

算法偏见是什么
The term “bias” has a lot of pejorative connotations. When we think of it, we see unfair treatment, prejudice, discrimination, or favoring someone or something. And it’s natural. We live in a world where, unfortunately, all of these things take place. However, words have many meanings depending on the context, and surprisingly even bias can be something helpful.
术语“ 偏见 ”具有很多贬义的含义。 当我们想到它时,我们会看到不公平的对待,偏见,歧视或偏someone某人或某物。 这是自然的。 不幸的是,我们生活在一个世界上,所有这些事情都会发生。 但是,取决于上下文,单词具有多种含义,而且令人惊讶的是,偏见也可能会有所帮助。
Machine Learning is a domain where we can meet bias in a couple of contexts. Let’s go through these meanings and find the one which makes Neural Networks useful.
机器学习是一个我们可以在几种情况下克服偏见的领域。 让我们研究这些含义,找到使神经网络有用的含义。
有偏数据 (Biased data)
For starters let’s discuss the most general context of bias. It’s the bias inside the data used to train models. Every time we feed our Neural Network or other a model with data, it determines the model’s behavior. We cannot expect any fair or neutral treatment from algorithms that were built from biased data.
首先,让我们讨论偏见的最一般背景。 这是用于训练模型的数据内部的偏差。 每次我们向神经网络或其他模型提供数据时,它都会确定模型的行为。 我们不能期望从有偏见的数据构建的算法中获得任何公平或中立的待遇。
One of the well-known examples of such biased data was Amazon recruiting tool. It was supposed to do some pre-filtering of resumes so recruiters could choose from the most promising ones. And it was great in filtering out resumes! Especially in filtering out female resumes… Unfortunately, the wonderful, AI-powered solution was biased. The system was favoring male candidates as engineers mainly used male resumes in the training process [1].
这种有偏见的数据的著名例子之一是亚马逊招聘工具 。 它应该对简历进行一些预过滤,以便招聘人员可以从最有前途的候选人中进行选择。 而且很棒过滤掉简历! 尤其是在过滤掉女性简历的过程中……不幸的是,由AI驱动的出色解决方案存在偏见。 该系统偏爱男性候选人,因为工程师在培训过程中主要使用男性简历[1]。
Another example of a biased model is Tay. Tay was a chatbot released by Microsoft. It was supposed to carry conversations by posting Tweets. Tay was also able to learn from content posted by users. And that doomed Tay. It learned how to be offensive and aggressive. Tay became biased and switched off. Actually, it was made biased by irresponsible users who spoiled it with abusive posts [2].
偏差模型的另一个示例是Tay 。 Tay是Microsoft发布的聊天机器人。 应该通过发布推文来进行对话。 Tay还能够从用户发布的内容中学习。 那注定了泰。 它学会了如何进攻和进取。 Tay变得有偏见并被关闭。 实际上,它是由不负责任的用户所偏向的,他们用辱骂性的帖子破坏了它[2]。

So biased data is definitely a negative phenomenon. Being responsible and aware of it is an important part of building models. When you create an artificial brain you must be careful what you put inside it. Otherwise, you may bring to life a monster.
因此,有偏见的数据绝对是负面现象。 负责并意识到它是构建模型的重要组成部分。 当您创建人造大脑时,必须小心放入大脑中的内容。 否则,您可能使怪物变得栩栩如生。
整个神经网络的偏见 (The bias of a whole Neural Network)
Let’s take a look at the second context of bias. When we train and test our Neural Networks or other Machine Learning models, we can observe two main trends:
让我们看一下第二种偏见。 当我们训练和测试我们的神经网络或其他机器学习模型时,我们可以观察到两个主要趋势:
- Model overfits to data. 模型对数据过度拟合。
- Model cannon learn patterns from data. 模型大炮从数据中学习模式。
Overfitting is like learning by heart. Your model did remember a vast majority of your training data, however, when something new comes up it doesn’t work correctly. You can think of it as it’s good at answering questions it’s already been asked, but when you ask something out of the box the model fails.
过度拟合就像是内心学习。 您的模型确实记住了您的绝大多数训练数据,但是,当出现新情况时,它将无法正常工作。 您可以认为它很好地回答了已经提出的问题,但是当您开箱即用地提出问题时,该模型就会失败。
Such an issue can be nicely visualized if we plot validation and training set errors depending on the training set size. Then we can use learning curves to alert.
如果我们根据训练集的大小来绘制验证和训练集错误,则可以很好地看到这样的问题。 然后,我们可以使用学习曲线来提醒。
If we get a relatively low error for the training set, but the error is high for validation set it means we have a high variance model. A big gap between validation and training set error values visible in the plot is specific to overfitting [3,4].
如果训练集的误差相对较低,但验证集的误差较高,则意味着我们有较高的方差模型。 图中可见的验证和训练集误差值之间的巨大差距是特定于过拟合的[3,4]。
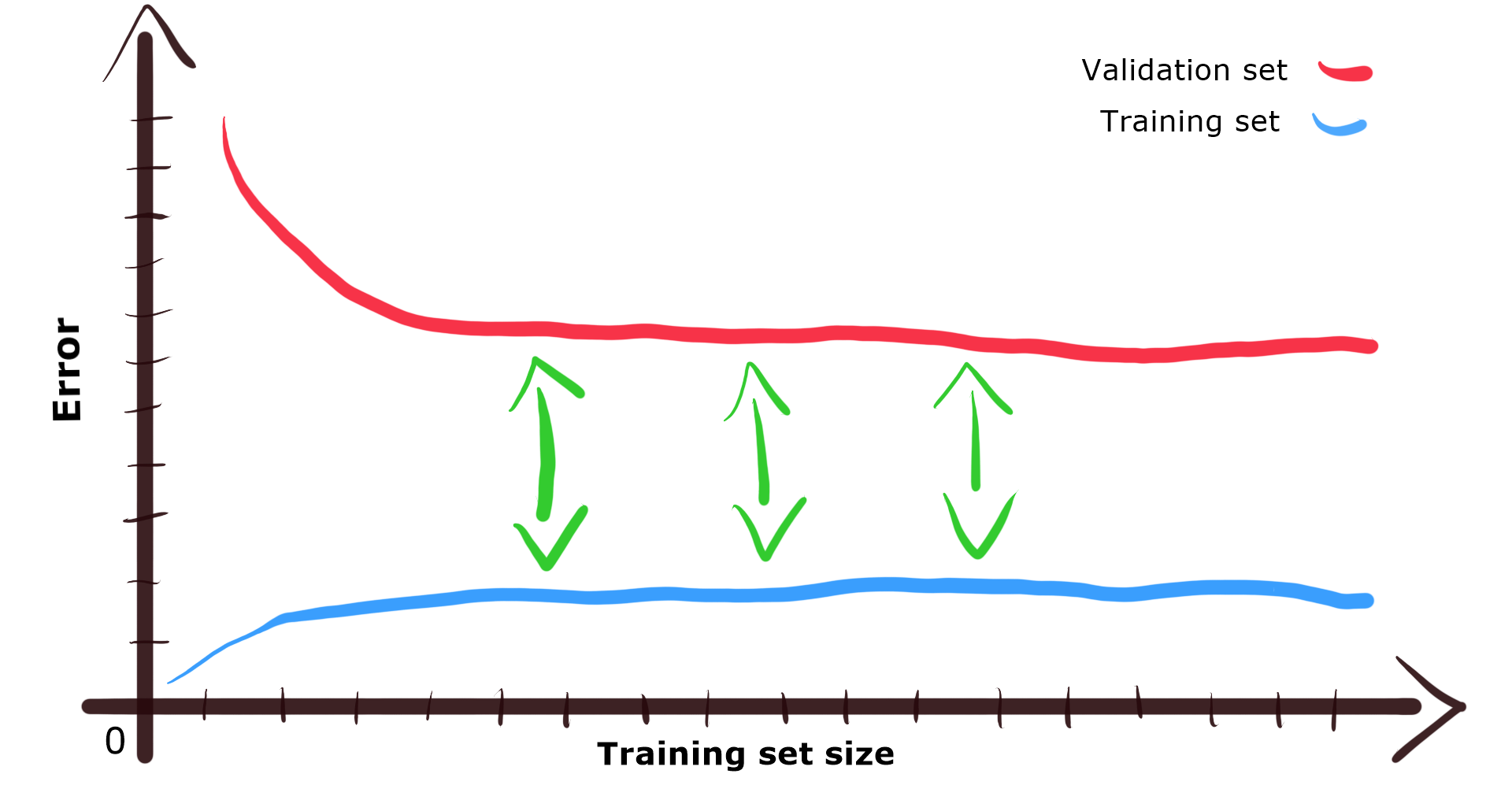
Let’s get back to the bias. When we speak about bias in the context of a model’s performance we can say that model has a high bias. Basically, it means that the model doesn’t do well during training, and what is expected, during validation. It behaves like a student that cannot grasp the idea we’re trying to teach them. There might be something wrong with the model or with our data [3,4].
让我们回到偏见。 当我们谈论模型性能方面的偏差时,可以说该模型具有很高的偏差 。 基本上,这意味着该模型在训练期间以及验证期间的预期效果不佳。 它的行为就像是一个学生,无法理解我们要教他们的想法。 模型或我们的数据[3,4]可能有问题。
When we take a look at learning curves plots and we see that the error is high for training set as well as for validation set, it may mean your model has high-bias. The gap between training and validation set curves will be small, as the model performs poorly in general. It lacks the ability to generalize and find patterns in data.
当我们看一下学习曲线图时,我们发现训练集和验证集的误差都很大,这可能意味着您的模型具有高偏差。 训练和验证集曲线之间的差距将很小,因为该模型的总体效果较差。 它缺乏概括和发现数据模式的能力。
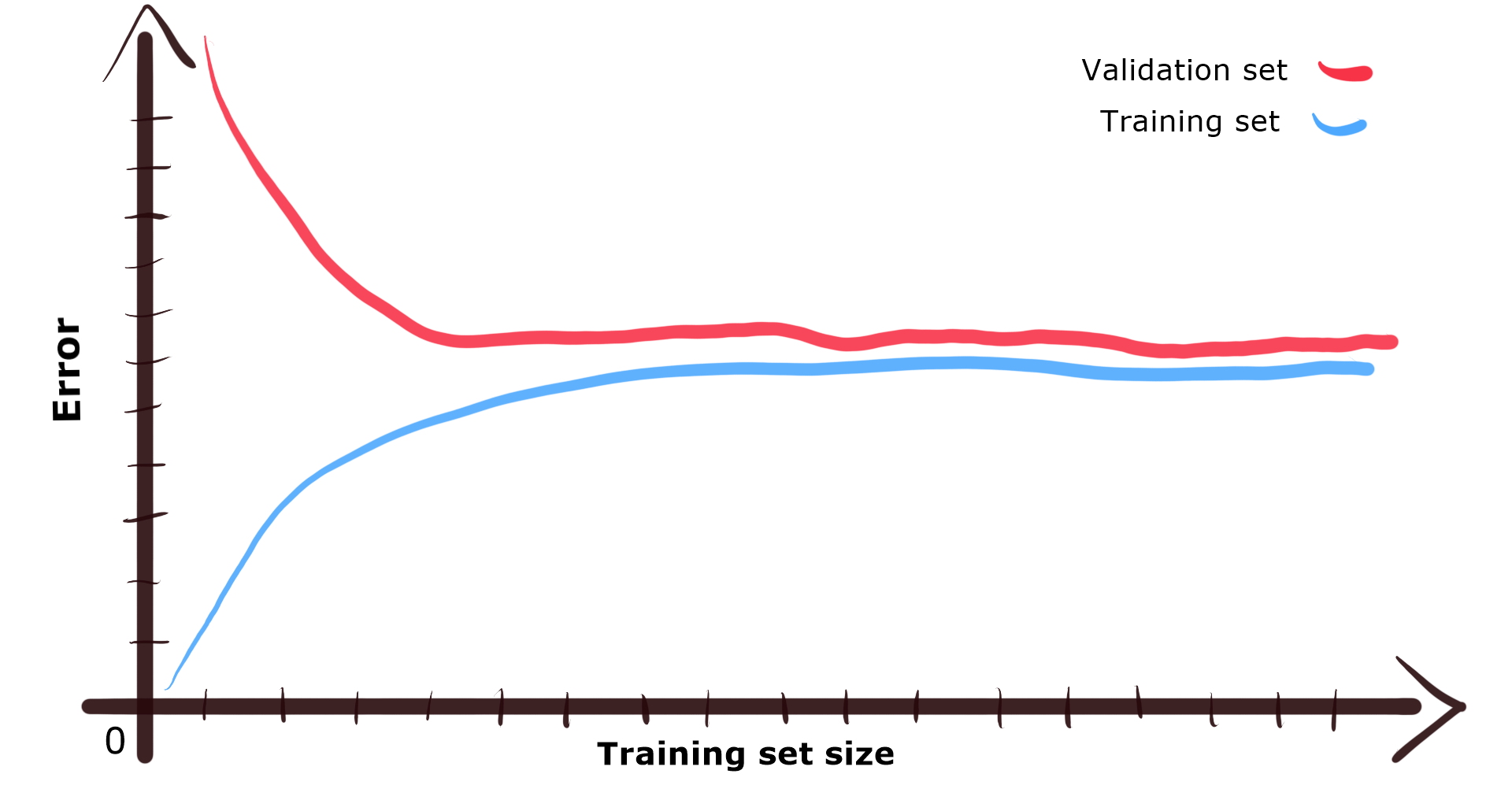
High bias is also something bad. Adding more data probably won’t help much. However, you can try to add extra features to data set samples. This additional information may give the model more clues while searching for patterns.
高偏见也是不好的。 添加更多数据可能无济于事。 但是,您可以尝试向数据集样本添加其他功能。 这些附加信息可能会在搜索模式时为模型提供更多线索。
You may also need to change a model. Sometimes models are too rigid to learn from data. Think of non-linearly distributed data points, which look like a parabola. If you will try to fit a simple line to this parabola your model will fail due to high bias. In such a case, a more flexible model (like a quadratic equation), which has more parameters is needed.
您可能还需要更改模型。 有时模型过于僵化,无法从数据中学习。 考虑一下看起来像抛物线的非线性分布数据点。 如果您尝试将一条简单的直线拟合到此抛物线,则由于高偏差,您的模型将失败。 在这种情况下,需要具有更多参数的更灵活的模型(如二次方程式)。
偏向单个神经元 (Bias as a single neuron)
Let’s analyze the third context, the bias in a particular Neural Network. In literature, we can find the term “bias neuron” [4]. Why we need this special kind of neurons? Take a look at the picture:
让我们分析第三种情况,即特定神经网络中的偏差。 在文献中,我们可以找到术语“ 偏向神经元 ” [4]。 为什么我们需要这种特殊的神经元? 看一下图片:
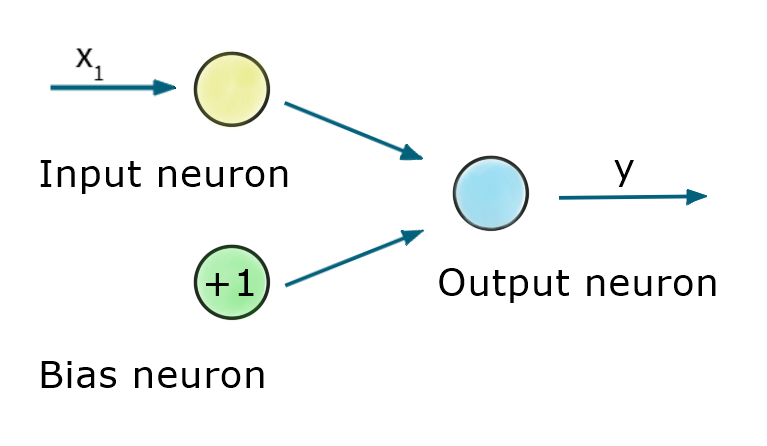
This simple neural network consists of 3 types of neurons. Input neuron simply passes feature (x₁) from the data set. Bias neuron mimics additional feature, let’s call it x₀. This additional input is always equal to 1. Finally, there is an output neuron, which is a full-fledged artificial neuron that takes inputs, processes them, and generates the output of the whole network.
这个简单的神经网络包含3种类型的神经元。 输入神经元只需传递数据集中的特征( x₁ )。 偏置神经元模仿了其他功能,我们称其为x₀ 。 此附加输入始终 等于1 。 最后,有一个输出神经元,它是一个成熟的人工神经元,它接受输入,对其进行处理并生成整个网络的输出。
Now let’s have a detailed look at our output neuron:
现在让我们详细看一下输出神经元:
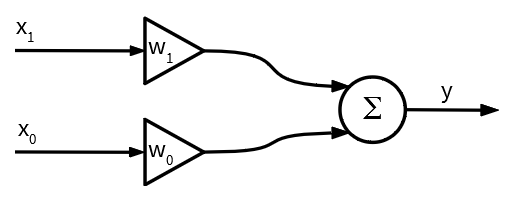
How does it work? We take inputs (x₀, x₁) and multiply them by corresponding weights (w₀, w₁). For the sake of simplicity the output neuron returns the sum os such inputs-weights products:
它是如何工作的? 我们以输入(X 0,X 1),并乘其相应的权重(W 0,W 1)。 为简单起见,输出神经元返回此类输入-权重乘积的和:
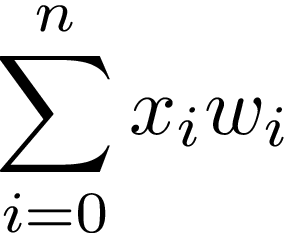
In our case i=1 and x₀=1. As a result, such Neural Network is actually a linear regression model:
在我们的情况下, i = 1且x₀= 1 。 结果,这样的神经网络实际上是线性回归模型:
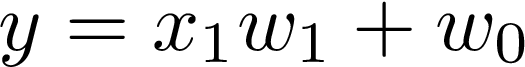
Now the crucial part. To understand why we need bias neuron, let’s see what happens when there is no bias input at all. It means that there will be only one input x₁ and nothing more:
现在至关重要的部分。 要了解为什么我们需要偏置神经元,让我们看看根本没有偏置输入时会发生什么。 这意味着将只有一个输入x₁ ,仅此而已:
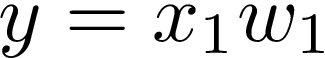
Such a model is not very flexible. It means that the line needs to go through the point (0, 0). A Slope of the line may change, however, it is tied to the coordinate system’s origin. Take a look at this visualization:
这样的模型不是很灵活。 这意味着线需要经过点(0,0) 。 直线的坡度可能会发生变化,但是,它与坐标系的原点相关。 看一下这个可视化:
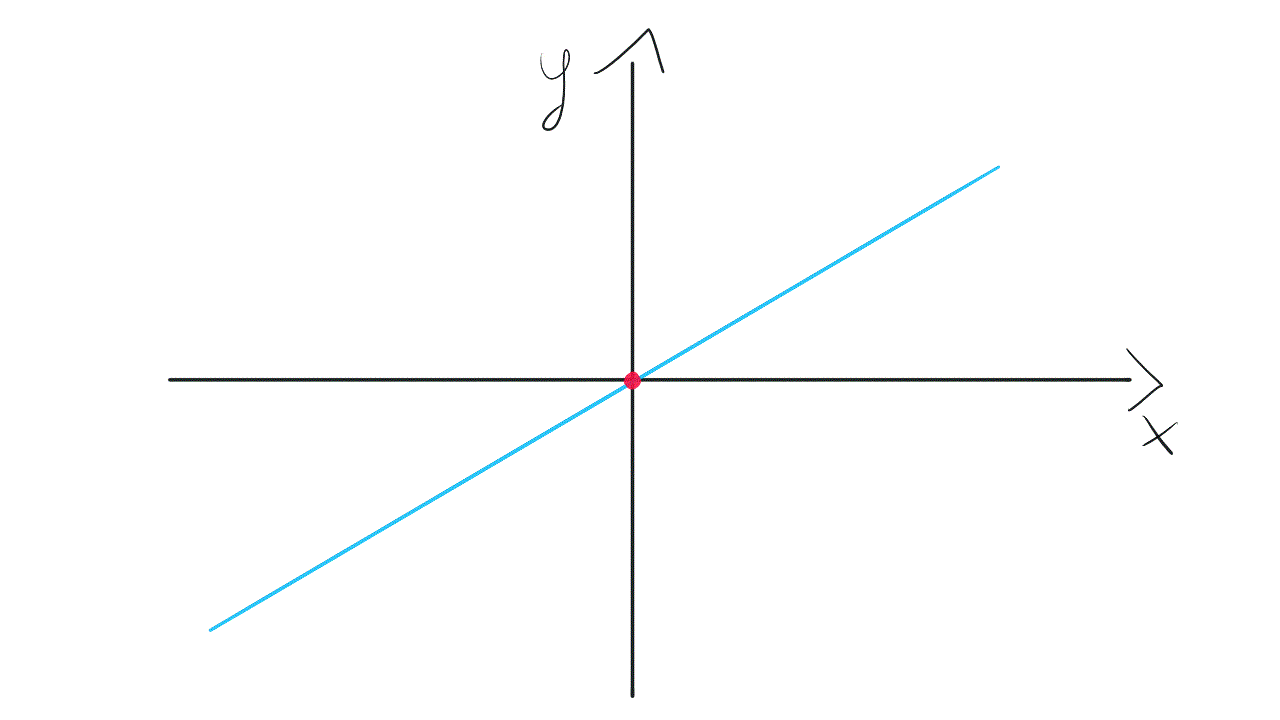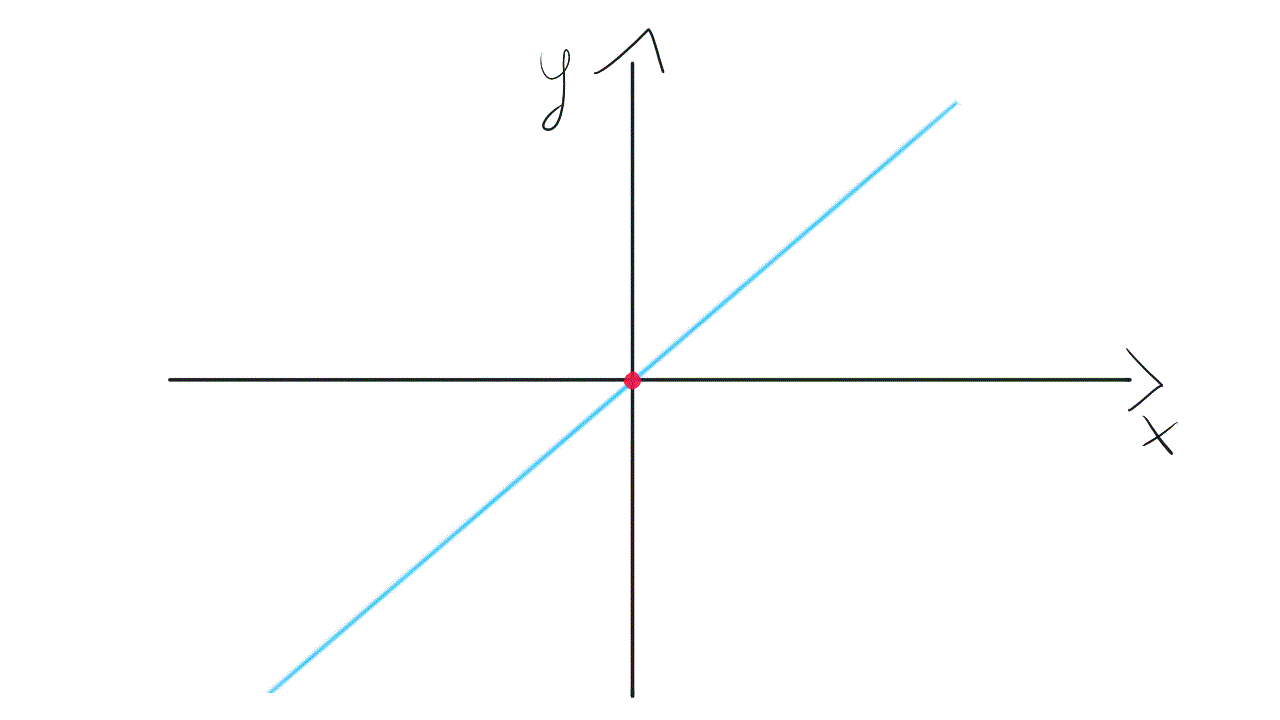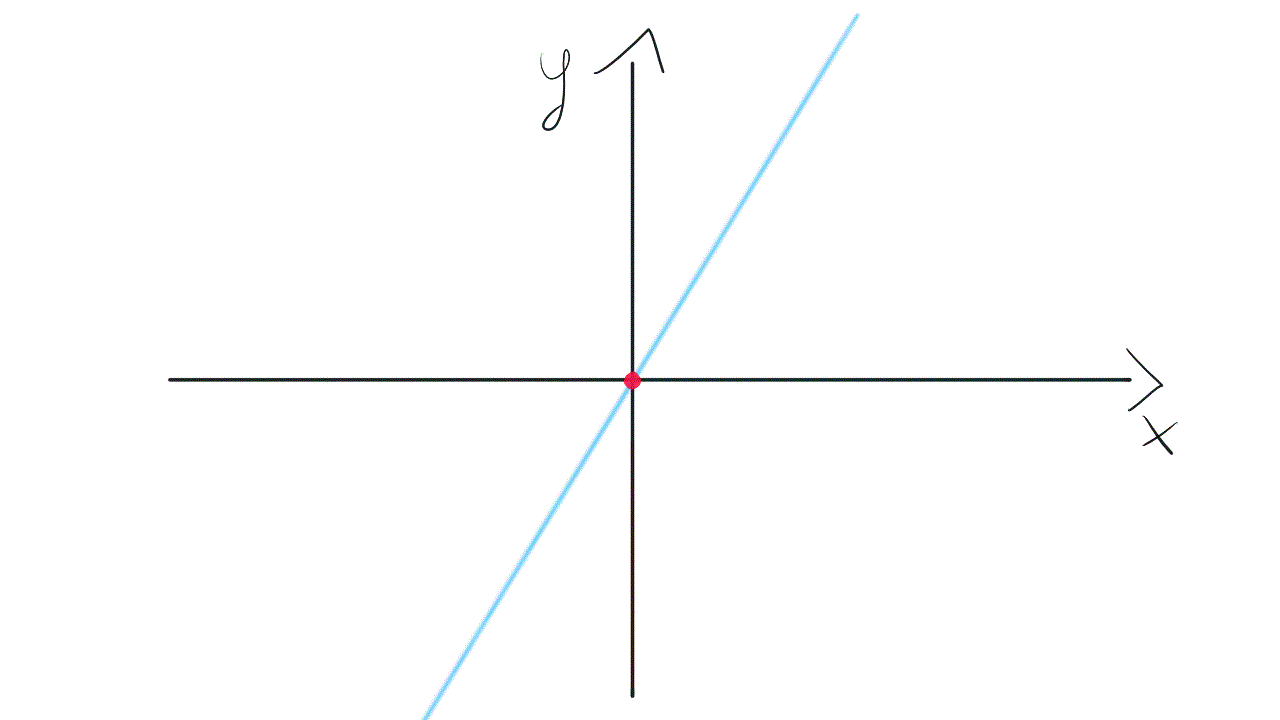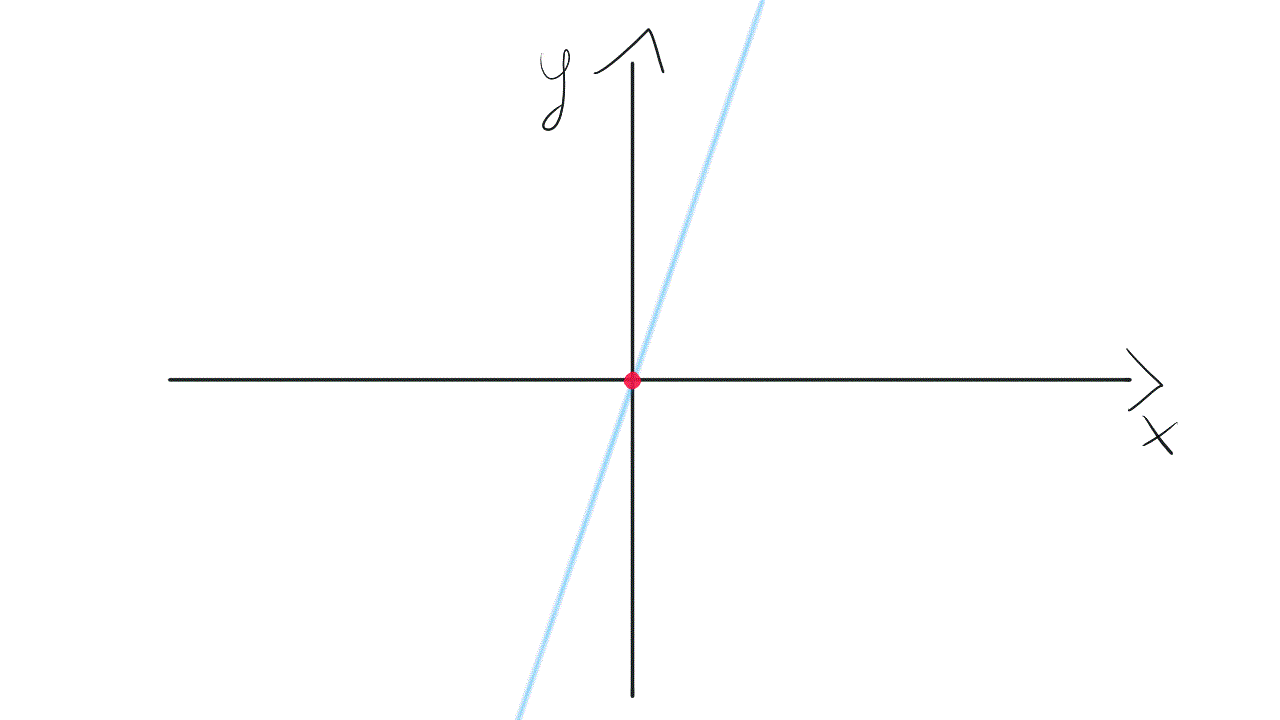
To gain more flexibility we need to get back to the original model with bias. It will equip us with weight w₀, not tied to any input. This weight allows the model to move up and down if it’s needed to fit the data.
为了获得更大的灵活性,我们需要在偏见下回到原始模型。 它将使我们获得重量w₀ ,而不受任何输入的束缚。 此权重允许模型在需要拟合数据时上下移动。
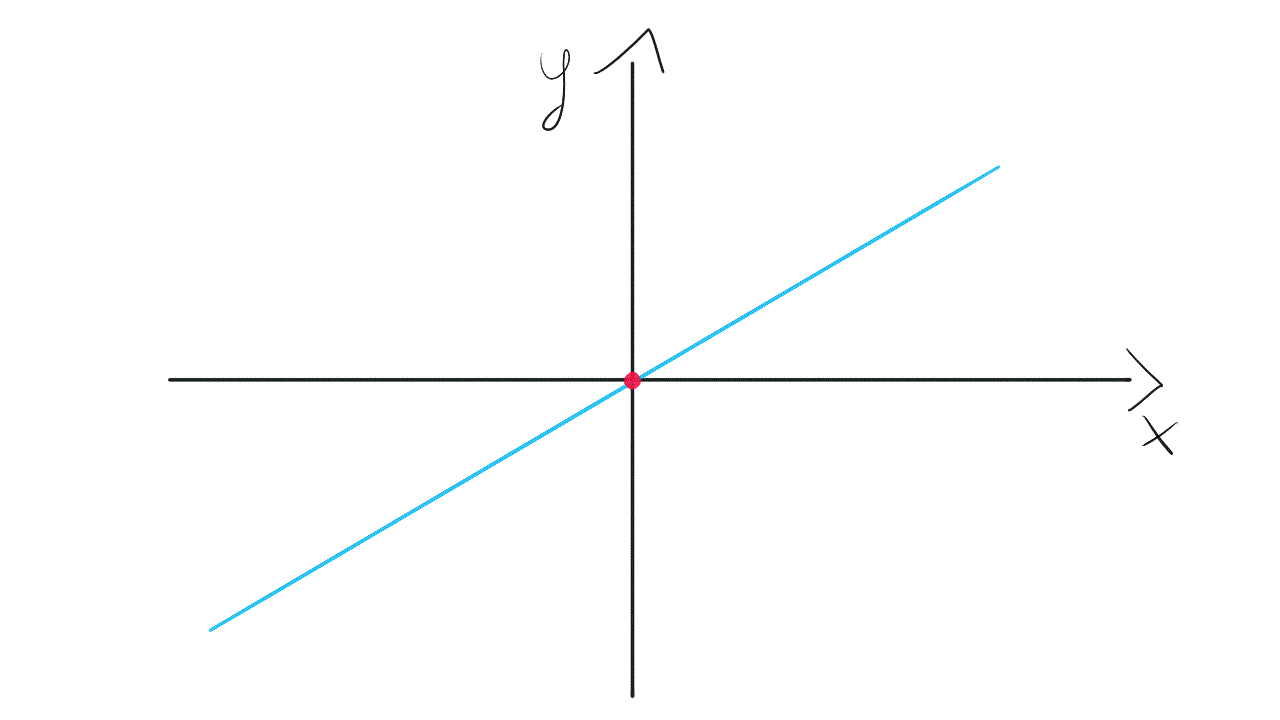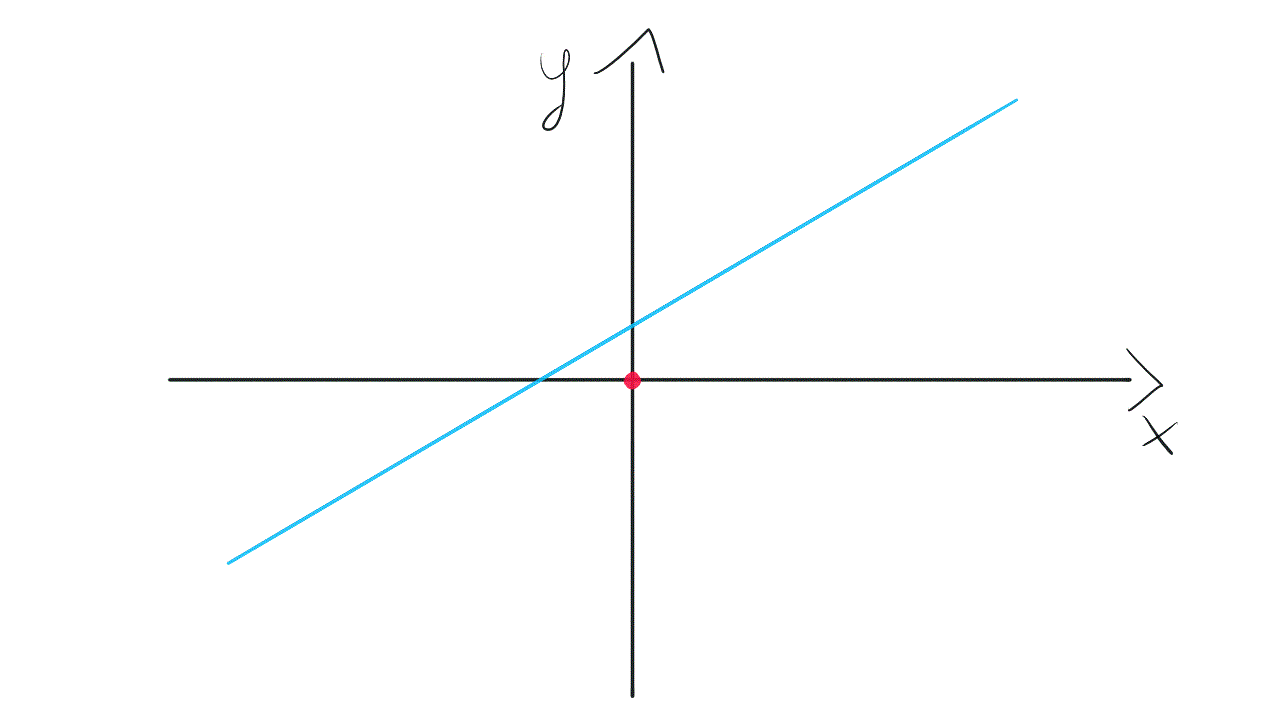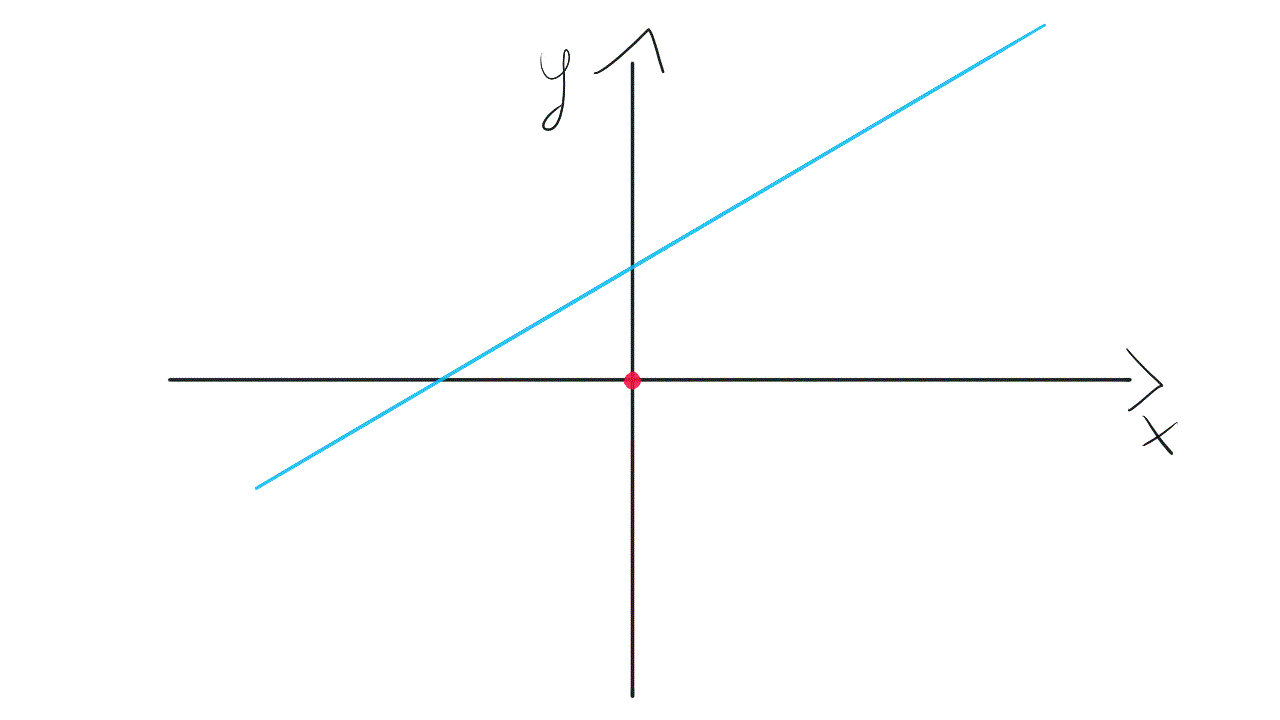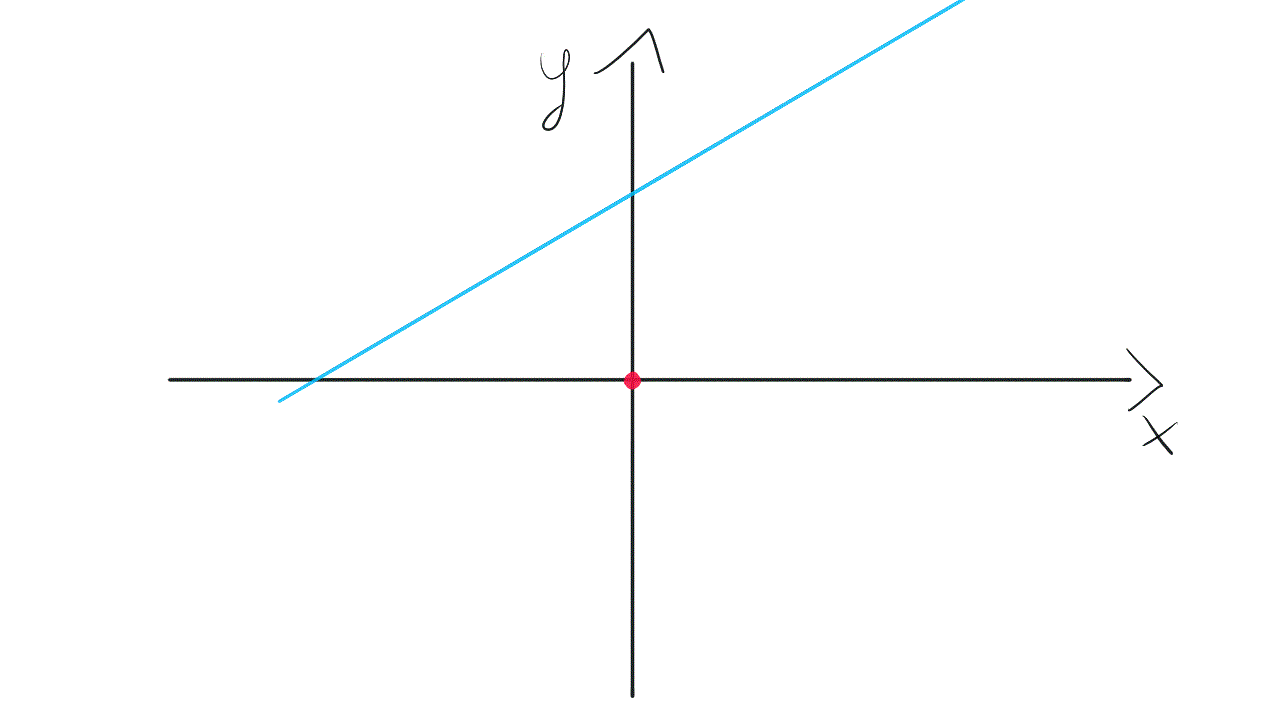
That’s the reason why we need bias neurons in neural networks. Without these spare bias weights, our model has quite limited “movement” while searching through solution space.
这就是为什么我们在神经网络中需要偏向神经元的原因。 如果没有这些多余的偏差权重,我们的模型在搜索解决方案空间时的“运动”将非常有限。
To give you one more example take a look at a neuron that uses non-linear activation function, like sigmoid:
再举一个例子,看看使用非线性激活函数(如Sigmoid)的神经元:

In this scenario bias also gives our activation function the possibility “to move”. Thanks to it, sigmoid can be shifted to the left (negative bias) or to the right (positive bias). This situation is visualized in the following diagram containing sigmoid plots for different bias values:
在这种情况下,偏见也使我们的激活函数有“移动”的可能性。 多亏了它,乙状结肠可以向左移动(负偏置)或向右移动(正偏置)。 下图显示了这种情况,其中包含针对不同偏差值的S型曲线:

第三次幸运 (Third time lucky)
Finally, after going through concepts of biased data and models with high bias, we reached the positive context of word bias. We understand why bias neurons are crucial elements of Neural Networks, but there is one last thing that raises a question. Why something with positive effects was named using a negative word such as bias?
最后,在经历了偏向数据和具有高度偏向的模型的概念之后,我们达到了词偏向的积极背景。 我们理解为什么偏向神经元是神经网络的关键要素,但是最后一件事引起了一个问题。 为什么使用消极词(例如偏见)来命名具有积极影响的事物?
That’s because bias weight is not tied to any element of input data. However, it is used to make decisions about it. So bias neuron or bias weight reflects our beliefs or prejudice about data set examples. It’s like adjusting our thoughts about someone or something using our experience instead of facts. Quite biased, isn’t it?
这是因为偏差权重与输入数据的任何元素无关。 但是,它用于做出决定。 因此,偏向神经元或偏向权重反映了我们对数据集示例的信念或偏见。 这就像利用我们的经验而不是事实来调整我们对某人或某物的想法。 颇有偏见,不是吗?
参考书目: (Bibliography:)
-
Joel Grus, Data Science from Scratch, 2nd Edition, ISBN: 978–1492041139.
Joel Grus,《 数据科学从零开始》,第二版 ,ISBN:978–1492041139。
-
Aurélien Géron, Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd edition, ISBN: 978–1492032649.
AurélienGéron, 《使用Scikit-Learn,Keras和TensorFlow进行动手机器学习:构建智能系统的概念,工具和技术》,第二版, ISBN:978–1492032649。
翻译自: https://towardsdatascience.com/why-we-need-bias-in-neural-networks-db8f7e07cb98
算法偏见是什么






 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)