
入门神经网络——识别图片是否为猫
浅层神经网络学习
·
一、环境准备
1.将下载的Anaconda与pycharm关联:
(1)点击File->Setting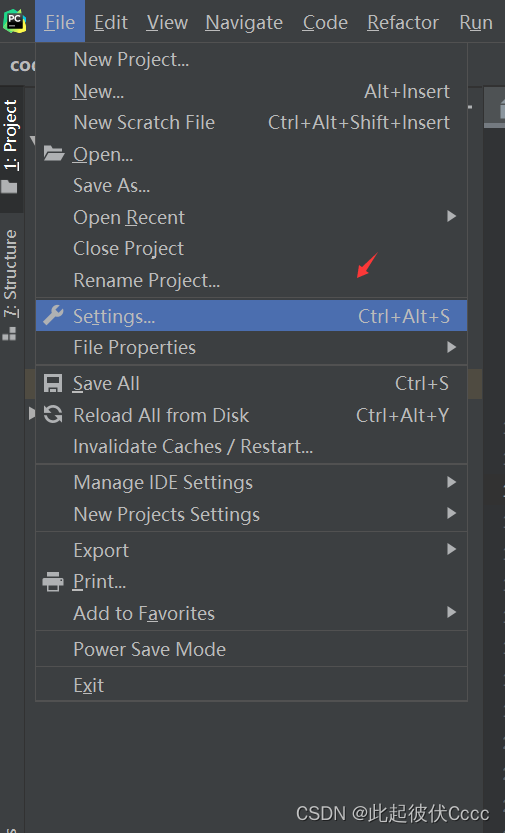 (2)选择Project:codes->Python Interpreter
(2)选择Project:codes->Python Interpreter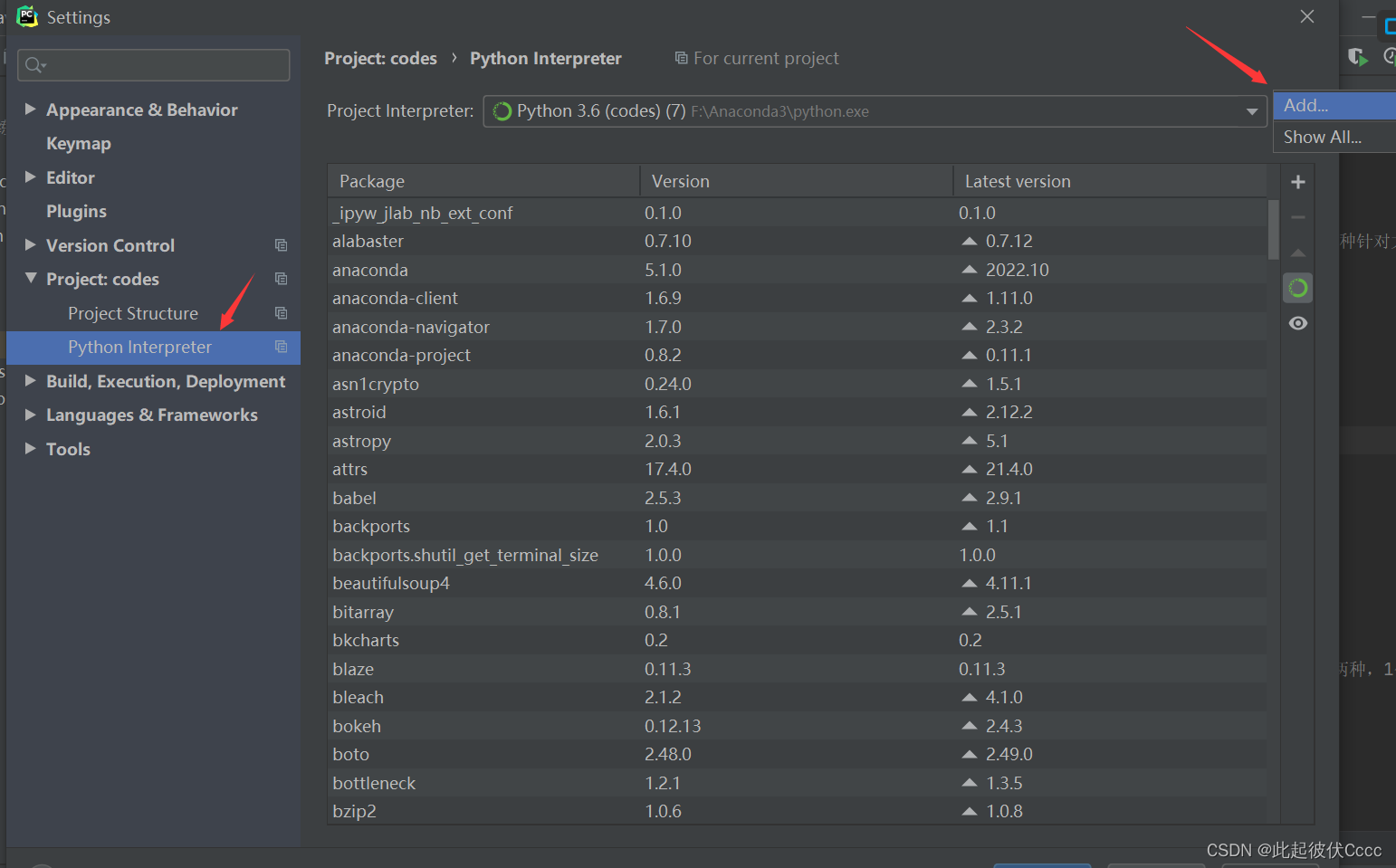 (3)添加已经安装的Anaconda环境
(3)添加已经安装的Anaconda环境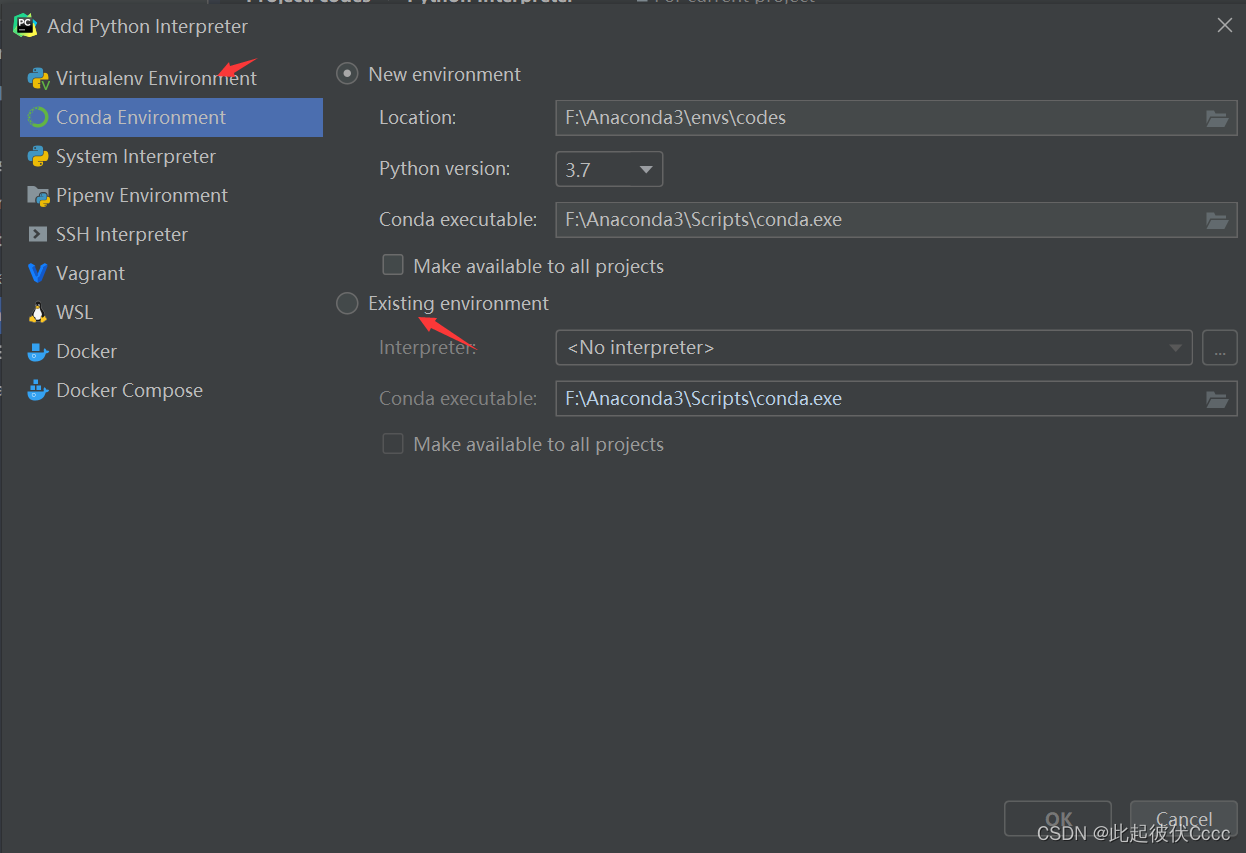 (4)路径参考如下
(4)路径参考如下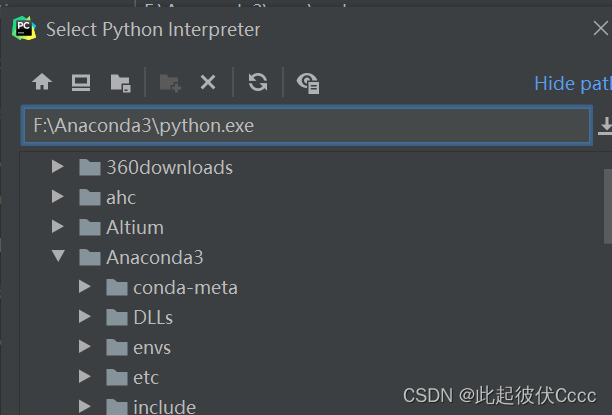
2.准备需要的文件
在pycharm中新建的工程中,添加两个需要存放数据的文件夹
datasets和images文件夹:
datasets:存放训练集和测试集h5照片,是这里的内容h5训练集
将里面的内容复制到此文件夹中
images:存放需要测试的照片,例:
二、代码编写
1.需要导入的库
import numpy as np # 加载numpy工具库并给它取个别名为np,后面就可以通过np来调用numpy工具库里面的函数了。numpy是python的一个科学计算工具库,
# 除了前面文章中提到的它可以用来进行向量化之外,它还有很多常用的功能。非常非常常用的一个工具库!
import matplotlib.pyplot as plt # 这个库是用来画图的
import h5py # 这个库是用来加载训练数据集的。我们数据集的保存格式是HDF。Hierarchical Data Format(HDF)是一种针对大量数据进行组织和存储的
# 文件格式,大数据行业和人工智能行业都用它来保存数据。
import skimage.transform as tf # 这里我们用它来缩放图片
2.定义的函数
(1)load_dataset:载入训练集、测试集样本的特征值和标签
# 载入训练集、测试集样本的特征值和标签
def load_dataset():
train_dataset = h5py.File('../datasets/train_catvnoncat.h5', "r") # 打开训练集的h5文件
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # 打开训练集中的特征值
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # 打开训练集中的标签
test_dataset = h5py.File('../datasets/test_catvnoncat.h5', "r") # 打开测试集的h5文件
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # 打开测试集中的特征值
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # 打开测试集中的标签
classes = np.array(test_dataset["list_classes"][:]) # 打开测试集中的标签类别数据,这里的类别只有两种,1代表有猫,0代表无猫
# 对训练集、测试集中的标签进行维度变换
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
(2)sigmoid:激活函数
# sigmoid函数
def sigmoid(z):
a = 1 / (1 + np.exp(-z))
return a
(3)init_zero:初始化权重w以及阈值b函数
# 初始化权重w以及阈值b函数
def init_zero(w_size):
"""
参数说明:
w_size:w的大小,即有多少权重
返回值:
w:返回的权重矩阵
b:阈值
"""
w = np.zeros((w_size, 1))
b = 0.
return w, b
(4)propagate:前向传播和传播求得dw,db,cost,为梯度下降做准备
# 前向传播,计算出dw,db,cost
def propagate(w, b, X, Y):
"""
:param w:权重矩阵
:param b: 阈值
:param X: 样本矩阵
:param Y: 标签
:return: dw,db,cost
"""
m = X.shape[1] # m为样本的总数量
A = sigmoid(np.dot(w.T, X) + b)
cost = -np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A)) / m
dZ = A - Y
dw = np.dot(X, dZ.T) / m
db = np.sum(dZ) / m
# dw,db保存到字典中
grands = {
"dw": dw,
"db": db
}
return grands, cost
(5)optimize:梯段下降算法,不断的优化w,b使得cost最小
# 梯段下降算法,优化w,b
def optimize(w, b, X, Y, optimize_times, learning_rate, print_cost=False):
"""
:param w: 权重矩阵
:param b: 阈值
:param X: 样本矩阵
:param Y: 标签矩阵
:param optimize_times:优化次数
:param learning_rate: 学习率:w = w'-learning_rate*dw
:param print_cost:为True时,每优化100次就把成本cost打印出来,以便我们观察成本的变化
:return:params:优化后w,b
costs:每优化100次,将成本记录下来,成本越小,表示参数越优化
"""
costs = [] # 用来记录花费的列表
for i in range(optimize_times):
grads, cost = propagate(w, b, X, Y)
# 从propagate返回的字典中得到db,dw
db = grads["db"]
dw = grads["dw"]
# 梯度下降优化w,b
w = w - learning_rate * dw
b = b - learning_rate * db
if i % 100 == 0:
costs.append(cost)
if print_cost:
print("优化%i次后的成本是:%f" % (i, cost))
params = {
"w": w,
"b": b
}
return params, costs
(6)predict:预测函数,利用优化后的w,b进行预测
# 预测函数,利用优化后的w,b进行预测
def predict(w, b, X):
"""
:param w:优化后的权重w
:param b: 优化好的阈值b
:param X: 要进行预测的样本
:return: Y_prediction -- 对每张图片的预测结果
"""
m = X.shape[1] # 输入的样本数量
Y_prediction = np.zeros((1, m)) # 存储对每一个样本预测的标签,并初始化为0
A = sigmoid(np.dot(w.T, X) + b) # 对样本的预测概率,A中的每一个值是对每一个样本预测概率值为小数
for i in range(m):
if A[0, i] >= 0.5:
Y_prediction[0, i] = 1
return Y_prediction
(7)model:神经网络模型函数
# 神经网络模型函数
def model(train_X, train_Y, test_X, test_Y, optimize_times, learning_rate, print_cost):
"""
:param train_X: 训练集特征值 (12288,209)
:param train_Y:训练集标签(1,209)
:param test_X: 测试集特征值(12288,50)
:param test_Y:测试集标签(1,50)
:param optimize_times:优化次数
:param learning_rate:学习率
:param print_cost:是否打印花费
:return:训练后返回的信息
"""
# 初始化训练集w,b
w, b = init_zero(train_X.shape[0])
optimized_params, costs = optimize(w, b, train_X, train_Y, optimize_times, learning_rate, print_cost)
opt_w = optimized_params["w"]
opt_b = optimized_params["b"]
# 用优化好的参数w,b进行预测
train_Y_prediction = predict(opt_w, opt_b, train_X) # 对训练集中的样本进行预测
test_Y_prediction = predict(opt_w, opt_b, test_X) # 对训练集中的样本进行预测
# 输出预测的准确率
print("对训练图片的预测准确率为: {}%".format(100 - np.mean(np.abs(train_Y_prediction - train_Y)) * 100))
print("对测试图片的预测准确率为: {}%".format(100 - np.mean(np.abs(test_Y_prediction - test_Y)) * 100))
d = {
"costs": costs,
"test_Y_prediction": test_Y_prediction,
"train_Y_prediction": train_Y_prediction,
""
"w": opt_w,
"b": opt_b,
"learning_rate": learning_rate,
"optimize_times": optimize_times
}
return d
(8)一些输出图片的函数
# 做cost随着优化次数的图
def paint_costs(costs_in):
"""
:param costs_in: 传入的花费数组
:return:
"""
plt.plot(costs_in)
plt.ylabel('cost') # 成本
plt.xlabel('iterations (per hundreds)') # 横坐标为训练次数,以100为单位
plt.title("Learning rate =" + str(d["learning_rate"]))
plt.show()
# 比较不同学习率对花费的不同效果
def paint_learning_rates_costs():
learning_rates = [0.01, 0.001, 0.0001]
models = {}
for i in learning_rates:
print("当学习率是" + str(i) + "时")
models[str(i)] = model(train_set_x, train_set_y, test_set_x, test_set_y, 2000, i, False)
print('\n' + "-------------------------------------------------------" + '\n')
for i in learning_rates:
plt.plot(models[str(i)]["costs"], label=str(models[str(i)]["learning_rate"]))
plt.ylabel('cost')
plt.xlabel('iterations (hundreds)')
""""
plt.legend()的作用:
在plt.plot() 定义后plt.legend() 会显示该 label 的内容,否则会报error: No handles with labels
"""
legend = plt.legend(loc='upper center', shadow=True)
""""
frame :画框架
"""
frame = legend.get_frame()
frame.set_facecolor('0.9')
plt.show()
# 测试自己图片是否为猫
def predict_self_picture(file_path, w, b):
"""
:param file_path: 传入的图片
:param w:优化后的w
:param b:优化后的b
:return:
"""
image = np.array(plt.imread(file_path))
my_image = tf.resize(image, (64, 64), mode='reflect').reshape((1, 64 * 64 * 3)).T
my_predicted_image = predict(w, b, my_image)
plt.imshow(image)
plt.show()
ret = int(my_predicted_image)
return ret # 0 :是猫 1:不是猫
3.代码实现:
注:需将上述函数定义在前面
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()
# 将训练集与测试集的样本进行数据扁平化,与转秩,处理后的矩阵为12288*209与12288*50
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T
# 将训练集与测试集的每个特征值/255 将每个特征值缩放到0~1之间(特征值存放的是每一个像素大小,像素范围是0~255)
train_set_x = train_set_x_flatten / 255
test_set_x = test_set_x_flatten / 255
d = model(train_set_x, train_set_y, test_set_x, test_set_y, 2000, 0.002, True)
# 画出花费cost 随着优化次数的变化
paint_costs(np.squeeze(d["costs"])) # np.squeeze(d["costs"])将返回的字典中的花费一项提出并保存为列表
# 比较不同学习率对花费的不同效果
paint_learning_rates_costs()
# 测试自己的图片是不是猫
my_image = "my_image3.jpg"
file_name = "../images/" + my_image
ret = predict_self_picture(file_name, d["w"], d["b"])
if ret == 1:
print("预测结果是猫")
else:
print("预测结果不是猫")
4.运行结果
cost随着优化次数变化的图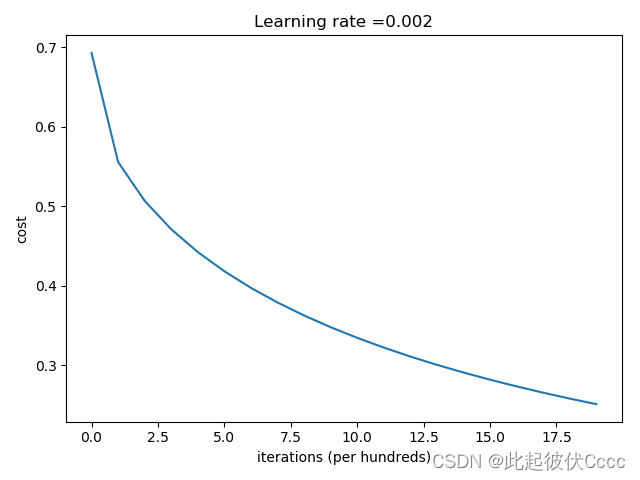
比较不同学习率对花费的不同效果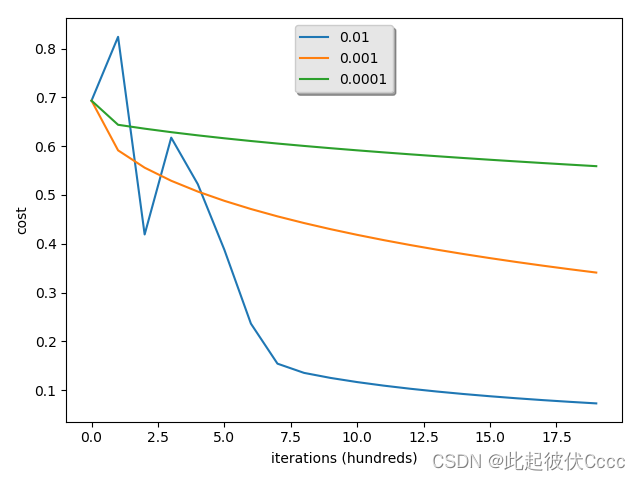
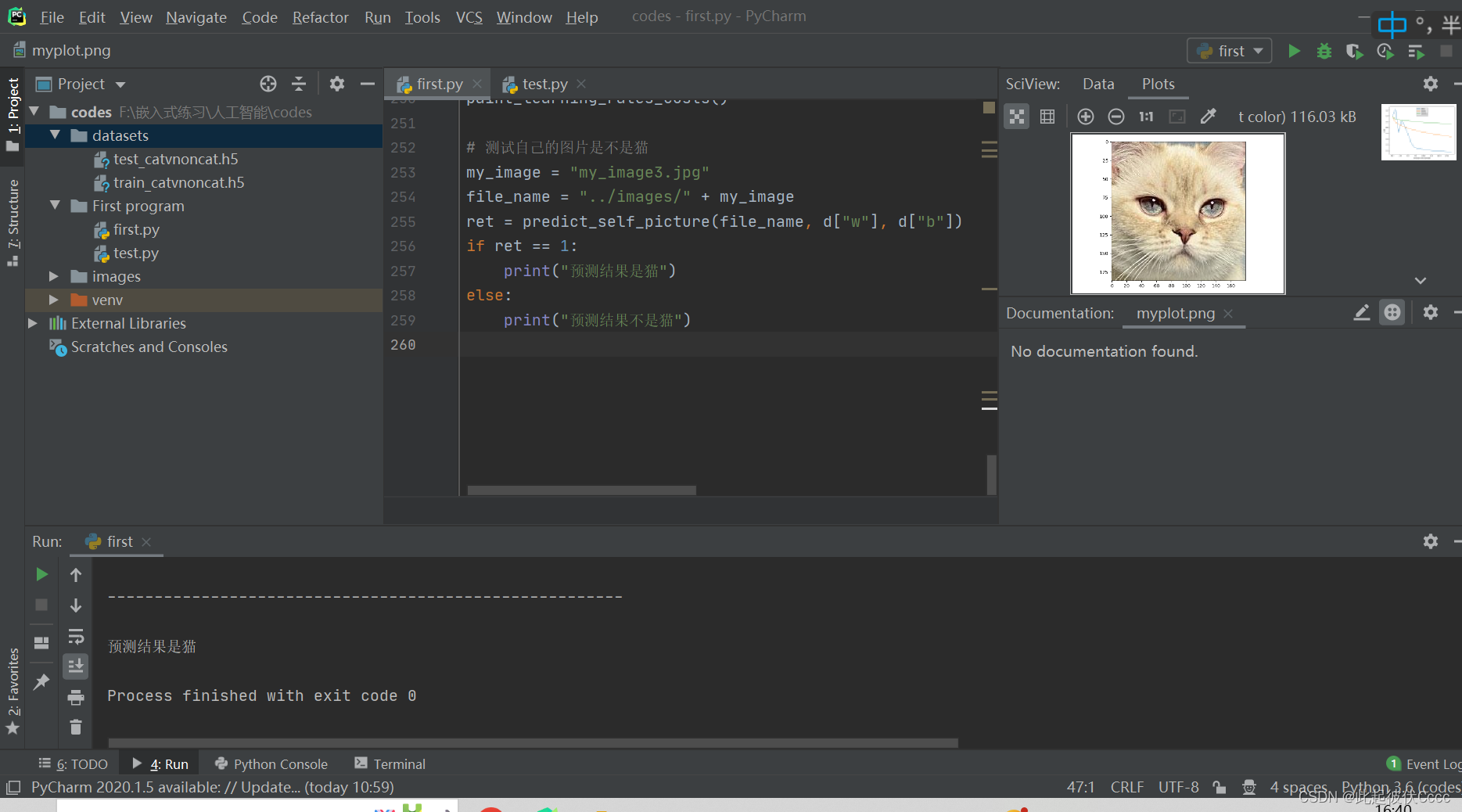
且成功预测传入的照片为猫

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)