
机器学习算法的核心原理与应用探索
机器学习算法不仅是人工智能的“发动机”,更是推动智能化社会转型的关键工具。从基础的线性模型到复杂的深度神经网络,算法的迭代与优化持续驱动着产业变革。未来,随着算法可解释性与泛化能力的提升,机器学习将在更多高价值场景中展现其潜能。
在人工智能的广阔版图中,机器学习算法(Machine Learning Algorithms) 是支撑其发展的基石。无论是图像识别、自然语言处理,还是推荐系统和预测建模,背后都离不开不同类型的机器学习算法。本文将从基本原理、主要分类以及实际应用场景三个维度出发,对机器学习算法进行系统梳理。
一、机器学习算法的核心思想
机器学习的核心思想在于“通过数据学习规律,并在未知数据上进行预测”。与传统的显式编程不同,机器学习更强调模型对数据模式的自动捕捉。一个典型的机器学习过程通常包括数据预处理、特征提取、模型训练、模型验证与优化等环节。
算法在其中扮演的角色,实际上是“函数逼近器”:它通过输入和输出的映射关系,不断调整参数,使预测结果尽可能接近真实值。
二、机器学习算法的主要分类
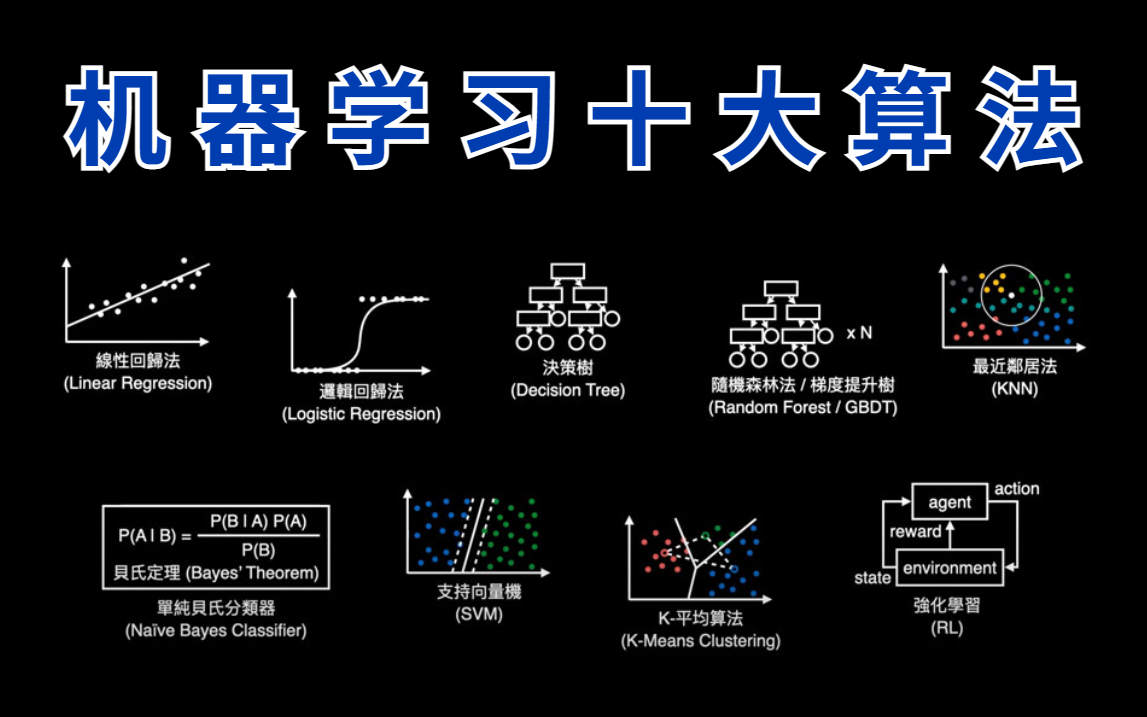
1. 监督学习(Supervised Learning)
监督学习是目前应用最广泛的机器学习范式,其特点是训练数据带有明确标签。算法通过已知样本的输入与输出对,学习映射关系,并在新数据上进行预测。
常见算法包括:
-
线性回归(Linear Regression):适用于连续型变量预测,如房价预测。
-
逻辑回归(Logistic Regression):用于分类问题,如垃圾邮件识别。
-
支持向量机(SVM):通过构造超平面实现分类,常用于高维数据分析。
-
决策树与随机森林:在分类与回归问题中均表现良好,具有较强解释性。
-
神经网络(Neural Networks):在复杂非线性关系建模中表现突出,是深度学习的基础。
2. 无监督学习(Unsupervised Learning)
无监督学习的训练数据没有标签,算法需要从数据中挖掘潜在结构。
代表算法包括:
-
聚类算法(Clustering):如 K-Means,用于用户分群、市场细分。
-
降维算法(Dimensionality Reduction):如主成分分析(PCA),用于高维数据可视化和特征压缩。
-
异常检测(Anomaly Detection):在网络安全与金融风控中应用广泛。
3. 强化学习(Reinforcement Learning)
强化学习强调“通过与环境交互获得奖励反馈,从而优化决策策略”。该类算法在博弈、自动驾驶和机器人控制等领域表现优异。典型算法有 Q-Learning、深度强化学习(Deep Reinforcement Learning)。
4. 半监督与自监督学习
在实际应用中,获取大量标注数据往往代价高昂,因此半监督与自监督学习逐渐受到重视。它们利用部分标注数据或通过数据本身构建伪标签,提升模型的泛化能力。
三、机器学习算法的应用场景
-
金融风控:通过逻辑回归和集成学习模型识别欺诈交易。
-
医疗诊断:利用卷积神经网络(CNN)分析医学影像,辅助医生诊断。
-
自然语言处理:基于深度学习的 Transformer 模型推动了机器翻译、对话系统的发展。
-
推荐系统:协同过滤与矩阵分解技术,为用户提供个性化内容推荐。
-
工业制造:通过异常检测模型实现设备预测性维护,降低运维成本。
四、挑战与未来趋势
尽管机器学习算法在诸多领域取得了突破,但仍存在挑战:
-
可解释性不足:尤其是深度学习模型,常被视为“黑箱”。
-
数据质量问题:噪声数据和偏差可能导致模型失真。
-
计算资源消耗:大规模模型的训练需要庞大算力支持。
未来,机器学习的发展趋势包括:
-
可解释性机器学习(Explainable AI, XAI),帮助人类理解模型决策过程;
-
小样本学习(Few-shot Learning) 与 零样本学习(Zero-shot Learning),缓解数据依赖;
-
跨模态学习(Multimodal Learning),实现文本、图像、语音的统一建模;
-
联邦学习(Federated Learning),在保护隐私的前提下实现多方协同训练。
结语
机器学习算法不仅是人工智能的“发动机”,更是推动智能化社会转型的关键工具。从基础的线性模型到复杂的深度神经网络,算法的迭代与优化持续驱动着产业变革。未来,随着算法可解释性与泛化能力的提升,机器学习将在更多高价值场景中展现其潜能。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)