
大数据技术之 Kafka---外部系统集成(Flume,SpringBoot)
kafka外部系统集成案例
大数据技术之 Kafka---外部系统集成(Flume,SpringBoot)
第一章.集成 Flume
Flume 是一个在大数据开发中非常常用的组件。可以用于 Kafka 的生产者,也可以用于
Flume 的消费者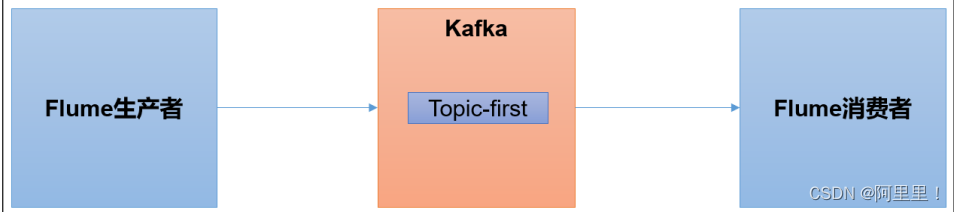
1.1 Flume作为生产者
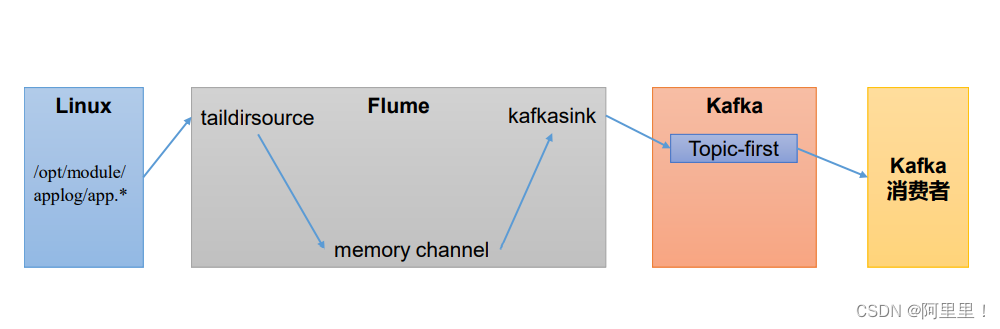
本次Flume使用的组件
(1)启动 kafka 集群
[atguigu@hadoop102 ~]$ zk.sh start
[atguigu@hadoop102 ~]$ kf.sh start
这里使用的是启动脚本,上一篇博客中有写到.
(2)启动 kafka 消费者
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
(3)Flume 安装步骤
在 hadoop102 主机上安装 Flume。(可以搜索安装教程)
(4)配置 Flume
在 hadoop102 节点的 Flume 的 job 目录下创建 file_to_kafka.conf
[atguigu@hadoop102 flume]$ mkdir jobs
[atguigu@hadoop102 flume]$ vim jobs/file_to_kafka.conf
配置文件内容如下(flume的配置都分为这五步)
具体的配置参数可在官方查看官方文档:
https://flume.apache.org/releases/content/1.10.0/FlumeUserGuide.html
# 1 组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2 配置 source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/app.*
a1.sources.r1.positionFile =
/opt/module/flume/taildir_position.json
# 3 配置 channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 4 配置 sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers =
hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.topic = first
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# 5 拼接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(5)启动 Flume
[atguigu@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f
jobs/file_to_kafka.conf &
(6)向/opt/module/applog/app.log 里追加数据,查看 kafka 消费者消费情况
[atguigu@hadoop102 module]$ mkdir applog
[atguigu@hadoop102 applog]$ echo hello >>
/opt/module/applog/app.log
(7)观察 kafka 消费者,能够看到消费的 hello 数据
查看到消费数据表示成功。
1.2 Flume 作为消费者
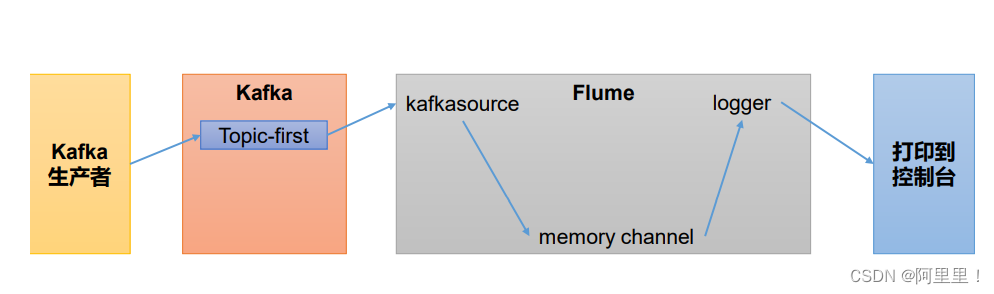
(1)配置 Flume
在 hadoop102 节点的 Flume 的/opt/module/flume/jobs 目录下创建 kafka_to_file.conf
[atguigu@hadoop102 jobs]$ vim kafka_to_file.conf
配置文件内容如下
# 1 组件定义
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 2 配置 source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 50
a1.sources.r1.batchDurationMillis = 200
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092
a1.sources.r1.kafka.topics = first
a1.sources.r1.kafka.consumer.group.id = custom.g.id
# 3 配置 channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 4 配置 sink
a1.sinks.k1.type = logger
# 5 拼接组件
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(2)启动 Flume
[atguigu@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f
jobs/kafka_to_file.conf -Dflume.root.logger=INFO,console
(3)启动 kafka 生产者
[atguigu@hadoop103 kafka]$ bin/kafka-console-producer.sh -- bootstrap-server hadoop102:9092 --topic first
并输入数据,例如:hello world
(4)观察控制台输出的日志
查看到输入表示成功,
第二章 .集成 SpringBoot
SpringBoot 是一个在 JavaEE 开发中非常常用的组件。可以用于 Kafka 的生产者,也可以
用于 SpringBoot 的消费者。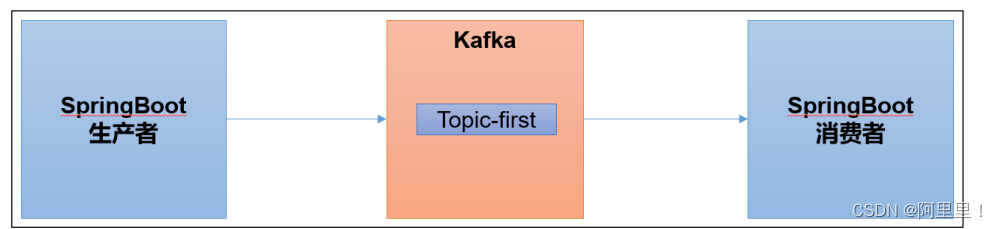
2.1 SpringBoot 环境准备
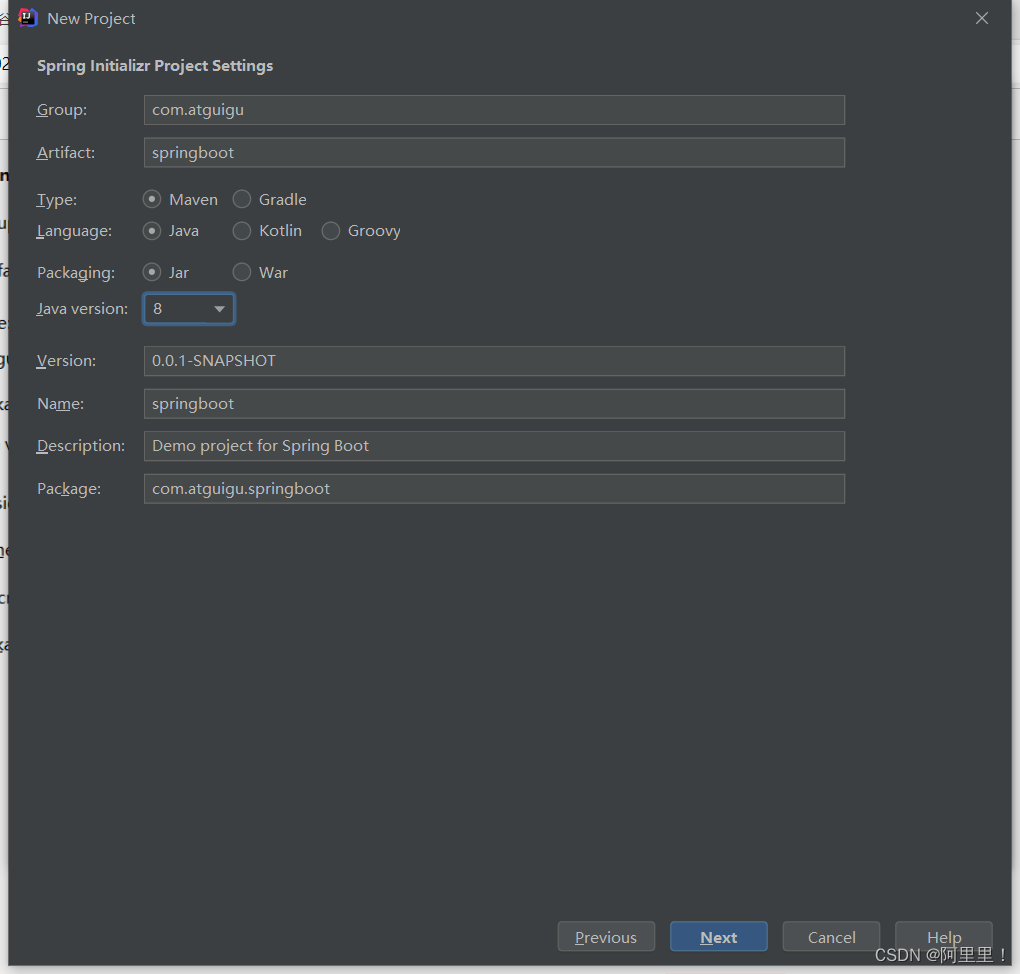
(1)创建一个 Spring Initializr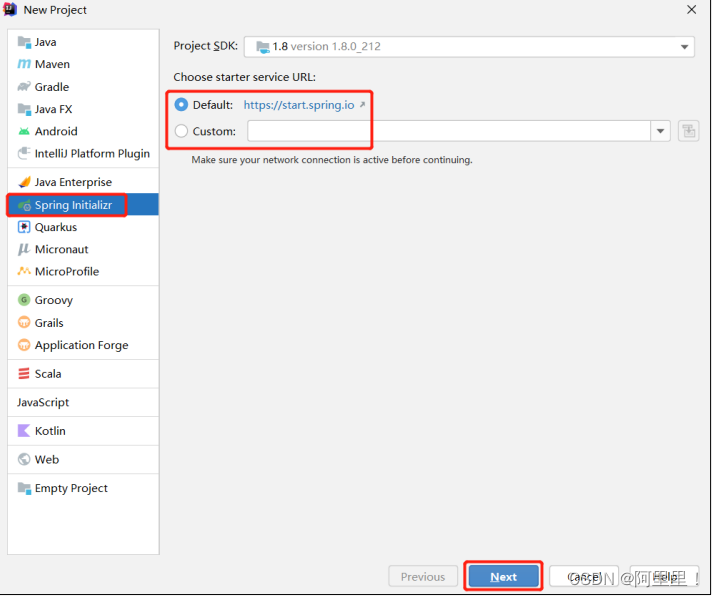
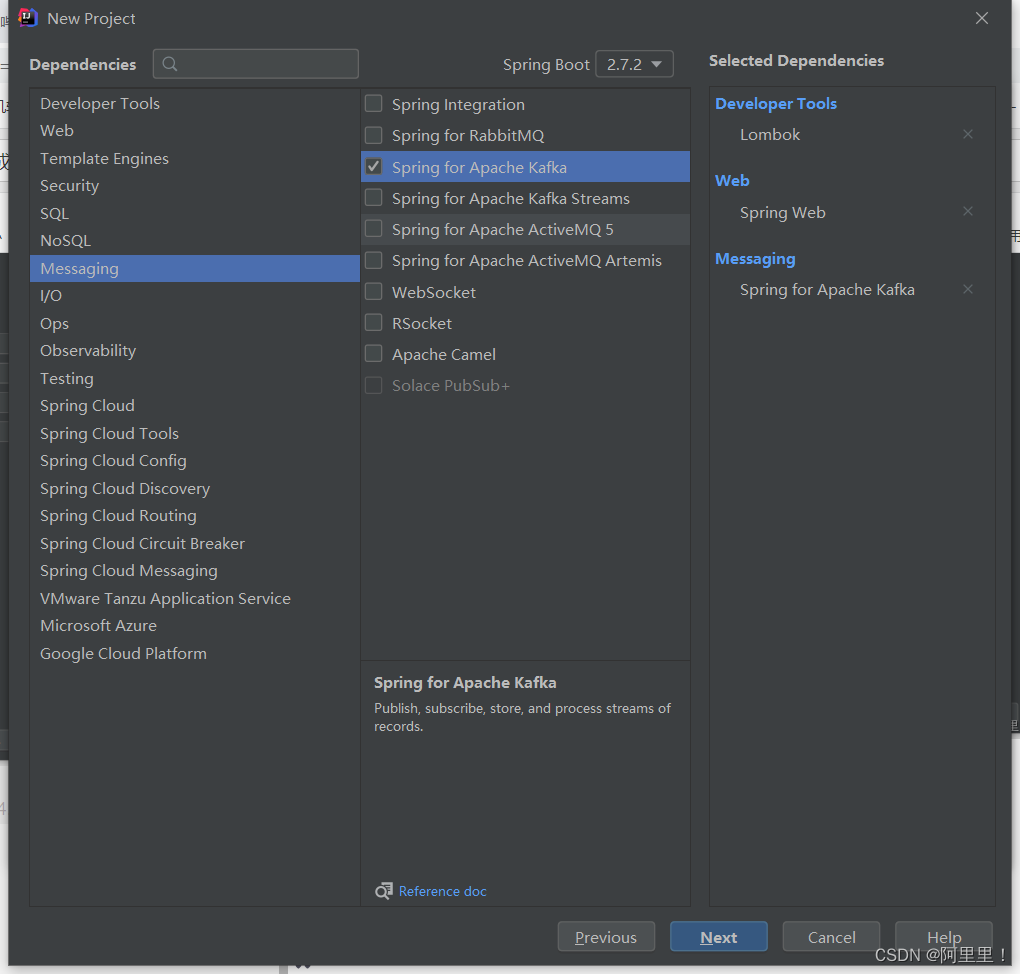
勾选需要的依赖。
2.2 Spring Boot 作为生产者
(1)修改 SpringBoot 核心配置文件 application.propeties, 添加生产者相关信息
# 应用名称
spring.application.name=atguigu_springboot_kafka
# 指定 kafka 的地址
spring.kafka.bootstrapservers=hadoop102:9092,hadoop103:9092,hadoop104:9092
#指定 key 和 value 的序列化器
spring.kafka.producer.keyserializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.valueserializer=org.apache.kafka.common.serialization.StringSerializer
(2)创建 controller 从浏览器接收数据, 并写入指定的 topic
2)创建 controller 从浏览器接收数据, 并写入指定的 topic
package com.atguigu.springboot;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ProducerController {
// Kafka 模板用来向 kafka 发送数据
@Autowired
KafkaTemplate<String, String> kafka;
@RequestMapping("/atguigu")
public String data(String msg) {
kafka.send("first", msg);
return "ok";
}
}
(3)在浏览器中给/atguigu 接口发送数据
http://localhost:8080/atguigu?msg=hello
(4)打开消费者查看发送的数据
[atguigu@hadoop103 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181/kafka --from-beginning --topic first
(这里我们配置文件中创建了kafka的文件夹,并且我们的kafka版本低于2.2,如果高于2.2,应该使用bootstrap-server,并且端口号使用9092,(配置信息在上一篇博客,要注意自己的kafka版本))
查看到springboot传递过来的hello表示成功。
2.2 Spring Boot 作为消费者
(1)修改 SpringBoot 核心配置文件 application.propeties
= =消费者配置=
# 指定 kafka 的地址
spring.kafka.bootstrapservers=hadoop102:9092,hadoop103:9092,hadoop104:9092
# 指定 key 和 value 的反序列化器
spring.kafka.consumer.keydeserializer=org.apache.kafka.common.serialization.StringDeserial
izer
spring.kafka.consumer.valuedeserializer=org.apache.kafka.common.serialization.StringDeserial
izer
#指定消费者组的 group_id
spring.kafka.consumer.group-id=atguigu
# =========消费者配置结束=========
(2)创建类消费 Kafka 中指定 topic 的数据
package com.atguigu.springboot;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.KafkaListener;
@Configuration
public class KafkaConsumer {
// 指定要监听的 topic
@KafkaListener(topics = "first")
public void consumeTopic(String msg) { // 参数: 收到的 value
System.out.println("收到的信息: " + msg);
}
}
(3)向 first 主题发送数据
[atguigu@hadoop102 ]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
kafka版本高于2.2使用:
[atguigu@hadoop102 ]$ bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first
客户端显示表示成功!

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)