
终于把卷积神经网络算法搞懂了!!
它通过局部感受野、权值共享和池化操作,有效提取输入数据的空间特征,大大减少了参数数量,提升了模型的表现力和计算效率,广泛应用于图像识别、目标检测、自然语言处理等领域。
今天给大家分享一个强大的算法模型,卷积神经网络算法
卷积神经网络算法是一类专门用于处理具有网格结构数据(如图像)的深度学习模型。
它通过局部感受野、权值共享和池化操作,有效提取输入数据的空间特征,大大减少了参数数量,提升了模型的表现力和计算效率,广泛应用于图像识别、目标检测、自然语言处理等领域。
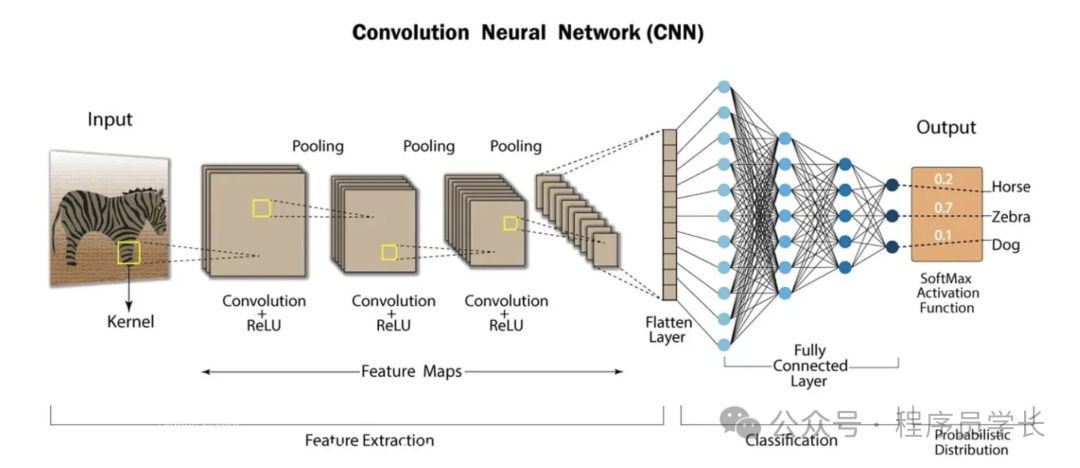
核心组成
卷积神经网络算法主要由卷积层、激活函数层、池化层和全连接层组成。
1.卷积层
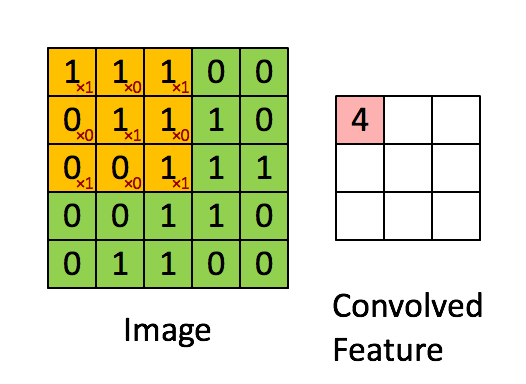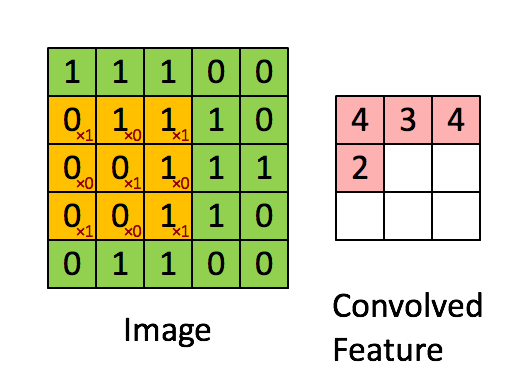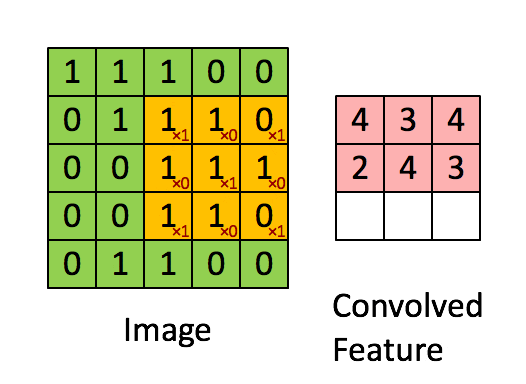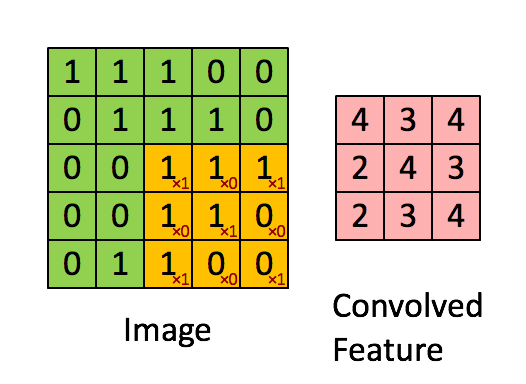
卷积层是卷积神经网络(CNN)中的核心构建模块,负责从输入数据(如图像)中自动提取局部特征。
它通过多个可学习的滤波器(卷积核)对输入进行滑动窗口的卷积操作,捕捉图像中的边缘、纹理、形状等重要信息。
卷积操作是通过一个小的滤波器(卷积核)在输入图像上滑动,计算局部区域和滤波器权重的加权和,提取局部特征。
通过多个卷积层的堆叠,CNN 可以提取越来越复杂的高级特征。
关键概念
-
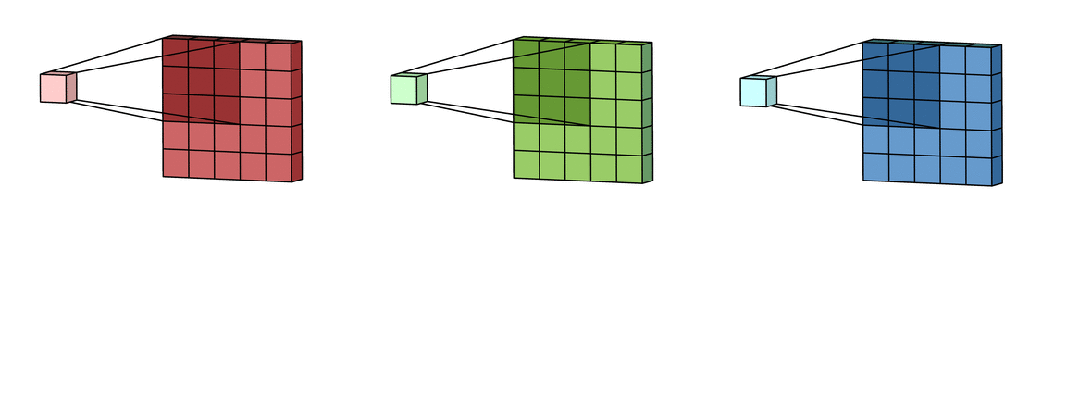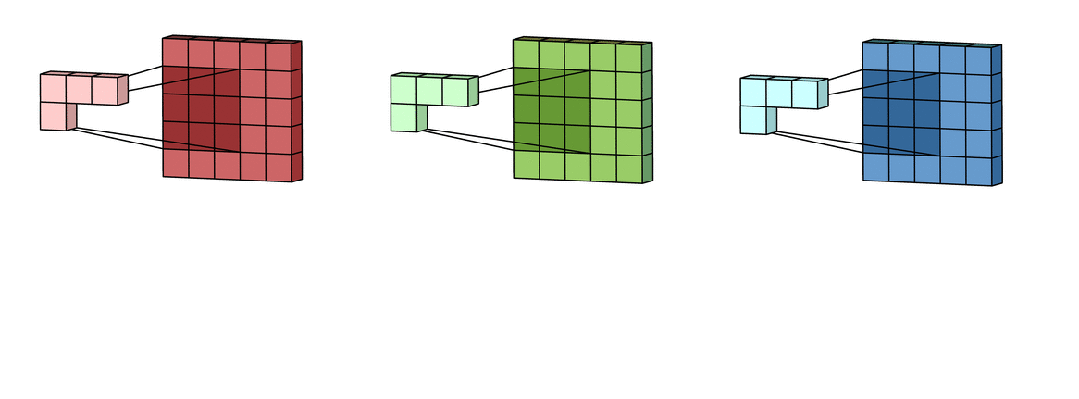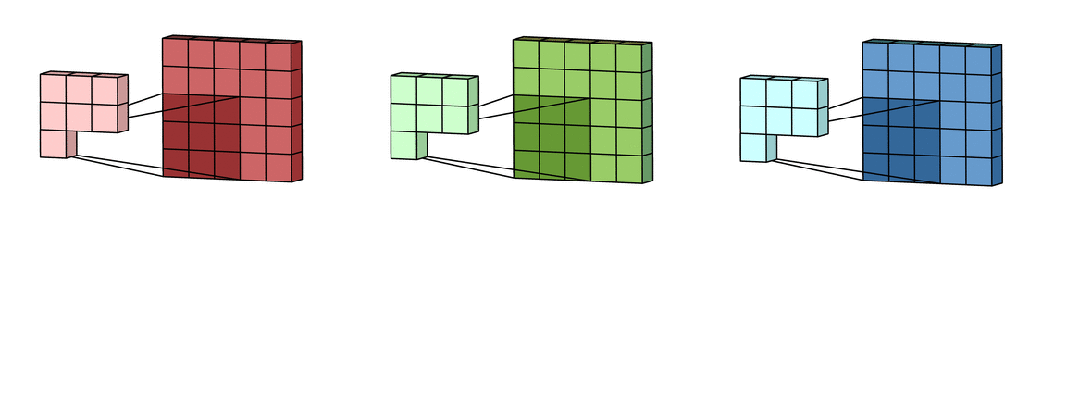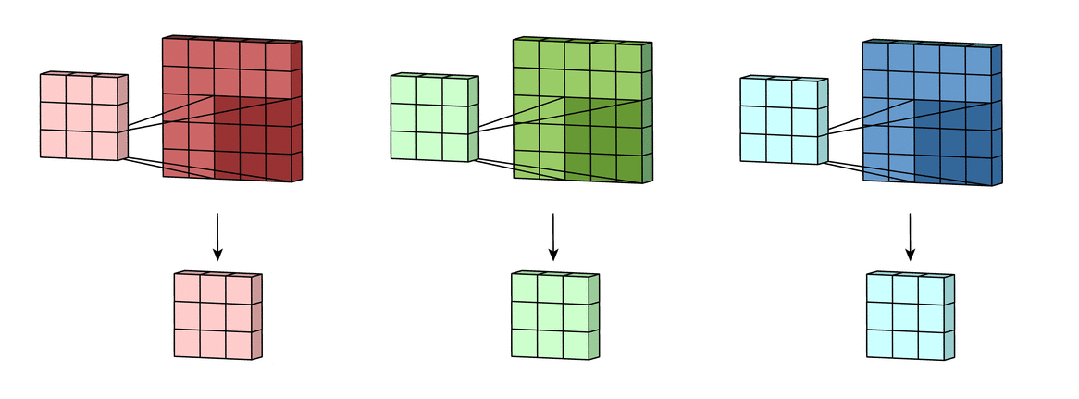
卷积核
卷积核是一个小尺寸的权重矩阵,如 、 等,用来提取输入数据中的局部特征。
-
卷积核数量
每个卷积核负责提取某种特定类型的特征(例如,水平边缘、垂直边缘、纹理等)。
-
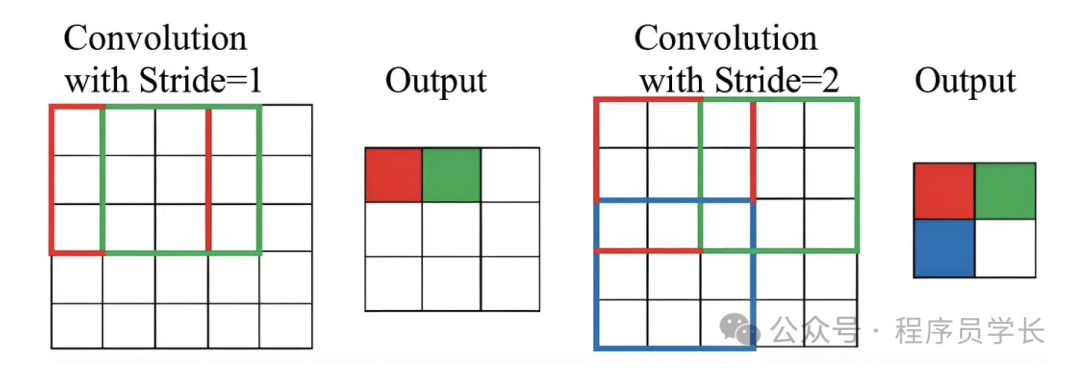
步长
卷积核在输入上滑动的步长。如果步长为1,则每次移动一个像素;如果步长为2,则每次移动两个像素。
-
填充
在输入图像的边缘添加额外的像素(通常为0),以控制输出特征图的大小。常见的有 “valid”(不填充)和“same”(填充后输出尺寸与输入尺寸相同)
2.激活函数层
卷积操作后,通常会通过激活函数引入非线性,从而增强模型表达能力。
常见的激活函数有
-
ReLU
-
Sigmoid
-
Tanh
3.池化层
池化层用于对卷积层输出的特征图进行下采样,减小空间尺寸,减少计算量和参数数量,同时具有一定的平移不变性。
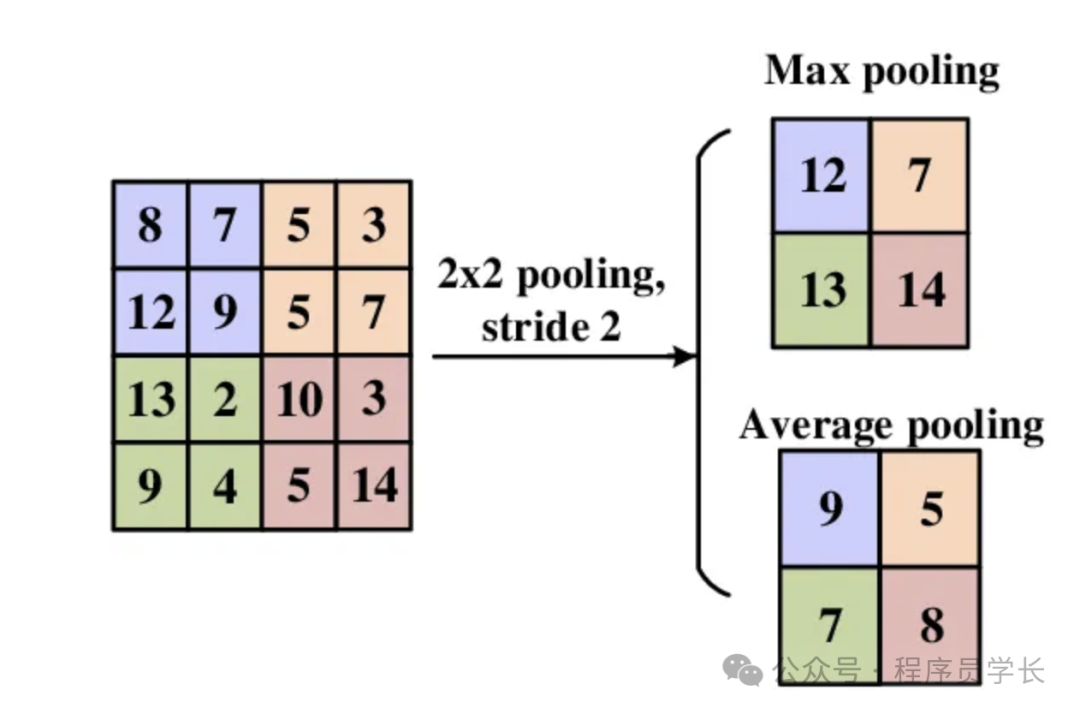
常用池化操作
- 最大池化(Max Pooling):选取池化窗口内的最大值
- 平均池化(Average Pooling):选取池化窗口内的平均值
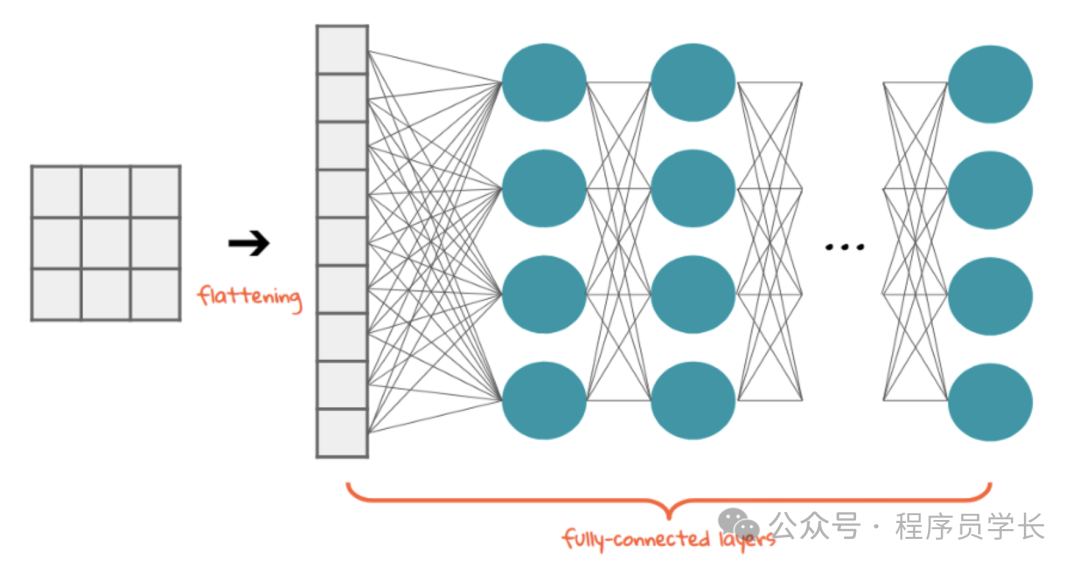
4.全连接层
在经过若干卷积层和池化层提取到特征后,通常会将多维的特征图展平,输入全连接层,用于最终的分类或回归任务。
在全连接层中,网络的每个神经元与上一层的所有神经元都有连接。
CNN 的优势
- 参数共享:卷积核在空间上共享参数,减少网络参数数量。
- 局部感受野:卷积操作专注于局部区域,使网络能捕捉局部特征。
- 平移不变性:卷积操作对输入的平移具有鲁棒性,即特征的空间位置发生变化时,CNN仍能捕获相同的特征,提升模型泛化能力。
- 层级特征提取:多层卷积和池化层级联能够提取从低级(边缘、纹理)到高级(物体部件、语义)逐层抽象的特征表示。
- 自动特征提取:CNN 通过卷积层自动从数据中学习特征,无需人工设计特征工程,尤其适合图像、语音等高维结构化数据。
案例分享
下面是一个使用卷积神经网络算法(CNN)进行手写数字识别的完整示例代码。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 1. 数据准备:MNIST数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
# 2. 定义CNN模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = x.view(x.size(0), -1)
x = self.relu3(self.fc1(x))
x = self.fc2(x)
return x
# 3. 训练设置
device = torch.device('cuda'if torch.cuda.is_available() else'cpu')
model = CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 4. 训练函数
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item():.6f}')
# 5. 测试函数(含显示预测结果)
def test(show_predictions=True, num_samples=5):
model.eval()
test_loss = 0
correct = 0
all_preds = []
all_targets = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item() * data.size(0)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
all_preds.append(pred.cpu())
all_targets.append(target.cpu())
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
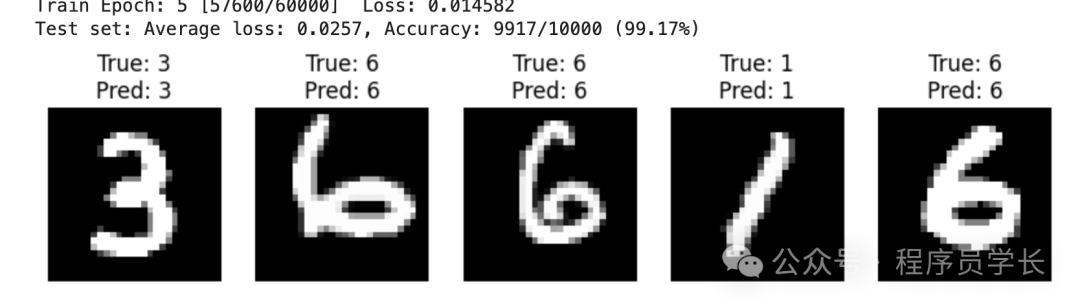
print(f'Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)')
if show_predictions:
all_preds = torch.cat(all_preds).squeeze()
all_targets = torch.cat(all_targets)
indices = np.random.choice(len(all_preds), num_samples, replace=False)
fig, axs = plt.subplots(1, num_samples, figsize=(num_samples*2, 3))
for i, idx in enumerate(indices):
img, label = test_dataset[idx][0], all_targets[idx].item()
pred_label = all_preds[idx].item()
axs[i].imshow(img.squeeze(), cmap='gray')
axs[i].set_title(f'True: {label}\nPred: {pred_label}')
axs[i].axis('off')
plt.show()
# 6. 主训练测试循环
for epoch in range(1, 6):
train(epoch)
test()

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)