
华为云Flexus+DeepSeek征文|华为云ModelArts Studio在线商用服DeepSeek与WebLLM Chat本地AI服务实战对比
华为云Flexus+DeepSeek征文|华为云ModelArts Studio在线商用服DeepSeek与WebLLM Chat本地AI服务实战对比
华为云Flexus+DeepSeek征文|华为云ModelArts Studio在线商用服务DeepSeek与WebLLM Chat本地AI服务实战对比
前言
在当今快速发展的AI技术领域,选择合适的AI服务部署方式对于提升业务效率和创新能力至关重要。本文旨在通过实际案例对比华为云ModelArts Studio平台上的DeepSeek在线商用服务与本地部署的WebLLM Chat AI服务,探讨两者在性能、成本效益及易用性方面的差异。希望通过此次实战对比,为技术选型提供有价值的参考依据。
一、华为云Flexus X实例介绍
1.1 华为云Flexus X实例介绍
华为云Flexus云服务器X实例是新一代面向中小企业和开发者的柔性算力云服务器。它能够智能感知业务负载的变化,自动调整资源配置。这款服务器特别适用于中低负载的应用场景,例如电商直播、企业网站建设、开发测试环境、游戏服务器以及音视频服务等。X实例的设计理念旨在为用户提供更加灵活和高效的计算资源管理方式。通过智能调整,它可以更好地满足不同业务的需求,提高资源利用率。
1.2 华为云Flexus X实例特点
🔍 Flexus云服务器X实例主要特点
柔性算力随心配:根据业务负载与内存峰值动态推荐算力规格,提升资源利用率,减少浪费。一直加速一直快:搭载X-Turbo加速技术和大模型智能调度,应用性能最高可达业界同规格6倍。越用越省降本多:按算力规格精准计费,结合智能推荐实现持续优化成本。安全可靠更放心:提供旗舰级安全保障,支持跨可用区 99.995% 高可用性,通过100+项全球权威合规认证。适用场景广泛:覆盖高科技、零售、金融、游戏等行业大多数通用工作负载场景。
二、WebLLM Chat介绍
2.1 项目介绍
WebLLM Chat是一个开创性的开源AI聊天界面,结合了 WebLLM 的强大本地语言模型运行能力与 NextChat 的优雅用户交互设计。它利用 WebGPU 技术,在用户的浏览器中实现无需依赖云端服务的大语言模型(LLMs)本地运行,真正做到隐私保护、离线使用和高度可定制。作为 MLC.ai 家族的重要组成部分,WebLLM Chat 致力于将高性能 AI 聊天体验带入每一个用户的桌面。
2.2 主要特点
- 🧠 浏览器原生AI:通过 WebGPU 加速,在浏览器中本地运行大型语言模型,无需云服务支持。
- 🔐 隐私保障:所有对话数据保留在本地设备,完全不上传服务器,确保用户信息安全。
- 📶 离线访问:完成初始加载后,即使断网也能继续使用 AI 聊天功能。
- 🖼️ 视觉模型支持:支持上传图片进行视觉理解,实现图文并茂的交互体验。
- 🎨 用户友好界面:采用响应式设计,支持深色模式和 Markdown 格式,界面简洁且功能丰富。
- 🔧 自定义模型支持:可通过 MLC-LLM 接入本地自定义语言模型,灵活扩展性强。
- 📦 开源可定制:项目完全开源,便于开发者基于其框架构建个性化 AI 应用。
2.3 适用场景
适用于希望在本地环境中安全、高效地使用大语言模型的个人用户、教育工作者、研究人员以及企业团队,尤其适合注重隐私保护、网络隔离环境或低资源场景下的AI应用部署。
三、本次实践介绍
3.1 本次实践介绍
- 本次实践基于个人测试环境,依托华为云 Flexus X 实例与 ModelArts Studio 平台,开展对 DeepSeek 在线商用服务的部署与调用测试。
- 同时结合本地 AI 服务 WebLLM Chat 进行功能对比,从响应速度、部署难度、资源占用等维度进行实战评测与分析。
3.2 环境规划
| 云厂商 | 云服务器 | 云服务 | 部署项目 | 备注 |
|---|---|---|---|---|
| 华为云 | 华为云Flexus X实例 | MaaS平台提供的DeepSeek商用服务 | WebLLM Chat | —— |
| 云服务器 | IP地址 | 操作系统版本 | 内核版本 | Docker版本 | 部署项目 | 商用服务大模型 |
|---|---|---|---|---|---|---|
| 华为云Flexus X实例 | 192.168.0.42 | Ubuntu 24.04.1 LTS | 6.8.0-49-generic | v 28.2.2 | WebLLM Chat | 华为云DeepSeek-V3-32K等 |
四、实践环境准备工作
4.1 购买Flexus云服务器X实例配置
我们在华为云官网首页,精选推荐模块中,可以看到Flexus云服务器X实例,点击进入Flexus云服务器X实例主页。
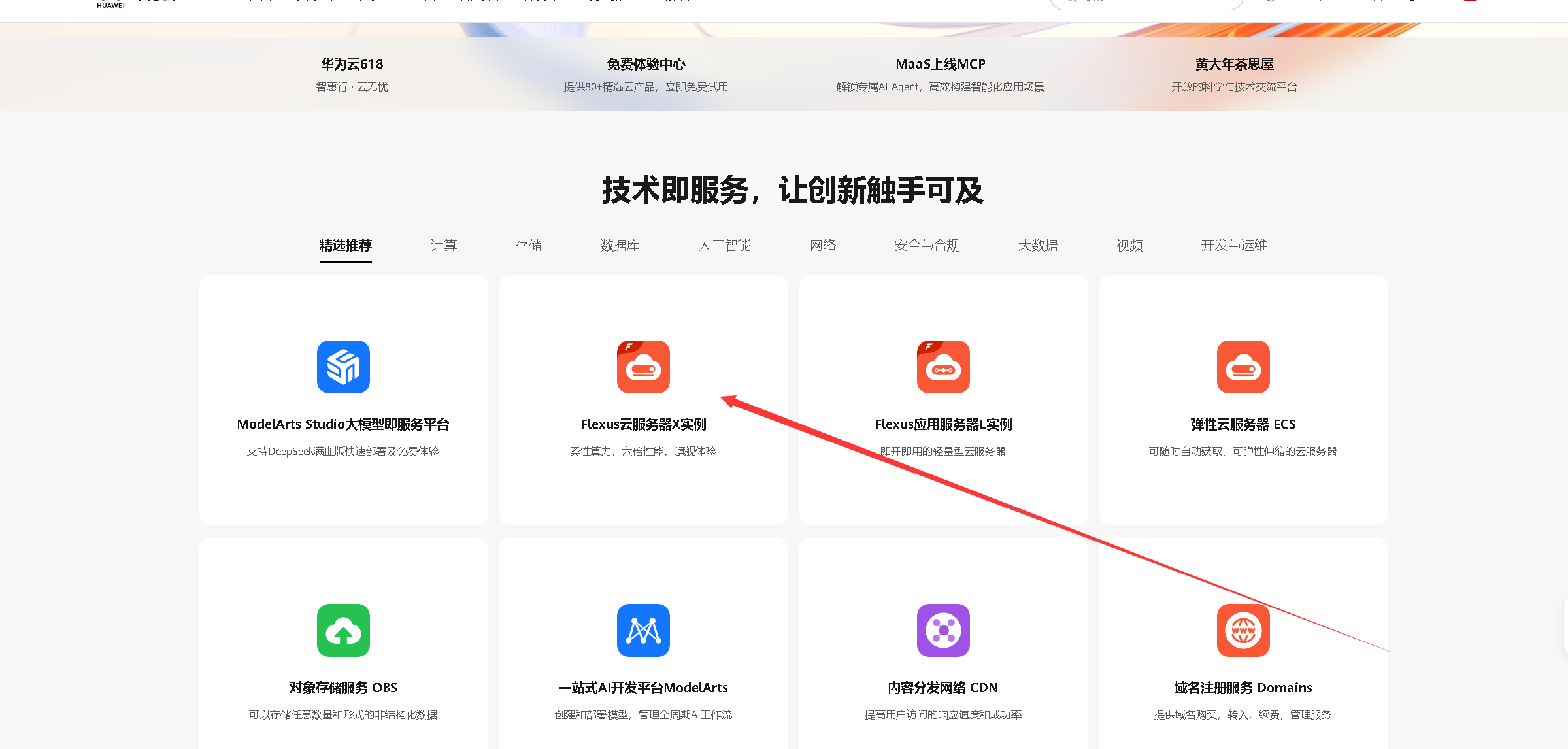
点击页面中的“购买”选项,进入Flexus云服务器X实例购买页面。
基础配置参考:购买时可参考以下基础配置进行选择。
| 项目 | 配置说明 |
|---|---|
| 计费模式 | 按需计费 |
| 区域 | 西南-贵阳一,可用区:随机即可 |
| 实例规格 | 2vCPUs | 4GiB |
| 性能模式 | 开启 |
| 镜像 | 公共镜像,Ubuntu,版本:Ubuntu 24.04 server 64bit(10GiB) |
| 存储 | 系统盘,默认通用型SSD 40 G |
| 网络 | 选择默认即可 |
| 安全组 | 选择默认即可 |
| 弹性公网IP | 选择“现在购买”,全动态BGP,带宽3Mbit/s |
| 云服务器名称 | 可自定义设置,这里选择默认的名称 |
| 登录凭证 | 自定义设置密码 |
| 云备份 | 根据需要自行选择 ,临时测试建议关闭以节省费用 |
确认配置及购买:在确认配置页面仔细检查Flexus云服务器X实例的各项设置,确保无误后点击“立即购买”,完成付款流程即可成功购买。
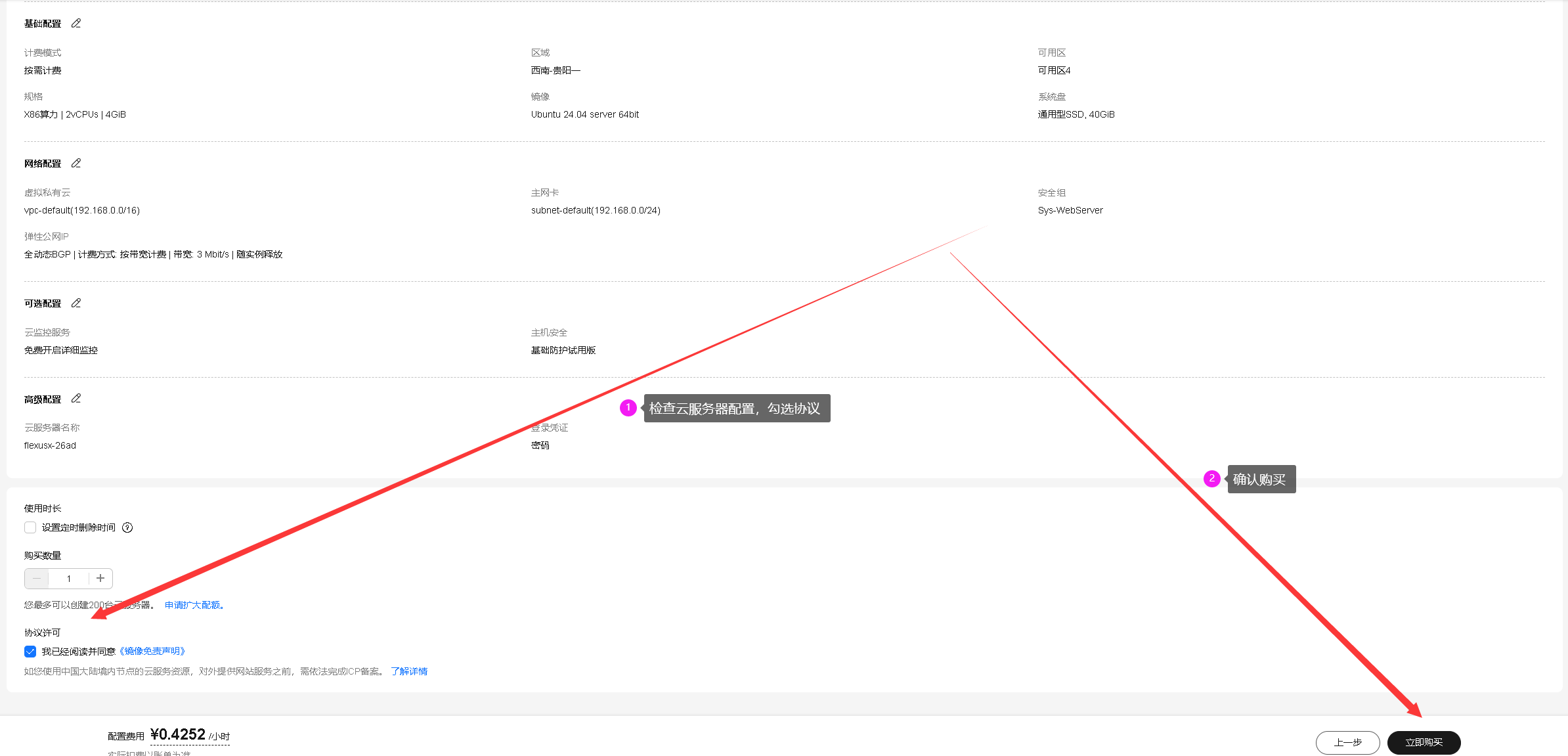
4.2 使用Xshell远程连接
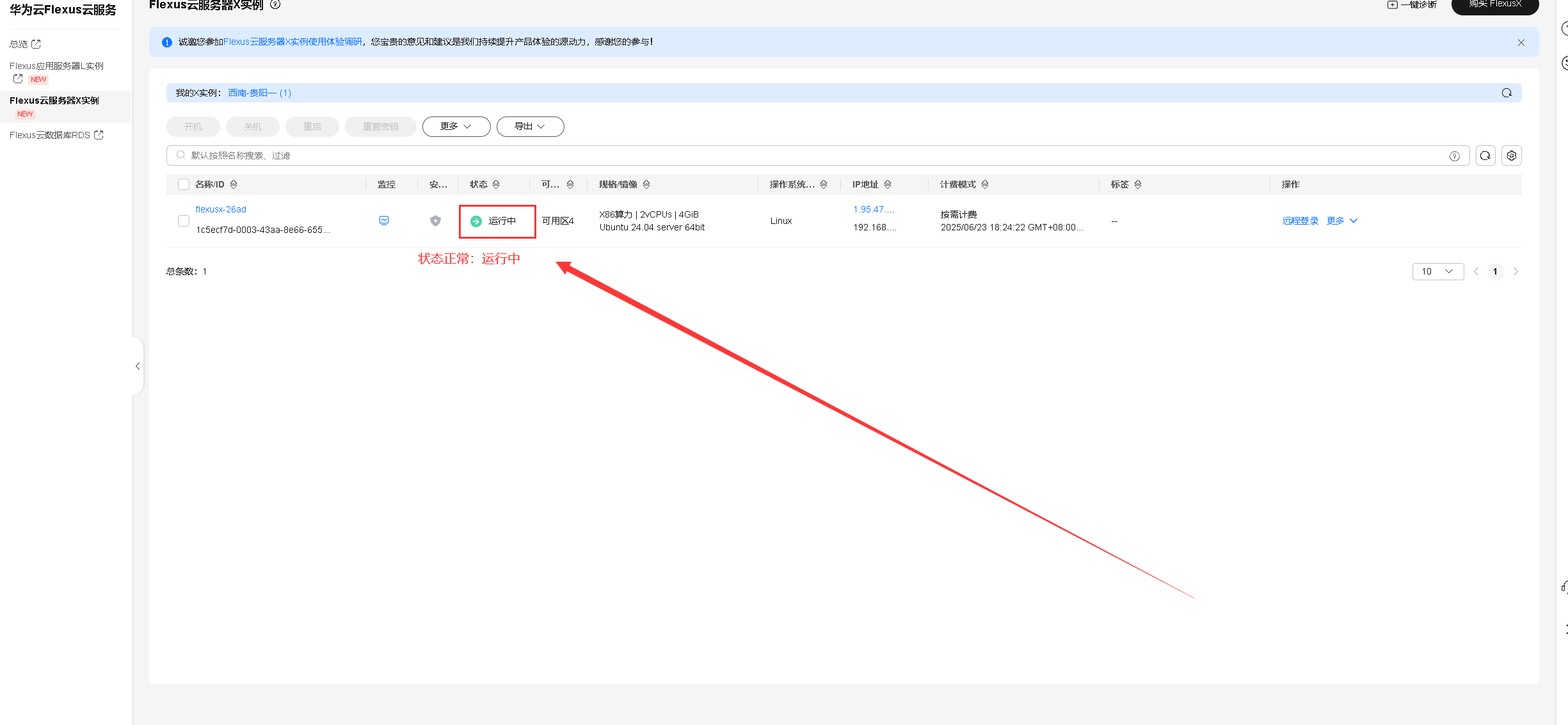
进入华为云Flexus云服务的控制台,选择Flexus云服务器X实例,可以看到已经正在运行的Flexus云服务器X实例。
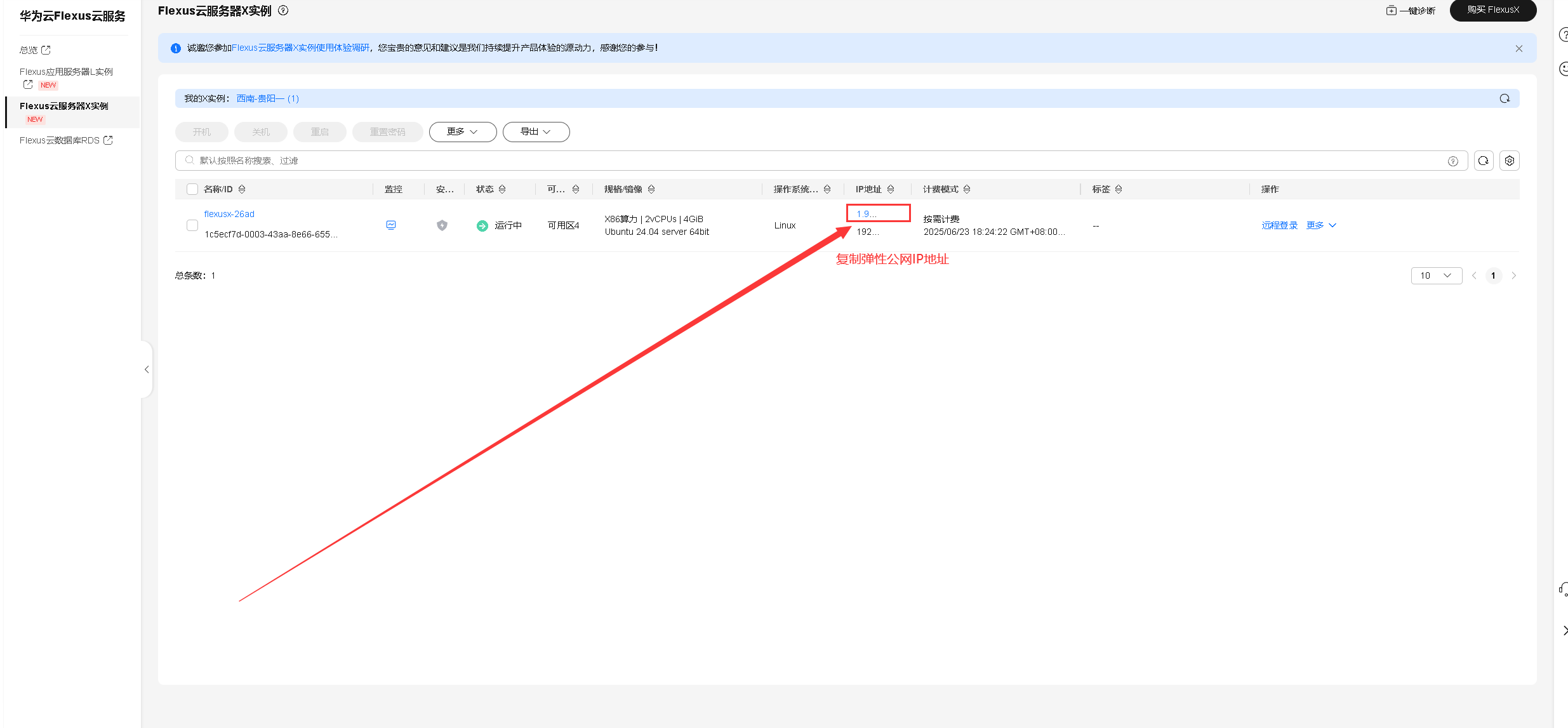
复制及保存Flexus云服务器X实例的弹性公网IP地址,作为后面登录xshell终端使用。
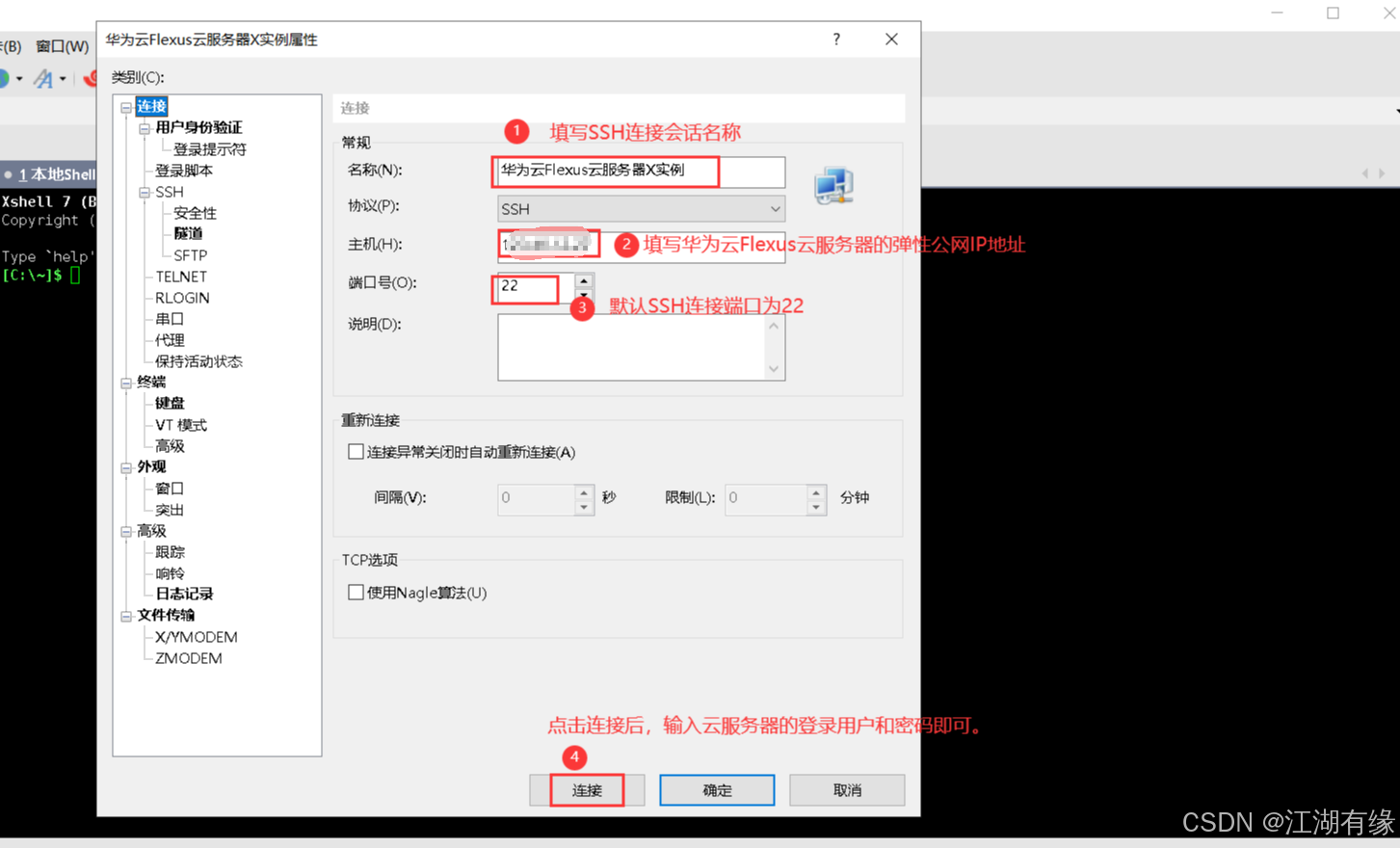
打开Xshell工具,在连接配置中主要填写Flexus云服务器X实例的弹性公网IP地址,输入其登录用户和密码,连接即可。
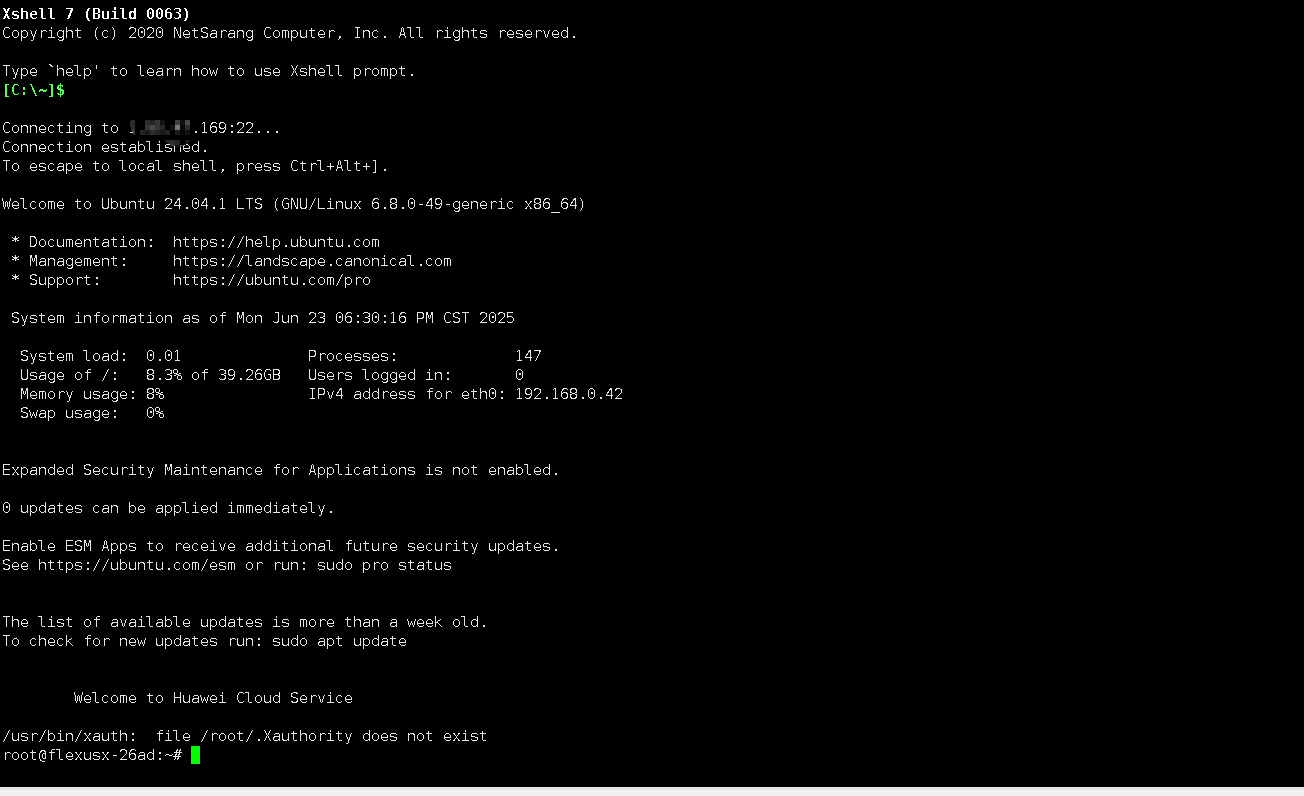
检查Flexus云服务器X实例的操作系统版本,本次实践选择的版本为
Ubuntu 24.04.1 LTS。
root@flexusx-26ad:~# cat /etc/os-release
PRETTY_NAME="Ubuntu 24.04.1 LTS"
NAME="Ubuntu"
VERSION_ID="24.04"
VERSION="24.04.1 LTS (Noble Numbat)"
VERSION_CODENAME=noble
ID=ubuntu
ID_LIKE=debian
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
UBUNTU_CODENAME=noble
LOGO=ubuntu-logo
检查当前操作系统的内核版本,当前内核版本为
6.8.0-49-generic。
root@flexusx-26ad:~# uname -r
6.8.0-49-generic
4.3 部署Docker环境
安装
Docker之前,我们先安装 HTTPS传输工具及必要组件。
apt install -y apt-transport-https ca-certificates curl gnupg lsb-release software-properties-common
执行以下命令,添加阿里云 GPG 密钥。
mkdir -p /etc/apt/keyrings
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker-archive-keyring.gpg
执行以下命令,开始配置阿里云 Docker 软件源。
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
使用
apt update命令,更新软件源。
apt update
执行以下命令,安装Docker核心组件。
apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
执行以下命令,快速配置Docker镜像加速。这里我们配置华为云的镜像加速服务,也可以自行添加多个Docker镜像加速源,确保后续可以成功拉取Docker镜像。
mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json > /dev/null <<EOF
{
"registry-mirrors": ["https://80c84f5330e14908928ca78944e61dc4.mirror.swr.myhuaweicloud.com"]
}
EOF
执行以下命令,配置Docker开机自启。
systemctl daemon-reload
systemctl restart docker
systemctl enable docker
检查Docker版本,可以看到当前安装的版本为
28.2.2。
root@flexusx-26ad:~# docker -v
Docker version 28.2.2, build e6534b4
检查Docker compose版本,当前安装版本为
2.36.2。
root@flexusx-26ad:~# docker compose version
Docker Compose version v2.36.2
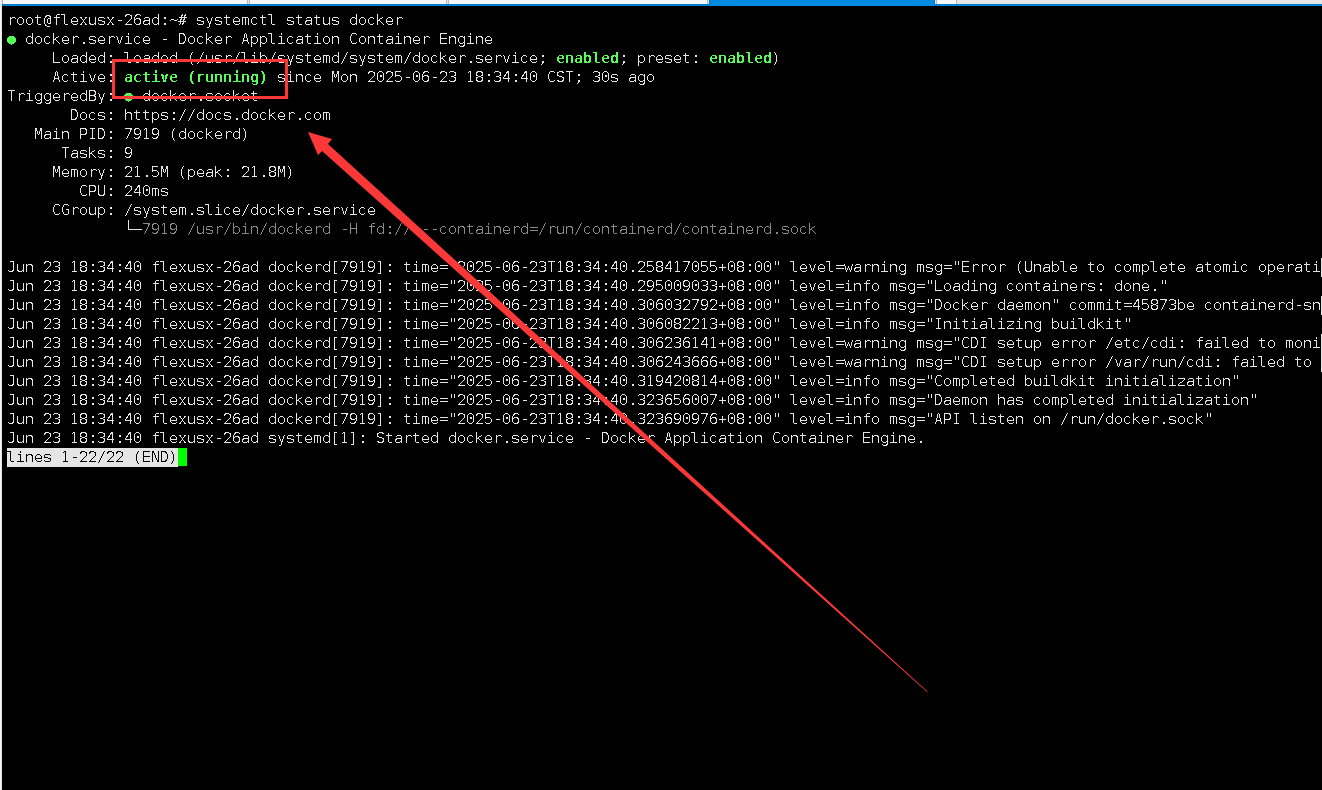
检查Docker服务状态,确保Docker服务正常运行。
systemctl status docker
五、部署WebLLM Chat应用
5.1 下载WebLLM Chat镜像
可以拉取以下WebLLM Chat容器镜像,名称为:
swr.cn-north-4.myhuaweicloud.com/jeven/webllmchat:v1。
root@flexusx-26ad:~/web-llm-chat# docker pull swr.cn-north-4.myhuaweicloud.com/jeven/webllmchat:v1
v1: Pulling from jeven/webllmchat
da9db072f522: Pull complete
aa6f657bab0c: Pull complete
f477ea663f1c: Pull complete
43c47a581c29: Pull complete
72d26cafad01: Pull complete
1513b3a13559: Pull complete
65fd72f40c6c: Pull complete
39ec35971416: Pull complete
65c9b75f5c63: Pull complete
3835d9940e7d: Pull complete
Digest: sha256:4d5cd97819133a788c0dd5a70cdebcecd0a0efea22981e8219cfac8468c441b6
Status: Downloaded newer image for swr.cn-north-4.myhuaweicloud.com/jeven/webllmchat:v1
swr.cn-north-4.myhuaweicloud.com/jeven/webllmchat:v1
5.2 创建WebLLM Chat容器
如果使用docker命令行方式部署,可参考以下示例:
docker run -d \
--name webllmchat \
--restart always \
-p 7200:3000 \
swr.cn-north-4.myhuaweicloud.com/jeven/webllmchat:v1
本次实践使用docker compose方式创建容器,建议采用该方式进行创建容器项目。
vim docker-compose.yaml
version: '3.9'
services:
jeven:
image: 'swr.cn-north-4.myhuaweicloud.com/jeven/webllmchat:v1'
ports:
- '7200:3000'
restart: always
container_name: webllmchat
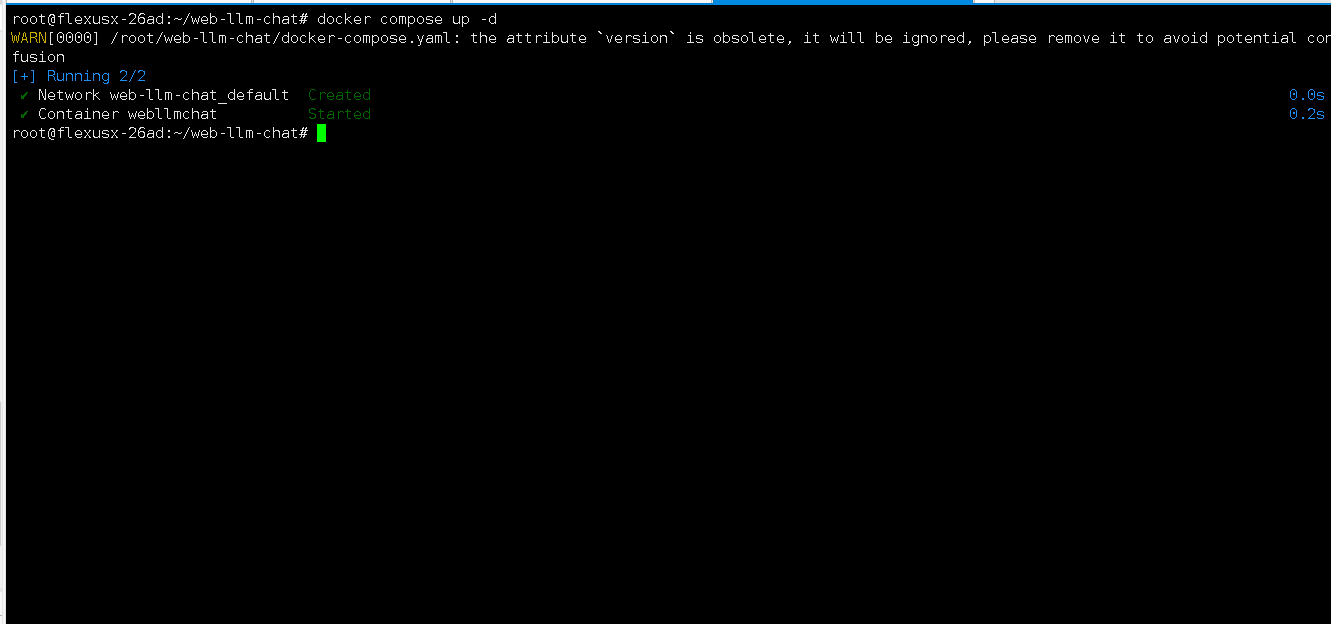
执行以下命令,创建WebLLM Chat相关容器。
docker compose up -d
5.3 检查WebLLM Chat容器状态
检查容器状态,确保WebLLM Chat容器正常启动。
root@flexusx-26ad:~/web-llm-chat# docker compose ps
WARN[0000] /root/web-llm-chat/docker-compose.yaml: the attribute `version` is obsolete, it will be ignored, please remove it to avoid potential confusion
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
webllmchat swr.cn-north-4.myhuaweicloud.com/jeven/webllmchat:v1 "docker-entrypoint.s…" jeven 2 minutes ago Up 2 minutes 0.0.0.0:7200->3000/tcp, [::]:7200->3000/tcp
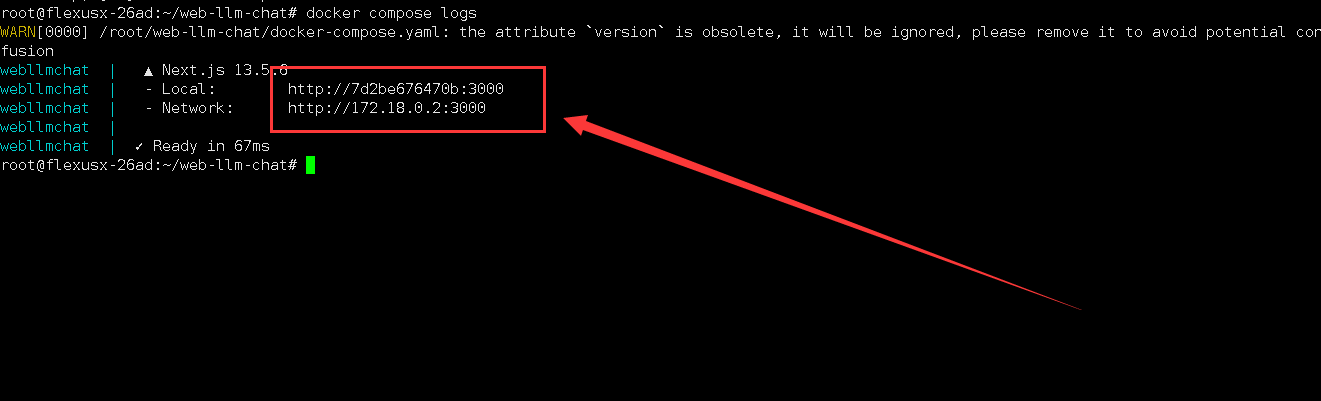
5.4 检查WebLLM Chat容器日志
检查WebLLM Chat容器日志,可以看到WebLLM Chat服务正常运行。
root@flexusx-26ad:~/web-llm-chat# docker compose logs
WARN[0000] /root/web-llm-chat/docker-compose.yaml: the attribute `version` is obsolete, it will be ignored, please remove it to avoid potential confusion
webllmchat | ▲ Next.js 13.5.6
webllmchat | - Local: http://7d2be676470b:3000
webllmchat | - Network: http://172.18.0.2:3000
webllmchat |
webllmchat | ✓ Ready in 67ms
六、https与访问验证配置工作
6.1 配置说明
在使用 HTTP 协议访问WebLLM Chat服务时,页面可能会出现错误并导致卡死现象。为保障访问的安全性与稳定性,在本次实践中,我们通过华为云 Flexus X 实例模拟本地云环境部署 WebLLM Chat,并配置了 HTTPS 加密通信及访问验证机制。为此,需要设置反向代理以实现对外服务的安全暴露和请求转发。
6.2 安装Nginx和相关工具
执行以下命令,更新软件源并安装Nginx和
apache2-utils(用于创建密码文件)。
apt update
apt install nginx apache2-utils
6.3 配置SSL证书
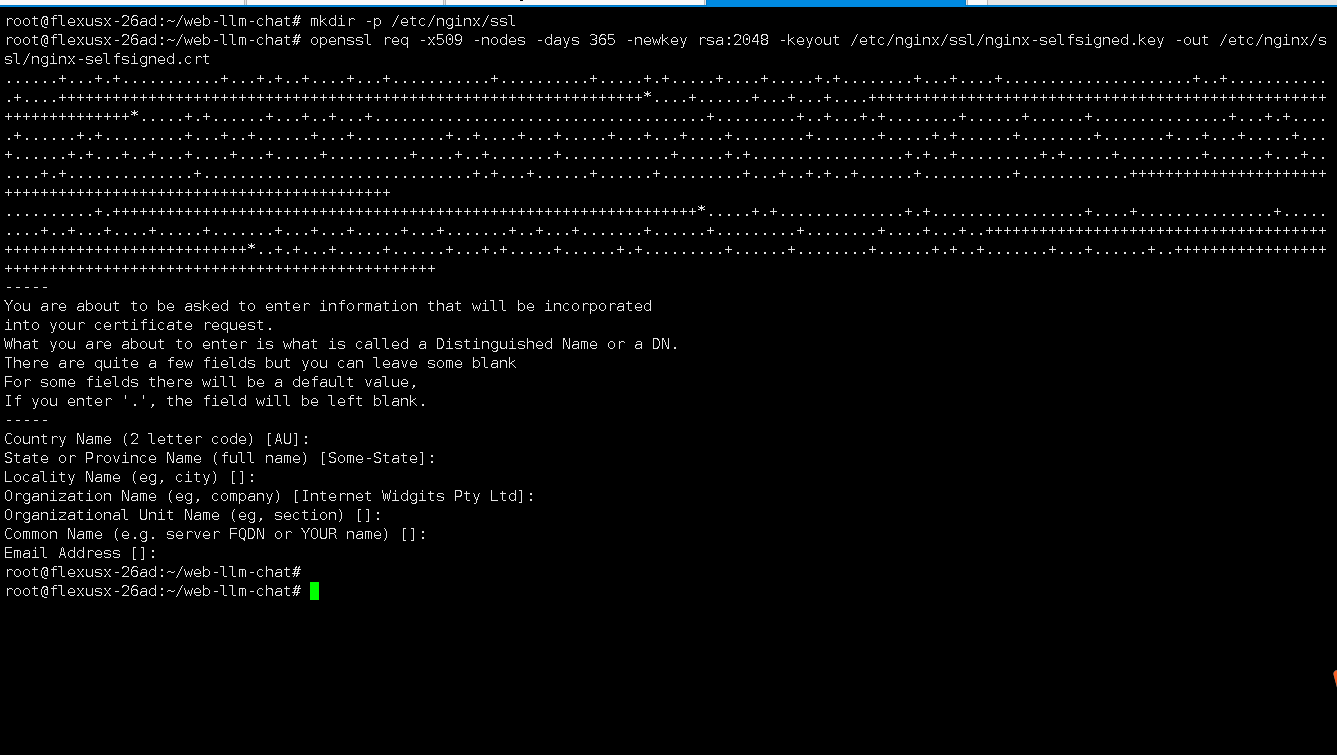
执行以下命令,创建证书存放目录。
mkdir -p /etc/nginx/ssl
为了使用HTTPS,我们需要一个SSL证书。由于当前为测试环境,我们可以使用自签名证书。要生成自签名证书,可使用执行以下操作。
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/nginx/ssl/nginx-selfsigned.key -out /etc/nginx/ssl/nginx-selfsigned.crt
6.4 设置基本认证
创建一个用户名为
admin的用户,并设置密码。自定义设置密码即可,这里设置为密码也为admin。
htpasswd -c /etc/nginx/.htpasswd admin
6.5 配置Nginx
编辑或创建一个新的Nginx配置文件(例如
/etc/nginx/sites-available/reverse-proxy),如下所示:
vim /etc/nginx/sites-available/reverse-proxy
reverse-proxy 的配置文件内容如下:其中
server_name需设置为华为云 Flexus X 实例的内网 IP 地址,proxy_pass指向本地后端服务地址 http://127.0.0.1:7200,listen端口为 9080(用于 HTTPS 访问),可根据实际需求进行调整。该配置用于实现安全的 HTTPS 访问和反向代理功能。
server {
listen 9080 ssl;
server_name 192.168.0.42;
ssl_certificate /etc/nginx/ssl/nginx-selfsigned.crt;
ssl_certificate_key /etc/nginx/ssl/nginx-selfsigned.key;
location / {
auth_basic "Restricted Content";
auth_basic_user_file /etc/nginx/.htpasswd;
proxy_pass http://127.0.0.1:7200;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
- 启用该配置文件:
ln -s /etc/nginx/sites-available/reverse-proxy /etc/nginx/sites-enabled/
- 检查Nginx配置是否正确:
root@flexusx-26ad:~/web-llm-chat# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
6.6 启动Nginx服务
启动Nginx服务,并设置开机自启。
systemctl start nginx
systemctl enable nginx
为了检查Nginx服务运行正常,使用以下命令进行检查确认。
systemctl status nginx
七、访问WebLLM Chat服务
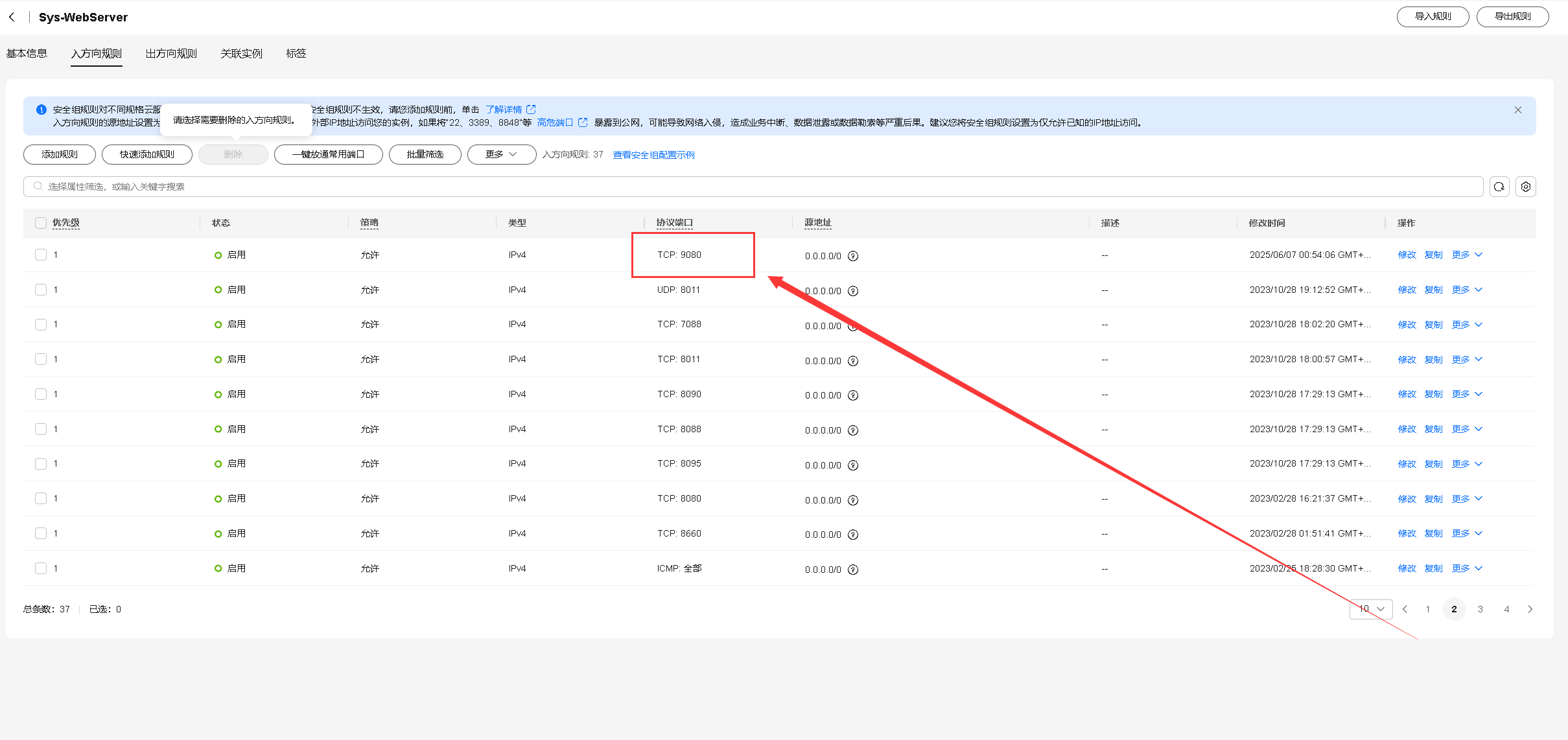
7.1 配置安全组规则
在华为云Flexus X实例绑定的安全组中,我们在入方向上放行9080端口,如下所示:
7.2 访问WebLLM Chat首页
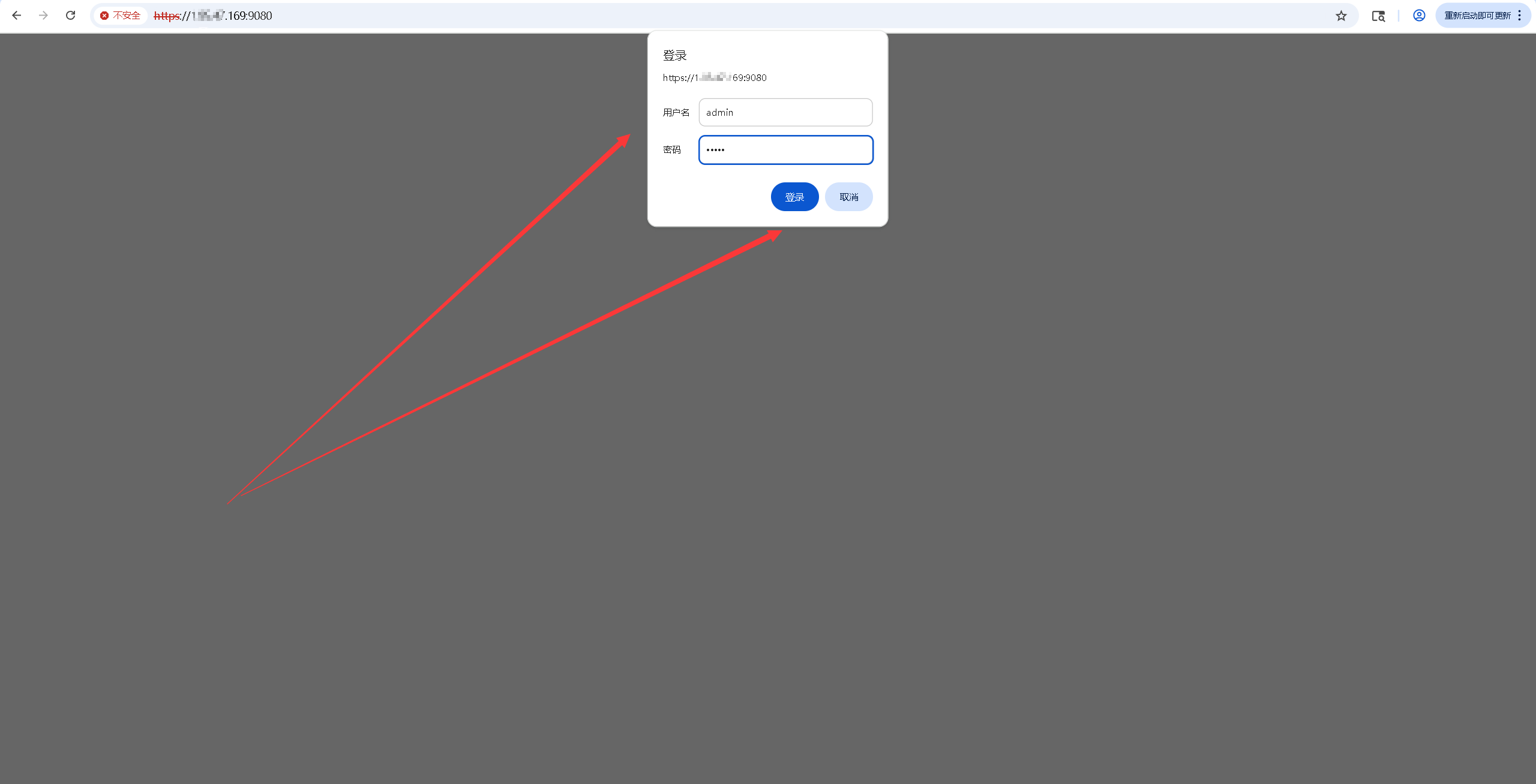
浏览器访问https://<云服务器公网IP地址>:9080,将IP替换为云服务器的弹性公网IP地址,访问WebLLM Chat的初始页。如果无法访问到该页面,需要检查操作系统的防火墙是否关闭或放行相关服务端口。
- 在登录页,输入我们设置的默认账号密码admin/admin,即可进入WebLLM Chat首页。
7.3 本地下载模型
选择本地模型:我们点击对话框的模型项,进入模型选择页面。
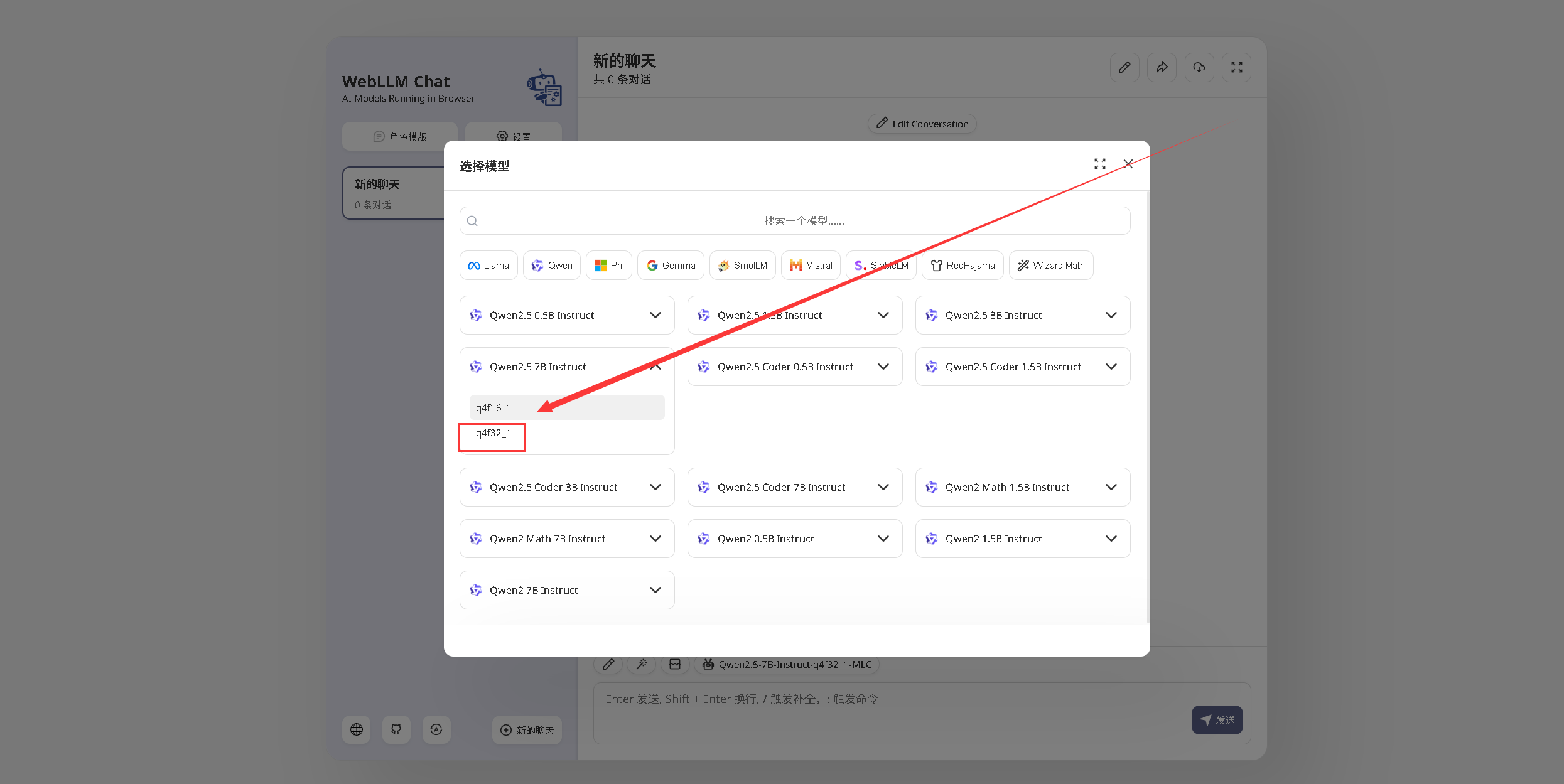
在模型选择页面中,我们选用了 Qwen2.5 7B Instruct q4f32_1 本地模型。
在对话框中输入问题后,系统将自动开始下载所选模型。模型文件下载完成后会被缓存,以便后续使用时能够快速加载和运行。该机制不仅提升了本地推理的效率,也有效减少了因重复下载带来的时间和带宽消耗。需要注意的是,如果因网络问题导致下载中断,可以再次提问以继续上次未完成的下载,直至模型成功部署到本地环境。
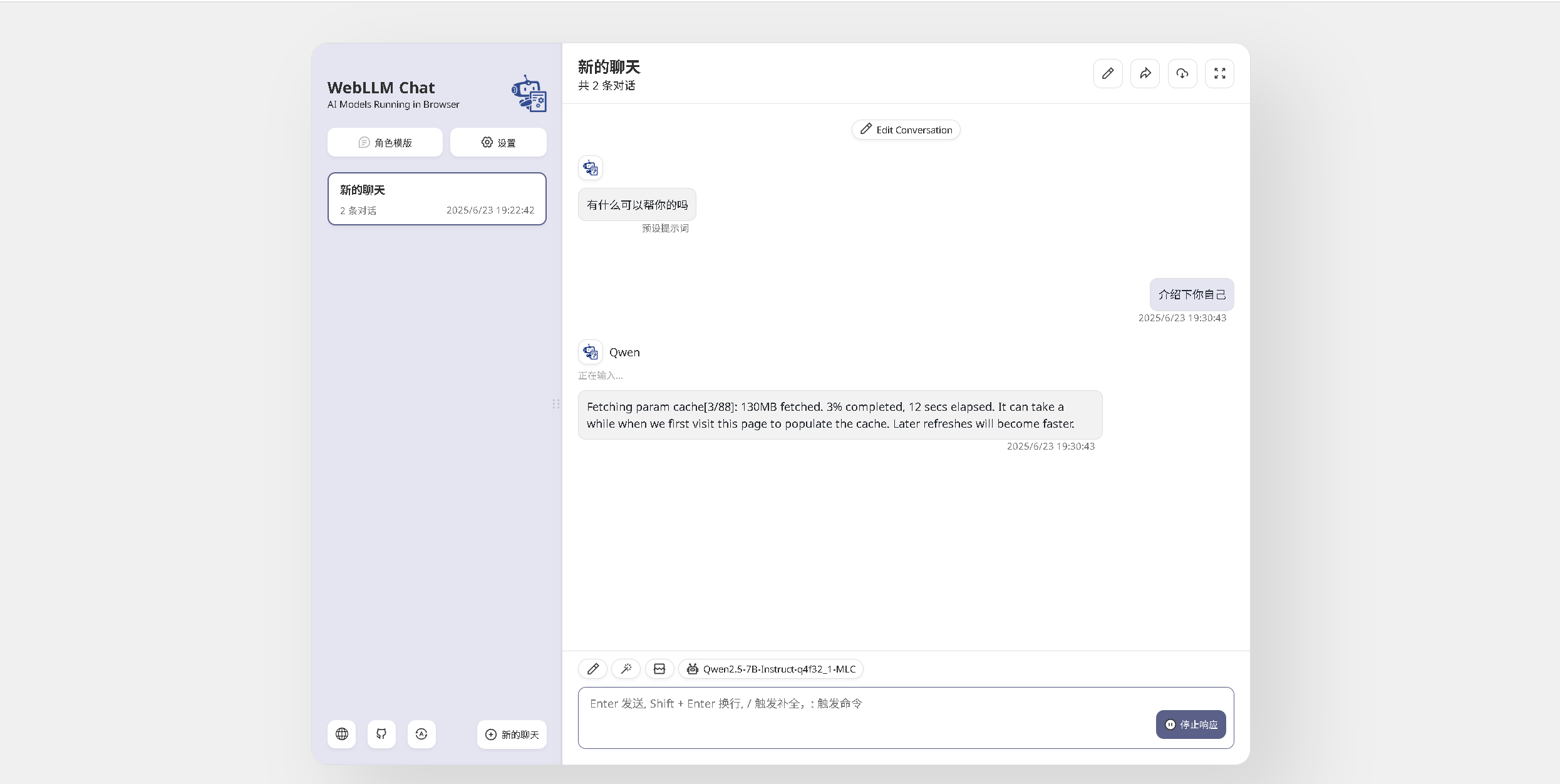
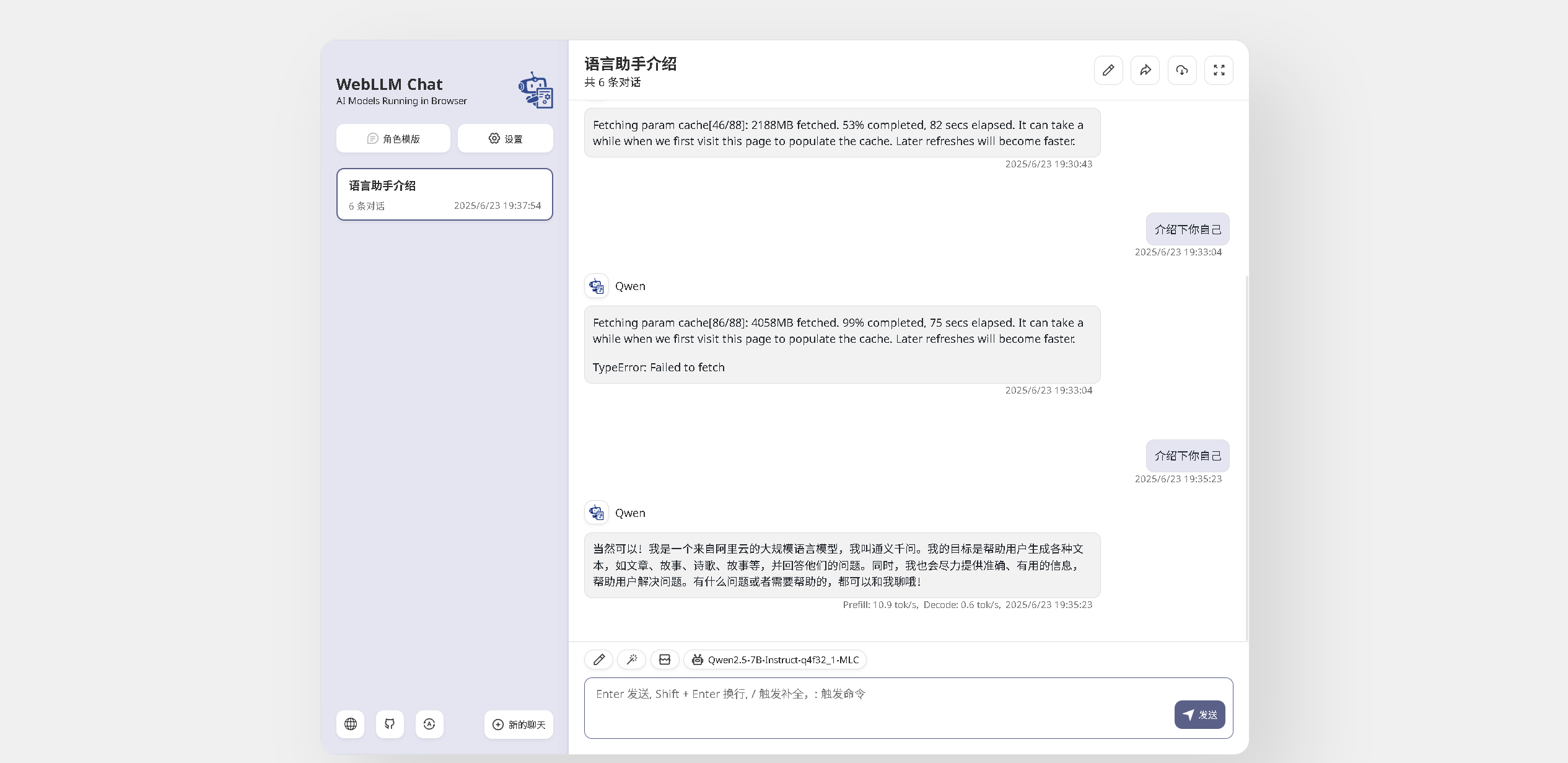
7.4 对话效果
可以看到,在模型下载并加载完成后,WebLLM Chat 开始响应我们的问题。在 Qwen2.5-7B Instruct q4f32_1 模型下,性能表现为 Prefill 阶段约 10.9 tok/s,Decode 阶段约 0.6 tok/s,回答速度相对较慢。但在华为云 Flexus X 实例 2核4G 的配置下,仍然能够成功运行模型并完成基本的问答任务。
八、开通DeepSeek商用服务
8.1 进入ModelArts Studio控制台
ModelArts Studio是华为云提供的一个大模型即服务平台(MaaS服务),旨在简化模型开发流程,支持定制化大模型的开发,并使这些模型能够无缝集成到业务系统中。通过降低企业AI应用的成本和难度,ModelArts Studio助力企业快速实现AI技术落地。我们登录华为云官网后,进入ModelArts Studio大模型即服务平台的介绍页。官网地址:https://www.huaweicloud.com/product/modelarts/studio.html。点击“ModelArts Studio控制台”,即可进入maas服务控制台内。
8.2 开通商业服务
访问 ModelArts Studio 大模型即服务平台后,ModelArts Studio 控制台,登录后进入 模型推理 页面,选择 在线推理 > 预置服务 > 商用服务,在模型列表中找到 DeepSeek-R1-32K,点击“开通服务”以启用该模型,具体操作如下所示:
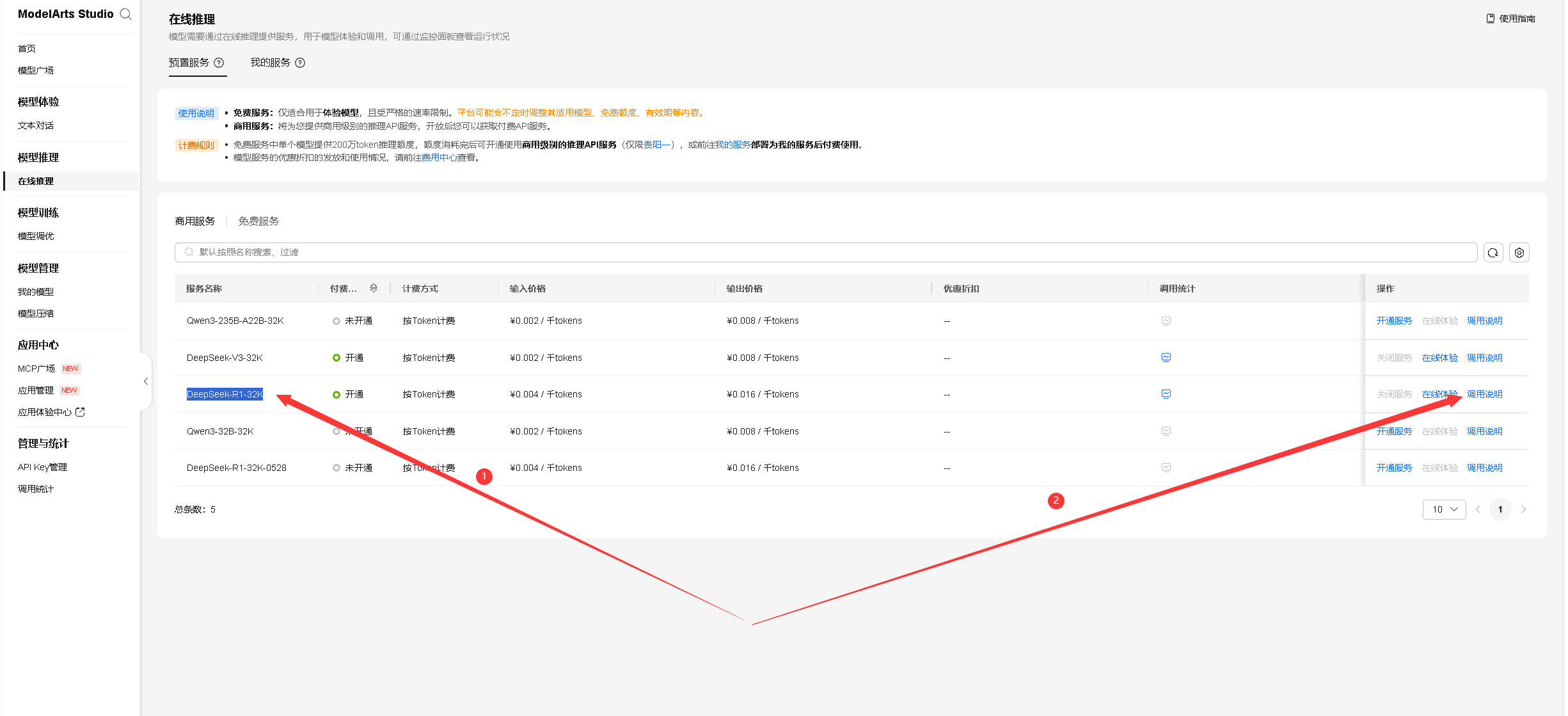
同样的方法,我们可以开通DeepSeek-V3-32K和DeepSeek-R1-32K-0528商用服务,如下所示已正常开通。

8.3 在线体验商用服务
我们在商用服务列表中选择 DeepSeek-V3-32K 模型,并点击“在线体验”选项,以开启模型的在线测试与使用。
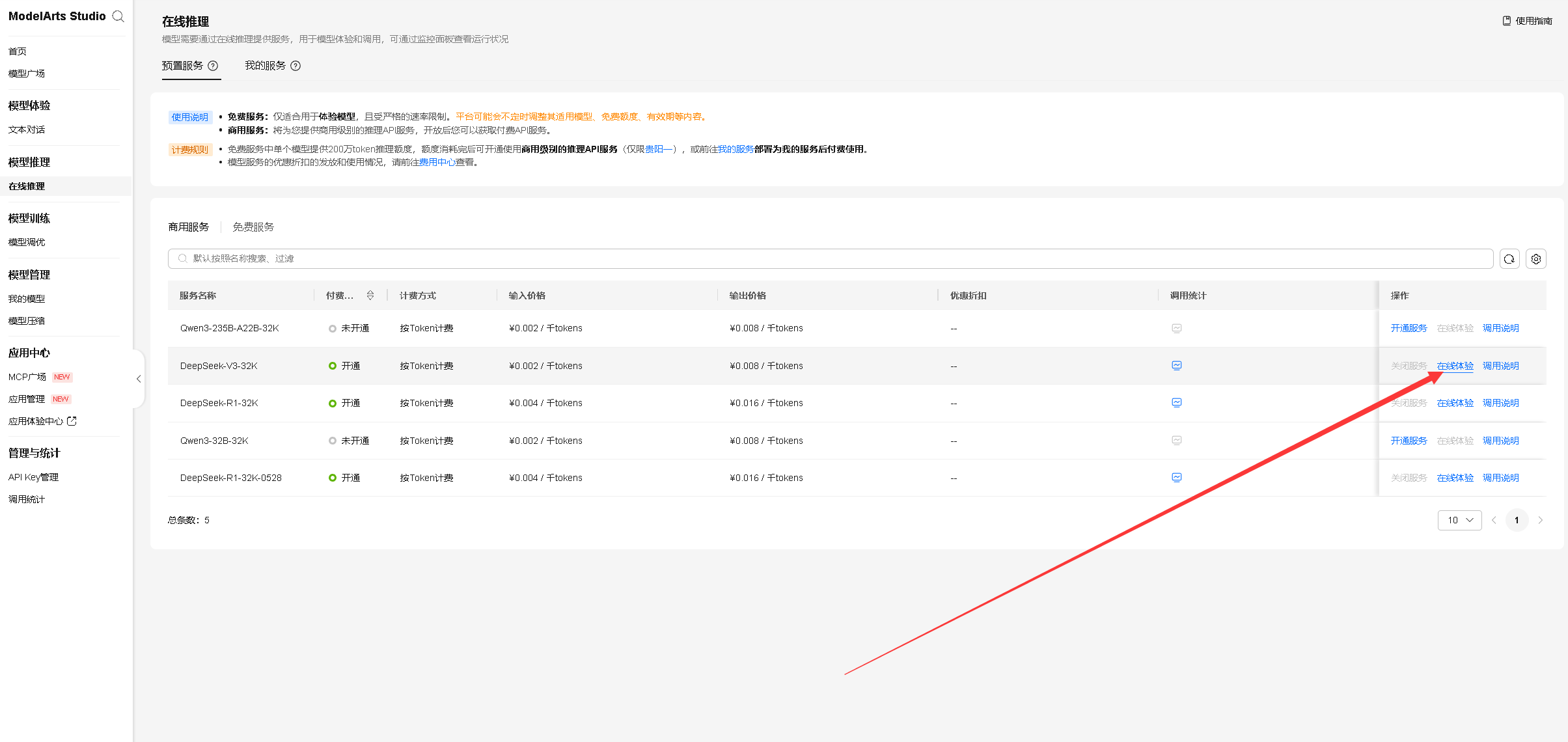
在对话框进行提问,可以看到 DeepSeek-V3-32K很快就回答我们的问题。
九、实际使用对比
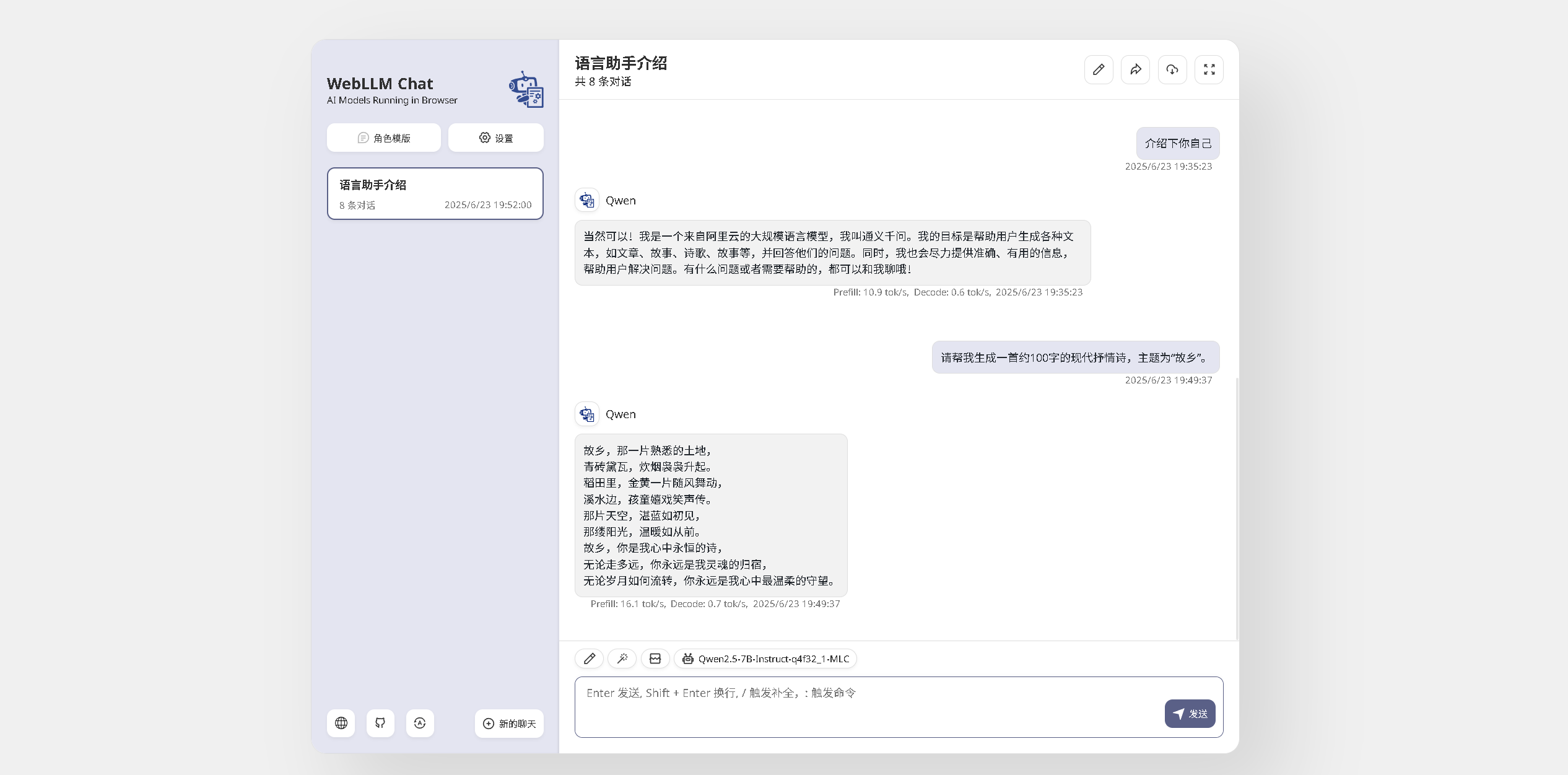
9.1 WebLLM Chat生成内容测试
我们在WebLLM Chat对话框中请求生成一首约100字、以“故乡”为主题的现代抒情诗。从性能数据来看,结果显示:Prefill阶段速度为16.1 tok/s,Decode阶段速度为0.7 tok/s。由于解码阶段速度较慢,整体生成过程耗时较长,大约需要几分钟时间。
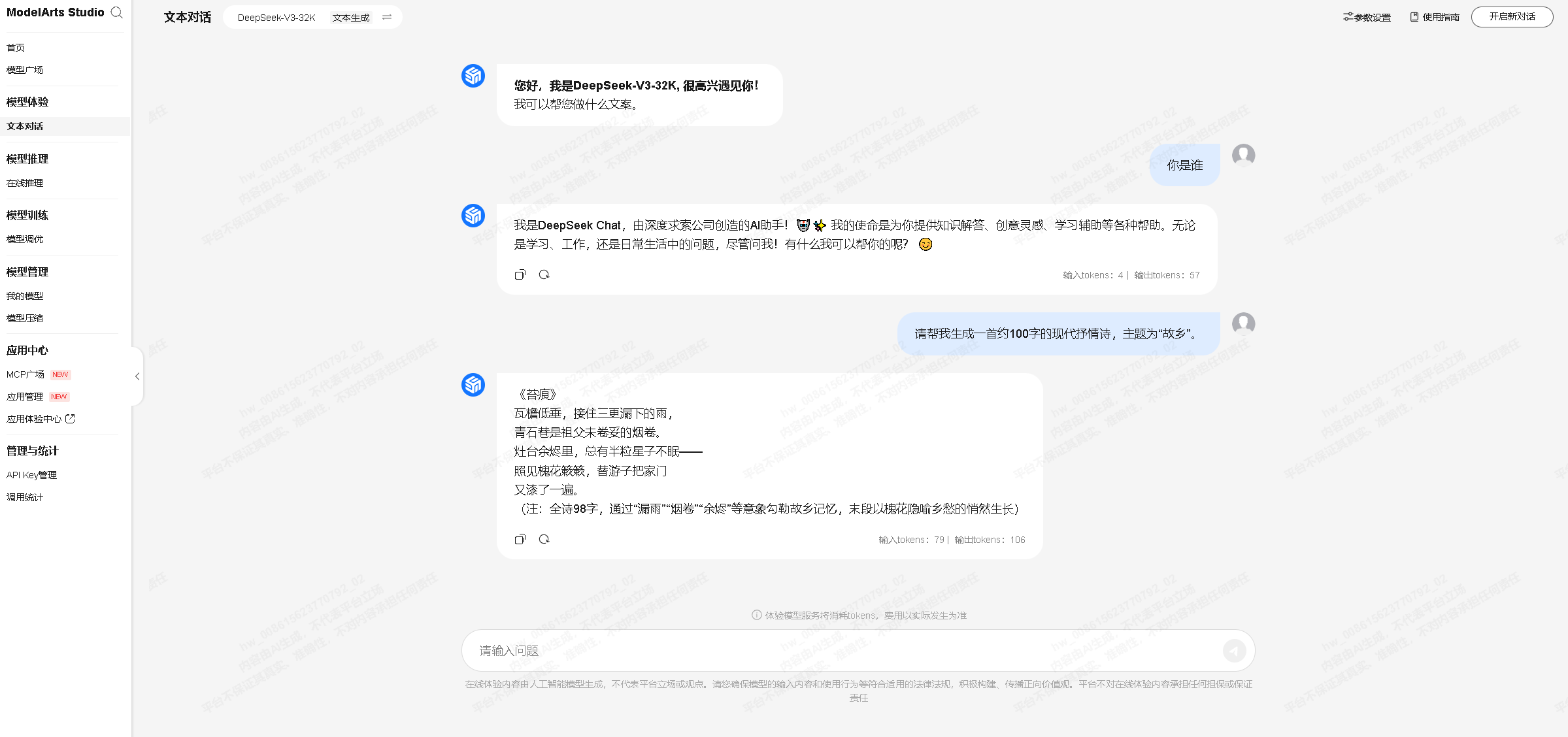
9.2 DeepSeek生成效果测试
我们在 DeepSeek-V3-32K 模型的对话页面,进行对话测试,同样请求生成一首约100字、以“故乡”为主题的现代抒情诗。可以看到输入tokens:79 输出tokens:106,几乎是秒级回答生成内容,速度很快。
9.3 对比分析
🔍 模型性能对比概览
| 特性/指标 | WebLLM Chat (故乡主题诗) | DeepSeek-V3-32K (故乡主题诗) |
|---|---|---|
| 输入Tokens | - | 📥 79 |
| 输出Tokens | 📤 约100 | 📤 106 |
| Prefill阶段速度 | ⚙️ 16.1 tok/s | ❌ 暂无数据 |
| Decode阶段速度 | ⏱️ 0.7 tok/s | ❌ 暂无数据 |
| 总耗时 | ⏳ 大约几分钟 | ⚡ 秒级响应 |
| 用户体验 | 😕 较慢,可能影响效率 | 😊 流畅,高效率 |
| 技术支持及稳定性 | 🛠️ 标准 | 💪 高,由华为云提供 |
✨ DeepSeek-V3-32K 在线服务优势
- 🚀 快速响应
- 几乎秒级完成内容生成,极大提升工作效率。
- ⚙️ 高效处理能力
- 即使面对大量输入(79 tokens)和输出(106 tokens),DeepSeek也能迅速处理并返回结果。
- 😎 用户体验佳
- 高速响应带来流畅无阻的服务体验,用户操作更高效。
☁️ 华为云 ModelArts Studio 的核心优势
- 🔒 稳定性和可靠性
- 提供极其稳定的服务平台,保障数据安全与服务持续运行。
- 🔧 强大的技术支持
- 背靠华为技术团队,确保技术领先与服务持续优化。
- 🧩 多样化的解决方案
- 支持大型企业、中小开发者等不同需求,灵活适配各类场景。
📌 总结:
DeepSeek-V3-32K 结合 华为云 ModelArts Studio 的强大支持,在响应速度、处理能力和用户体验方面表现卓越。相比 WebLLM Chat,其在高性能推理和服务稳定性上具有显著优势,是企业级 AI 应用的理想选择。
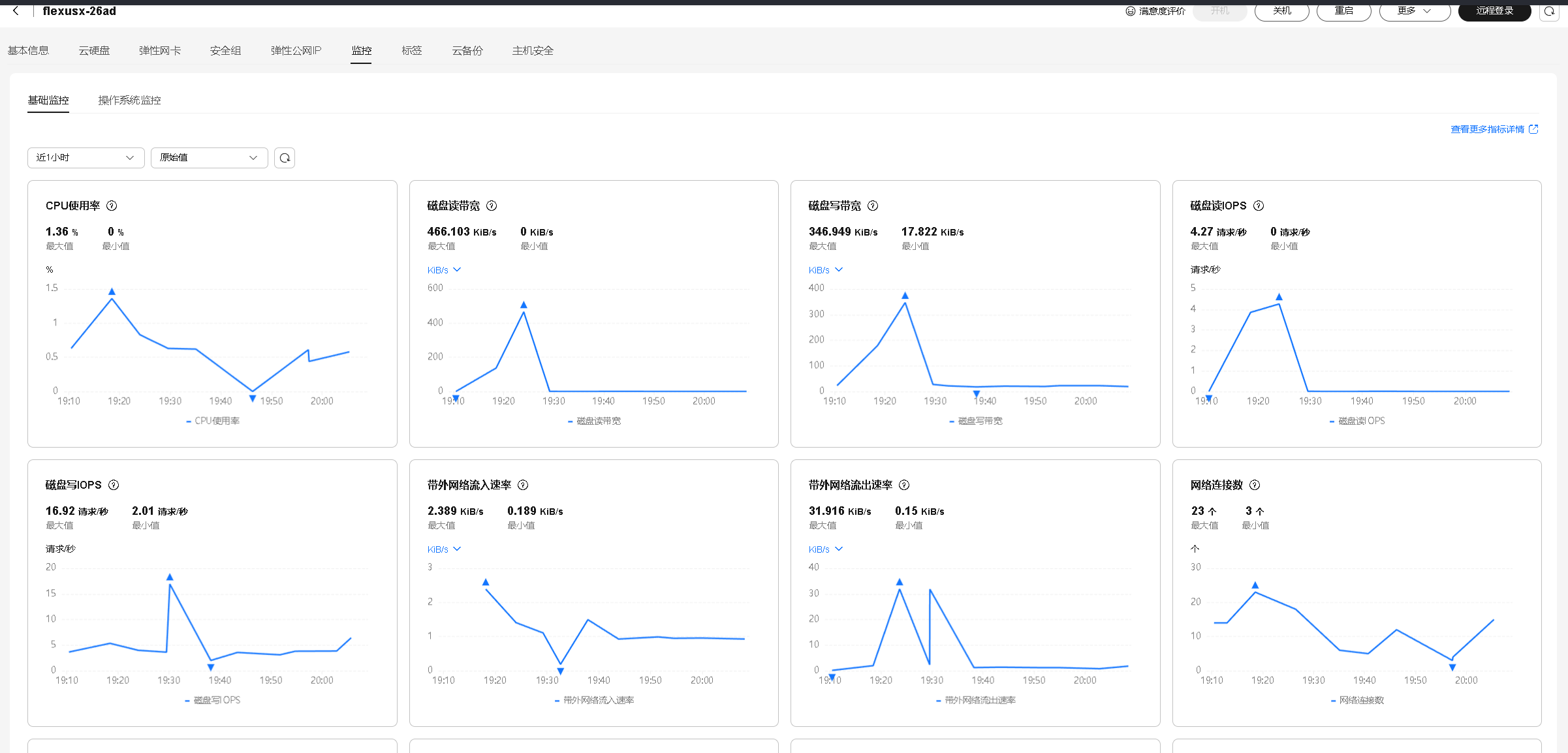
十、华为云Flexus X实例资源使用分析
通过华为云Flexus X实例的监控页面可以清晰地看到,在运行WebLLM Chat本地AI服务过程中,系统资源占用始终保持在较低水平,CPU和内存使用率稳定,未出现明显波动。即使在模型加载和推理任务执行期间,整体性能表现依然优秀,响应速度快、运行流畅,充分展现了华为云Flexus X实例在资源调度与稳定性方面的优势,为本地AI应用提供了高效可靠的运行环境。
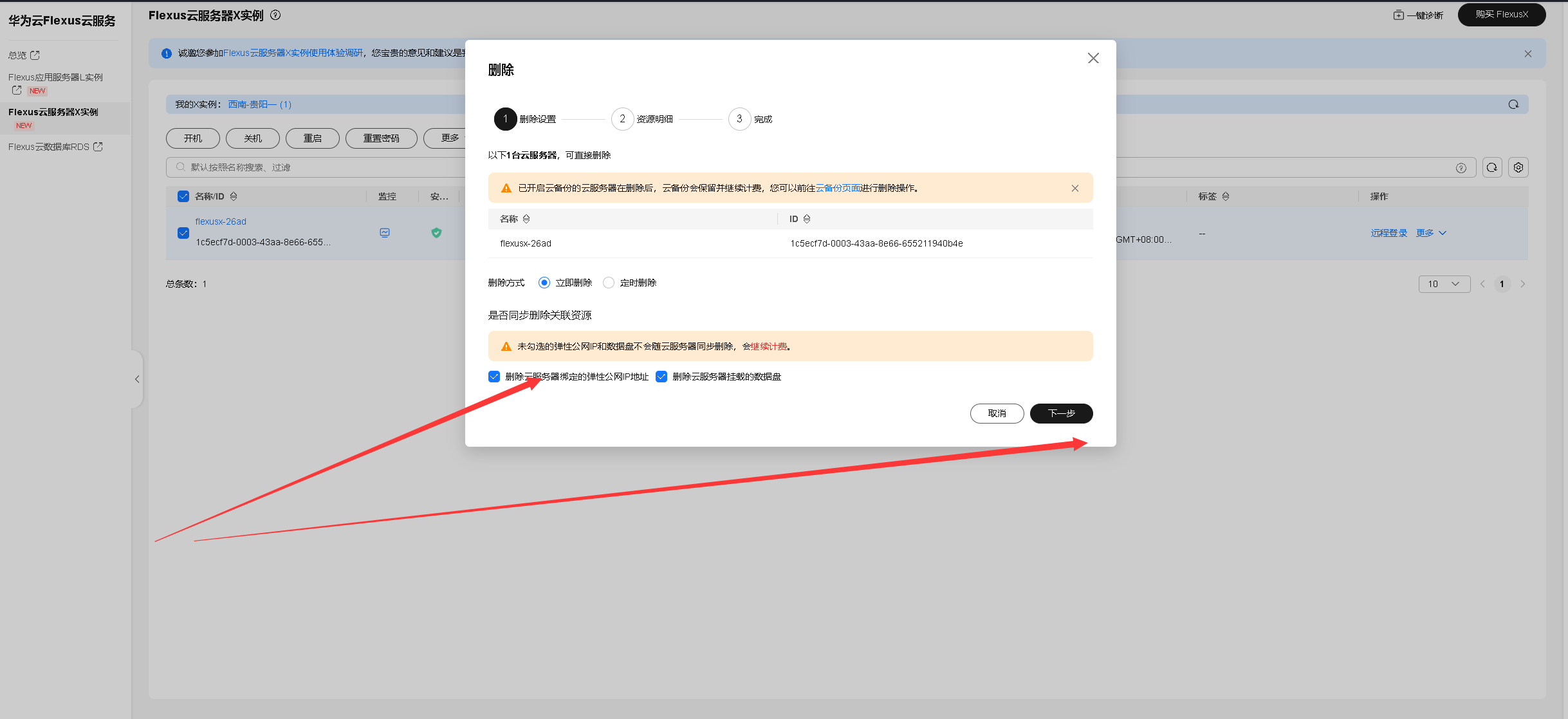
十一、清空资源
在完成所有实践任务后,及时清理云服务器上的相关资源至关重要,既能避免不必要的费用支出,也能提高资源使用效率。良好的资源管理习惯有助于维持云端环境的整洁与稳定,确保系统运行流畅。此外,释放闲置资源还能为后续项目的部署与运行预留充足的空间,提升整体开发与运维的灵活性。
十二、实践体验与总结
通过本次实战对比,深刻体会到华为云 ModelArts Studio 在线服务的强大性能和稳定表现。相较于本地部署的 WebLLM Chat,DeepSeek-V3-32K 在响应速度和处理效率上优势明显,真正实现了秒级生成、高效推理。华为云不仅提供了卓越的技术支持,还以高可靠性保障了流畅无阻的 AI 服务体验。🌈
📢 选择华为云 ModelArts Studio,让 AI 开发更智能、更高效!
828 B2B企业节已经开幕,汇聚千余款华为云旗下热门数智产品,更带来满额赠、专属礼包、储值返券等重磅权益玩法,是中小企业和开发者上云的好时机,建议密切关注官方渠道,及时获取最新活动信息,采购最实惠的云产品和最新的大模型服务!

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 23
23 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)