
[Methods 2024]Automatic ICD-10-CM coding via Lambda-Scaled attention based deep learning model
计算机-人工智能-lambda注意力和bi-LSTM结合的诊断记录ICD编码多分类

论文网址:Automatic ICD-10-CM coding via Lambda-Scaled attention based deep learning model - ScienceDirect
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3.2. Creating clinical Pool of liver transplant (CPLT) database
2.3.4. Web application deployment
1. 心得
(1)设计的比较简单
2. 论文逐段精读
2.1. Abstract
①Task: automatic International Classification of Diseases (ICD) (ICD-10-CM) coding
2.2. Introduction
①Version of ICD: ICD-9, ICD-10, ICD-11 etc.
②Challenge: lack of kownledge system will caused suboptimal diagnosis result
③Introduced relevant works
2.3. Methodology
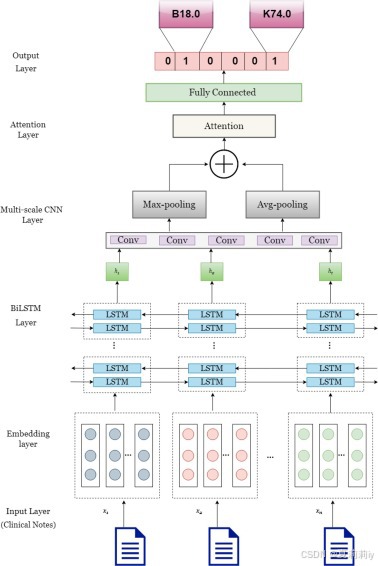
2.3.1. Overview of workflow
①Pipeline:
2.3.2. Creating clinical Pool of liver transplant (CPLT) database
①The authors annotated MIMLT with 1380 ICD-9-CM samples then named it as “Clinical Pool of Liver Transplant” (CPLT)
②They transfer ICD-9-CM to ICD-10-CM by https://www.aapc.com/icd-10/codes/(啊,这可靠吗)
③They directly accepted one-to-one transfer but found experts to precisely classify the cases of one-to-many
2.3.3. Model architecture
(1)Embedding layer
①Employ Word2Vec to mapping original code/words in one clinical text
to
vectors
with dimension of
(2)Deep bi-directional LSTM layer
①The processes of bi-LSTM:
where (
是根据时间步自适应的?)
(3)Multi-scale CNN layer
①This MS-CNN is constructed by a max pooling layer and mean pooling layer after CNN
②Concatenate all output from MS-CNN they get :
(4)Lambda-Scaled attention layer
①They further scale features:
(5)Classification
①Classification by fully connected layers with Sigmoid
②Optimizer: Adam
③Binary cross entropy loss:
2.3.4. Web application deployment
①They build a web to predict ICD code
2.4. Experiments
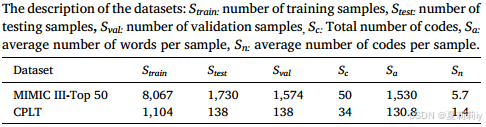
2.4.1. Datasets
①Pretraining on MIMIC III and test on MIMIC III-Top 50 and CPLT
②Statistics:
(1)MIMIC III
①Sample: 53423
②Pre-training: stopword removal, tokenization, lowercase conversion, and removal of numbers, punctuation, and symbols by the Natural Language Toolkit (NLTK) library
③Limited record length: 2500
(2)CPLT
①Samples: 1380
②Preview:

③Data split: 1104 for training, 138 for testing and 138 for val
④Max record length: 150
2.4.2. Evaluation metrics
①Micro F1 and Macro F1 for imbalanced data
2.4.3. Parameter setting
①Hidden dim of bi-LSTM: 64 for CPLT and 128 for MIMC III-Top 50
②Batch size: 8
③Epoch: 50
④Dropout rate: 0.5
2.5. Experimental results
2.5.1. Baseline models
~
2.5.2. Results
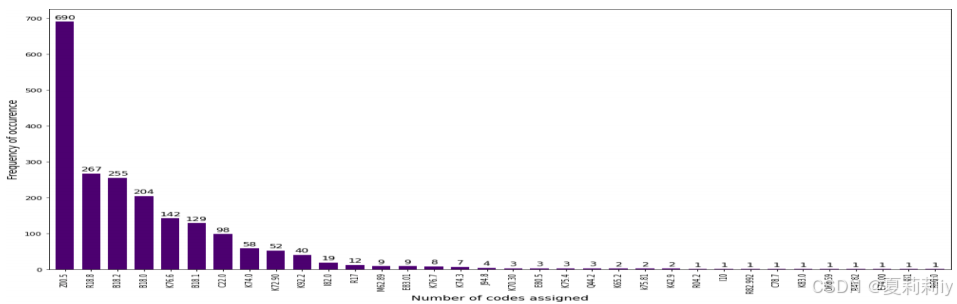
(1)Complete distribution of ICD-10-CM codes in the CPLT database
①34 ICD code in CPLT dataset:
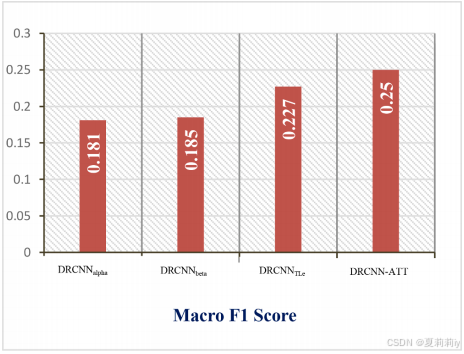
(2)Comparison of DRCNN-ATT model with baselines on CPLT database
①Performance comparison table on CPLT:
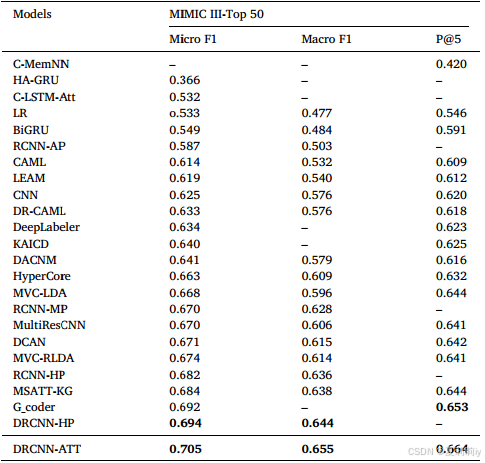
(3)Comparison of DRCNN-ATT model with baselines on MIMIC III-Top 50 database
①Performance on MIMIC III-Top 50:
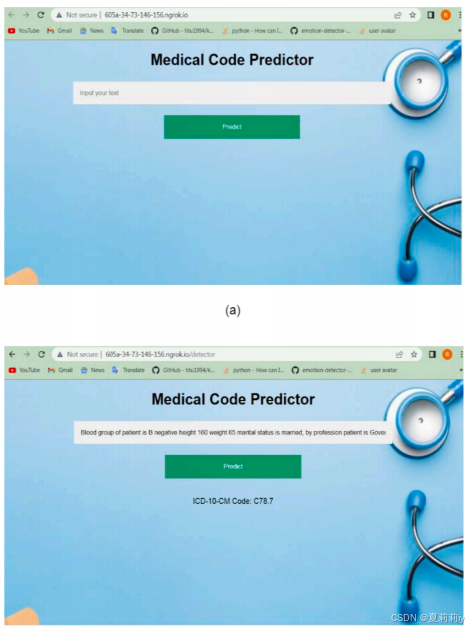
(4)Medical code Predictor web application
①Application preview:
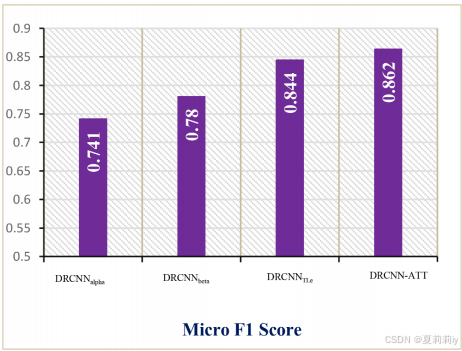
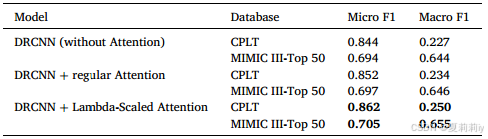
(5)Ablation study
①Attention module ablation:
2.6. Discussion
~
2.7. Conclusion
~

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)