
神经网络实验——从搭建环境开始建全连接网络,进行手写数字识别
在本实验中,我们将使用全连接神经网络来训练一个手写数字识别模型,以识别0到9之间的数字。我们将使用经典的MNIST数据集,该数据集包含了大量的手写数字图像,作为我们的训练和测试数据。通过对这些数据进行训练,我们的目标是建立一个准确识别手写数字的模型。
在本实验中,我们将使用全连接神经网络来训练一个手写数字识别模型,以识别0到9之间的数字。我们将使用经典的MNIST数据集,该数据集包含了大量的手写数字图像,作为我们的训练和测试数据。通过对这些数据进行训练,我们的目标是建立一个准确识别手写数字的模型。
一、全连接网络与MNIST
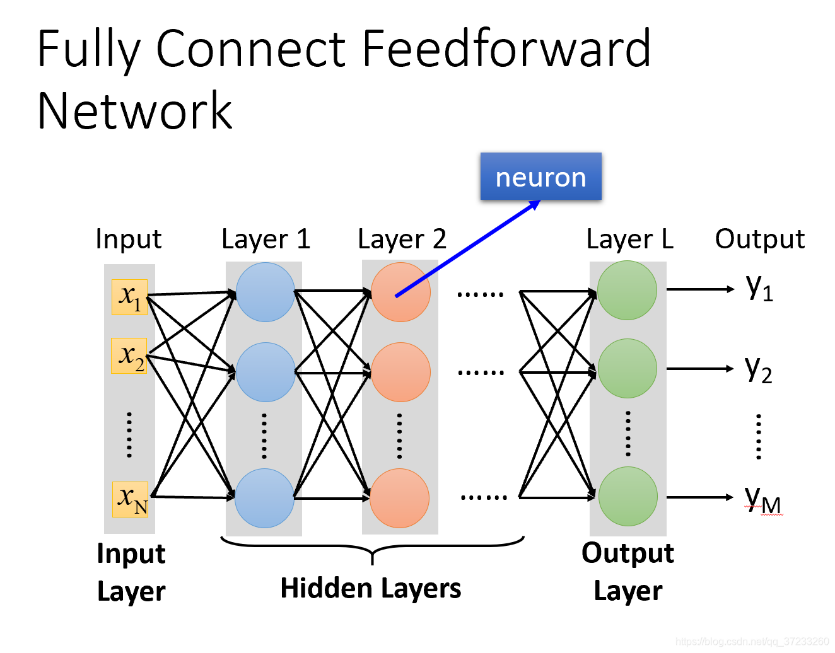
图1 全连接网路结构
全连接网络(Fully Connected Networks),也称为密集连接网络或多层感知器(Multilayer Perceptrons,MLP),是深度学习中最基础和最常用的神经网络结构之一。它由输入层、多个隐藏层和输出层组成,每一层中的神经元与前一层中的每个神经元都有连接,因此称为“全连接”。
图1 全连接网路结构

图2 手写数据集样本
手写数据集是一类常用于机器学习和深度学习领域的经典数据集之一,用于训练和测试模型对手写数字进行识别。这些数据集通常包含大量的手写数字图像及其对应的标签,标签表示每张图像所代表的数字。
二、实验准备
2.1 硬件准备
计算机配有ADM Ryzen 7 5800H CPU、Geforce RTX 3060显卡和16 GB内存,采用PyTorch 2.10深度学习框架。
2.2 环境搭建
搭建conda虚拟环境,采用PyTorch 2.10深度学习框架。(需要在虚拟环境里下载torch、cv、cuda等,这里已经安装好了直接选择conda环境)
添加图片注释,不超过 140 字(可选)
图3 conda环境搭建
三、实验步骤(代码详解)
3.1 数据集准备
本实验中,我们将使用MNIST数据集,它包含了大量的手写数字图像。每个图像都是28x28像素的灰度图像,标签为0到9的数字。
transform 参数指定了在加载 MNIST 测试数据集时要应用的转换操作。
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5,), (0.5,)) # 归一化图像数据
])
DataLoader创建了一个用于训练的数据加载器
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)3.2 建立训练模型
在__init__方法中,我们定义了三个全连接层:self.fc1、self.fc2和self.fc3。其中,self.fc1连接输入层和第一个隐藏层,self.fc2连接第一个隐藏层和第二个隐藏层,self.fc3连接第二个隐藏层和输出层。
在forward方法中,我们首先将输入的图像数据展平成一维向量,然后经过第一个隐藏层和第二个隐藏层,使用ReLU作为激活函数,最后经过输出层,不使用激活函数,得到模型的输出。
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28 * 28, 512)
self.fc2 = nn.Linear(512, 256) # 添加一个隐藏层
self.fc3 = nn.Linear(256, 10) # 输出层的大小改为10
def forward(self, x):
x = x.view(-1, 28 * 28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x)) # 添加ReLU激活函数
x = self.fc3(x)
return x3.3 训练模型
步骤:1、将模型的梯度清零,以避免梯度积累。
2、对每个批次进行前向传播,计算损失,并进行反向传播。
3、使用优化器更新模型参数。
4、统计每个批次的训练精度,并计算整个训练集的平均精度。
5、打印每个训练周期的训练精度。
def train_model(model, train_loader, criterion, optimizer, num_epochs=5):
for epoch in range(num_epochs):
correct = 0
total = 0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad() # 梯度清零
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
train_accuracy = 100 * correct / total
train_accuracy_history.append(train_accuracy)
print(f'Epoch [{epoch + 1}/{num_epochs}], Training Accuracy: {train_accuracy:.2f}%')四、训练结果
在训练过程中,我们采用了Adam优化器和交叉熵损失函数,同时对输入数据进行了归一化处理。通过在训练集上进行了10个epoch的训练,我们获得了一个在测试集上表现良好的模型,其测试精度达到了97%。同时,我们还绘制了训练精度随epoch变化的曲线,可以观察到随着训练的进行,模型的训练精度逐渐提高,表现出良好的收敛性能。
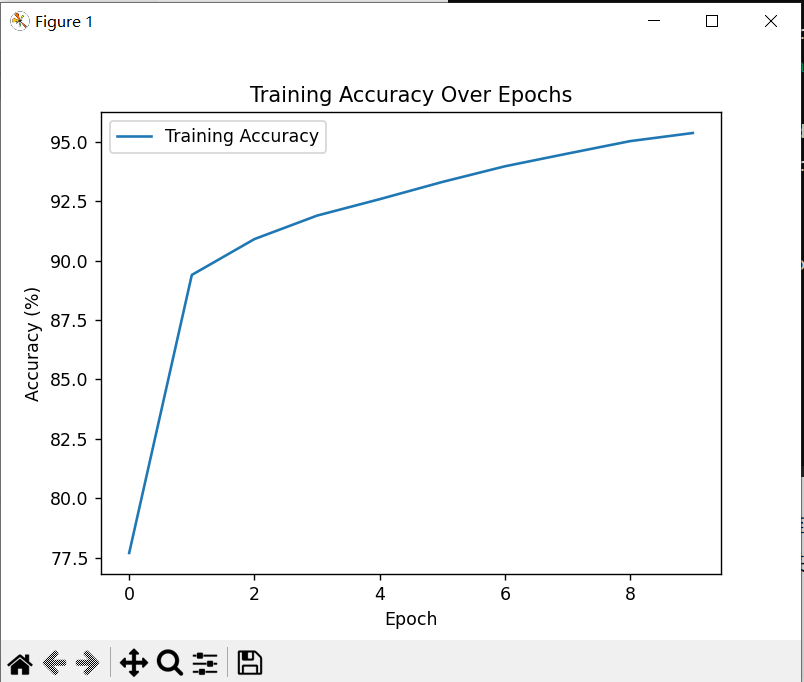
图4 训练结果
从数据集中选择图片,在训练的数据集中进行测试,模型能够准确的识别出手写数字图片

图5 测试结果
五、结论
本实验验证了全连接网络在手写数字识别任务中的有效性。通过适当调整网络结构和训练参数,我们可以获得较高的识别准确率。然而,全连接网络也存在一些局限性,例如在处理大规模数据时可能出现过拟合的问题。因此,在实际应用中,我们需要综合考虑模型的复杂度和性能,选择合适的网络结构和训练策略。
下附全部代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# 定义数据预处理的转换
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5,), (0.5,)) # 归一化图像数据
])
# 加载 MNIST 数据集
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
# 定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 实例化模型
model = Net()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(5): # 遍历数据集多次
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad() # 梯度清零
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
running_loss += loss.item()
if i % 100 == 99: # 每 100 个 mini-batch 输出一次信息
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
print('Finished Training')
# 在测试集上评估模型
correct = 0
total = 0
with torch.no_grad(): # 禁用梯度计算
for data in test_loader:
inputs, labels = data
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test images: %d %%' % (100 * correct / total))
# 打印模型架构
print(model)
import matplotlib.pyplot as plt
# 选择几张图像进行验证
num_images_to_validate = 5
images_to_validate = []
labels_to_validate = []
for i in range(num_images_to_validate):
image, label = test_dataset[i]
images_to_validate.append(image)
labels_to_validate.append(label)
# 将图像和标签组成一个小批次
images_to_validate = torch.stack(images_to_validate)
labels_to_validate = torch.tensor(labels_to_validate)
# 使用模型进行预测
with torch.no_grad():
model.eval()
outputs = model(images_to_validate)
_, predicted = torch.max(outputs, 1)
# 可视化选定图像及其预测结果
fig, axes = plt.subplots(1, num_images_to_validate, figsize=(12, 3))
for i in range(num_images_to_validate):
axes[i].imshow(images_to_validate[i].squeeze(), cmap='gray')
axes[i].set_title(f'Predicted: {predicted[i].item()}\nActual: {labels_to_validate[i].item()}')
axes[i].axis('off')
plt.show()
技术共进,成长同行——讯飞AI开发者社区
更多推荐
 33
33 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)