
(一)0基础配置YOLOv11环境与模型训练及应用(PyCharm)
本文详细介绍了YOLOv11环境配置与安装步骤。主要内容包括:1)从GitHub获取YOLOv11源码和预训练模型;2)Anaconda的安装与环境配置,使用清华源加速下载;3)创建Python3.11虚拟环境并安装PyTorch。通过命令行操作演示了环境搭建全过程,为后续模型训练与验证奠定基础。文章还提供了常用conda命令集,方便用户管理虚拟环境。整个流程清晰规范,适合初学者快速搭建YOLOv
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
基于我上篇YOLO的配置文章《 基于pycharm的YOLOv11模型训练方法 》,
上篇以 模型训练 为主要内容
本文重点介绍:
1)从GitHub上,直接下载源代码,原模型。更加源头、更加抽丝剥茧地展示给大家搭建YOLOv11基础环境
2)完成模型验证测试
3)为后续模型训练与精度提升奠定基础
下篇文章 将在此文章的基础上,进行模型训练,及精度提升。
一、YOLOv11 安装步骤
-
从GitHub下载 ultralytics/v8.3.163 ,注意要
v8.3.163版本,注意解压路径,不能重复嵌套 ultralytics-8.3.163
通过网盘分享的文件:ultralytics-8.3.163.zip
-
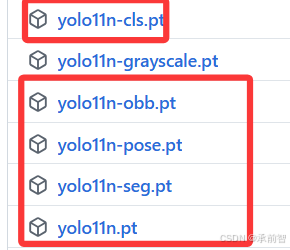
从GitHub下载 v8.3.0 - New YOLO11 Models Release 下载红框五个,并放入 ultralytics-8.3.163 文件夹中
通过网盘分享的文件:YOLOV11模型.zip- yolo11n-cls.pt:图像分类模型
- yolo11n-grayscale.pt:灰度图检测模型
- yolo11n-obb.pt:旋转框检测模型
- yolo11n-pose.pt:姿态估计模型
- yolo11n-seg.pt:图像分割模型
- yolo11n.pt:通用目标检测模型
- 最终效果
二、Anaconda 安装步骤
若是电脑内有下载过,建议卸载。参考Anaconda安装与卸载
- 从清华源下载 Anaconda3-2024.06-1-Windows-x86_64.exe ,注意要
2024.06-1版本
通过网盘分享的文件:Anaconda3-2024.06-1-Windows-x86_64.zip - 打开安装包,注意安装路径,不能重复嵌套/含中文或空格
Anaconda 环境配置
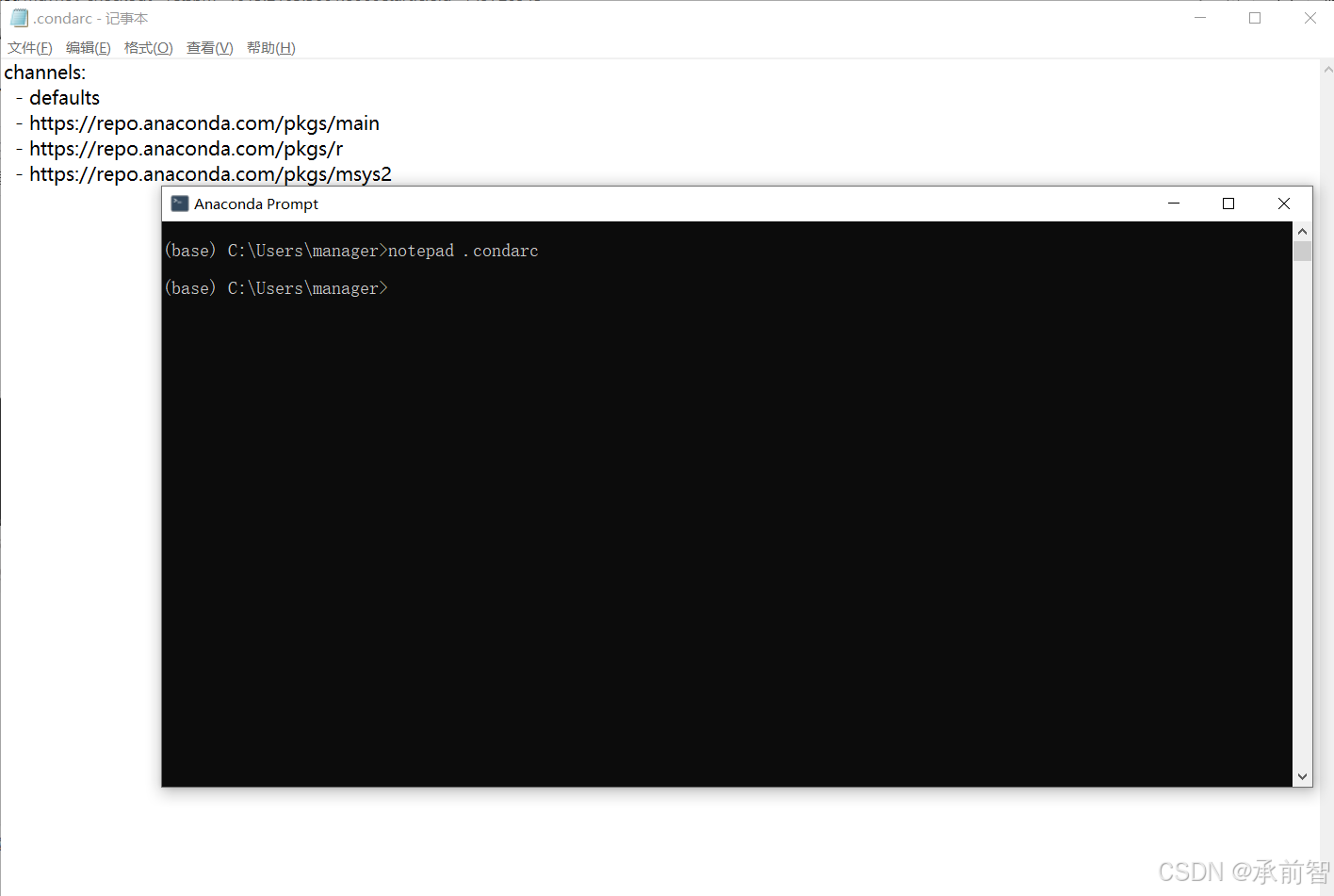
- 打开 Anaconda Prompt

- 输入
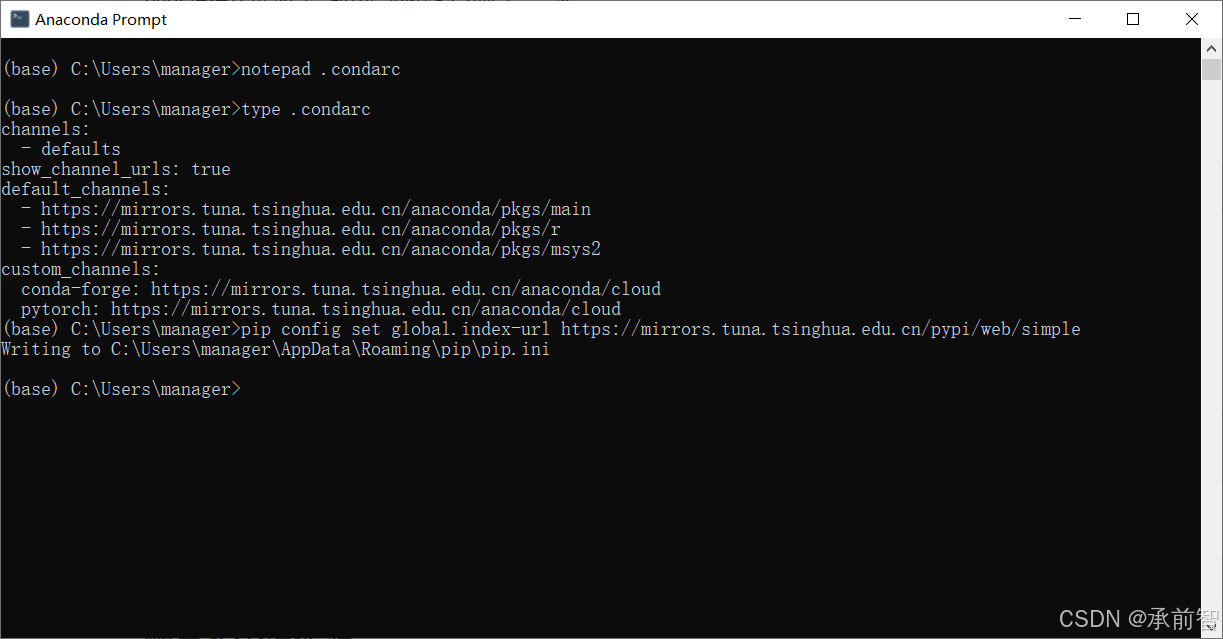
notepad .condarc
notepad xxx的作用是使用记事本打开名为xxx的文件,如果文件不存在就会提醒你是否创建
- 将 清华源 找到
Anaconda 环境配置文件(.condarc)的内容复制到记事本,并保存,关掉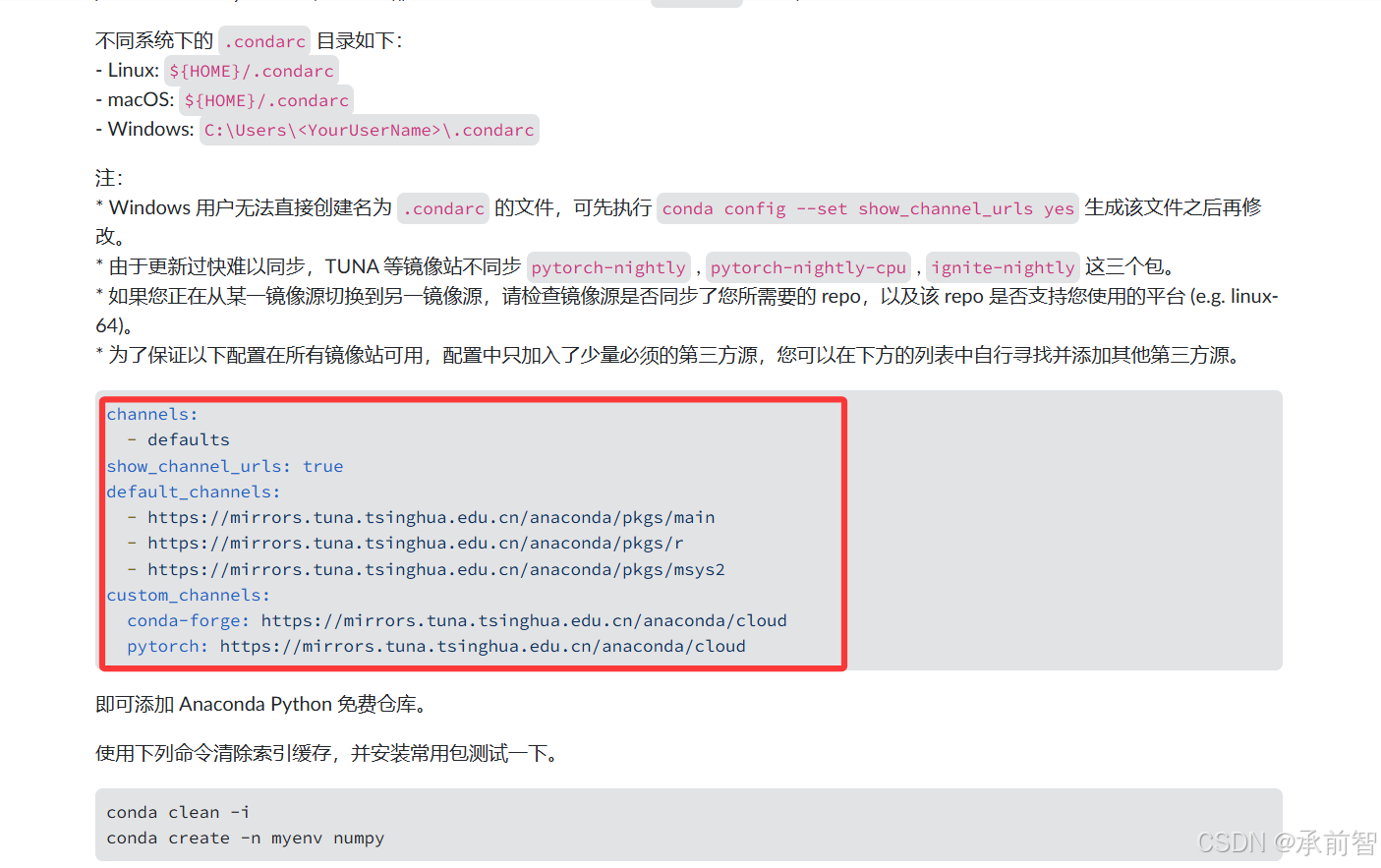
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
- 输入
type .condarc
type xxx的作用是打印出xxx的内容,可以用于在命令行里快速查看文本内容,如果xxx这个文件不存在那么就会报错(若是报错,则前面的记事本可能添加 .txt 后缀。type .condarc.txt,后修改文件名,ren .condarc.txt .condarc重命名为.condarc)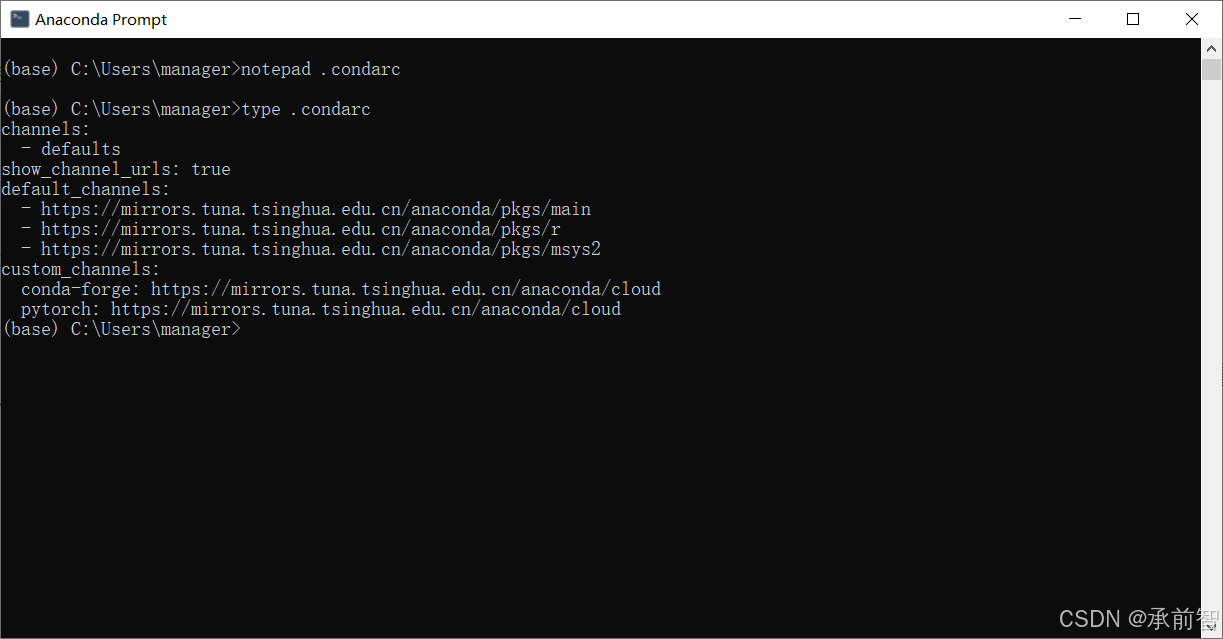
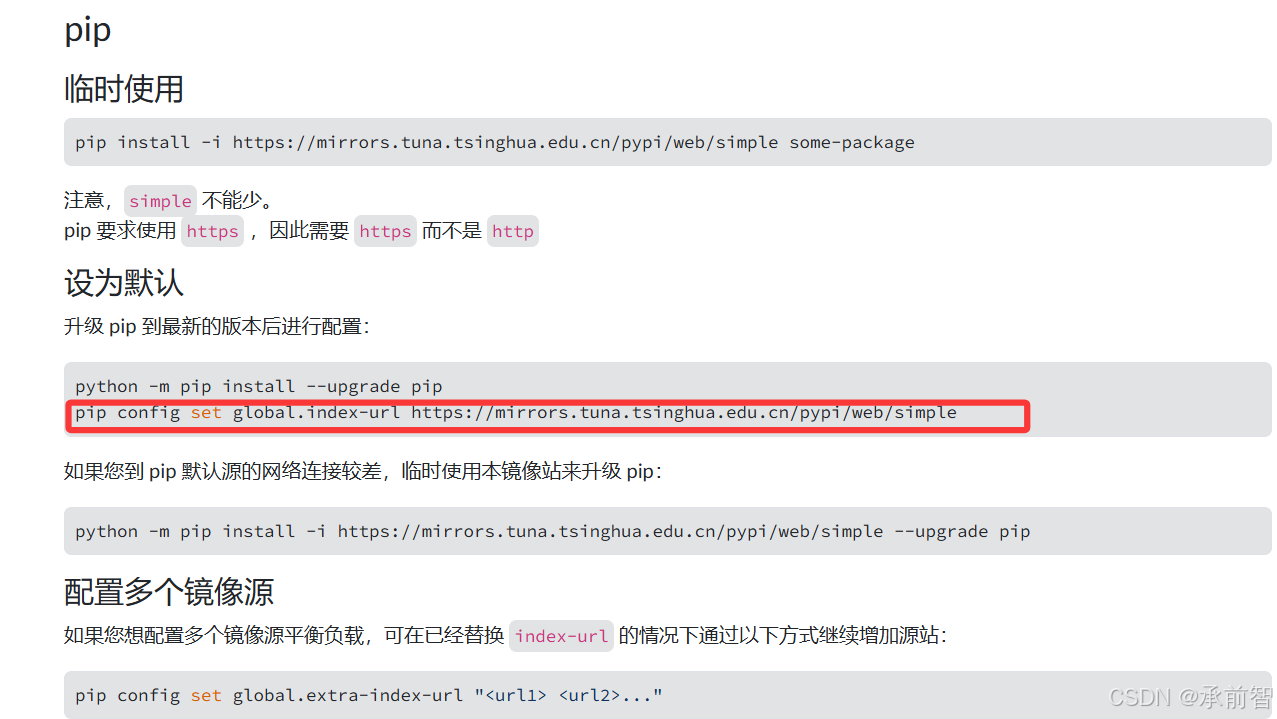
- 将 清华源 找到
设为默认复制到Anaconda Prompt
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
conda 命令集
| 命令 | 作用 |
|---|---|
| conda env list | 列举所有环境及保存路径 |
| conda create -n python=3.xx | 创建一个名为的环境,python版本为3.xx |
| conda remove -n --all | 删除名为的环境 |
| conda activate | 激活(进入)名为的环境 |
| conda deactivate | 退出当前环境 |
| python --version | 查看当前环境的Python版本 |
| pip list | 列举当前环境安装的所有包 |
| pip install ==x.xx | 为当前环境安装名为的包,包的版本为x.xx |
| pip show | 查看当前环境中这个包的信息 |
| pip uninstall | 为当前环境卸载名为的包 |
YOLO 环境配置
-
打开 Anaconda Prompt
-
输入
conda env list,确定目前环境只有base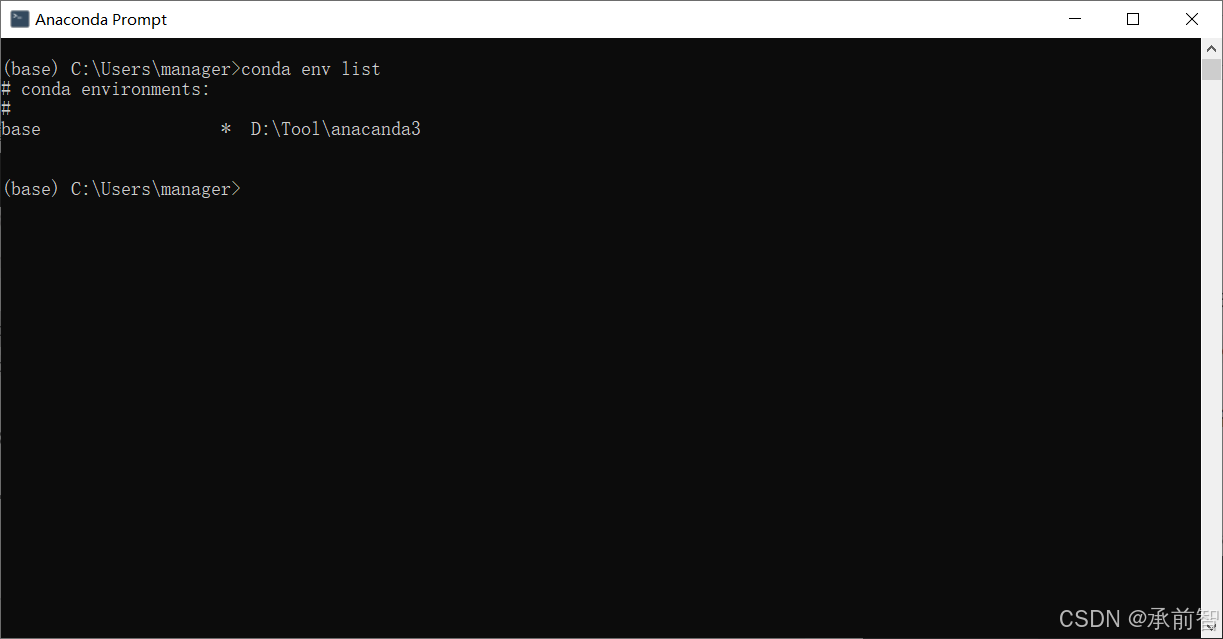
-
输入
conda create -n yolo python=3.11y,安装环境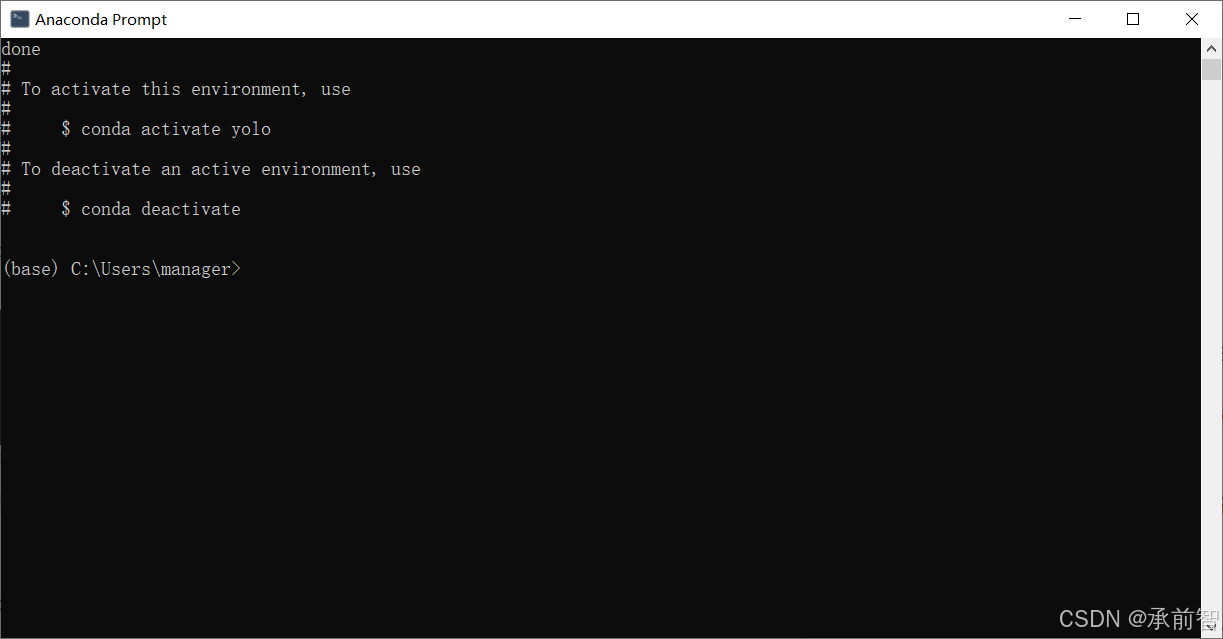
-
输入
conda env list,确定安装成功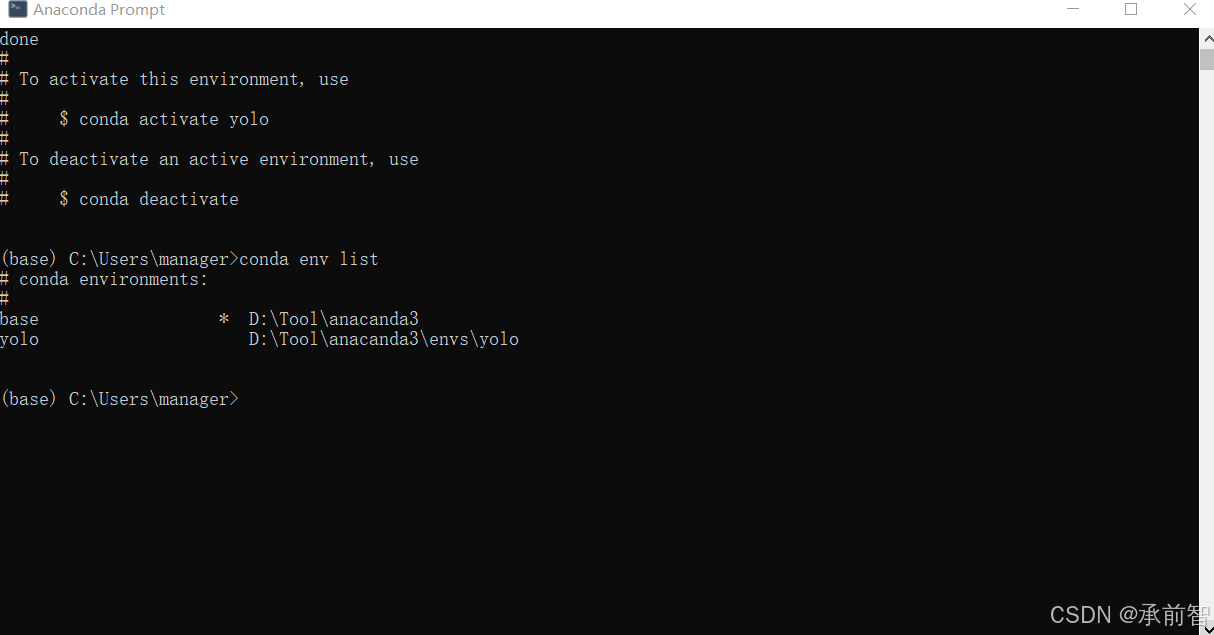
安装PyTorch
-
打开 Anaconda Prompt
-
输入
conda activate yolo,进入yolo环境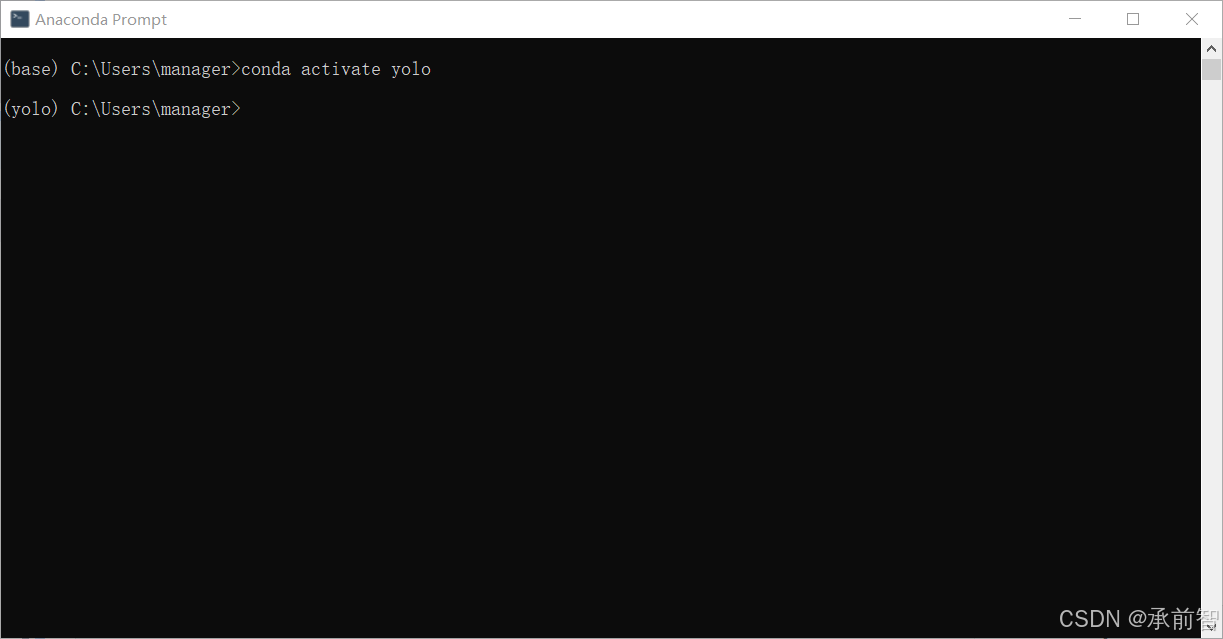
-
输入
nvidia-smi,查看显卡驱动 CUDA Version: 12.3(若<11.8,更新显卡驱动)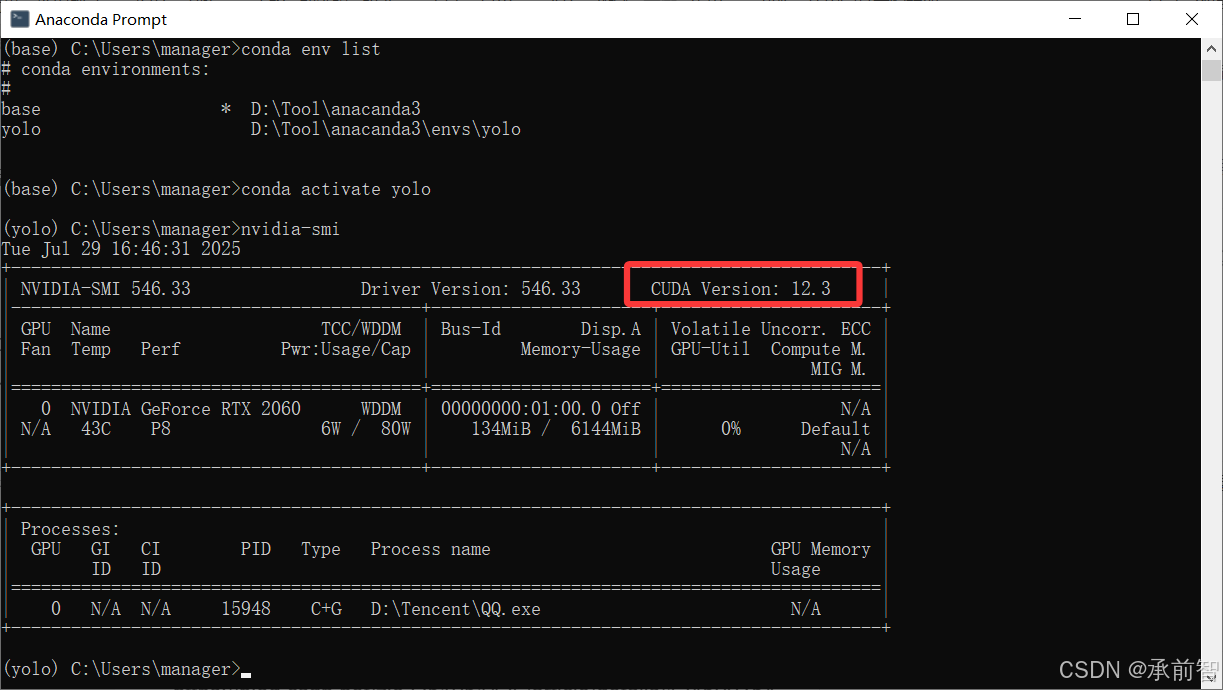
| 硬件条件 | 目标PyTorch版本 |
|---|---|
| 电脑带英伟达显卡50系列(5060,5060Ti,5070,5070Ti…) | 最新+CUDA12.8 |
| 电脑带英伟达显卡非50系列(1050Ti, 2060,3060,4060…) | 2.5.0+CUDA11.8 |
| 电脑不带英伟达显卡(CPU环境) | 2.5.0+CPU |
- 从 PyTorch 找到 2.5.0-11.8
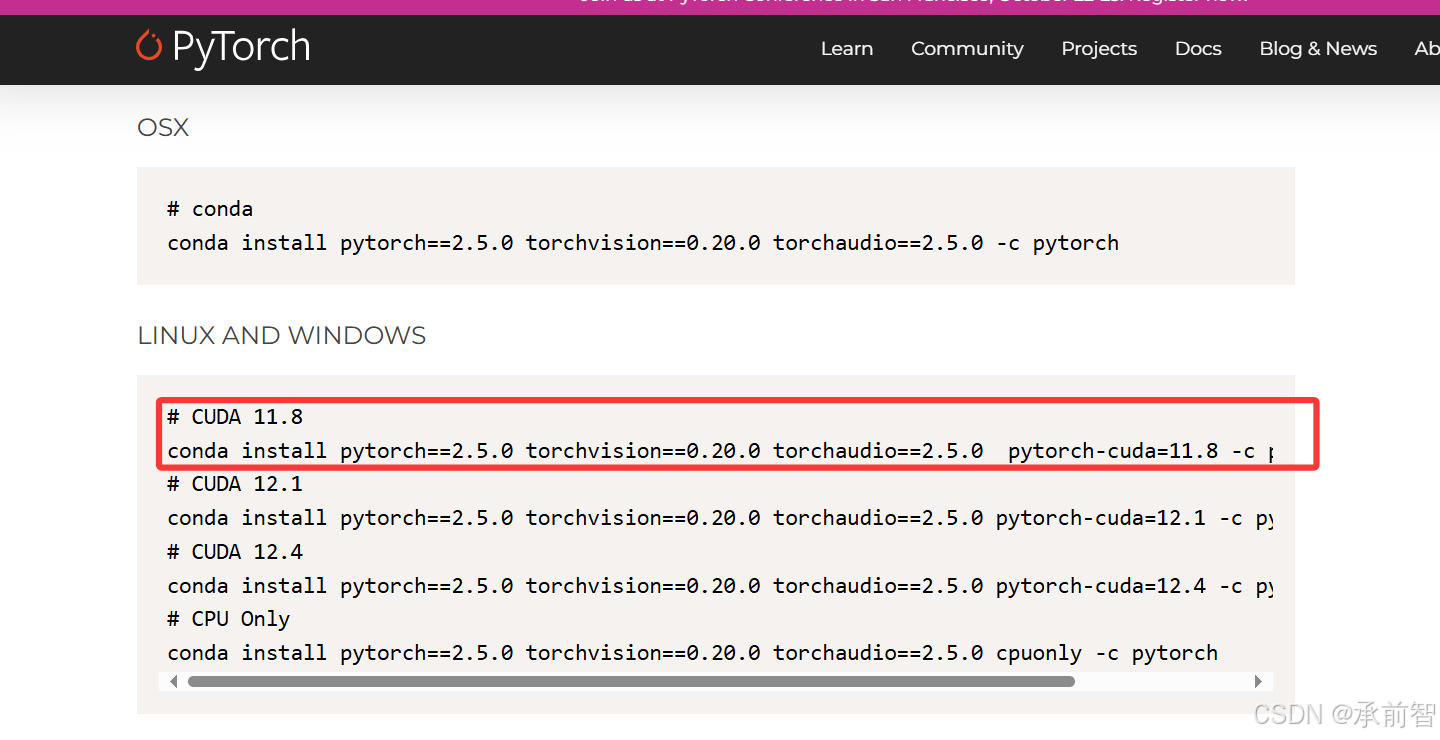
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=11.8 -c pytorch -c nvidia
-
输入
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=11.8 -c pytorch -c nvidia(若速度过慢,换镜像换阿里源)
(该命令就是上面的CUDA 11.8,记住要在yolo环境下)
-
输入
pip show torch(查看torch)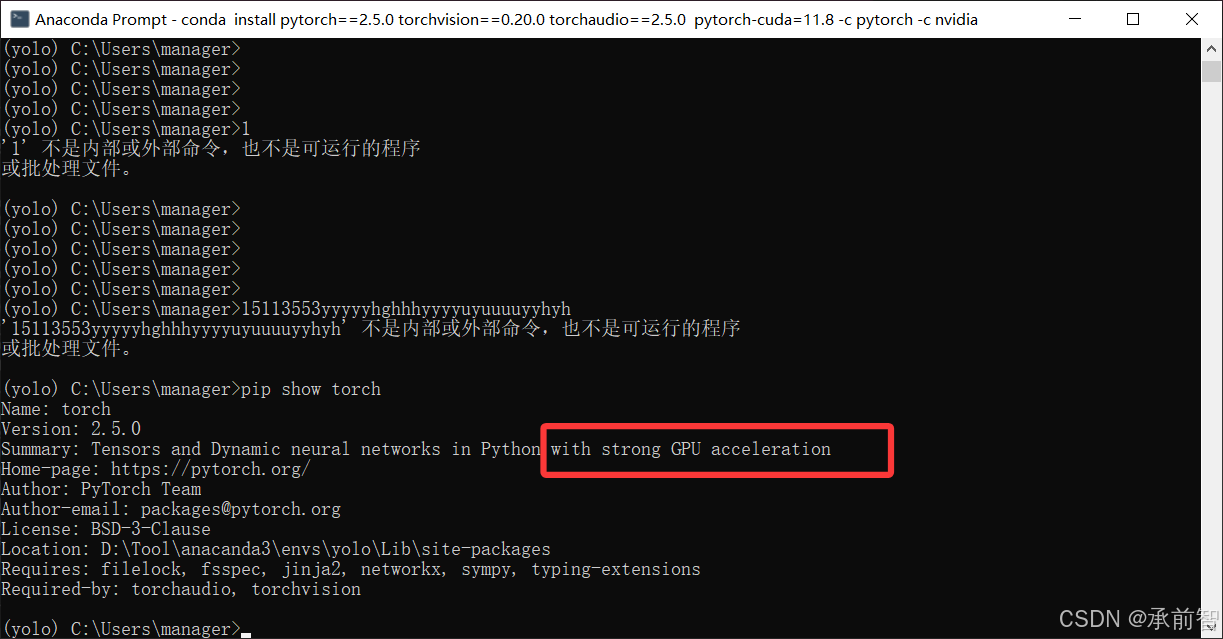
PyTorch 验证
- 输入
python(记住要在yolo环境下)
→import torchvision
→import torch
→torch.cuda.is_available()(True说明是GPU版本,False说明是CPU版本)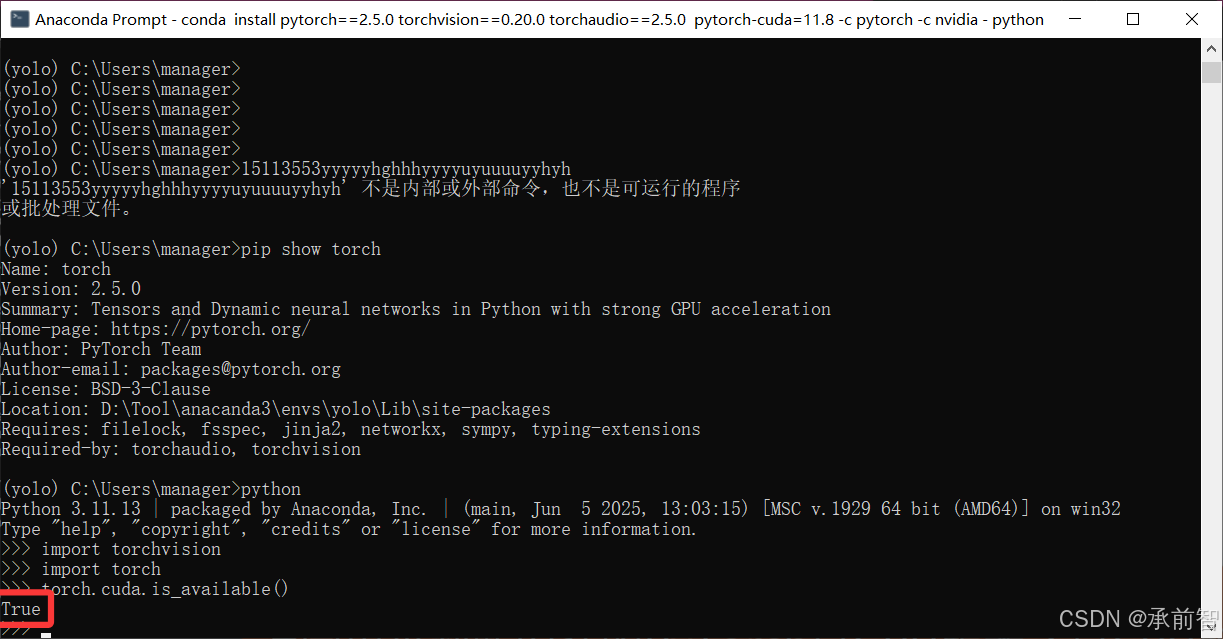
→torch.randn(1).cuda()(创建一个随机数,然后把这个随机数加载到GPU。极少数情况下即使torch.cuda.is_available()返回True
这个命令也会报错,代表PyTorch其实用不了GPU)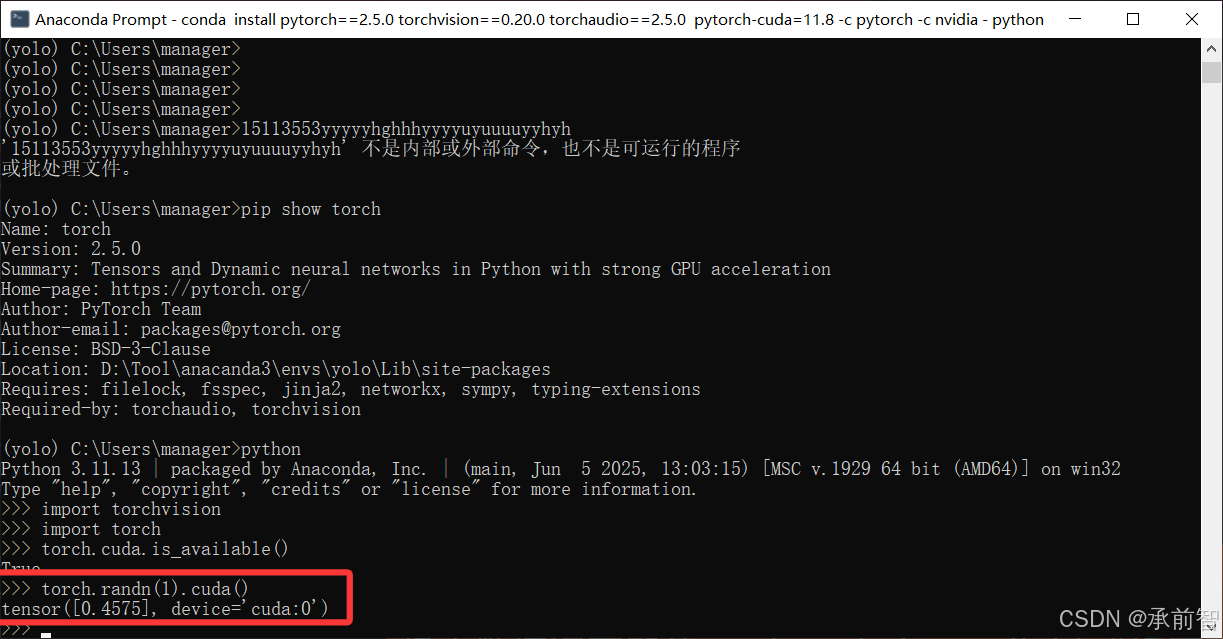
→Ctrl+Z(退出python,返回)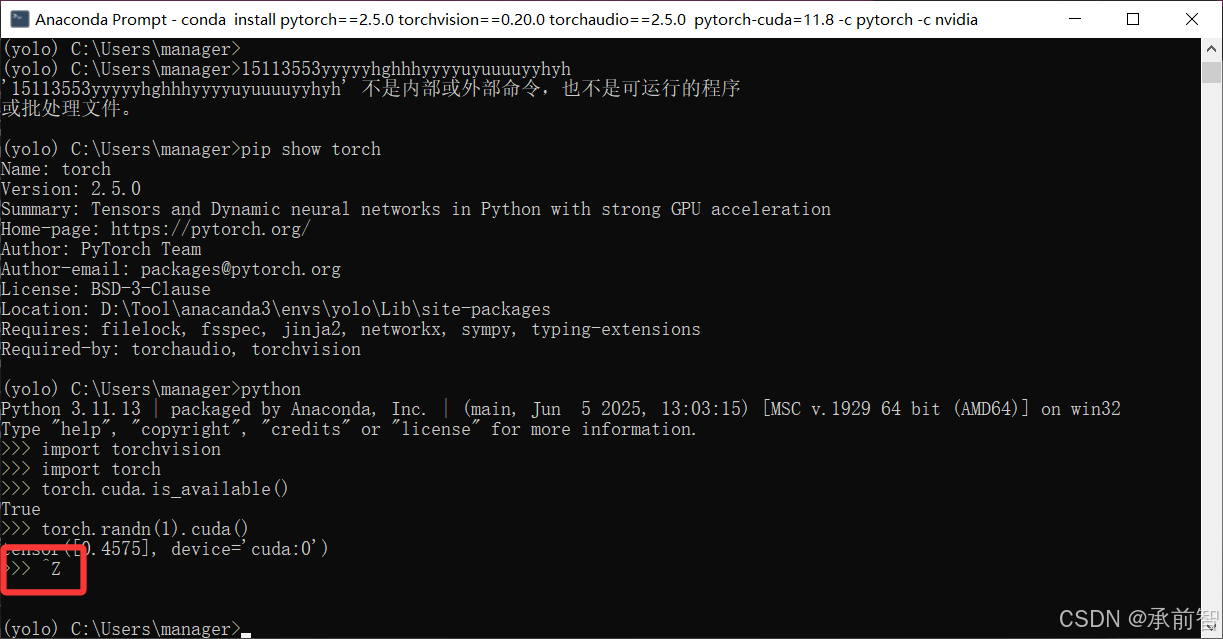
三、依赖包 安装步骤
-
复制前面的文件夹路径
D:\DeepLearning\ultralytics-8.3.163
-
打开 Anaconda Prompt
-
输入
conda activate yolo,进入yolo环境
-
输入
pushd D:\DeepLearning\ultralytics-8.3.163,进入文件夹(记得改成自己的路径)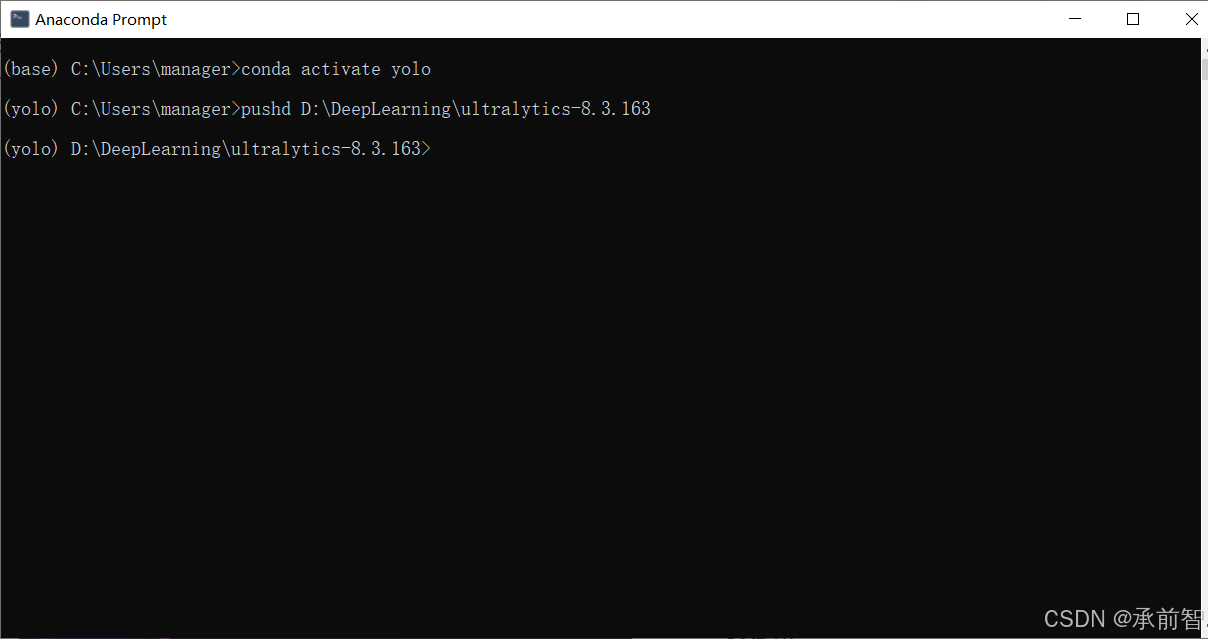
-
输入
pip install -e .,安装其他包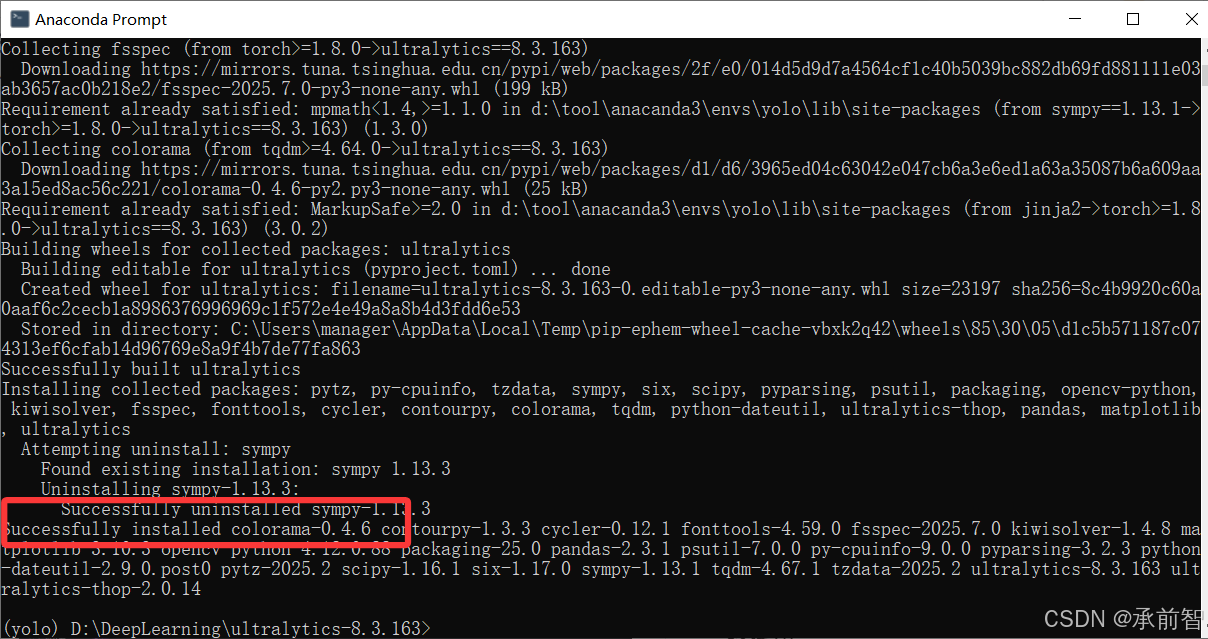
YOLO 项目验证(命令集)
-
打开 Anaconda Prompt
-
输入
conda activate yolo,进入yolo环境 -
输入
pushd D:\DeepLearning\ultralytics-8.3.163,进入文件夹(记得改成自己的路径)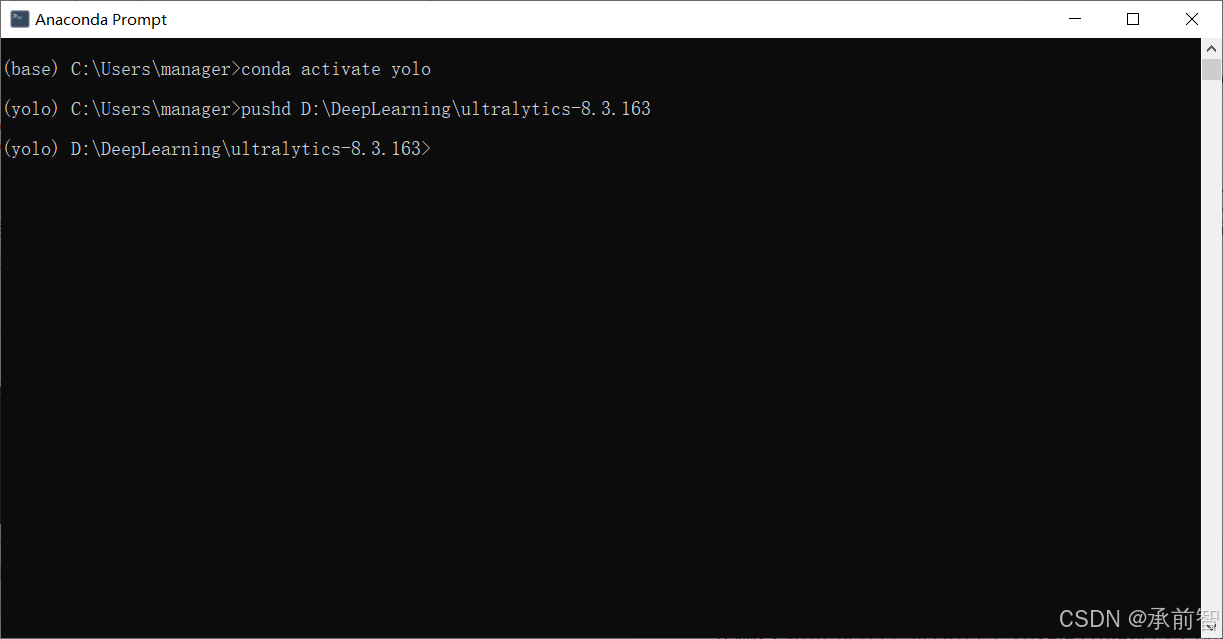
-
输入
yolo detect predict,用yolo11n.pt这个目标检测模型,预测D:\DeepLearning\ultralytics-8.3.163\ultralytics\assets里的两张图片
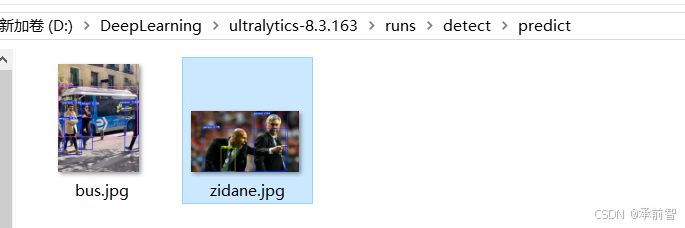
图片预测结果 保存在D:\DeepLearning\ultralytics-8.3.163\runs\detect\predict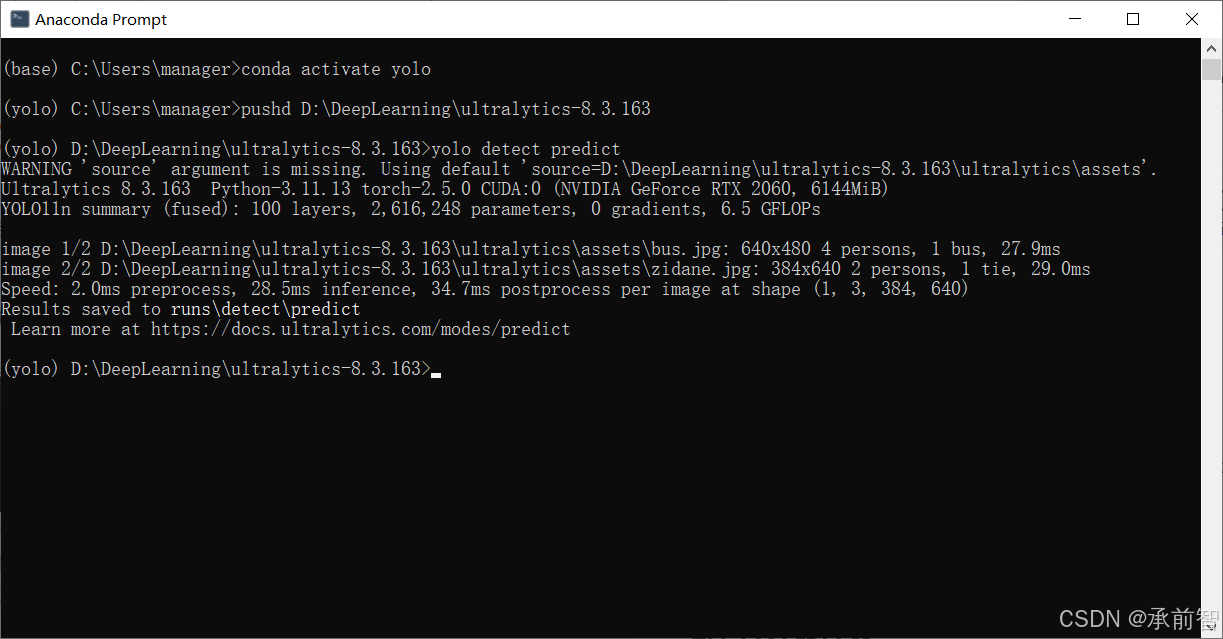

四、 Pycharm 卸载与安装
若是电脑内有下载过,建议卸载。参考 Pycharm如何完全卸载干净
- 从JETBRAINS下载
2025.1.1.1 - Windows x64 (exe)
通过网盘分享的文件:pycharm-community-2025.1.1.1.zip - 打开安装包,注意安装路径,不能重复嵌套/含中文或空格
Pycharm 环境配置
-
打开 Pycharm ,打开项目
D:\DeepLearning\ultralytics-8.3.163
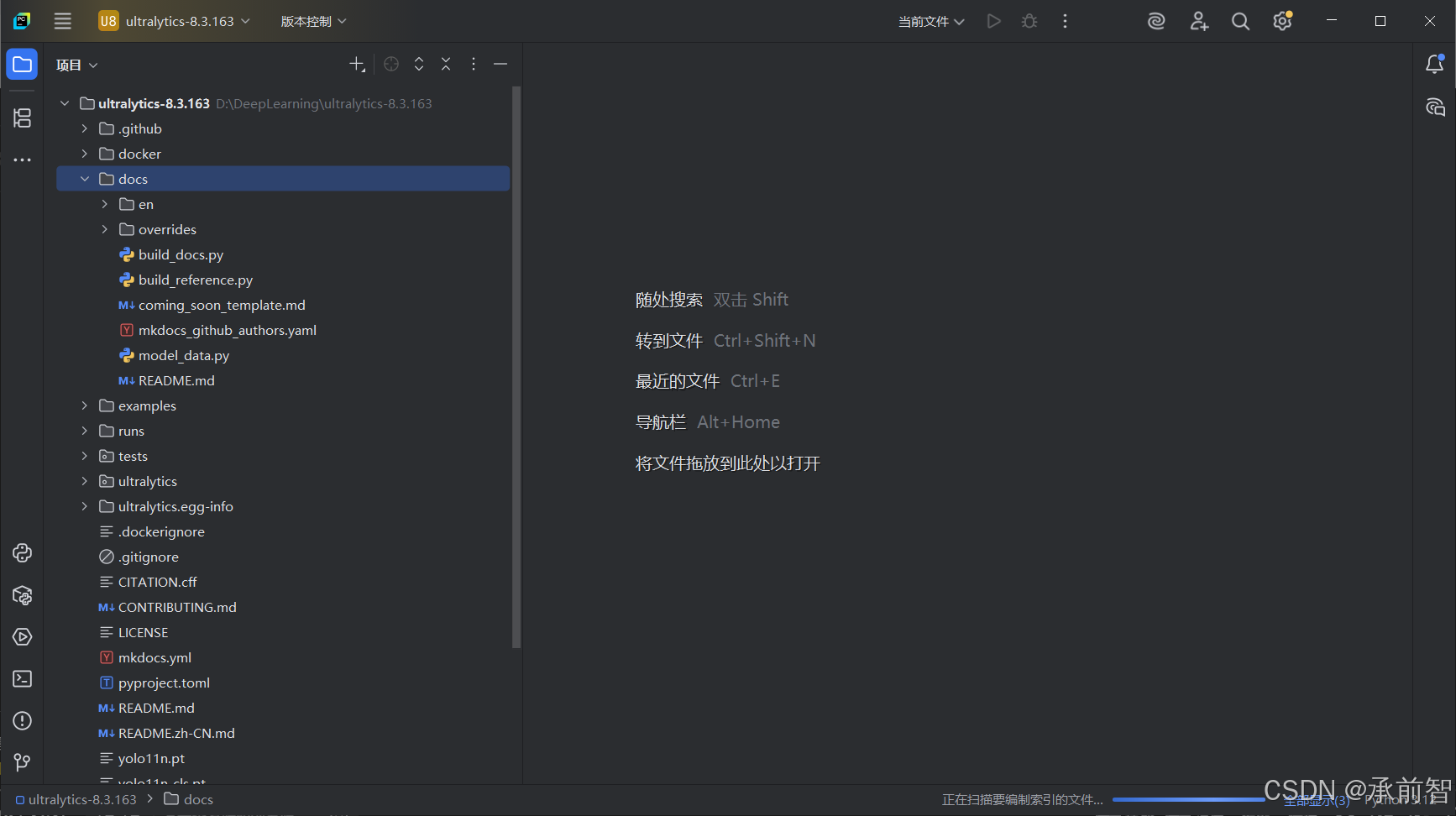
-
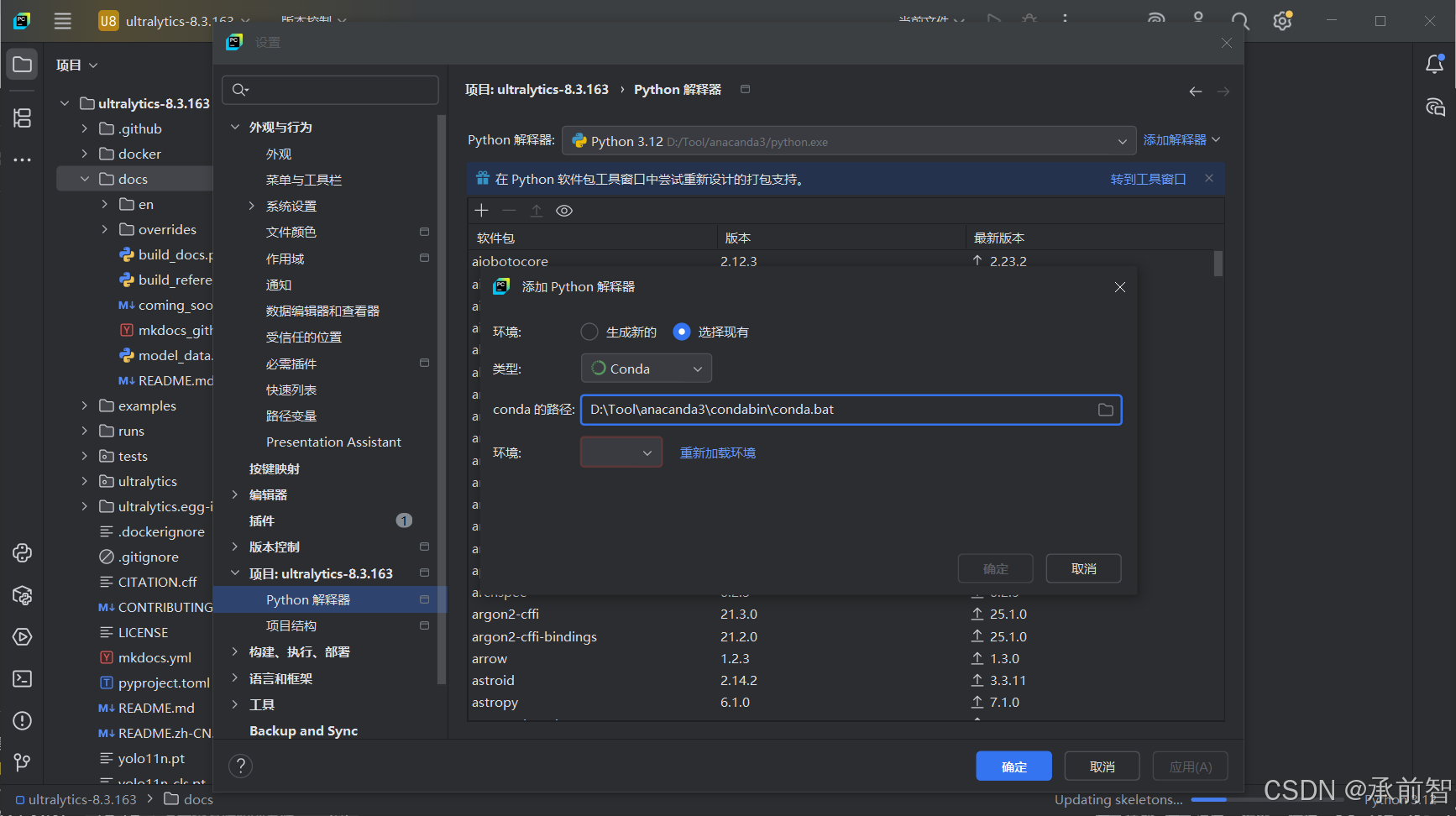
左上角 “文件” → “设置” → “项目:ultralytics-8.3.163” → “Python 解释器” → “添加解释器” → “选择现有” → “添加解释器”
类型: Conda
路径: D:\Tool\anacanda3\condabin\conda.bat
环境: yolo (重新加载环境,后点击 生成新的/选择现有 )
→ 确定
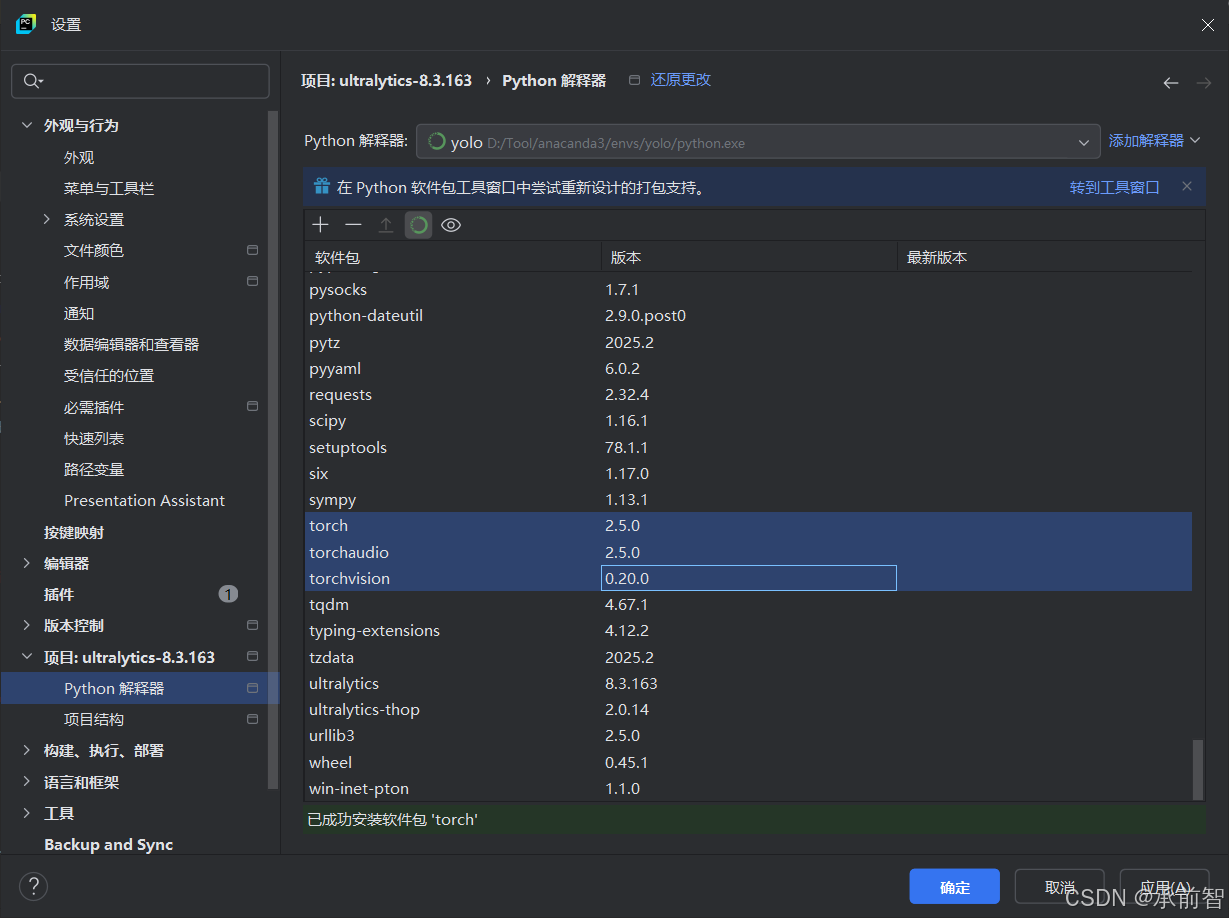
若没有torch和PyQt5,下载torch2.5.0和PyQt5(最新版)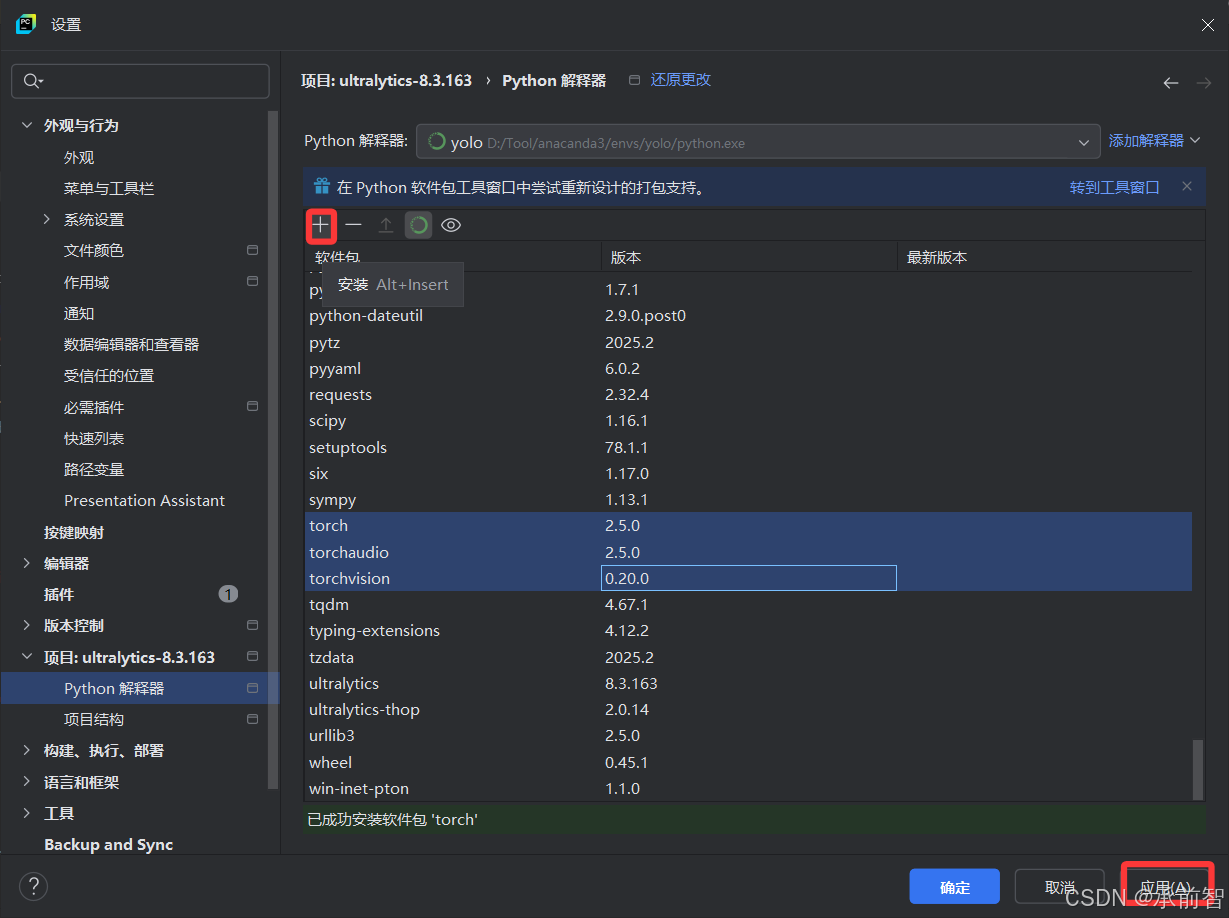
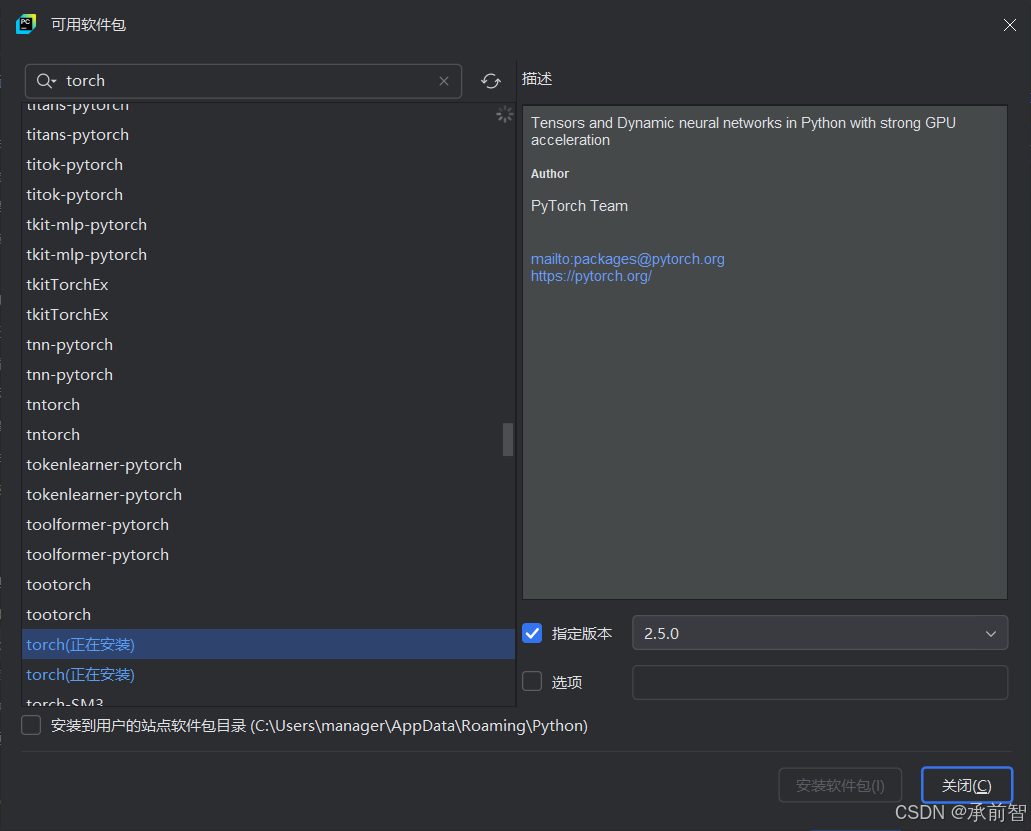
YOLO 项目配置(pycharm)
1)Single_image_detection.py
- 打开 Pycharm ,打开项目
D:\DeepLearning\ultralytics-8.3.163 - 新建一个源文件
Single_image_detection.py(注意与模型同级文件夹)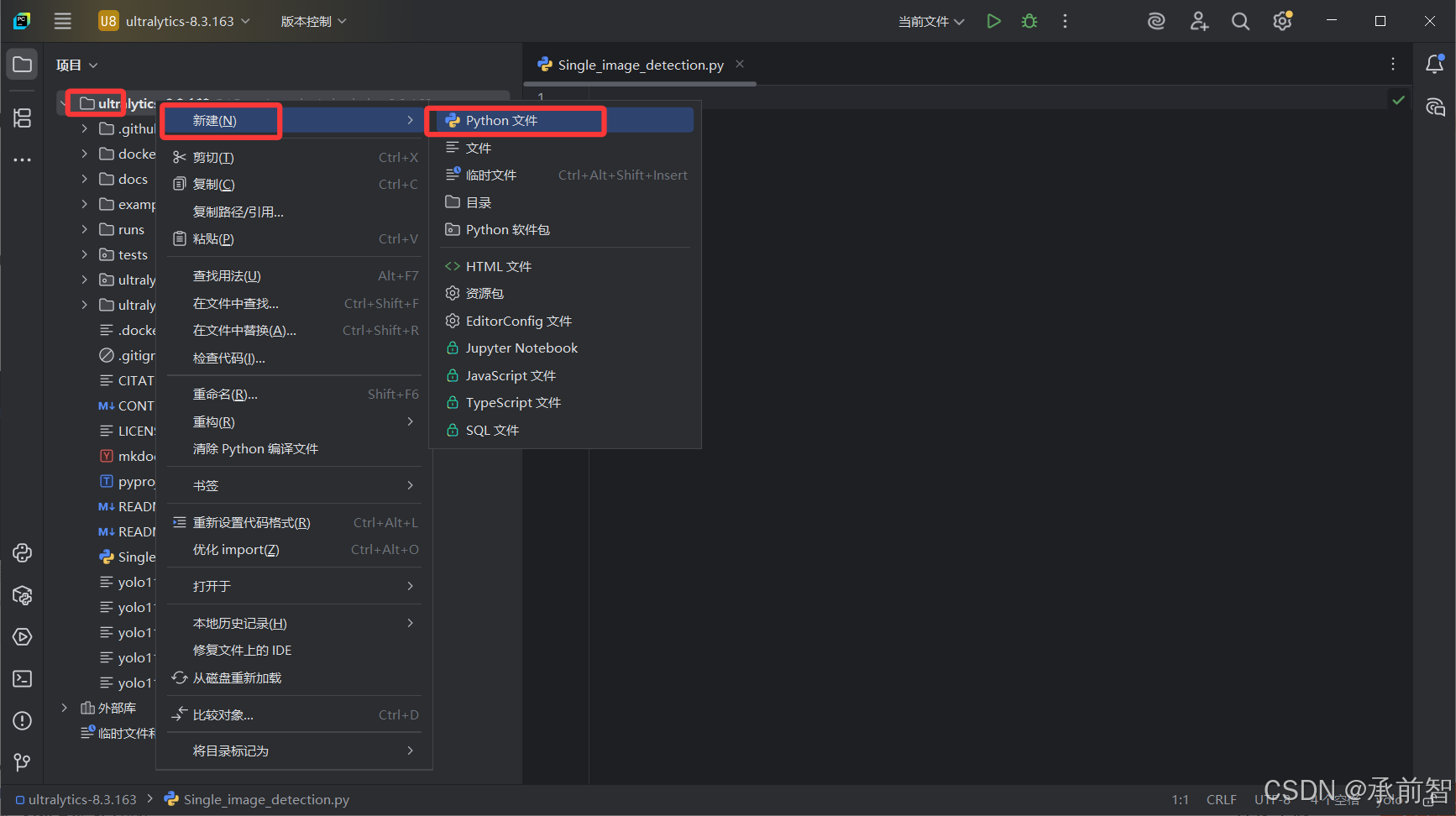
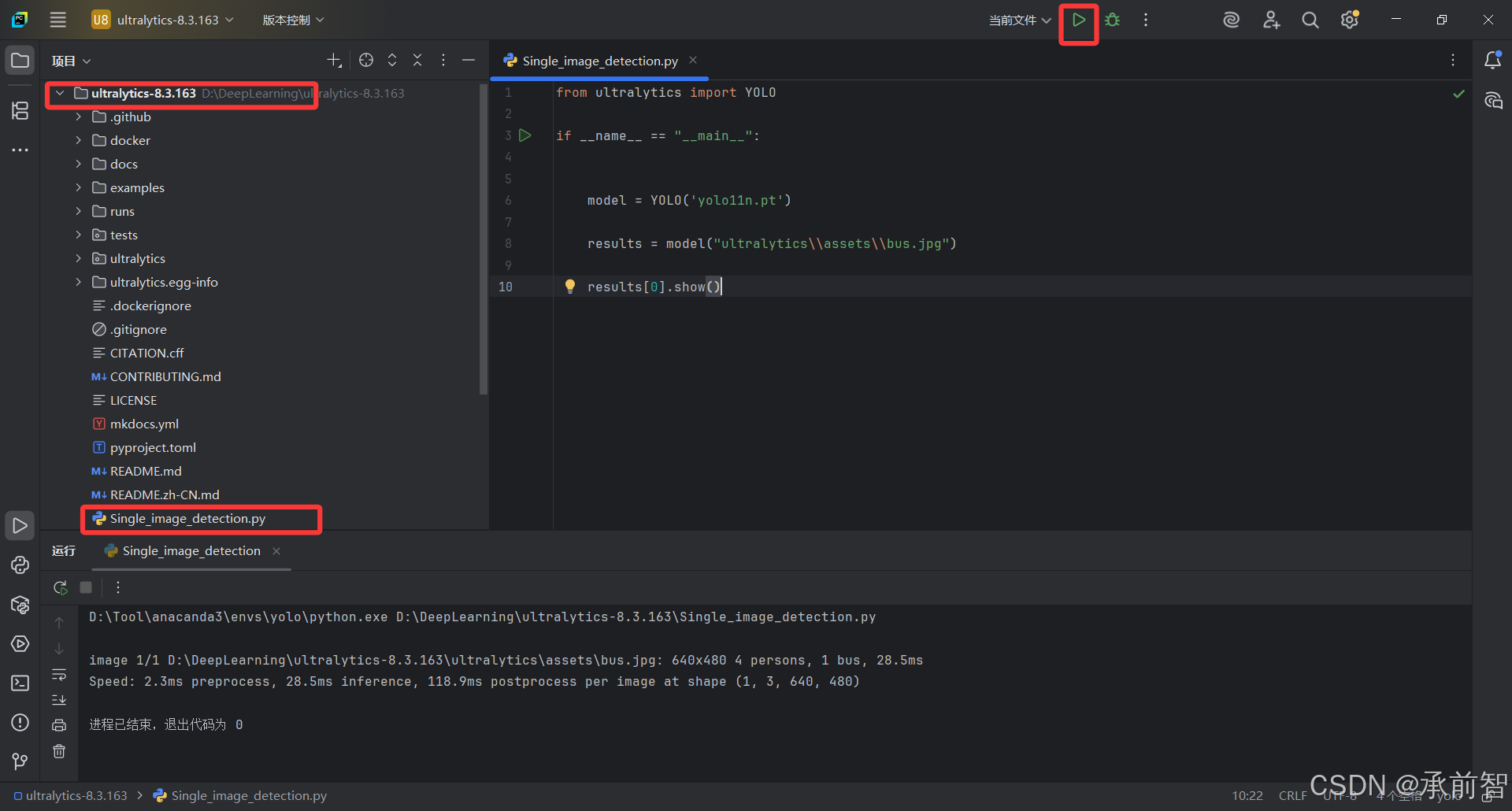
from ultralytics import YOLO
if __name__ == "__main__":
model = YOLO('yolo11n.pt')
# 模型的绝对路径为 D:\DeepLearning\ultralytics-8.3.163\yolo11n.pt
# 模型使用 来自内容根的路径
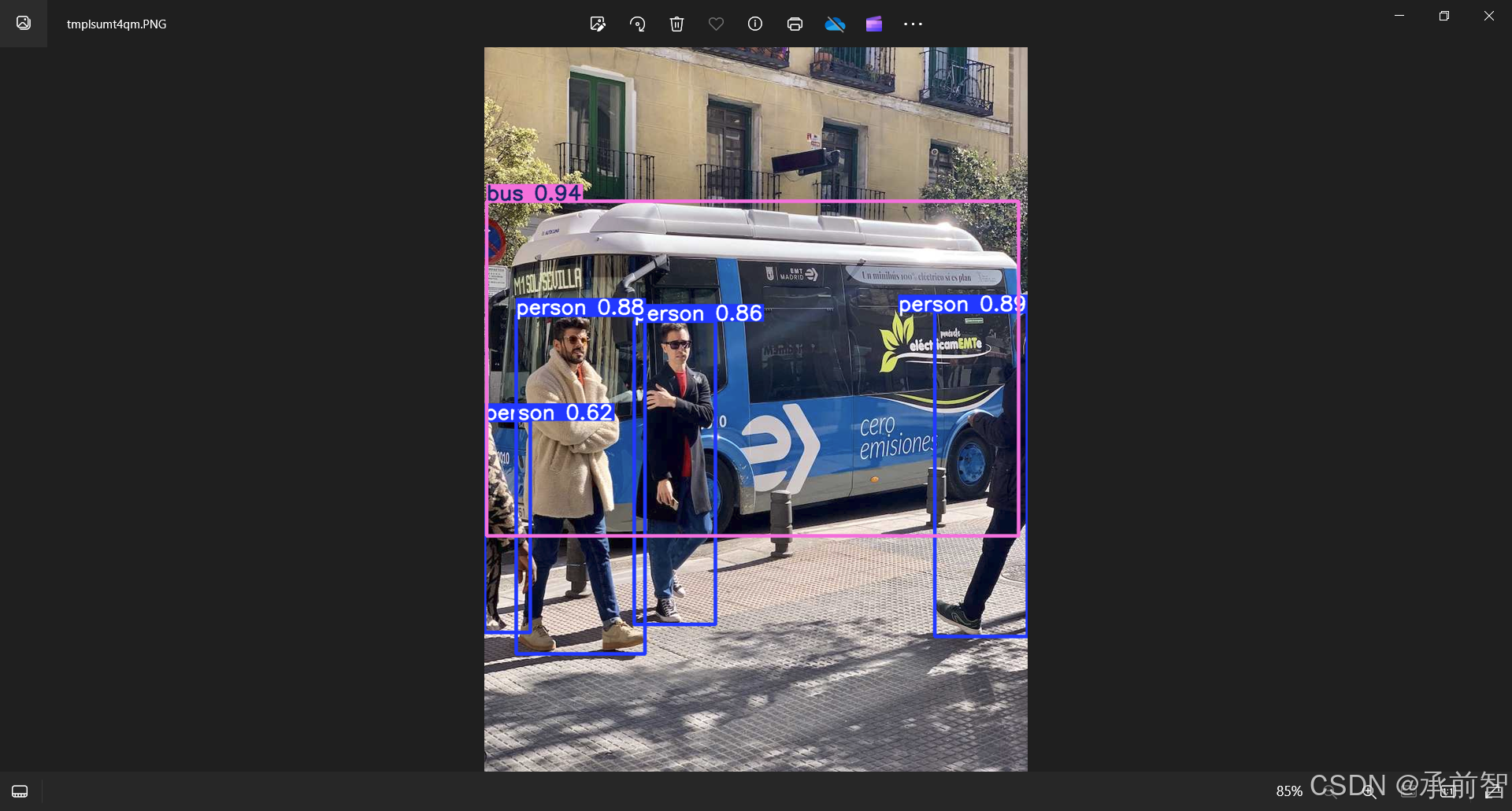
results = model("ultralytics\\assets\\bus.jpg")
# 图片绝对路径为 D:\DeepLearning\ultralytics-8.3.163\ultralytics\assets\bus.jpg
# 但这边我们右键图片,使用 来自内容根的路径
results[0].show()
# 若想保存结果,则用下面这个代码
# from ultralytics import YOLO
#
# if __name__ == '__main__':
# model = YOLO('yolo11n.pt')
# model.predict(
# source='D:\\Download\\src.jpg',
# save=True,
# show=True
# )
结果验证:
2)Multi_image_detection.py
- 打开 Pycharm ,打开项目
D:\DeepLearning\ultralytics-8.3.163 - 新建一个源文件
Multi_image_detection.py(注意与模型同级文件夹)
# 标准库导入
import os
import sys
# 第三方库导入
import cv2
from ultralytics import YOLO
# PyQt5 核心模块导入
from PyQt5.QtCore import Qt, QTimer
from PyQt5.QtGui import QImage, QPixmap
# PyQt5 组件导入
from PyQt5.QtWidgets import (
QApplication,
QMainWindow,
QLabel,
QVBoxLayout,
QWidget,
QPushButton,
QHBoxLayout,
QFileDialog,
QMessageBox,
QInputDialog # 用于设置间隔时间
)
# connect和static也明确保留源代码,不需要修改
class Worker:
def __init__(self):
self.model = None
self.current_annotated_image = None
self.detection_type = None
def load_model(self):
model_path, _ = QFileDialog.getOpenFileName(None, "选择模型文件", "", "模型文件 (*.pt)")
if model_path:
self.model = YOLO(model_path)
return self.model is not None # 直接返回布尔值
return False
def detect_objects(self, frame):
det_info = []
class_ids = frame[0].boxes.cls
class_names_dict = frame[0].names
for class_id in class_ids:
class_name = class_names_dict[int(class_id)]
det_info.append(class_name)
return det_info
def save_image(self, image):
if image is not None:
file_name, _ = QFileDialog.getSaveFileName(None, "保存图片", "", "JPEG (*.jpg);;PNG (*.png);;All Files (*)")
if file_name:
cv2.imwrite(file_name, image)
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.flag = 0 # 0=单图检测,1=文件夹检测
self.current_results = None # 存储检测结果
# 新增定时器相关 ↓
self.timer = QTimer(self)
self.timer.timeout.connect(self.next_image)
self.image_paths = [] # 存储文件夹图片路径
self.current_image_index = 0
self.switch_interval = 1000 # 默认1秒切换间隔
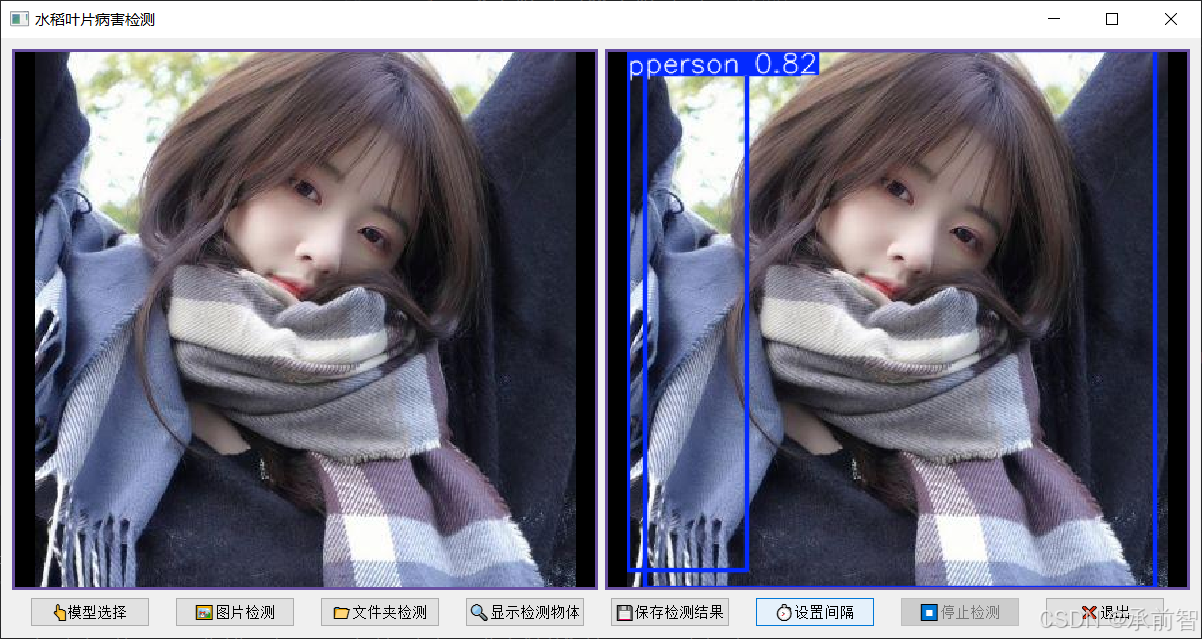
self.setWindowTitle("水稻叶片病害检测")
# self.setWindowIcon(QIcon("icon.png"))
self.setGeometry(300, 150, 1200, 600)
# 创建两个 QLabel 分别显示左右图像
self.label1 = QLabel()
self.label1.setAlignment(Qt.AlignCenter)
self.label1.setMinimumSize(580, 450) # 设置大小
self.label1.setStyleSheet('border:3px solid #6950a1; background-color: black;') # 添加边框并设置背景颜色为黑色
self.label2 = QLabel()
self.label2.setAlignment(Qt.AlignCenter)
self.label2.setMinimumSize(580, 450) # 设置大小
self.label2.setStyleSheet('border:3px solid #6950a1; background-color: black;') # 添加边框并设置背景颜色为黑色
# 水平布局,用于放置左右两个 QLabel
layout = QVBoxLayout()
hbox_video = QHBoxLayout()
hbox_video.addWidget(self.label1)
hbox_video.addWidget(self.label2)
layout.addLayout(hbox_video)
self.worker = Worker()
# 创建按钮布局
hbox_buttons = QHBoxLayout()
# 添加模型选择按钮
self.load_model_button = QPushButton("👆模型选择")
self.load_model_button.clicked.connect(self.load_model)
self.load_model_button.setFixedSize(120, 30)
hbox_buttons.addWidget(self.load_model_button)
# 添加图片检测按钮
self.image_detect_button = QPushButton("🖼️️图片检测")
self.image_detect_button.clicked.connect(self.select_image)
self.image_detect_button.setEnabled(False)
self.image_detect_button.setFixedSize(120, 30)
hbox_buttons.addWidget(self.image_detect_button)
# 添加图片文件夹检测按钮
self.folder_detect_button = QPushButton("️📁文件夹检测")
self.folder_detect_button.clicked.connect(self.detect_folder)
self.folder_detect_button.setEnabled(False)
self.folder_detect_button.setFixedSize(120, 30)
hbox_buttons.addWidget(self.folder_detect_button)
# 添加显示检测物体按钮
self.display_objects_button = QPushButton("🔍显示检测物体")
self.display_objects_button.clicked.connect(self.show_detected_objects)
self.display_objects_button.setEnabled(False)
self.display_objects_button.setFixedSize(120, 30)
hbox_buttons.addWidget(self.display_objects_button)
# # 添加保存检测结果按钮
self.save_button = QPushButton("💾保存检测结果")
self.save_button.clicked.connect(self.save_detection)
self.save_button.setEnabled(False)
self.save_button.setFixedSize(120, 30)
hbox_buttons.addWidget(self.save_button)
# 添加间隔设置按钮
self.interval_button = QPushButton("⏱️设置间隔")
self.interval_button.clicked.connect(self.set_interval)
self.interval_button.setFixedSize(120, 30)
hbox_buttons.addWidget(self.interval_button)
# 添加停止按钮
self.stop_button = QPushButton("⏹️停止检测")
self.stop_button.clicked.connect(self.stop_detection)
self.stop_button.setEnabled(False) # 初始不可用
self.stop_button.setFixedSize(120, 30)
hbox_buttons.addWidget(self.stop_button)
# 添加退出按钮
self.exit_button = QPushButton("❌退出")
self.exit_button.clicked.connect(self.exit_application)
self.exit_button.setFixedSize(120, 30)
hbox_buttons.addWidget(self.exit_button)
layout.addLayout(hbox_buttons)
central_widget = QWidget()
central_widget.setLayout(layout)
self.setCentralWidget(central_widget)
def stop_detection(self):
self.timer.stop()
self.stop_button.setEnabled(False)
QMessageBox.information(self, "提示", "文件夹检测已停止")
def set_interval(self):
interval, ok = QInputDialog.getInt(
self, "设置切换间隔", "毫秒数:",
self.switch_interval, 100, 5000, 100
)
if ok:
self.switch_interval = interval
if self.timer.isActive():
self.timer.setInterval(interval)
def save_detection(self):
detection_type = self.worker.detection_type
if detection_type == "image":
self.save_detection_results()
def select_image(self):
self.timer.stop() # 停止定时器
image_path, _ = QFileDialog.getOpenFileName(None, "选择图片文件", "", "图片文件 (*.jpg *.jpeg *.png)")
self.flag = 0
if image_path:
self.detect_image(image_path)
def detect_folder(self):
folder_path = QFileDialog.getExistingDirectory(self, "选择图片文件夹")
if folder_path:
self.flag = 1
self.image_paths = [
os.path.join(folder_path, f)
for f in os.listdir(folder_path)
if f.lower().endswith((".jpg", ".jpeg", ".png"))
]
self.current_image_index = 0
if self.image_paths:
self.stop_button.setEnabled(True) # 启用停止按钮
self.timer.start(self.switch_interval) # 启动定时器
self.detect_image(self.image_paths[0]) # 显示第一张
def next_image(self):
if self.image_paths and self.timer.isActive():
self.current_image_index = (self.current_image_index + 1) % len(self.image_paths)
if self.current_image_index == 0: # 检测到循环完成一轮
self.stop_detection() # 自动停止
else:
self.detect_image(self.image_paths[self.current_image_index])
def detect_image(self, image_path):
if image_path:
results = None # 先初始化
print(image_path)
image = cv2.imread(image_path)
if image is not None:
if self.flag == 0:
results = self.worker.model.predict(image)
elif self.flag == 1:
results = self.worker.model.predict(image_path, save=True)
self.worker.detection_type = "image"
if results:
self.current_results = results
self.worker.current_annotated_image = results[0].plot()
annotated_image = self.worker.current_annotated_image
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
height1, width1, channel1 = image_rgb.shape
bytes_per_line1 = 3 * width1
q_image1 = QImage(image_rgb.data, width1, height1, bytes_per_line1, QImage.Format_RGB888)
pixmap1 = QPixmap.fromImage(q_image1)
self.label1.setPixmap(pixmap1.scaled(self.label1.size(), Qt.KeepAspectRatio))
annotated_image = cv2.cvtColor(annotated_image, cv2.COLOR_BGR2RGB)
height2, width2, channel2 = annotated_image.shape
bytes_per_line2 = 3 * width2
q_image2 = QImage(annotated_image.data, width2, height2, bytes_per_line2, QImage.Format_RGB888)
pixmap2 = QPixmap.fromImage(q_image2)
self.label2.setPixmap(pixmap2.scaled(self.label2.size(), Qt.KeepAspectRatio))
self.save_button.setEnabled(True)
cv2.waitKey(300) # 修改图片切换时间
def save_detection_results(self):
if self.worker.current_annotated_image is not None:
self.worker.save_image(self.worker.current_annotated_image)
def show_detected_objects(self):
frame = self.current_results
if frame:
det_info = self.worker.detect_objects(frame)
if det_info:
object_count = len(det_info)
object_info = f"识别到的物体总个数:{object_count}\n"
object_dict = {}
for obj in det_info:
if obj in object_dict:
object_dict[obj] += 1
else:
object_dict[obj] = 1
sorted_objects = sorted(object_dict.items(), key=lambda x: x[1], reverse=True)
for obj_name, obj_count in sorted_objects:
object_info += f"{obj_name}: {obj_count}\n"
self.show_message_box("识别结果", object_info)
else:
self.show_message_box("识别结果", "未检测到物体")
def show_message_box(self, title, message):
msg_box = QMessageBox(self)
msg_box.setWindowTitle(title)
msg_box.setText(message)
msg_box.exec_()
def load_model(self):
if self.worker.load_model():
self.image_detect_button.setEnabled(True)
self.folder_detect_button.setEnabled(True)
self.display_objects_button.setEnabled(True)
def exit_application(self):
sys.exit()
if __name__ == '__main__':
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())
结果验证:
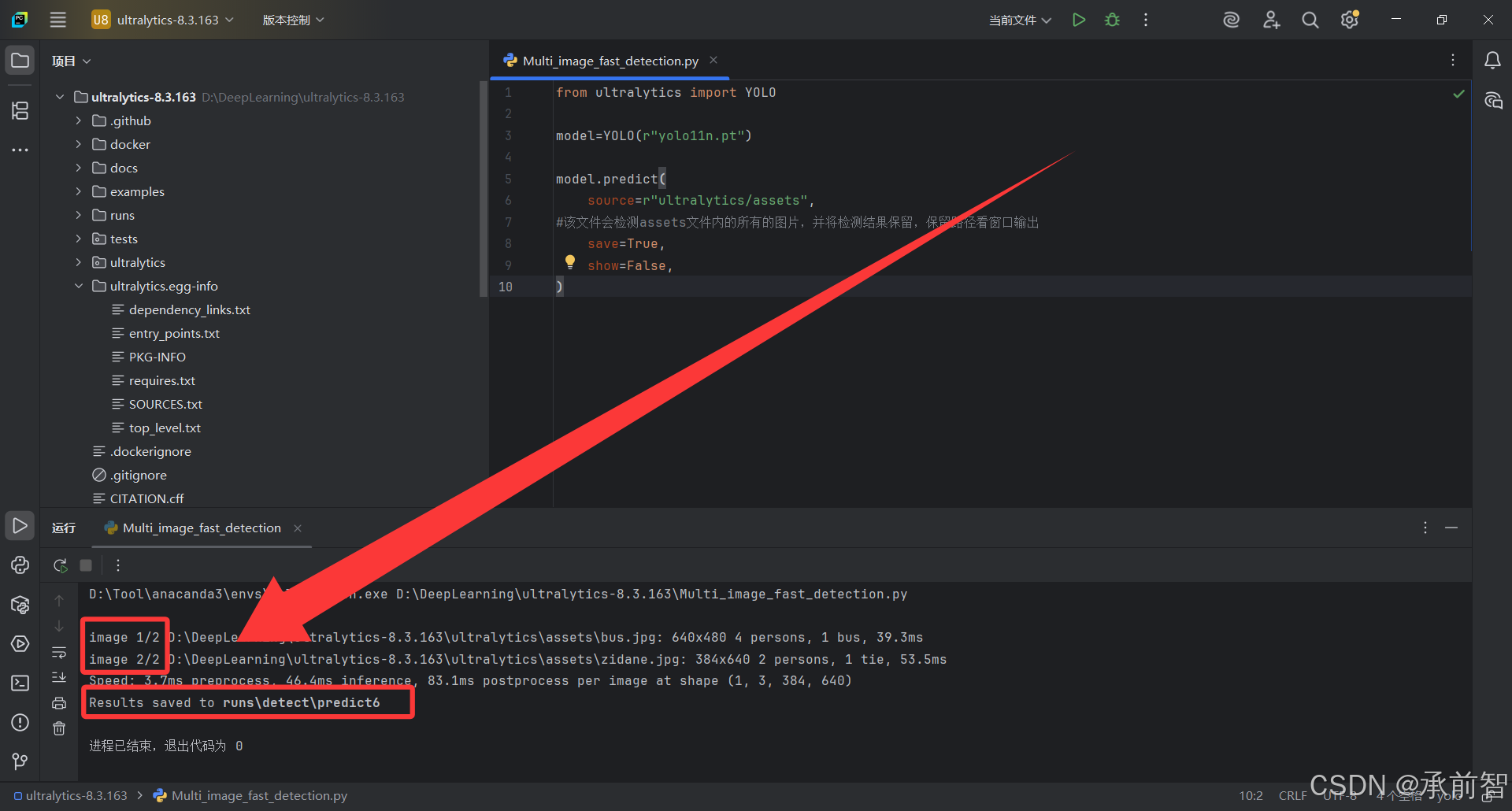
3)Multi_image_fast_detection.py
- 打开 Pycharm ,打开项目
D:\DeepLearning\ultralytics-8.3.163 - 新建一个源文件
Multi_image_fast_detection.py(注意与模型同级文件夹)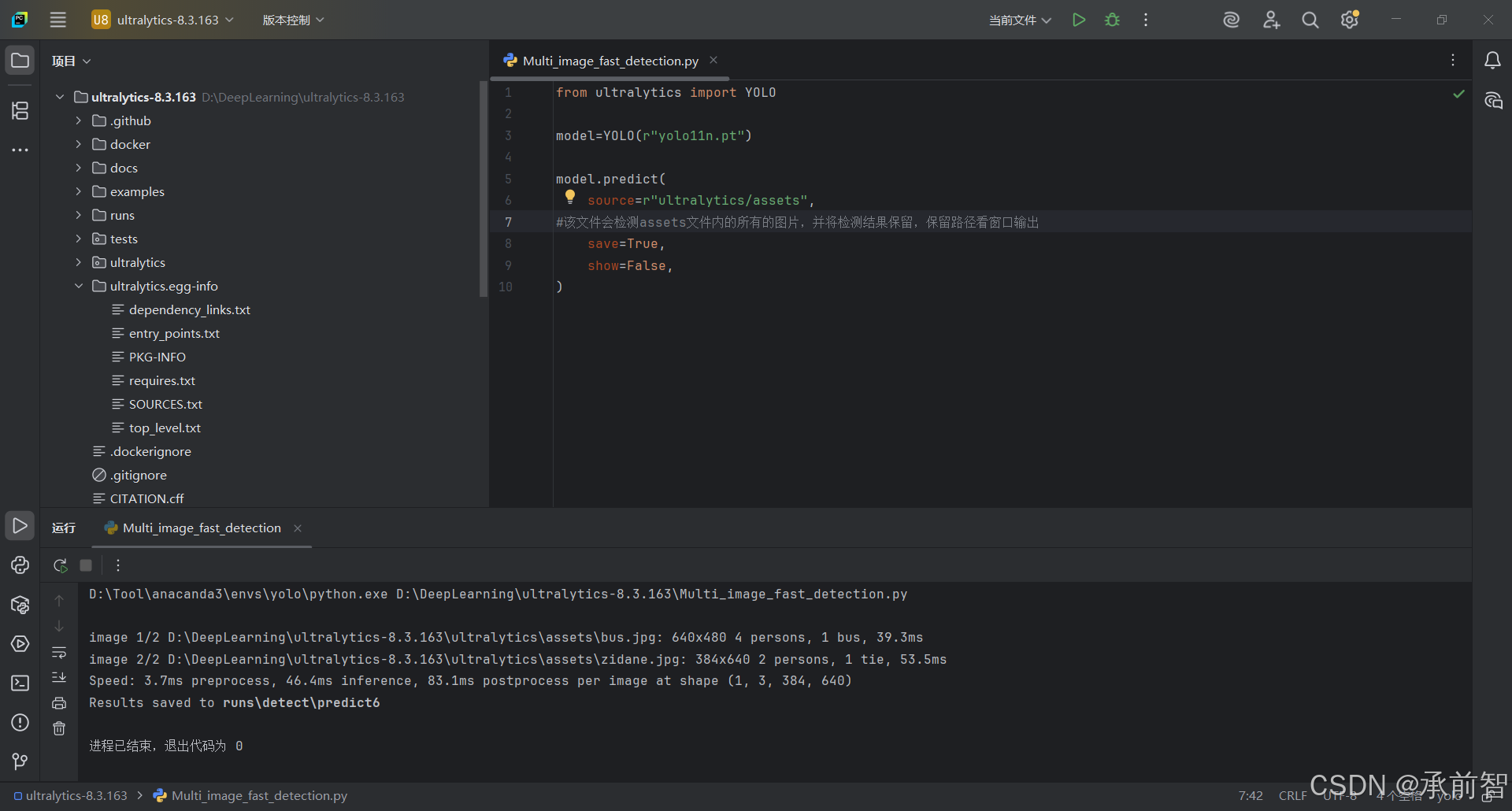
from ultralytics import YOLO
model = YOLO(model=r"yolo11n.pt")
model.predict(
source=r"ultralytics/assets",
#该文件会检测assets文件内的所有的图片,并将检测结果保留,保留路径看窗口输出
#也可将路径改为视频的绝对路径,此时输出的结果也是检测后的视频
save=True,
show=False,
)
结果验证:
4)Camera_realtime_detection
- 打开 Pycharm ,打开项目
D:\DeepLearning\ultralytics-8.3.163 - 新建一个源文件
Camera_realtime_detection(注意与模型同级文件夹)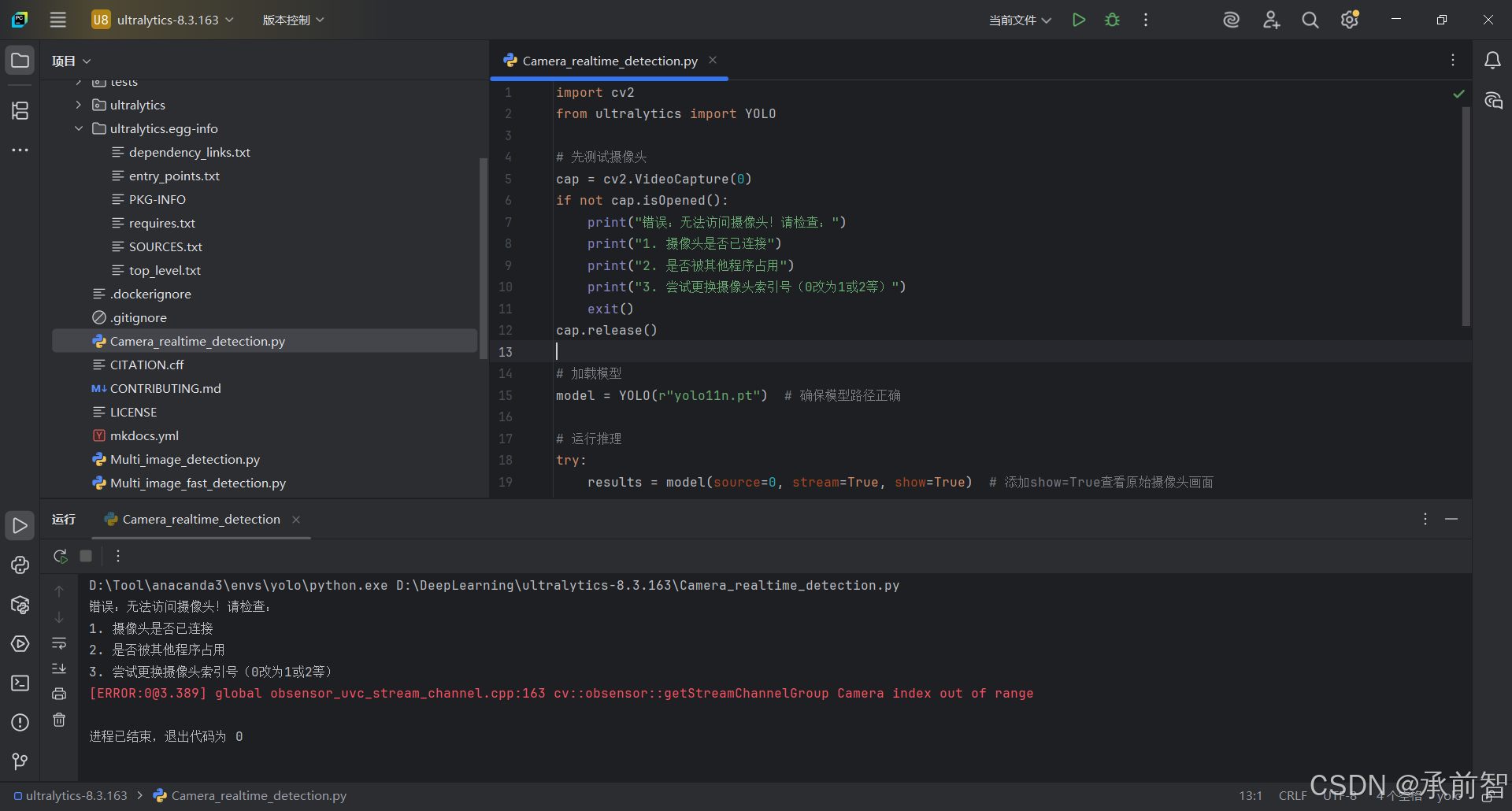
import cv2
from ultralytics import YOLO
# 先测试摄像头
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("错误:无法访问摄像头!请检查:")
print("1. 摄像头是否已连接")
print("2. 是否被其他程序占用")
print("3. 尝试更换摄像头索引号(0改为1或2等)")
exit()
cap.release()
# 加载模型
model = YOLO(r"yolo11n.pt") # 确保模型路径正确
# 运行推理
try:
results = model(source=0, stream=True, show=True) # 添加show=True查看原始摄像头画面
for result in results:
plotted = result.plot()
cv2.imshow("YOLO Inference", plotted)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
except Exception as e:
print(f"发生错误: {e}")
finally:
cv2.destroyAllWindows()
结果验证:
总结
本文完整实现了:
- YOLOv11基础环境搭建
- PyCharm开发环境配置
- 多场景验证方案
下篇将在此基础开展:
- 自定义数据集训练
- 模型精度调优
- 实际应用部署

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 22
22 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)