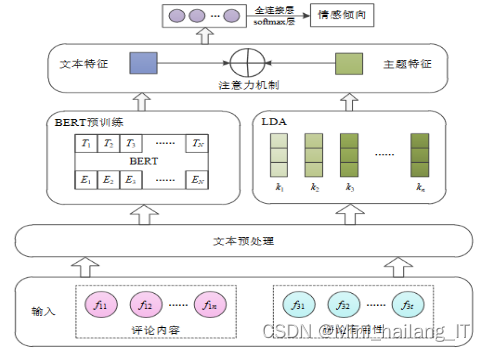
深度学习在自然语言处理领域得到广泛应用,成功解决了文本分类、情感分析、话题检测等问题。由于计算机无法直接处理文本字符串,预处理是必要的。在文本处理中,首先结合文本内容与评论有用性进行筛选,去除低有用性评论。然后,对筛选后的评论文本进行预处理,使用不同的模型进行特征抽取,以便进一步分析和应用。深度学习在处理文本数据方面提供了强大的能力,使得文本分析和应用变得更加准确和高效。
数据集
为了训练和优化基于Python的旅游评论情感分析系统,一个高质量且多样化的数据集至关重要。首先,我们从多个在线旅游平台爬取了大量的用户评论数据,涵盖了不同目的地、酒店、景点等。然后,我们对这些评论进行了预处理,包括去除无关信息、分词、去除停用词等步骤。接下来,我们通过人工标注的方式,为每条评论打上了情感标签,包括正面、负面和中性。为了确保标注的准确性,我们还进行了多轮校验和修正。
# 读取评论数据集
data = pd.read_csv('travel_reviews.csv')
# 预处理数据
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
# 去除无关信息
text = text.lower().strip()
# 分词
tokens = word_tokenize(text)
# 去除停用词
filtered_tokens = [token for token in tokens if token not in stop_words]
# 拼接为字符串
preprocessed_text = ' '.join(filtered_tokens)
return preprocessed_text
data['preprocessed_text'] = data['text'].apply(preprocess_text)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data['preprocessed_text'], data['sentiment'], test_size=0.2, random_state=42)
数据扩充是一种有效的技术,用于增加数据集的多样性和规模,从而提高模型的泛化能力。在基于Python的旅游评论情感分析系统的研究中,我们采用了多种数据扩充方法来增强数据集的丰富性。首先,我们通过同义词替换、随机插入、随机删除等方式对原始评论进行了文本层面的扩充。此外,我们还利用情感词典和规则,对评论的情感标签进行了调整,以模拟更多的情感倾向。这些数据扩充操作不仅增加了数据集的多样性,还为模型的训练提供了更多的有效数据,有助于提高情感分析的准确性和鲁棒性。
# 读取评论数据集
data = pd.read_csv('travel_reviews.csv')
# 数据扩充函数:同义词替换
def synonym_replacement(text, n=1):
tokens = word_tokenize(text)
new_tokens = list(tokens)
for _ in range(n):
for i in range(len(tokens)):
synsets = wordnet.synsets(tokens[i])
if synsets:
synonym = random.choice(synsets).lemmas()[0].name()
new_tokens[i] = synonym
new_text = ' '.join(new_tokens)
return new_text
# 数据扩充函数:随机插入
def random_insertion(text, n=1):
tokens = word_tokenize(text)
new_tokens = list(tokens)
for _ in range(n):
word = random.choice(tokens)
new_tokens.insert(random.randrange(len(new_tokens)), word)
new_text = ' '.join(new_tokens)
return new_text模型训练
实验环境使用Windows操作系统,并利用Python作为主要的编程语言进行算法和模型的实现。使用PyTorch作为深度学习框架,构建和训练神经网络模型。借助Pandas等库,完成数据的加载、处理和转换。这样的实验环境提供了一个方便和高效的平台,用于开发和测试基于深度学习的交通灯识别算法系统。

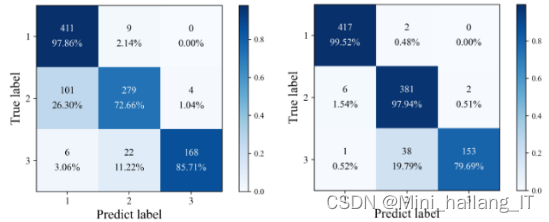
混淆矩阵是评估分类模型性能的一种常用工具,可以用于计算多个评价指标,包括准确率、精确率、召回率和F1值。对于多分类模型,可以将其看作多个二分类问题。针对每个类别,将该类别视为正类,其他类别视为负类,然后计算出各自的准确率、精确率、召回率和F1值。这样就可以得到每个类别的评价指标。
为了综合评估整个多分类模型的性能,可以对各个类别的评价指标进行平均计算。常见的平均计算方式包括宏平均(Macro-average)和微平均(Micro-average)。
- 宏平均:对每个类别的评价指标进行求平均,不考虑类别样本的不平衡性,每个类别被视为同等重要。宏平均适用于各个类别的样本数量相对均衡的情况。
- 微平均:将所有类别的预测结果合并起来,计算整体的准确率、精确率、召回率和F1值。微平均适用于类别样本数量不平衡的情况,对于少数类别的性能更加敏感。
更多帮助

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 46
46 0
0- 0



 已为社区贡献159条内容
已为社区贡献159条内容

所有评论(0)