
大数据毕业设计:python职位信息推荐系统 协同过滤推荐算法 Echarts可视化 Django框架 简历投递(建议收藏)✅
大数据毕业设计:python职位信息推荐系统 协同过滤推荐算法 Echarts可视化 Django框架 简历投递(建议收藏)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:python语言、Django框架、MySQL数据库、前端用的bootstrap做界面渲染设计、基于用户的协同过滤算法、Echarts可视化
项目主要的功能模块
1、用户登录,注册,退出登录
2、前台:岗位操作(查看、评论、评分等)、投递简历、推荐岗位、图表分析展示
3、后台:岗位管理、用户管理、评论管理、打分管理、分类管理等
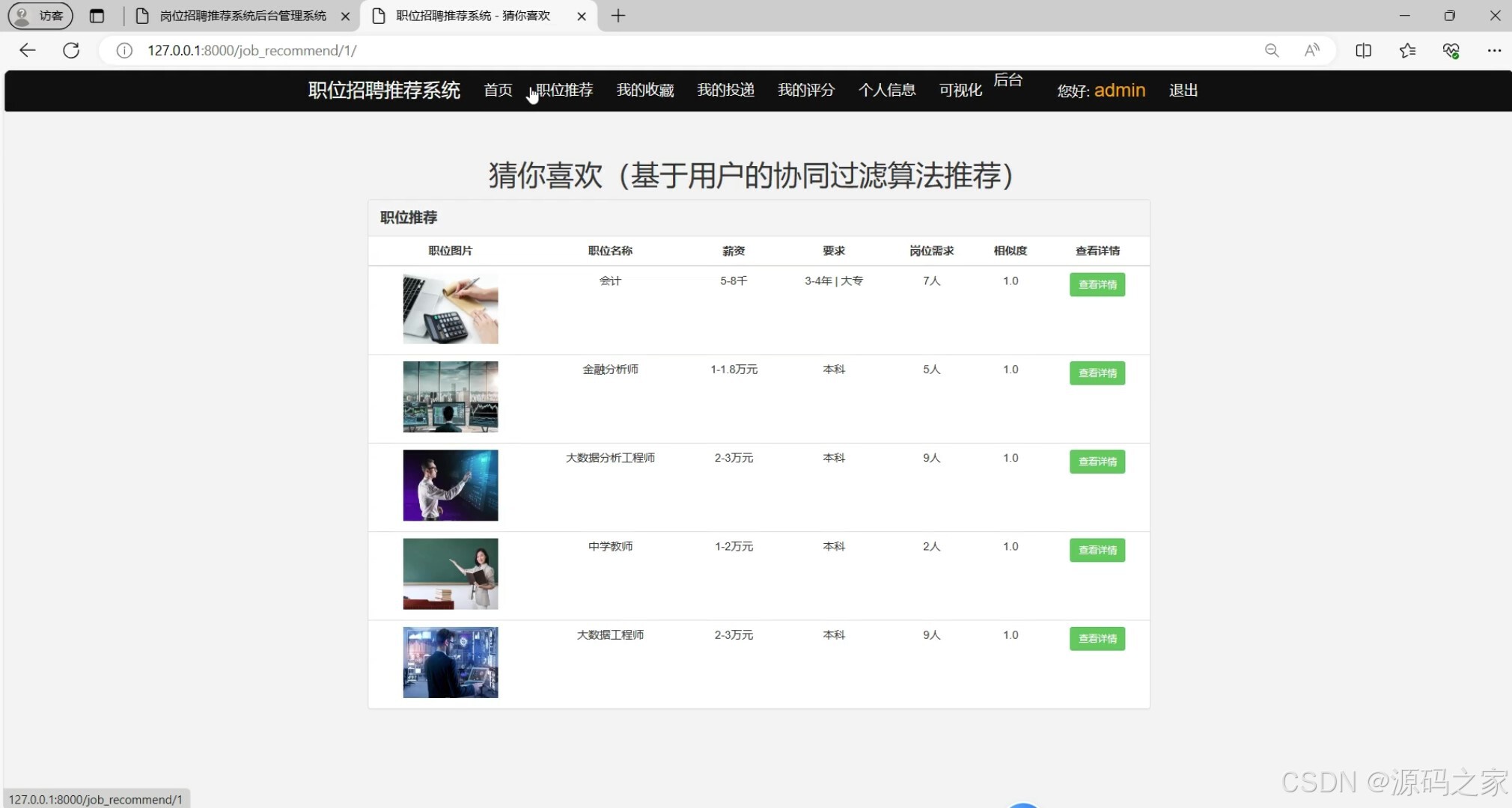
4、推荐岗位(推荐列表),使用推荐系统(基于用户的协同过滤)算法,给用户推荐可能喜欢的岗位
2、项目界面
(1)首页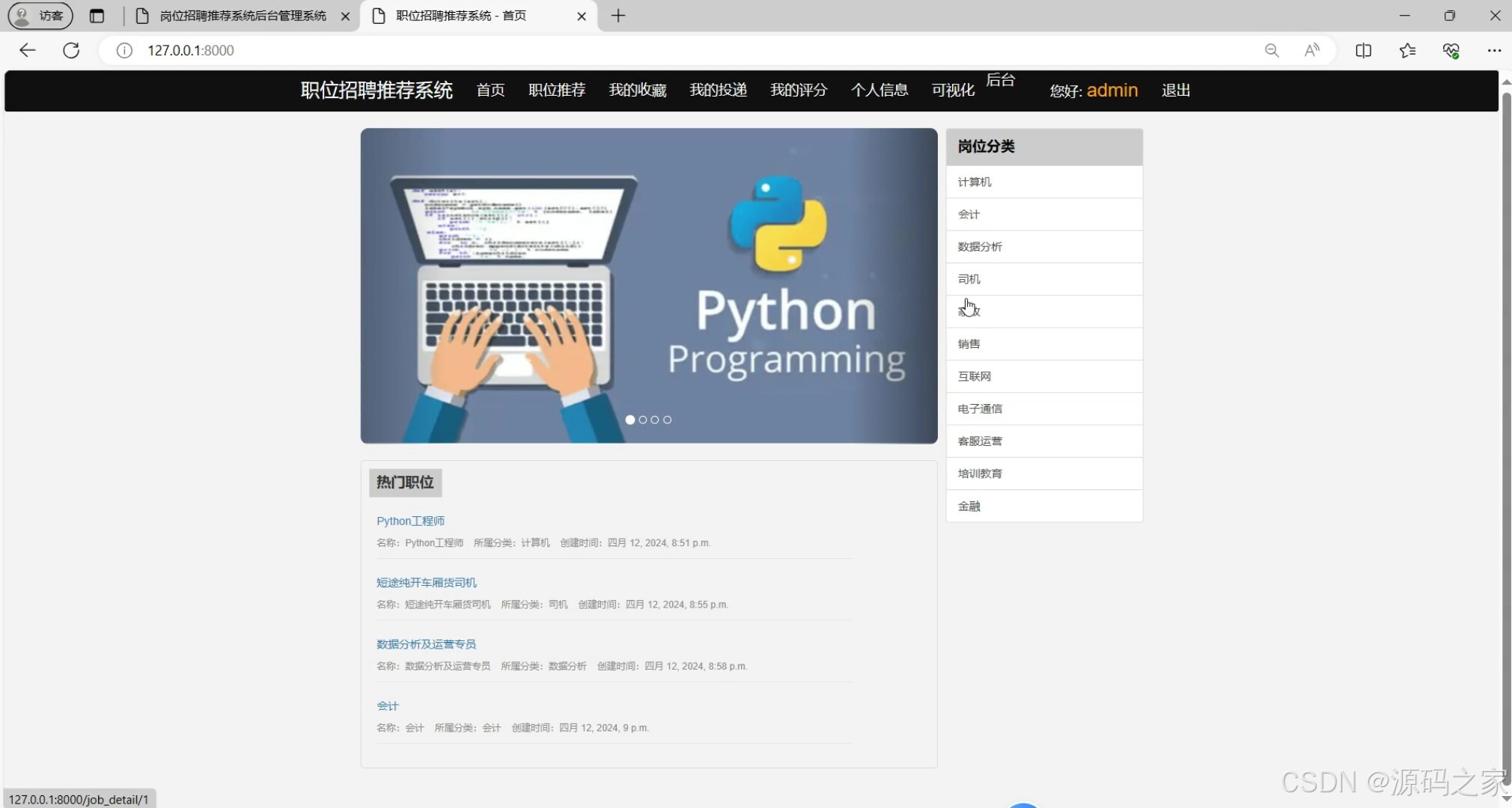
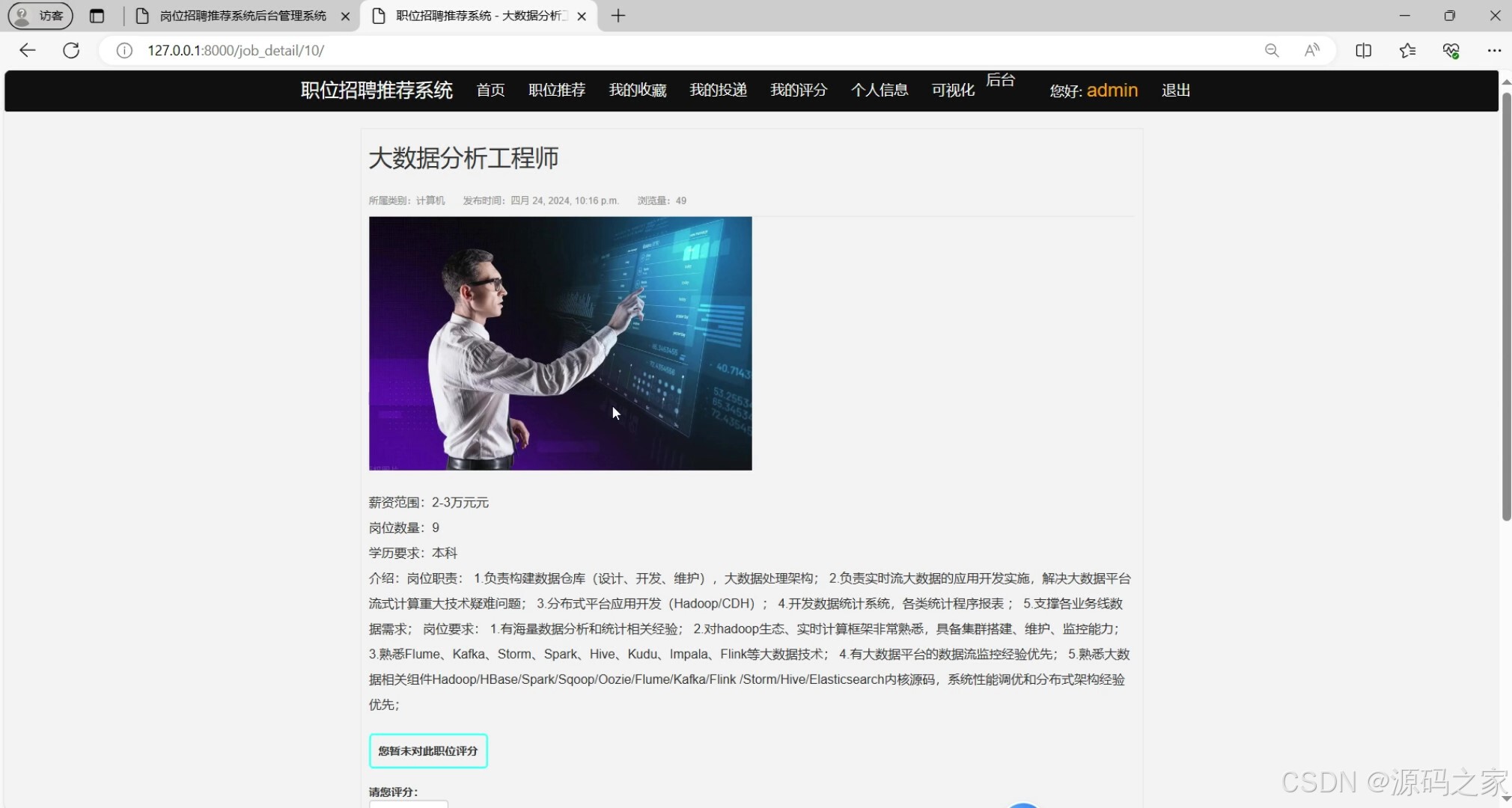
(2)职位详情页
(3)职位推荐
(4)用户评分、投递简历、收藏、留言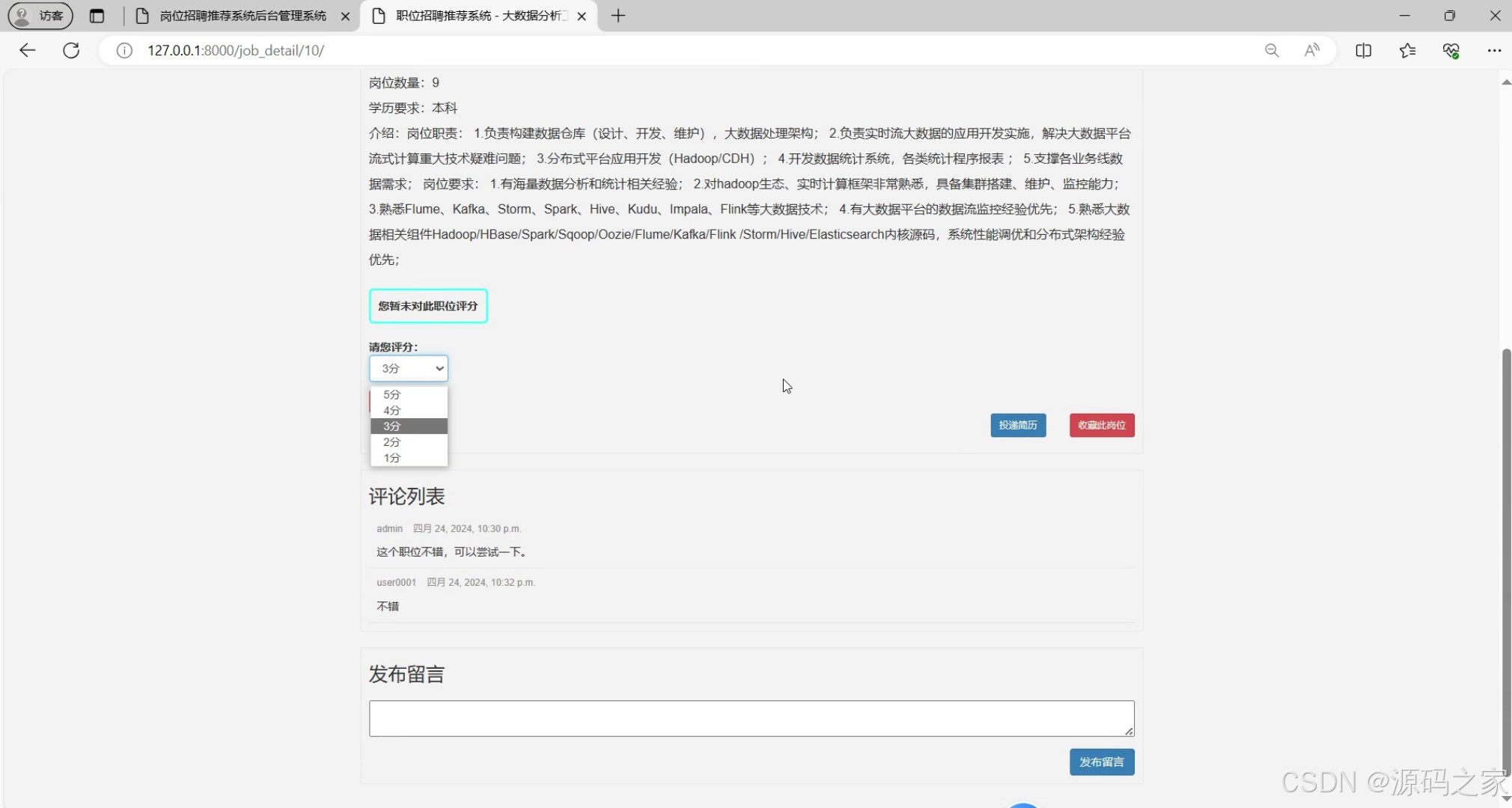
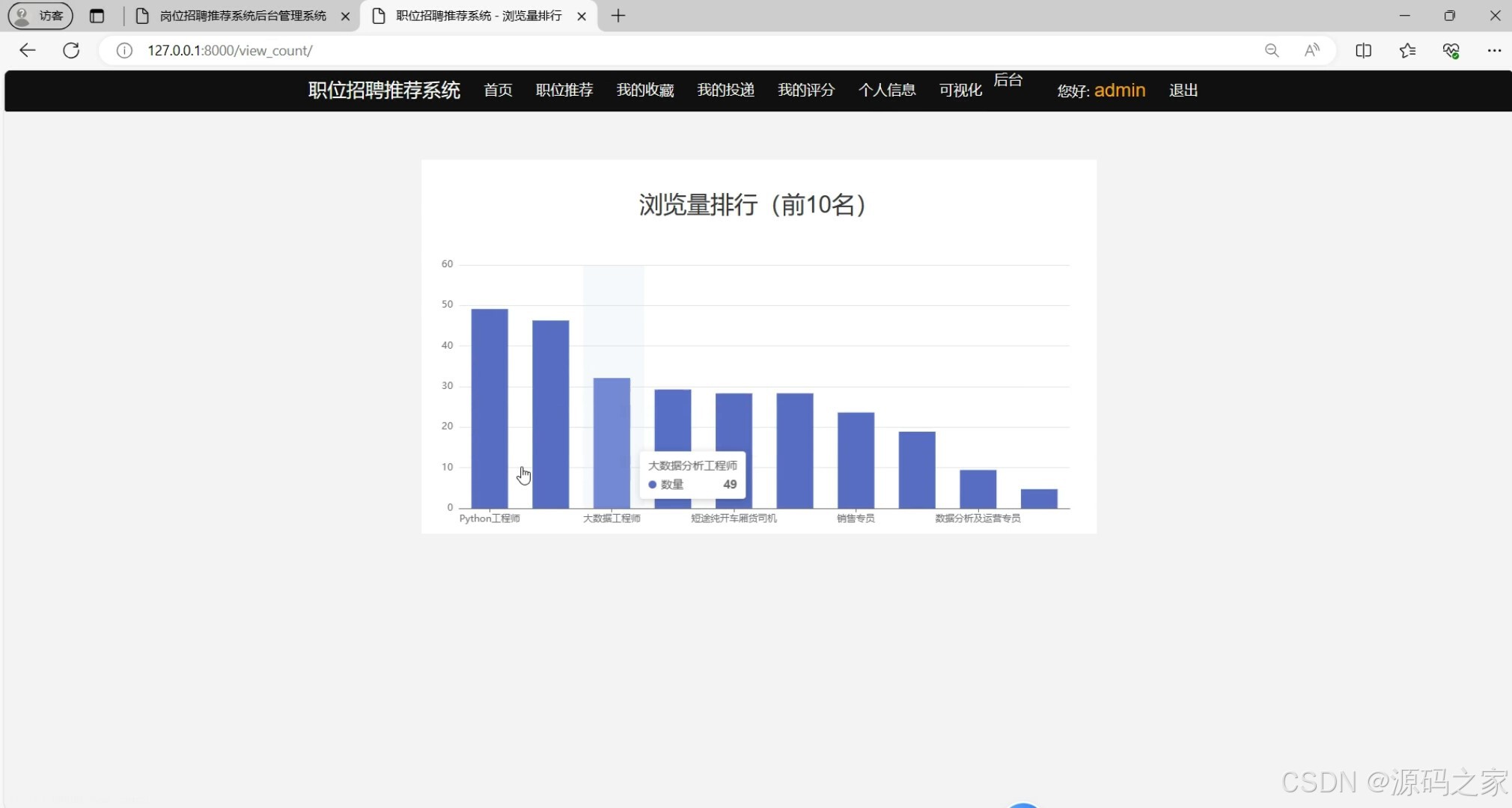
(5)数据可视化分析
(6)投递信息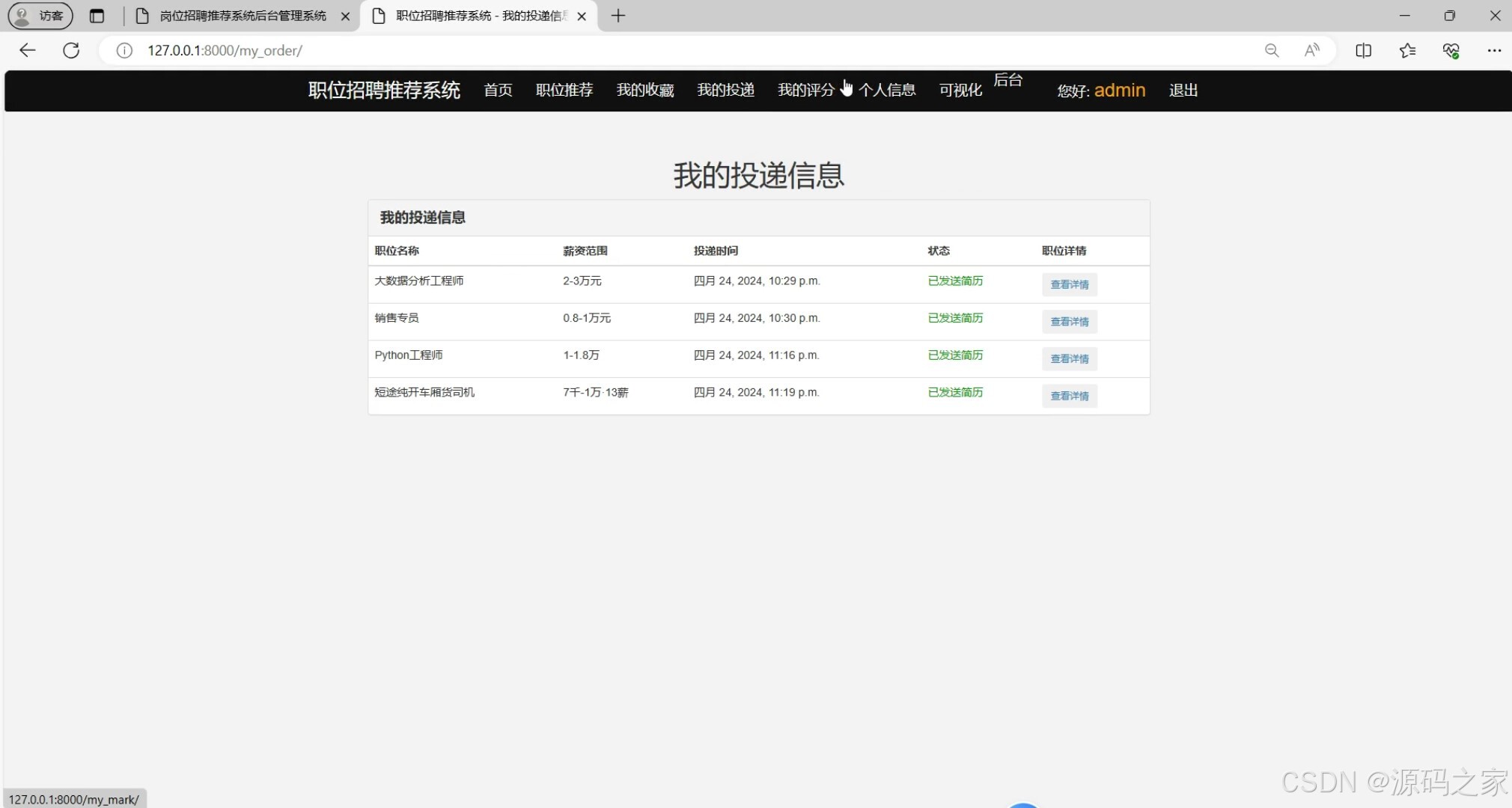
(7)我的收藏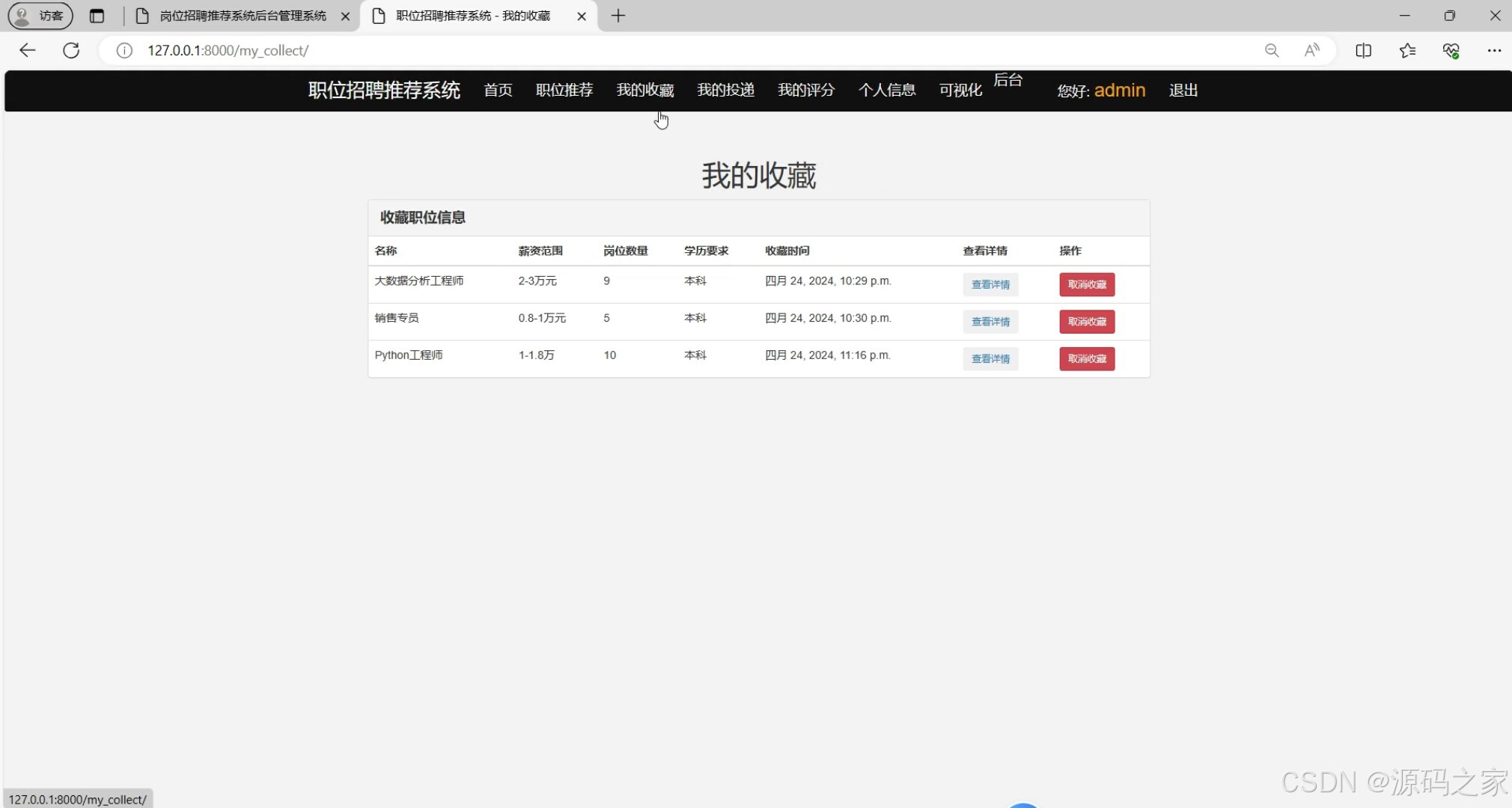
(8)后台数据管理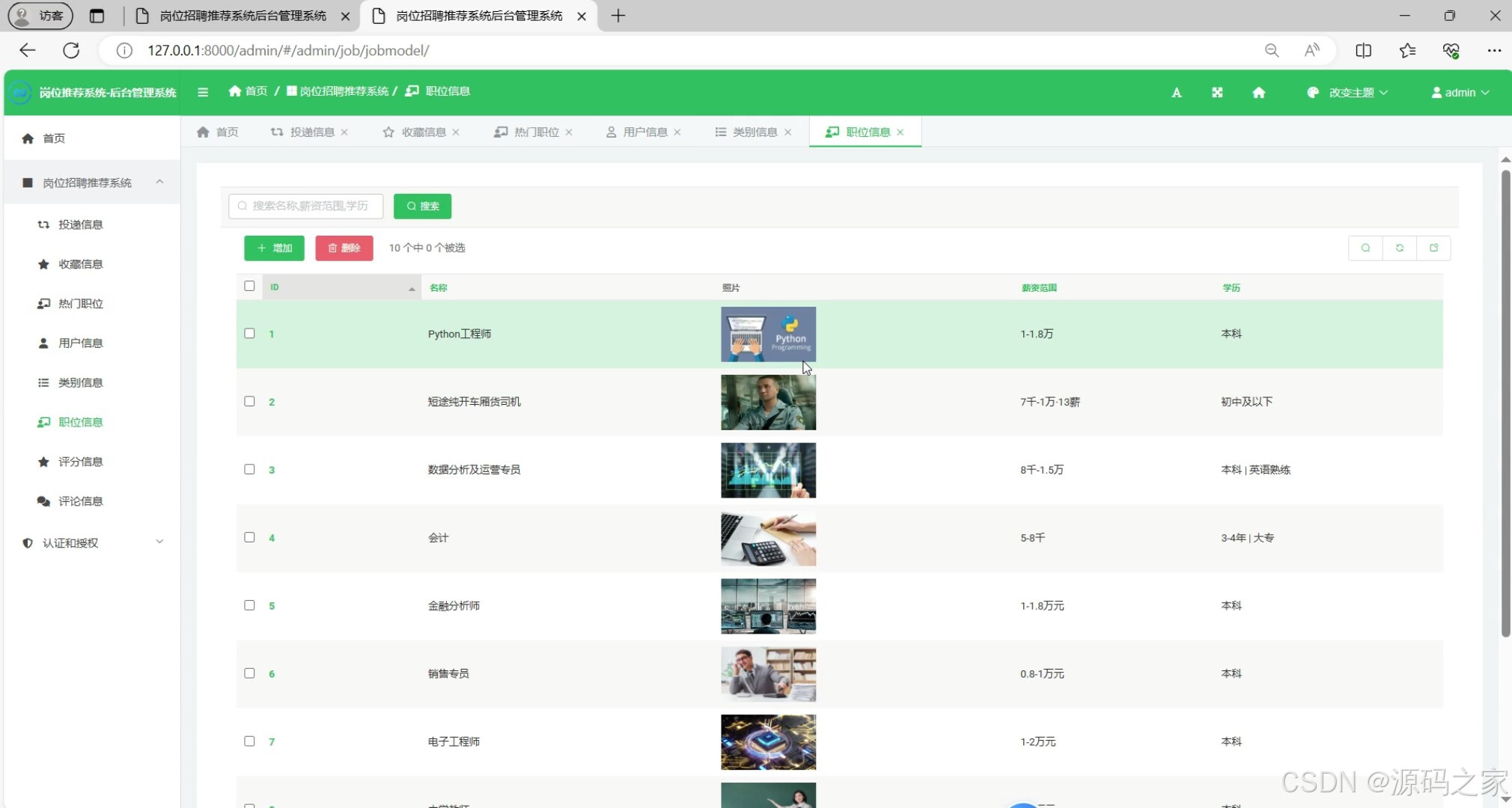
3、项目说明
项目介绍:基于Python+Django+MySQL的岗位招聘推荐系统
在当今数字化时代,招聘行业正迅速向智能化、个性化方向发展。为了帮助企业和求职者更有效地匹配岗位与人才,我们开发了一款基于Python、Django框架、MySQL数据库以及基于用户的协同过滤算法的岗位招聘推荐系统。该系统不仅提供了用户登录、注册、岗位查看、评论、评分、简历投递等基础功能,还通过先进的推荐算法为用户提供个性化的岗位推荐,极大地提升了用户体验和招聘效率。
技术栈与项目结构
项目采用Python作为开发语言,得益于其简洁的语法和丰富的第三方库,使得开发过程更加高效。Django框架则提供了强大的Web开发功能,包括ORM(对象关系映射)、模板引擎、用户认证等,大大简化了后端开发流程。MySQL作为数据库,保证了数据的高可靠性和可扩展性。前端使用Bootstrap进行界面渲染设计,使得页面布局美观、响应速度快。同时,结合Echarts进行数据可视化,为用户提供直观的图表分析展示。
主要功能模块
用户管理:提供用户登录、注册、退出登录功能,确保用户信息的安全性和隐私性。用户可以通过简单的操作完成账号的创建和登录,享受个性化的服务。
前台功能:用户可以在前台查看岗位信息,包括岗位名称、职位描述、薪资待遇等。同时,用户可以对岗位进行评论和评分,为其他求职者提供参考。此外,用户还可以投递简历到感兴趣的岗位,并查看系统为其推荐的岗位列表。通过Echarts,用户可以直观地看到岗位评分分布、热门岗位排行等图表分析。
后台管理:管理员可以在后台进行岗位管理,包括岗位的添加、编辑、删除等操作。同时,管理员还可以管理用户信息、评论信息、打分信息等,确保数据的准确性和完整性。分类管理功能使得岗位信息更加有序,方便用户查找。
推荐系统:基于用户的协同过滤算法是项目的核心亮点。该算法通过分析用户的评论和评分行为,计算用户之间的相似度,从而为每个用户推荐可能感兴趣的岗位。推荐列表不仅提高了用户的满意度,也为企业提供了更精准的招聘服务。
总结
本项目通过整合先进的技术栈和创新的推荐算法,为招聘行业带来了全新的解决方案。它不仅提高了招聘效率,还为用户提供了个性化的服务体验。无论是求职者还是企业,都能从中受益,实现双赢。未来,我们将继续优化算法,拓展功能,为用户提供更加智能、便捷的招聘推荐服务。
项目结构清晰,分为多个模块:
JobRecommendSystem:主模块,包含项目的主路由和配置文件,是项目的核心部分。
media:用于存放用户上传的图片等多媒体文件,实现文件的动态管理。
front:前端文件,包括HTML、CSS、JS等,负责页面的渲染和交互逻辑。
job:岗位招聘推荐系统的业务逻辑实现,包括岗位管理、用户管理、评论管理、打分管理等核心功能。
utils:工具类,存储了登录用户数据处理、推荐算法实现等辅助方法。
venv:项目虚拟环境,隔离了项目依赖,保证了环境的一致性。
manage.py:项目管理文件,作为项目的入口,用于启动服务器、创建应用、迁移数据库等。
4、核心代码
# 投递简历
def add_order(request):
user_id = request.session.get('user_id')
if not user_id:
return JsonResponse({'code': 400, 'message': '请先登录'})
job_id = request.POST.get('job_id')
flag = OrderModel.objects.filter(user_id=user_id, job_id=job_id).first()
if flag:
return JsonResponse({'code': 400, 'message': '您已投递该岗位,请勿重复投递!'})
OrderModel.objects.create(
user_id=user_id,
job_id=job_id
)
return JsonResponse({'code': 200})
# 添加收藏
def add_collect(request):
user_id = request.session.get('user_id')
if not user_id:
return JsonResponse({'code': 400, 'message': '请先登录'})
job_id = request.POST.get('job_id')
flag = CollectModel.objects.filter(user_id=user_id, job_id=job_id).first()
if flag:
return JsonResponse({'code': 400, 'message': '您已收藏该岗位,请勿重复收藏!'})
CollectModel.objects.create(
user_id=user_id,
job_id=job_id
)
return JsonResponse({'code': 200})
# 添加评论
def add_comment(request):
user_id = request.session.get('user_id')
if not user_id:
return JsonResponse({'code': 400, 'message': '请先登录'})
content = request.POST.get('content')
job_id = request.POST.get('job_id')
if not content:
return JsonResponse({'code': 400, 'message': '内容不能为空'})
CommentModel.objects.create(
user_id=user_id,
content=content,
job_id=job_id
)
return JsonResponse({'code': 200})
# 用户对岗位进行评分
def input_score(request):
user_id = request.session.get('user_id')
if not user_id:
return JsonResponse({'code': 400, 'message': '请先登录'})
score = int(request.POST.get('score'))
item_id = request.POST.get('job_id')
mark = MarkModel.objects.filter(item_id=item_id, user_id=user_id).first()
if mark:
mark.score = score
mark.save()
else:
MarkModel.objects.create(
item_id=item_id,
score=score,
user_id=user_id
)
return JsonResponse({'code': 200})
# 我的收藏
def my_collect(request):
user_id = request.session.get('user_id')
collects = CollectModel.objects.filter(user_id=user_id)
return render(request, 'my_collect.html', {'collects': collects})
# 取消收藏
def delete_collect(request):
collect_id = request.POST.get('collect_id')
collect = CollectModel.objects.get(id=collect_id)
collect.delete()
return JsonResponse({'code': 200})
# 我的投递信息
def my_order(request):
user_id = request.session.get('user_id')
orders = OrderModel.objects.filter(user_id=user_id)
return render(request, 'my_order.html', {'orders': orders})
# 我的评分信息
def my_mark(request):
user_id = request.session.get('user_id')
marks = MarkModel.objects.filter(user_id=user_id)
return render(request, 'my_mark.html', {'marks': marks})
# 个人信息
def my_info(request):
user_id = request.session.get('user_id')
if request.method == 'GET':
# 个人信息界面
info = UserInfoModel.objects.get(id=user_id)
return render(request, 'my_info.html', {'info': info})
else:
# 更新个人信息
username = request.POST.get('username')
password = request.POST.get('password')
phone = request.POST.get('phone') or ''
edu_level = request.POST.get('edu_level') or ''
major = request.POST.get('major') or ''
age = request.POST.get('age') or ''
content = request.POST.get('content') or ''
UserInfoModel.objects.filter(
id=user_id
).update(
username=username,
password=password,
phone=phone,
edu_level=edu_level,
major=major,
age=age,
content=content,
)
return JsonResponse({'code': 200})
# 浏览量统计
def view_count(request):
if request.method == 'GET':
return render(request, 'view_count.html')
else:
jobs = JobModel.objects.all().order_by('-view_number')[:10]
name_list = []
count_list = []
for job in jobs:
name_list.append(job.name)
count_list.append(job.view_number)
return JsonResponse({'code': 200, 'name_list': name_list, 'count_list': count_list})
# 计算两用户的余弦相似度
def calculate_cosine_similarity(user_ratings1, user_ratings2):
# 将用户1的职位评分存入字典,键为职位ID,值为评分 1:5 2:3
item_ratings1 = {rating.item_id: rating.score for rating in user_ratings1}
print('item_ratings1:', item_ratings1)
# 将用户2的职位评分存入字典,键为职位ID,值为评分 1:4
item_ratings2 = {rating.item_id: rating.score for rating in user_ratings2}
print('item_ratings2:', item_ratings2)
# 找出两个用户共同评价过的职位 1
common_items = set(item_ratings1.keys()) & set(item_ratings2.keys())
print('common_items:', common_items)
if len(common_items) == 0:
return 0.0 # 无共同评价的职位,相似度为0
# 提取共同评价职位的评分,存入NumPy数组
user1_scores = np.array([item_ratings1[item_id] for item_id in common_items]) # 5
user2_scores = np.array([item_ratings2[item_id] for item_id in common_items]) # 4
print('user1_scores:', user1_scores)
print('user2_scores:', user2_scores)
# 计算余弦相似度
cosine_similarity = np.dot(user1_scores, user2_scores) / (
np.linalg.norm(user1_scores) * np.linalg.norm(user2_scores))
print('cosine_similarity:', cosine_similarity)
return cosine_similarity
# 基于用户协同过滤推荐
def user_based_recommendation(request, user_id):
try:
# 获取目标用户对象
target_user = UserInfoModel.objects.get(id=user_id)
except UserInfoModel.DoesNotExist:
return JsonResponse({'code': 400, 'message': '该用户不存在'})
# 获取目标用户的职位评分记录
target_user_ratings = MarkModel.objects.filter(user=target_user)
# 用于存储推荐职位的字典
recommended_items = {}
# 遍历除目标用户外的所有其他用户 test1 bhml
for other_user in UserInfoModel.objects.exclude(pk=user_id):
# 获取其他用户的职位评分记录
other_user_ratings = MarkModel.objects.filter(user=other_user)
# 计算目标用户与其他用户的相似度
similarity = calculate_cosine_similarity(target_user_ratings, other_user_ratings)
if similarity > 0:
# 遍历其他用户评价的职位
for item_rating in other_user_ratings:
# 仅考虑目标用户未评价过的职位
if item_rating.item.id not in target_user_ratings.values_list('item', flat=True):
if item_rating.item.id in recommended_items:
# 累积相似度加权的评分和相似度
recommended_items[item_rating.item.id]['score'] += similarity * item_rating.score
recommended_items[item_rating.item.id]['similarity'] += similarity
else:
# 创建推荐职位的记录
recommended_items[item_rating.item.id] = {'score': similarity * item_rating.score,
'similarity': similarity}
# 将推荐职位按照加权评分排序
sorted_recommended_items = sorted(recommended_items.items(), key=lambda x: x[1]['score'], reverse=True)
# 获取排名靠前的推荐职位的ID
top_recommended_items = [item_id for item_id, _ in sorted_recommended_items[:5]]
# 构建响应数据
response_data = []
for item_id in top_recommended_items:
item = JobModel.objects.get(pk=item_id)
similarity = recommended_items[item_id]['similarity']
response_data.append({
'job': item,
'name': item.name,
'id': item.id,
'image': item.image,
'similarity': similarity,
})
context = {
'response_data': response_data
}
return render(request, 'job_recommend.html', context=context)
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
https://mbd.pub/o/author-aWiYmGxnZA==/work
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 14
14 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)