
【机器学习快速入门】2 Pipeline构建机器学习工作流
1.Pipeline都是执行各学习器中对应的方法,如果该学习器没有该方法,则报错2. 假设该pipeline有n个学习器,fit依次对前n-1的学习器执行fit和transform方法,并且对最后一个学习器执行fit方法3.predict先对n-1学习器执行transform方法,然后执行最后一个学习器的predict方法4. score先对n-1学习器执行transform方法,然后执行最后一个
·
pipeline实现了对特征处理与机器学习的封装流程化管理,期间处理的参数可以很方便的在测试集和未来数据上反复使用。
Pipeline流程介绍¶
1.Pipeline都是执行各学习器中对应的方法,如果该学习器没有该方法,则报错
2. 假设该pipeline有n个学习器,fit依次对前n-1的学习器执行fit和transform方法,并且对最后一个学习器执行fit方法
3.predict先对n-1学习器执行transform方法,然后执行最后一个学习器的predict方法
4. score先对n-1学习器执行transform方法,然后执行最后一个学习器的score方法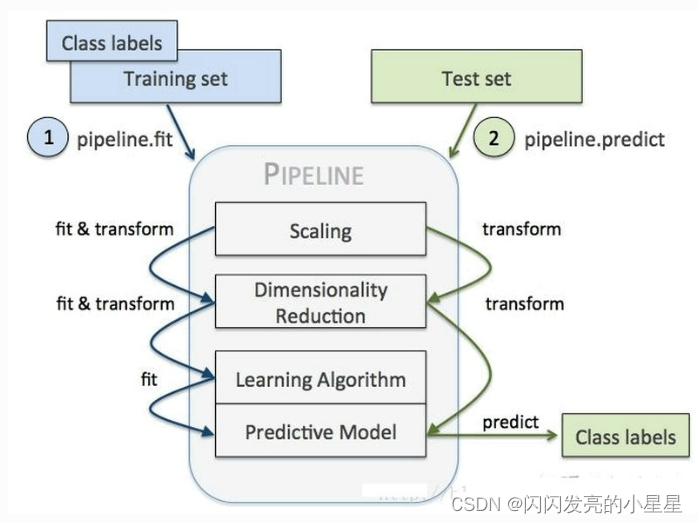
一个简单的demo
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_boston
X,y= load_boston(return_X_y=True)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=1)
# Pipeline构建机器学习工作流
pip_lr = Pipeline(steps=[('std', StandardScaler()), ('lr', LinearRegression())])
# 显示所有学习器参数
# deep=False ==> verbose: False
# print(pip_lr.get_params(deep=False))
# 获取某个学习器对象
# std:StandardScaler = pip_lr.named_steps['std']
# fit依次对前n-1的学习器执行fit和transform方法,并且对最后一个学习器执行fit方法
pip_lr.fit(X_train, y_train)
# print(std.mean_)
# lr:LinearRegression = pip_lr.named_steps['lr']
# print(f'权重为:{lr.coef_},偏置为:{lr.intercept_}')
# 预测和评价
print(f'test accuracy:{pip_lr.score(X_test,y_test)}')
封装Pipeline并构建工作流程
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.datasets import load_boston
# 1: 获取数据
X,y = load_boston(return_X_y=True)
# 2: 预处理(略)
# 3: 拆分训练集与测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=1)
# 4~6: 采用Pipeline封装 特征工程、训练、调优
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
pipe_lr = Pipeline([
('pf', PolynomialFeatures(degree=3,include_bias=False,interaction_only=False)),
('sc', StandardScaler()),
('clf', Ridge(alpha=0.8))])
# fit依次对前n-1的学习器执行fit和transform方法,并且对最后一个学习器执行fit方法
pipe_lr.fit(X_train,y_train)
# score依次对前n-1的学习器执行transform方法,并且对最后一个学习器执行score方法
print(f'Train score: {pipe_lr.score(X_train, y_train)},Test score: {pipe_lr.score(X_test, y_test)},')

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)