
李飞飞最新成果:AI不再只会说话,大世界模型(LWMs)叙事开启!
她认为,正如五亿多年前生物视觉的进化,以前所未有的方式点燃了生命形态与智能的爆炸性增长,赋予机器空间智能,也将为AI带来一次类似的范式飞跃。在她看来,任何缺少空间智能的通用人工智能(AGI)都是不完整的。同时,这也与李飞飞长期关注的医疗健康“环境智能”理念不谋而合——具备空间感知力的AI系统,可以在不侵犯隐私的前提下,默默守护病患安全,辅助医护工作。从google的最新进展,到这次李飞飞的成果展示
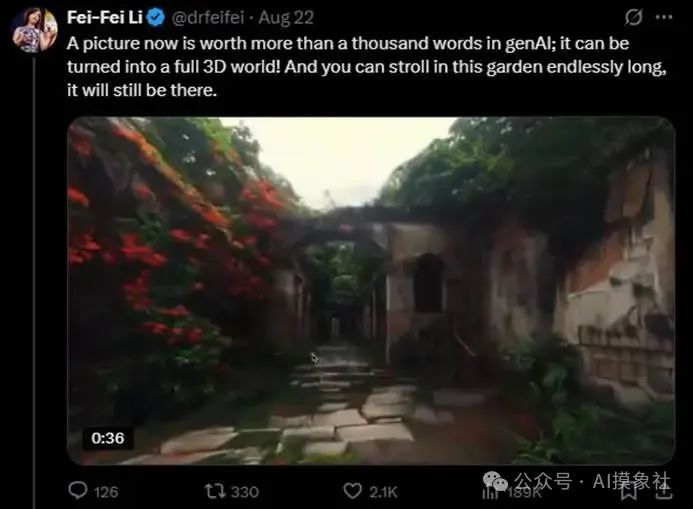
李飞飞在社交媒体上发布了世界模型最新的成果展示,由一张图片生成的可交互的3D世界。没看过的推荐看一看,体会一下空间模型的初版demo~
从google的最新进展,到这次李飞飞的成果展示,提醒我们应该把目光放的再广阔一些,大语言模型的智力提升碰壁了,但是整个AI领域的创新仍然在飞速发展。
AI的进化分野——从“看见”到“行动”
要理解空间智能的颠覆性,必须回溯李飞飞的学术轨迹。她的传奇始于ImageNet,一个规模空前的图像标注数据库。ImageNet并非仅仅是一个数据集,它更像是一把钥匙,为深度学习开启了视觉感知的大门,证明了机器能够“看见”世界。这被公认为点燃现代AI革命的三大引擎之一。
然而,对于李飞飞而言,“看见”仅仅是序章。她毕生的求索,是从被动的感知(Perception)进化到主动的交互(Interaction)。她曾言,梦想并非让机器识别物体,而是让它们能够“讲述世界的故事”。这要求AI不仅能分辨像素的组合,更能理解场景的逻辑、物理的规律以及物体间动态的因果关系。这种从二维静态图像到三维动态交互的跃升,正是当前主流AI范式的局限所在,也为空间智能的登场铺设了理论基石。

李飞飞为空间智能的重要性,提供了一个极具震撼力的类比——“寒武纪大爆发”。她认为,正如五亿多年前生物视觉的进化,以前所未有的方式点燃了生命形态与智能的爆炸性增长,赋予机器空间智能,也将为AI带来一次类似的范式飞跃。这将使AI首次走出屏幕,真正融入并作用于我们身处的物理现实。在她看来,任何缺少空间智能的通用人工智能(AGI)都是不完整的。
在LLM竞赛已然白热化的今天,将空间智能定位为下一个前沿,是一次极具战略眼光的议程设置。这与当年她以ImageNet定义大数据驱动时代的手法如出一辙。通过开辟一个更复杂、更根本的新战场,她为自己和World Labs创造了独特的竞争生态位,吸引着全球顶尖的人才与资本。

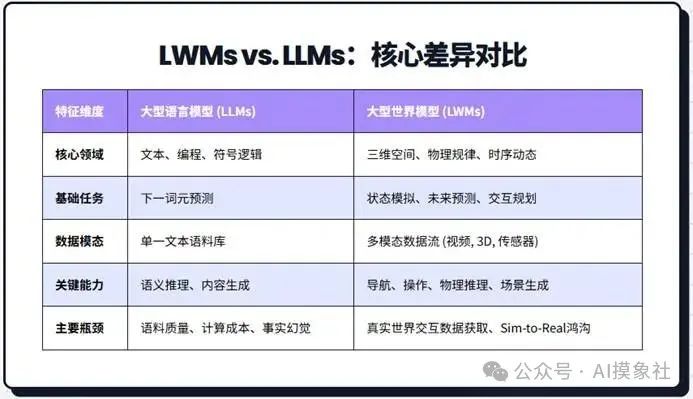
大世界模型(LWMs)vs 大语言模型 (LLMs)
空间智能的实现载体——大型世界模型(LWMs),因此代表了与LLM截然不同的技术哲学。LLM的核心是基于海量文本的统计规律学习,其本质是序列预测。而LWMs的目标,则是通过融合视频、三维扫描、传感器等多模态数据,构建一个关于物理与空间规律的“直觉模型”。众多技术专家指出,试图将复杂的现实世界空间动态,硬塞进基于序列建模的LLM中,存在着根本性的“阻抗失配”。李飞飞本人也断言,“AI不仅仅是LLM”。这是一场从语言符号到物理现实的范式转移。
构建三维世界观的技术基石
空间智能的宏大叙事,需要坚实的技术支点。构建LWMs是一项系统工程,其技术栈至少包含三大核心。
首先是三维重建与生成。这要求模型具备从二维图像中恢复三维场景与物体几何形态的能力。在此基础上,生成式AI的角色被重新定义:不再是创造静态图像,而是生成可供探索、可供交互的无限三维空间。这与World Labs“感知、生成并与三维世界互动”的使命完全契合。
其次是物理引擎的深度集成。这是LWMs与纯视觉模型的根本区别。模型不仅要“看见”世界的样子,更要内化其背后的运行法则,如重力、碰撞、摩擦与因果。它需要理解一个球会下落,一杯水会倾覆。
然而,最艰巨的挑战在于数据获取。正如一位技术评论家所言,空间智能“真正可用的数据集只有一个:世界本身,而它无法被压缩或高速输入计算机”。为破解此局,业界主要采取两大策略:一是通过机器人等AI Agent在物理世界中进行真实互动,以第一视角收集数据,形成“看见与行动”的闭环;二是在高度逼真的模拟环境中,让AI Agent以远超现实的速度进行海量试错与学习。前者受制于物理时间的流速,后者则面临“模拟到现实”(Sim-to-Real)的迁移鸿沟。
为了引领这一新兴领域的发展,李飞飞的团队发布了名为WorldScore的基准测试框架。这一举动,彰显了其愿景背后的学术严谨性与战略远见。WorldScore旨在为3D、4D乃至视频等各类世界生成模型,建立首个统一的评估标准。它通过一个包含3000个测试用例的数据集,从可控性(是否遵循指令)、质量(视觉保真度与一致性)和动态性(物理运动的真实感)三个维度进行评估。

World Labs——空间智能的商业引擎
如果说空间智能是宏伟的蓝图,那么World Labs就是将这张蓝图变为现实的商业引擎。这家2024年成立的公司,在短短四个月内便筹集2.3亿美元,估值超过10亿美元,晋身独角兽行列。
其创始团队堪称豪华,汇集了李飞飞的愿景领导力,以及在计算机视觉与图形学领域声名显赫的技术巨擘。如此惊人的估值,核心逻辑并非AI投资热潮下的盲目跟风,而是一场押注于李飞飞本人的豪赌——赌她能像定义深度学习时代一样,再次定义并引领AI的下一个纪元。
World Labs的商业模式定位清晰:它不做具体的终端应用,而是致力于成为一个“深度科技平台”,为机器人、自动驾驶、元宇宙、创意产业等各行各业,提供空间智能所需的基础模型与开发工具。它的目标不是制造一辆畅销的汽车,而是成为所有下一代智能设备与数字世界所依赖的引擎与底盘。其巨大的估值,只有在投资者相信“空间智能将成为如同今日云计算或移动操作系统般的基础设施”这一判断成立时,才显得合乎逻辑。

LWMs的应用——当AI进入物理现实
LWMs的变革性潜力,将辐射至从实体经济到数字内容的广阔领域。
在具身AI领域,它将赋予机器人和自动驾驶汽车真正的空间理解力,使其能够在复杂、非结构化的环境中更安全、高效地导航与操作。
在创意产业,艺术家和设计师将能通过自然语言指令,快速生成和编辑用于电影、游戏、虚拟现实(VR)和增强现实(AR)的超精细三维世界,极大地降低创作门槛,催生全新的沉浸式交互体验。
在工业与科学领域,LWMs可用于创建城市或工厂的数字孪生,为规划设计和灾难模拟提供前所未有的保真度。同时,这也与李飞飞长期关注的医疗健康“环境智能”理念不谋而合——具备空间感知力的AI系统,可以在不侵犯隐私的前提下,默默守护病患安全,辅助医护工作。
这些应用场景揭示了一个深层趋势:LWMs标志着AI的经济影响力,正从以编程、写作为代表的数字知识经济,向制造业、物流、建筑、医疗等实体经济大规模渗透。这无疑将对生产力与就业结构产生更为深远的影响,也使得李飞飞所倡导的,以审慎和人为本的原则来设计和部署AI,变得比以往任何时候都更加紧迫。

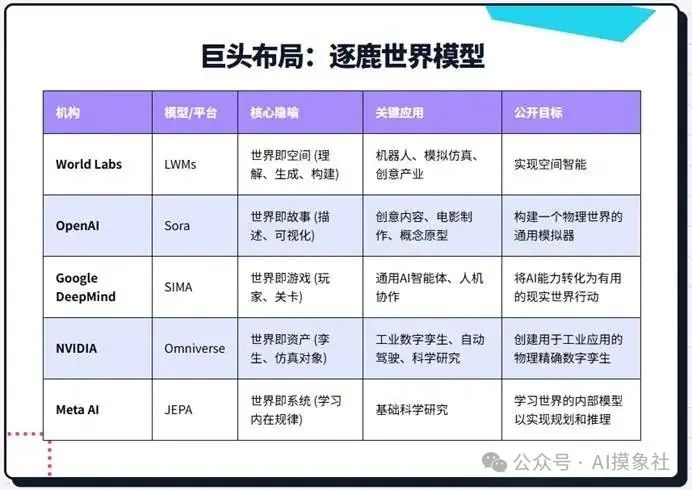
还有谁?
通过这张表格,我们可以清晰地看到各方战略的本质区别。OpenAI的Sora专注于从文本生成视频,它模拟的是物理世界的视觉表象,但不一定构建一个可交互的、符合物理规律的三维模型。它的核心隐喻是“叙事”,旨在用视觉语言讲故事。Google DeepMind的SIMA则强调智能体的主动性,它学习在已有的游戏世界中根据指令完成任务。它的核心隐喻是“游戏”,目标是培养能够在环境中行动的智能体。NVIDIA的Omniverse则服务于工业界,致力于创建现实世界系统的高保真数字复制品,用于测试和优化。其核心隐喻是“数字孪生”,追求的是工程上的精确性。
相比之下,World Labs的路径更为根本。它不满足于模拟表象、在现有世界中行动或复制特定系统,而是致力于从零开始生成三维世界本身,并赋予其可交互性。其核心隐喻是“创造空间”或“沙盒”,目标是掌握生成和控制物理现实的基本能力。Yann LeCun在Meta的JEPA架构则更为抽象,它试图通过预测信息在抽象空间的表征来学习世界的基本规律,这是一种更偏向基础科学研究的路径,旨在理解学习本身。
摸象结语
更大的愿景,开始向我们走来~

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)