
【目标检测·yolo系列】YOLOV2目标检测论文笔记(参考 同济子豪兄的解读)
目录anchor 、 Dimension Clusters 、Direct location prediction在YOLOv2中规定了五种anchor,grid cell数量为奇数限制预测框位置损失函数细粒度特征Multi-Scale Traininganchor 、 Dimension Clusters 、Direct location prediction在YOLOv1中先验框是随机的,在Y
目录
anchor 、 Dimension Clusters 、Direct location prediction
在YOLOv1中先验框是随机的,在YOLOv2中规定了两个先验框,如下图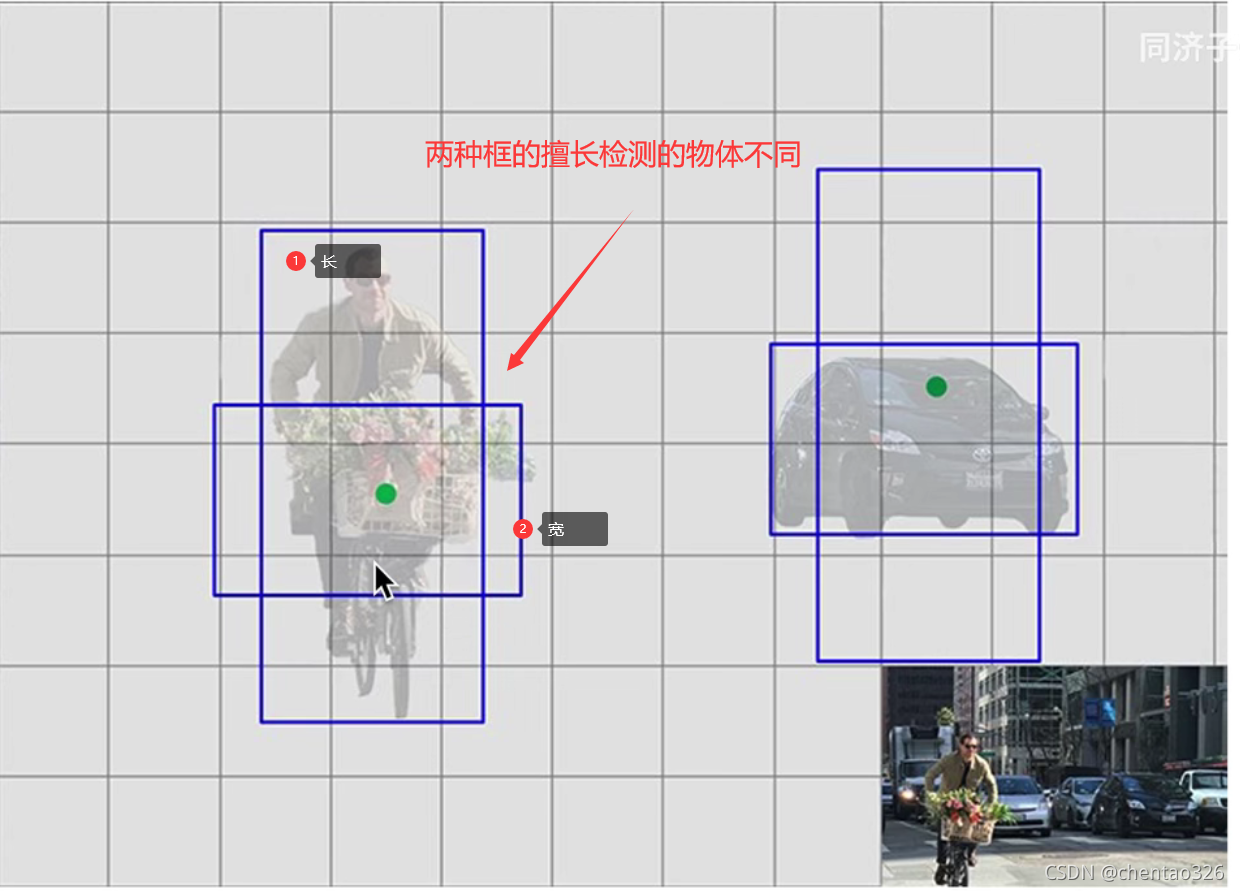
如图,①框擅长套高瘦长的物体,②框擅长矮胖宽的物体
由此可以使得模型稳定
在YOLOv2中规定了五种anchor,
并把图片分成了13*13个grid cell,每个grid cell预测5种anchor,每一种anchor对应了一种预测框,每一个预测框只需要输出他相对于其anchor的偏移量。
如下图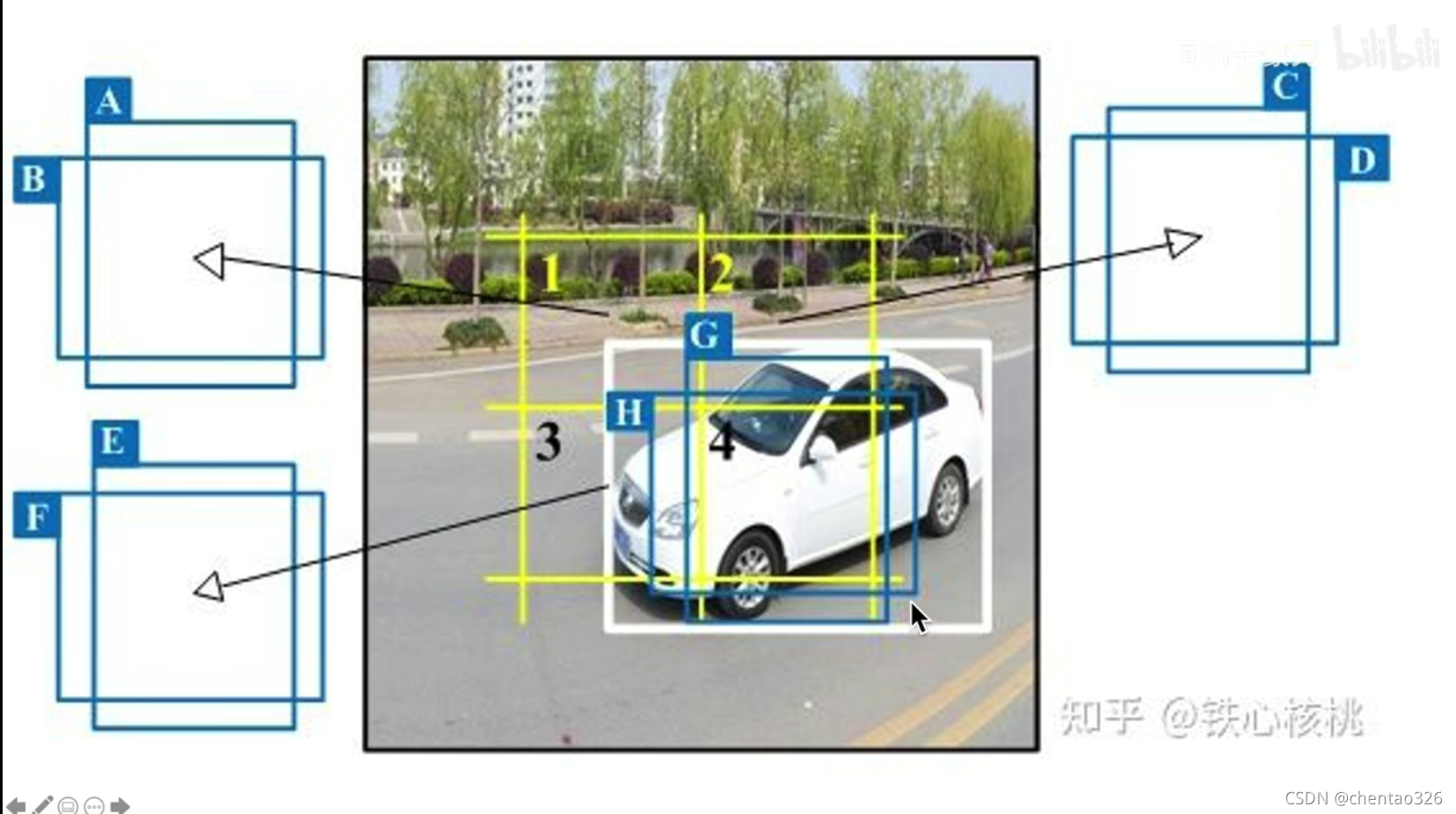
白色汽车的人工标注框(白色框)的中心位置落在了4号框中,那么就由4号框产生的五种anchor中与白框IOU最大的anchor去预测,其预测框只需要输出相比于所属anchor的偏移量即可。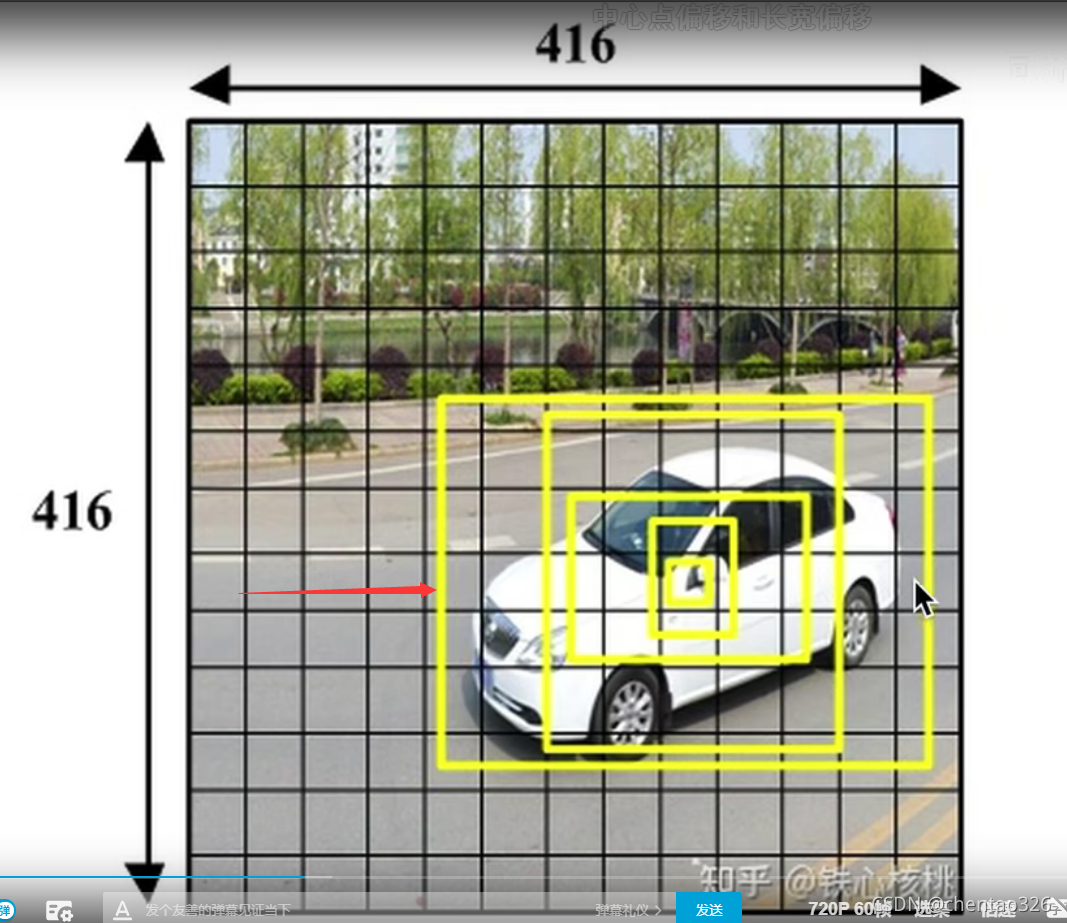
grid cell数量为奇数
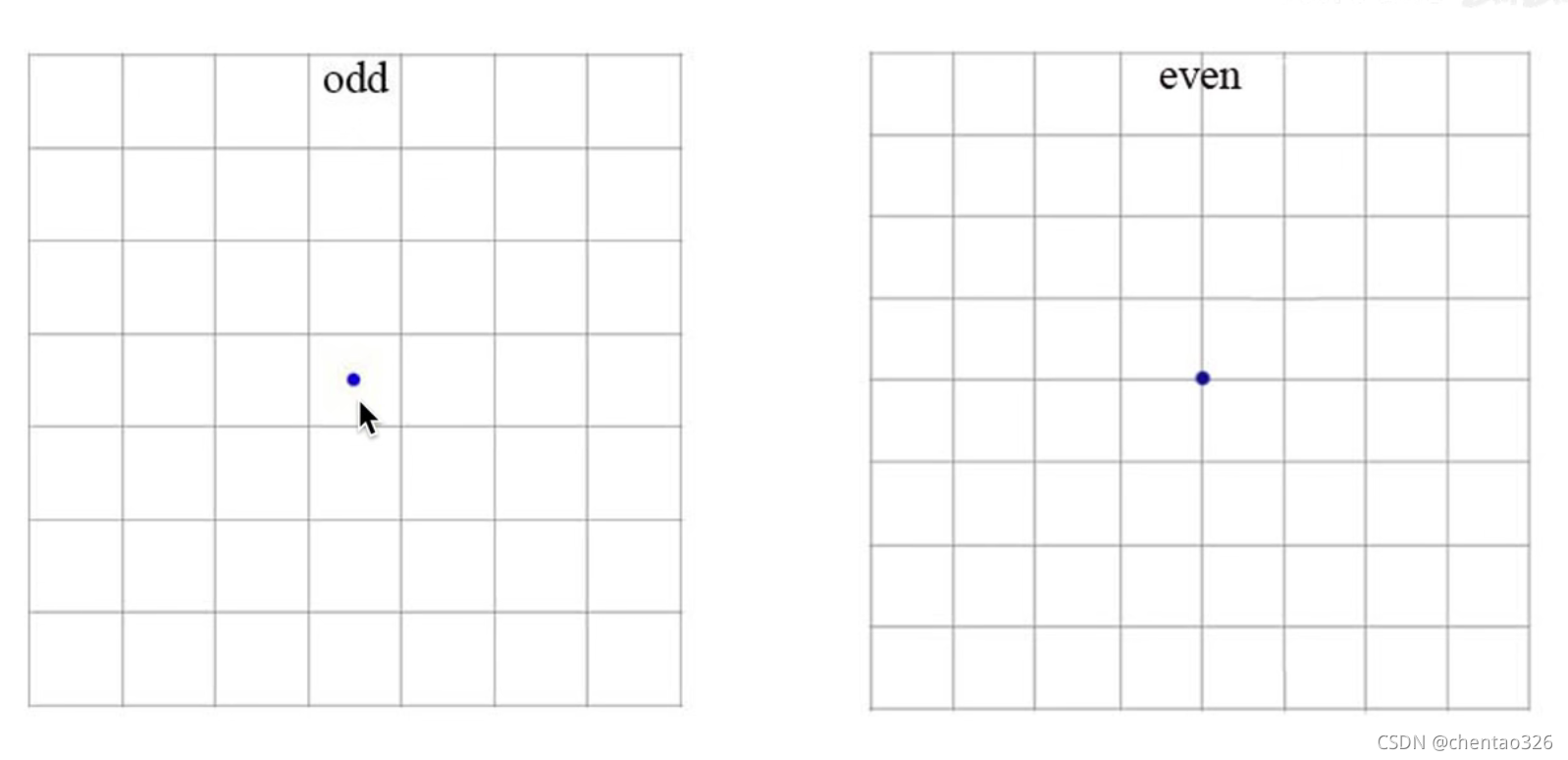
当图片存在主体的时候,一般是由中心grid cell负责,奇数时正好有中心cell存在,偶数就会落在中心点的位置上——被四个框争取。
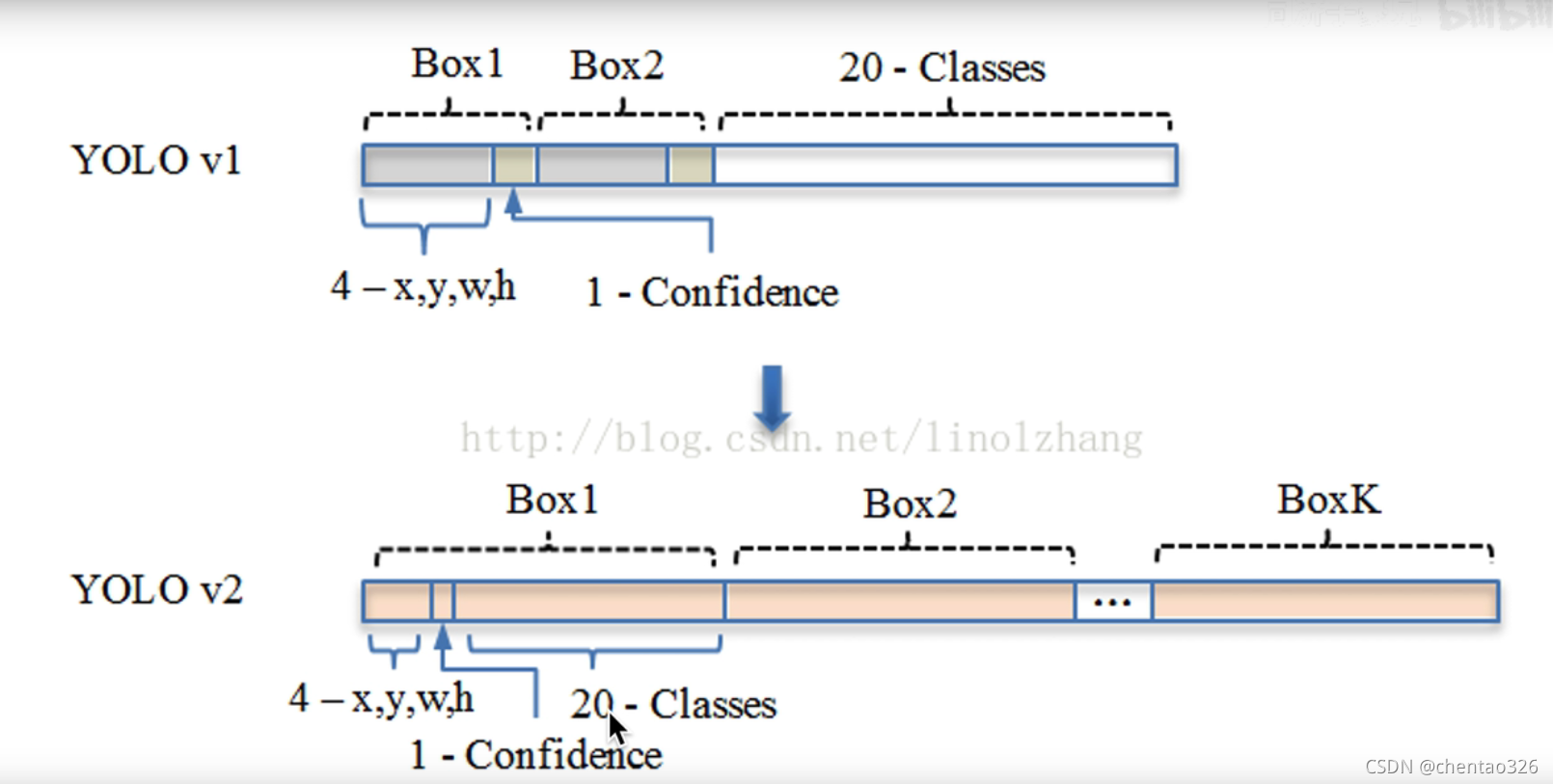
在yolo1中,一个bounding box包含4个维度+一个置信度,另外加上20个预测输出的条件类别概率,共5*2+20=30维
在YOLOv2中,条件类别概率归anchor管,一个anchor中有4个维度+1置信度+20个类别,共5个anchor,总计5*25=125维,一个grid cell有5个anchor共125维
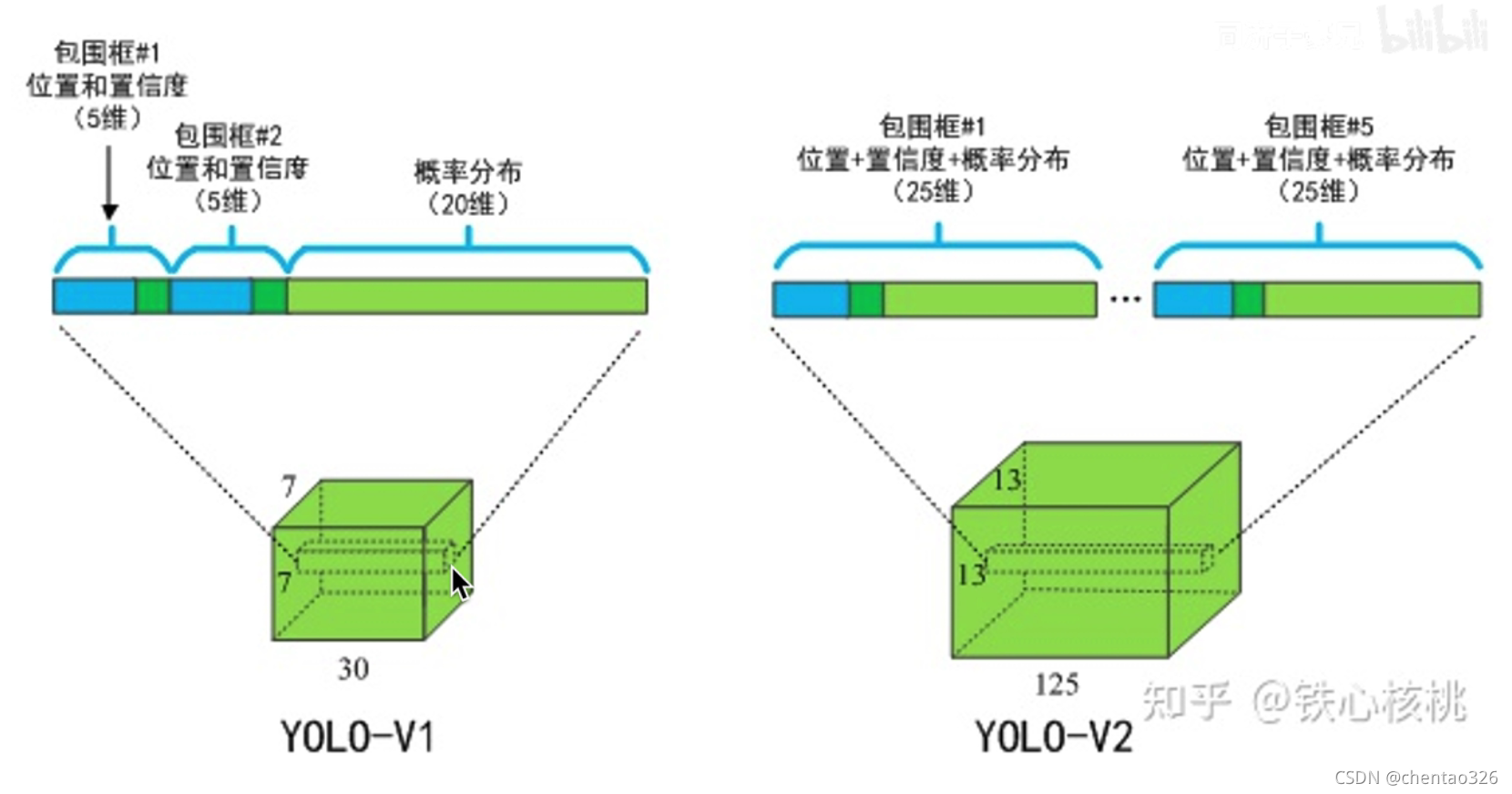
注:5个anchor通过k-means聚类选出
限制预测框位置
现对于anchor的偏移量tx ty tw th,tx,ty ∈(-∞,∞)
为了防止野蛮生长,就在tx和ty上添加sigmoid函数,使得sigmoid(tx,ty)属于(0,1) 【注】
cx和cy是左上角的坐标,已归一化。由此,预测框的中心位置不会脱离anchor所在的cell。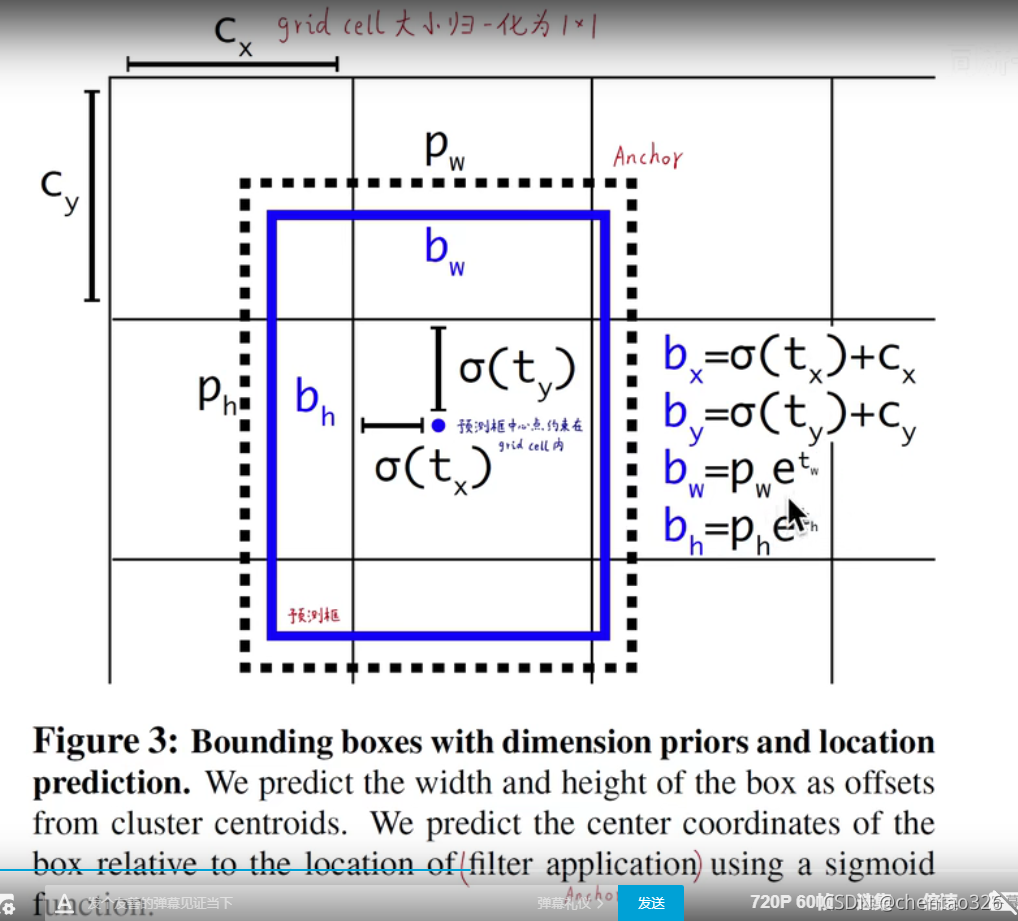
置信度: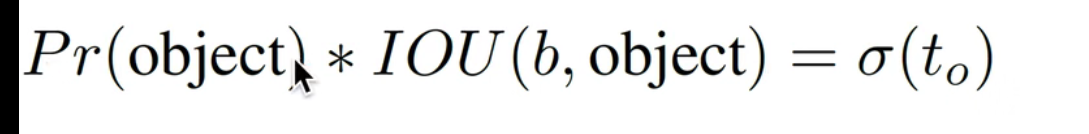
【注】:sigmoid函数: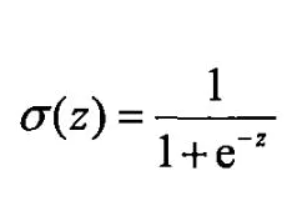
损失函数
yolov1: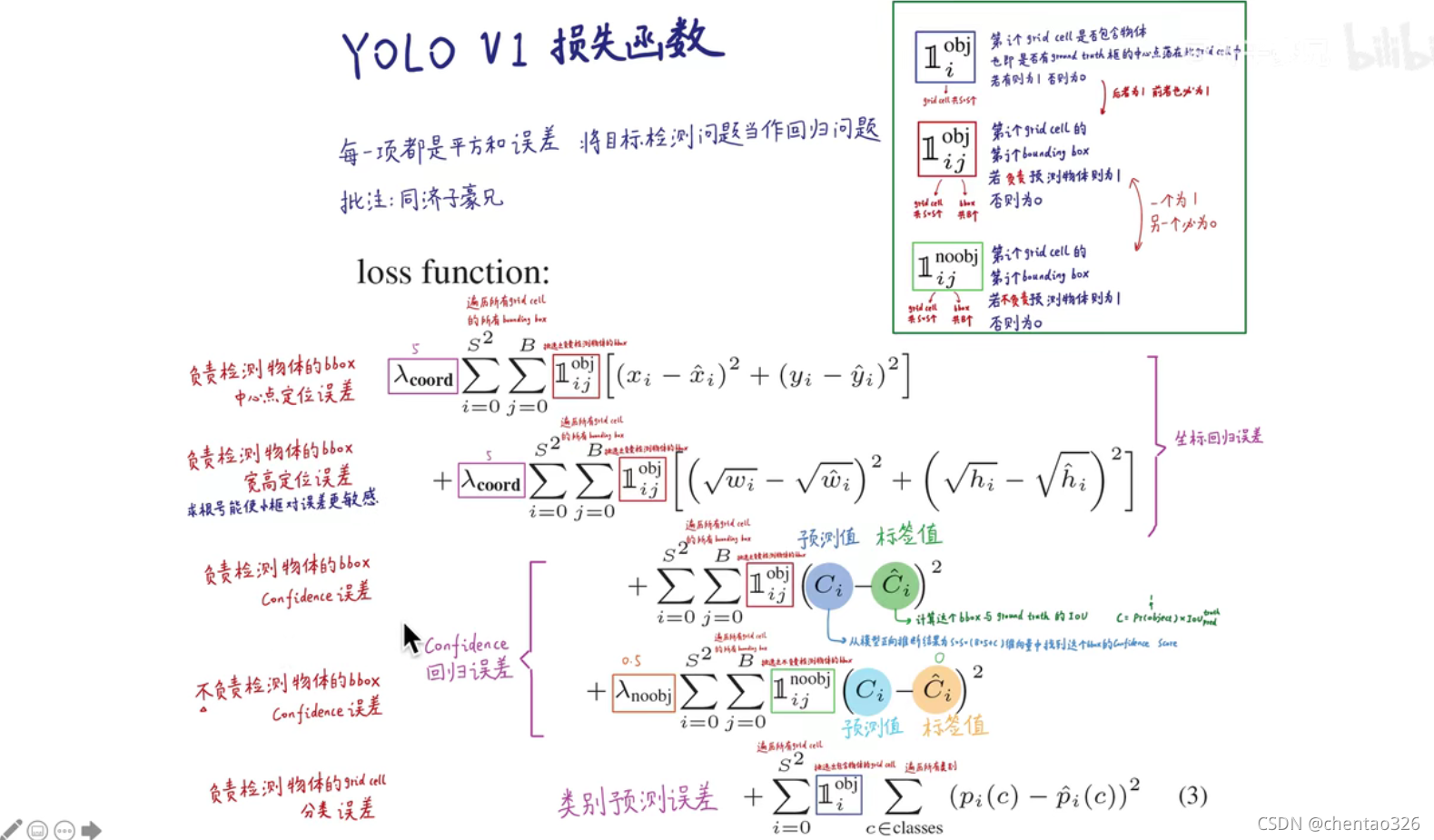
yolov2: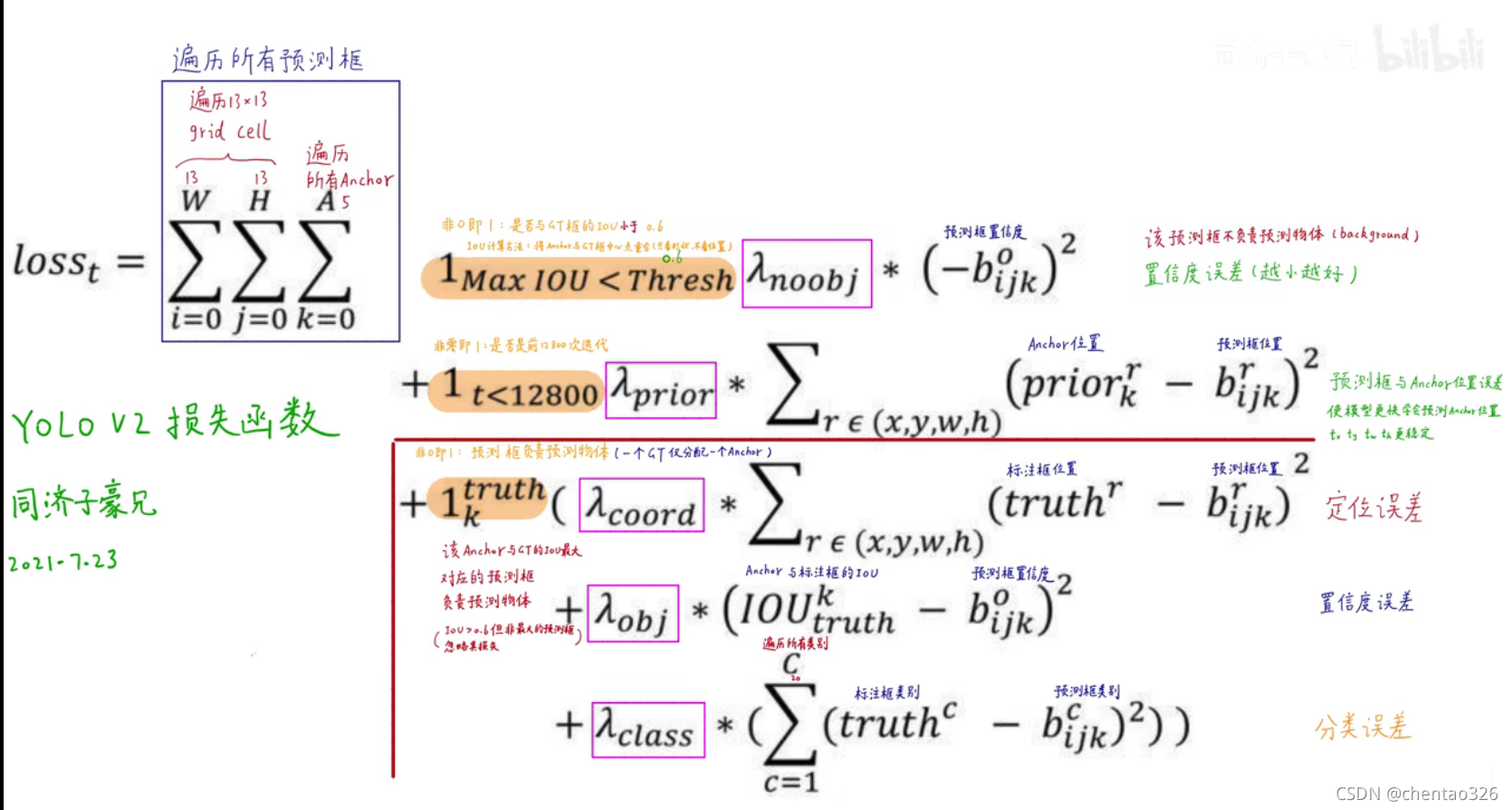
细粒度特征
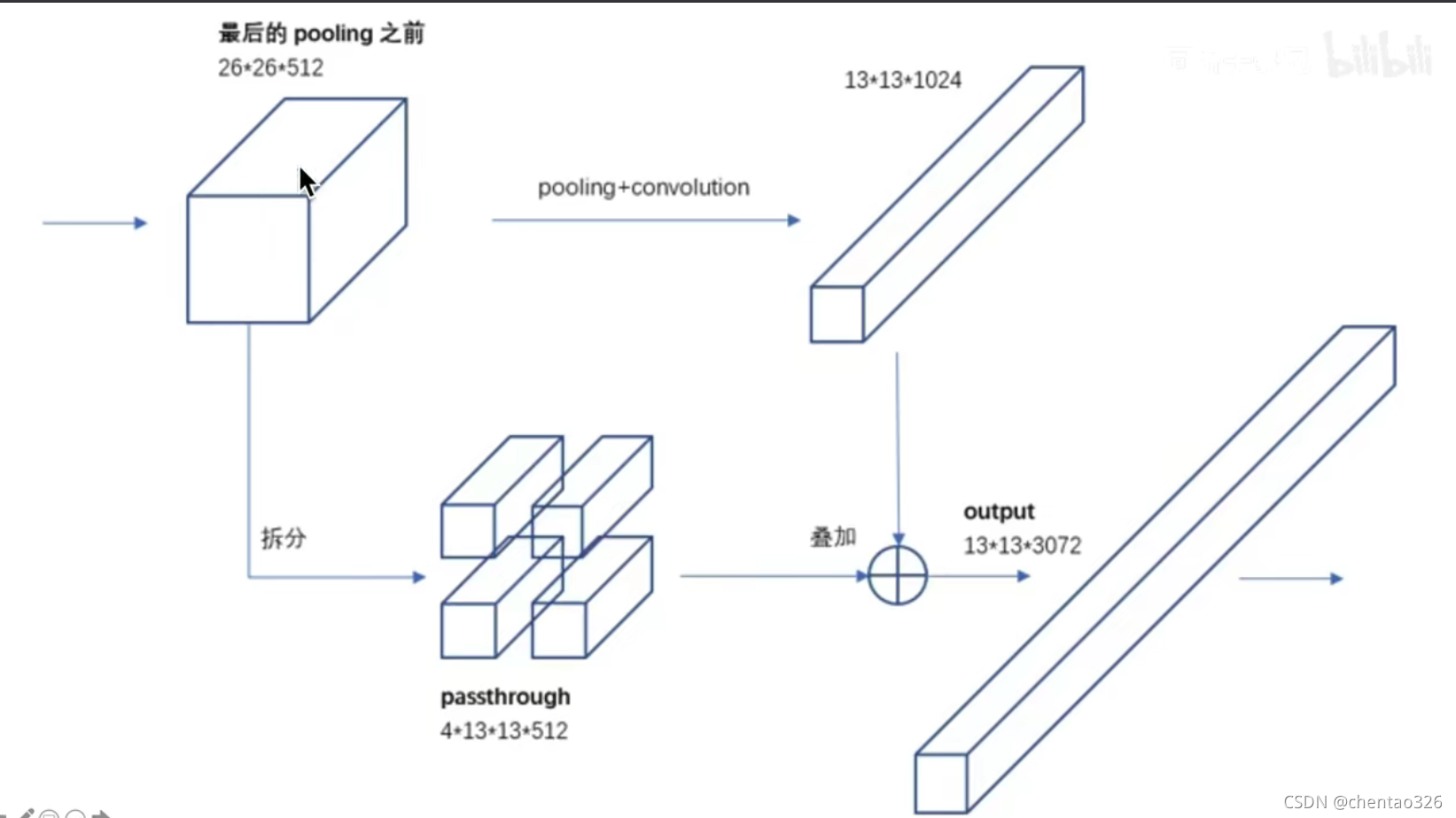
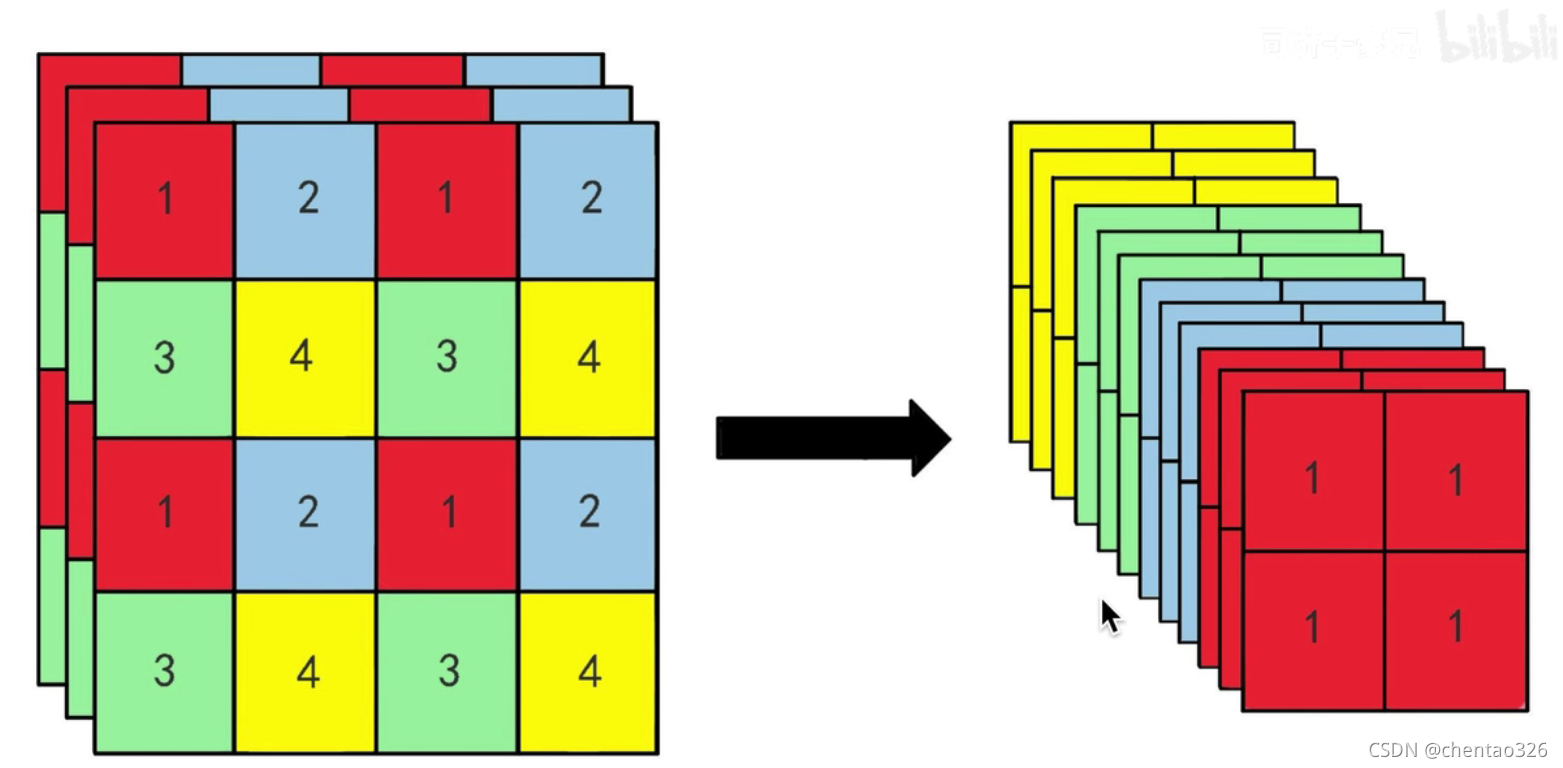
在yolo2的代码中: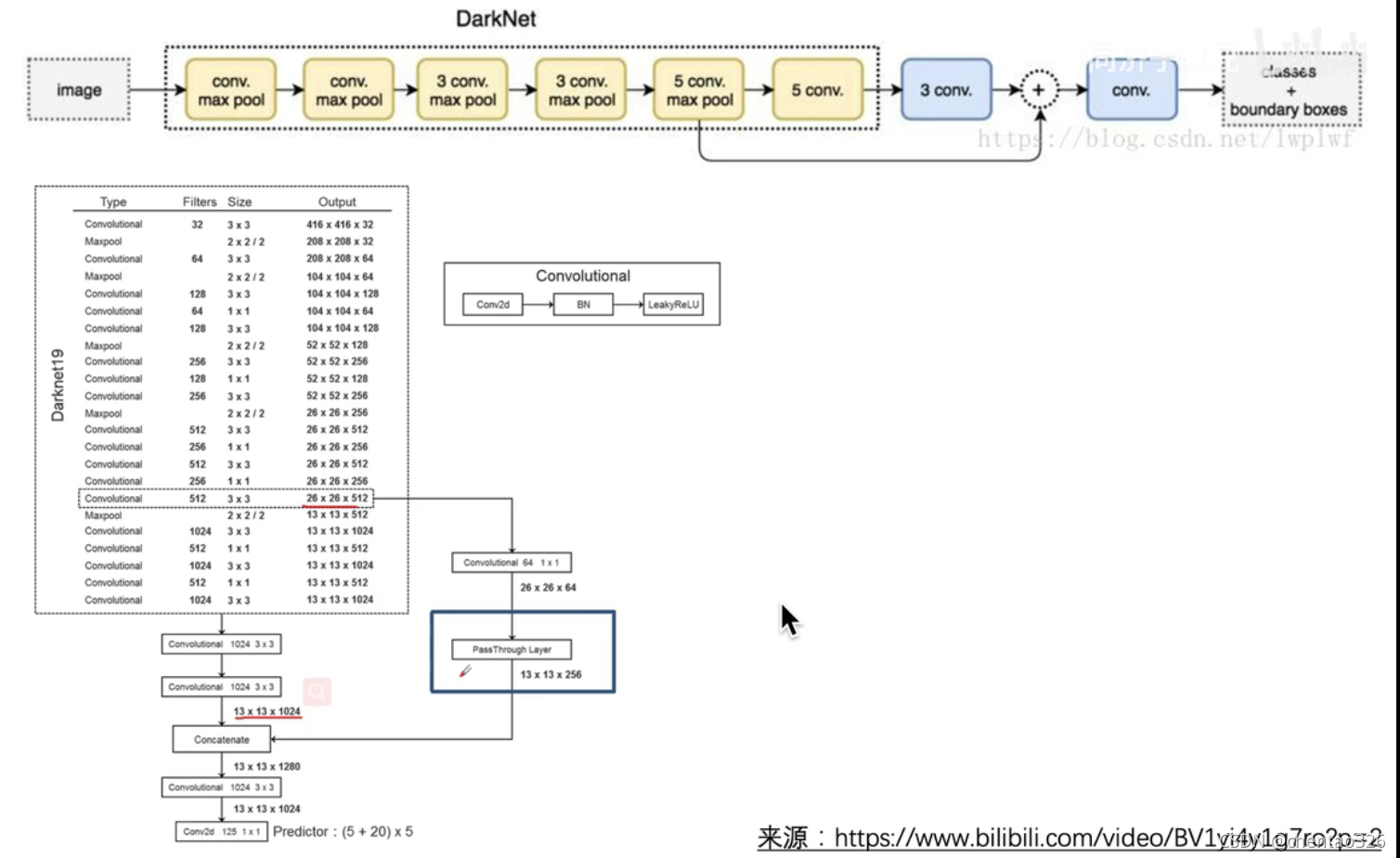
.
Multi-Scale Training
多尺度训练
每10步重新选择同图不同尺度的图像,强制模型适应不同的大小的图
低分辨率的:快、精度小;
高分辨率的:慢、精度大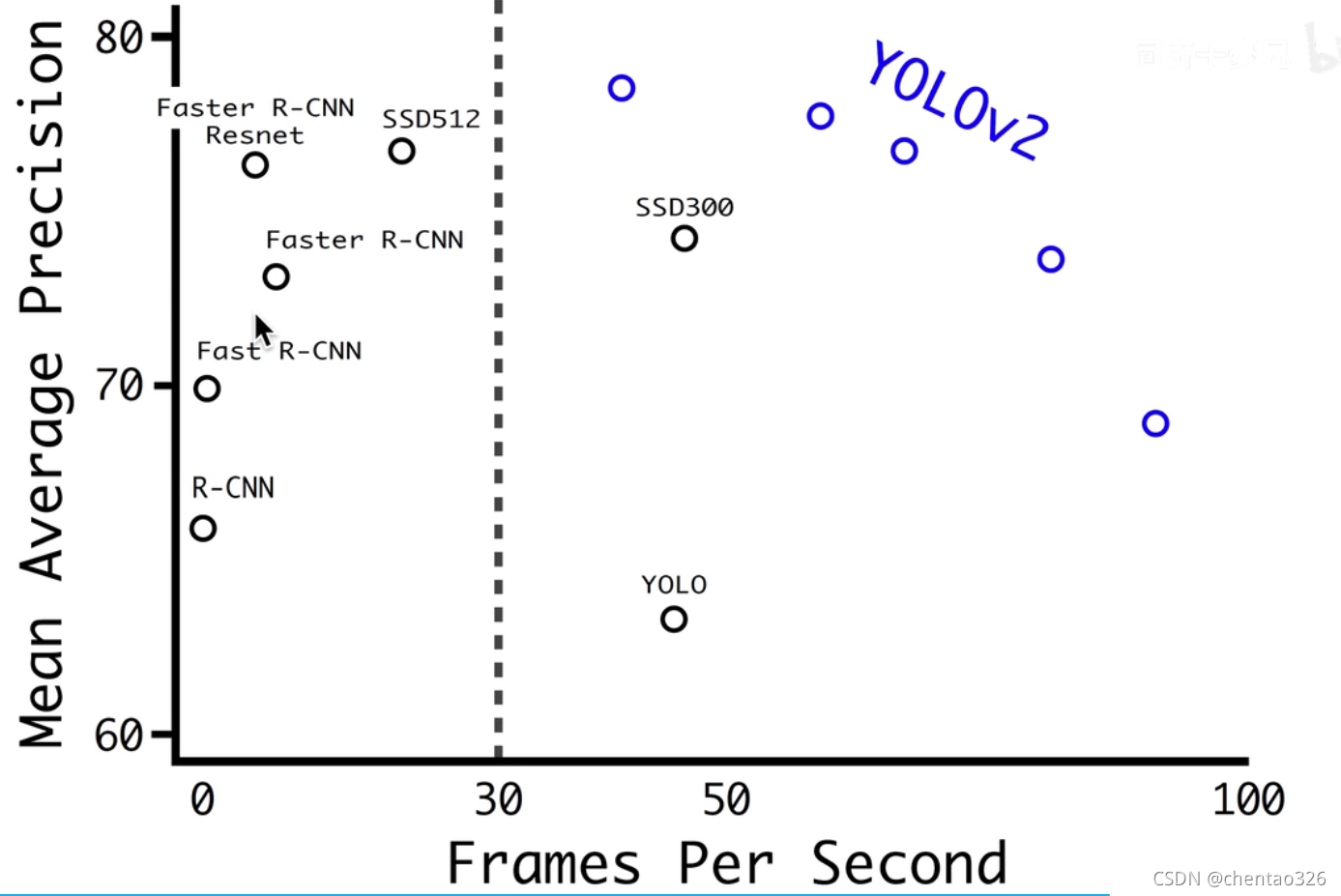

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)