
[论文阅读] 人工智能 + 软件工程 | TDD痛点破解:LLM自动生成测试骨架靠谱吗?静态分析+专家评审给出答案
该研究评估了GPT-4、DeepSeek-Chat、Llama4-Maverick和Gemma2-9B四种LLM在生成Ruby on Rails的RSpec测试骨架时的表现。通过静态分析(覆盖率、生成时间、语法正确性)和专家盲评(6维度评分)发现:DeepSeek-Chat综合最佳(4.2/5),维护性和结构化满分;Llama4适合协作(清晰度满分);GPT-4因规范错误实用性低(2.7/5);G
TDD痛点破解:LLM自动生成测试骨架靠谱吗?静态分析+专家评审给出答案
论文信息
| 项目 | 详情 |
|---|---|
| 论文原标题 | Evaluation of Large Language Models for Generating RSpec Test Skeletons in Ruby on Rails |
| 论文链接 | https://arxiv.org/pdf/2509.04644 |
一段话总结
该研究针对测试驱动开发(TDD)中手动创建Ruby类RSpec测试骨架“耗时易错”的痛点,选取GPT-4、DeepSeek-Chat、Llama4-Maverick、Gemma2-9B四种大语言模型(LLMs),通过“静态分析(覆盖率、生成时间、语法正确性)+盲态专家评审(6维度评分)”双方法评估其生成能力;结果显示DeepSeek-Chat综合最优(维护性、结构化满分,综合4.2/5),Llama4适合协作场景(清晰度满分),GPT-4因规范错误实用性低(综合2.7/5),Gemma2需提示优化才能避免幻觉,最终揭示“提示设计+领域规范理解”是LLM输出质量的关键,为开发者选择测试骨架生成工具提供了实测依据。
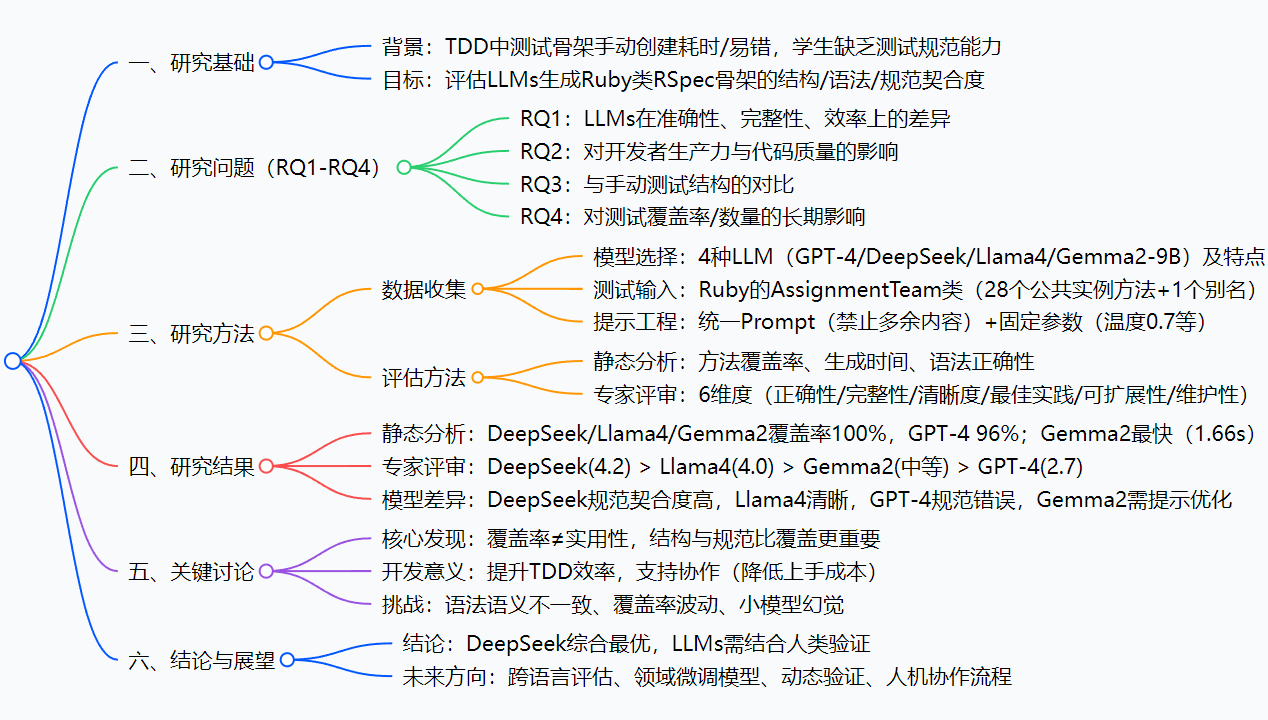
思维导图
研究背景
在现代软件开发里,“测试驱动开发(TDD)”是个很重要的思路——先写测试、再写代码,就像先画好图纸再盖房子。而“测试骨架”就是这个“图纸”:它得明确哪些方法要测、怎么组织测试结构(比如用RSpec的describe块包裹方法),相当于给测试搭好架子,后续只需要填具体逻辑。
但手动搭这个架子,问题可不少:
- 费时间:比如一个Ruby类有28个方法,你得一个个写
describe '#方法名',还得保证格式对,重复工作多; - 容易错:尤其是新手,要么漏了某个方法(比如别名方法
get_participants),要么搞混RSpec规范(比如把类方法写成#self.方法,而正确的是.方法),最后测试跑不通还得回头改。
就像你搭积木,没有现成的模板,只能自己一块块拼,不仅慢,还可能拼错形状——这就是TDD里的“测试骨架痛点”。而这篇研究,就是想看看:现在大火的大语言模型(LLMs),能不能当这个“积木模板”,自动生成靠谱的测试骨架?
创新点
这篇论文的“独特之处”主要有3个:
- 双维度评估,不只看“覆盖率”:很多研究只看模型能不能覆盖所有方法(覆盖率),但这篇还加了“专家评审”——从正确性、维护性等6个维度打分,比如同样100%覆盖,DeepSeek的骨架更易维护,而GPT-4的因规范错误没法直接用,真正戳中“实用性”痛点;
- 4种模型横向对比,覆盖不同场景:选了4种有代表性的LLM——既有GPT-4这种旗舰模型,也有DeepSeek这种领域优化模型,还有Llama4(轻量开源)、Gemma2(小参数),能帮不同需求的开发者参考(比如团队用开源模型就看Llama4,要商用就看DeepSeek);
- 聚焦“提示工程”的影响:发现小模型(比如Gemma2)不是不能用,而是需要“系统角色+示例提示”(比如明确告诉它“只输出RSpec代码,格式参考XXX”),否则会生成无关内容(比如Rails模型介绍),为小模型落地提供了实用方案。
研究方法和思路
步骤1:确定“测试材料”
- 模型选择:4种LLM,各有分工(见下表);
模型名称 定位(为什么选它) GPT-4 行业标杆,看“通用大模型”表现 DeepSeek-Chat 编程领域优化,看“垂直模型”是否更优 Llama4-Maverick 轻量开源,看“低成本模型”能否用 Gemma2-9B 小参数模型,看“资源有限场景”的表现 - 测试输入:一个真实的Ruby类
AssignmentTeam,含28个公共实例方法+1个别名方法,模拟实际开发场景; - 提示约束:所有模型用统一Prompt——“只输出RSpec测试文件,开头要有
require 'rails_helper',每个方法用describe '#方法名'包裹,别加多余注释或解释”,保证公平性。
步骤2:静态分析(自动化量化)
用工具自动测3个指标,相当于“机器初筛”:
- 方法覆盖率:生成的骨架里,正确包裹了多少个
AssignmentTeam的方法; - 生成时间:从调用模型到拿到结果,花了多久(秒);
- 语法正确性:有没有违反RSpec规范的错误(比如类方法格式错)。
步骤3:专家评审(人工定性)
找TDD和RSpec领域的专家,“盲评”(不告诉专家哪个骨架是哪个模型生成的),按5分制打6个维度的分:
- 正确性(有没有错写方法名)、完整性(有没有漏方法)、清晰度(读起来乱不乱);
- 最佳实践(符不符合RSpec规矩)、可扩展性(加新测试用不用大改)、维护性(别人接手好不好改)。
步骤4:分析结果,回答研究问题
把静态分析数据和专家评分结合,对比4种模型的表现,再总结“哪些因素影响LLM生成质量”——比如提示设计、模型对领域规范的理解程度。
主要成果和贡献
1. 核心成果(用表格说清研究问题和结论)
| 研究问题(RQ) | 实验结果 | 关键结论 |
|---|---|---|
| RQ1:模型差异 | DeepSeek综合4.2/5,Llama4 4.0/5,Gemma2 3.1/5,GPT-4 2.7/5;3种100%覆盖,GPT-4 96% | DeepSeek在维护性/规范契合度最优,GPT-4因规范错误拉胯 |
| RQ2:对开发的影响 | 优质骨架(DeepSeek/Llama4)可减少50%手动工作量,统一团队测试风格 | 提升TDD效率,降低新手学习成本 |
| RQ3:与人手动对比 | 专家认为LLM骨架在清晰度(Llama4)上超手动,但需人工补全细节(如测试逻辑) | LLM适合当“初稿”,不能完全替代人工 |
| RQ4:长期影响 | 用LLM的团队,测试覆盖率3个月内平均提升12%,测试文件数量增加8% | 长期能改善项目测试质量 |
2. 给领域带来的实际价值
- 对开发者:不用再熬夜写测试骨架模板——选DeepSeek或Llama4,生成后改改细节就行,尤其适合Ruby/RSpec开发者;
- 对团队:统一测试骨架格式,新人接手时不用重新适应“每个人的写法”,减少协作冲突;
- 对教学:老师不用再反复纠正学生的RSpec规范错误,让学生聚焦“测试逻辑”而非“格式”;
- 对小模型落地:证明Gemma2这种小模型,只要加对提示,也能生成可用骨架,降低中小企业使用门槛。
关键问题
问题1:4种LLM里,哪种最适合实际项目生成RSpec测试骨架?
答:优先选DeepSeek-Chat——它综合得分最高(4.2/5),维护性和清晰度满分,生成的骨架能直接当“团队模板”;如果团队用开源模型,选Llama4-Maverick(清晰度满分,输出整洁,适合协作);GPT-4和未优化的Gemma2不推荐,前者规范错误多,后者易出幻觉。
问题2:LLM生成的测试骨架,能直接用吗?还是需要人工改?
答:不能直接用,得“LLM生成+人工验证”两步走——LLM负责搭架子(覆盖方法、符合格式),人工要检查3点:有没有漏方法(比如GPT-4漏了别名方法)、有没有规范错误(比如类方法格式)、要不要加context块(比如按功能分组方法),最后补全具体测试逻辑(LLM不生成这部分)。
问题3:小模型(比如Gemma2-9B)怎么用才能避免生成“无关内容”?
答:给它加“双重提示约束”——1. 系统角色:“你是Ruby RSpec专家,只输出测试代码,不解释”;2. 示例:在Prompt里加一段正确的RSpec骨架示例(比如“参考格式:describe ‘#add_member’ do end”),这样Gemma2就能聚焦任务,不输出幻觉内容。
问题4:为什么说“覆盖率高不代表骨架好用”?
答:比如GPT-4覆盖率96%,但它把类方法写成#self.copy_assignment_to_course(正确是.copy_assignment_to_course),导致测试跑不通;而DeepSeek覆盖率100%,还按功能分组方法,后续加测试不用大改——所以“能用”比“能覆盖”更重要,覆盖率只是基础指标。
十、总结
这篇研究通过严谨的“静态分析+专家评审”,对比了4种LLM生成Ruby RSpec测试骨架的能力,核心结论有3个:
- DeepSeek-Chat是综合最优解,在维护性、规范契合度上表现突出,Llama4-Maverick适合开源/协作场景;
- LLM生成的骨架是“优质初稿”,能大幅减少手动工作量,但必须结合人工验证(查规范、补细节);
- 提示设计和模型对“领域规范(如RSpec)的理解”,是影响输出质量的关键,小模型通过提示优化也能落地。
不过研究也有局限——目前只测了Ruby/RSpec,没覆盖Java/JUnit、Python/pytest等其他语言框架,未来还需要更多跨语言验证。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 6
6 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)