
大数据计算引擎、常用组件介绍(一)包含HDFS/MAPREDUCE/YARN/HIVE
大数据计算引擎(MAPREDUCE/DAG/SPARK/FLINK/KYLIN/IMPALA)和大数据常用组件介绍(HDFS/MAPREDUCE/YARN/HIVE)
目录
一、大数据计算引擎
1、大数据计算引擎的发展历程
很多人把大数据的计算引擎分成了4 代:
第一代:批处理引擎(MapReduce)
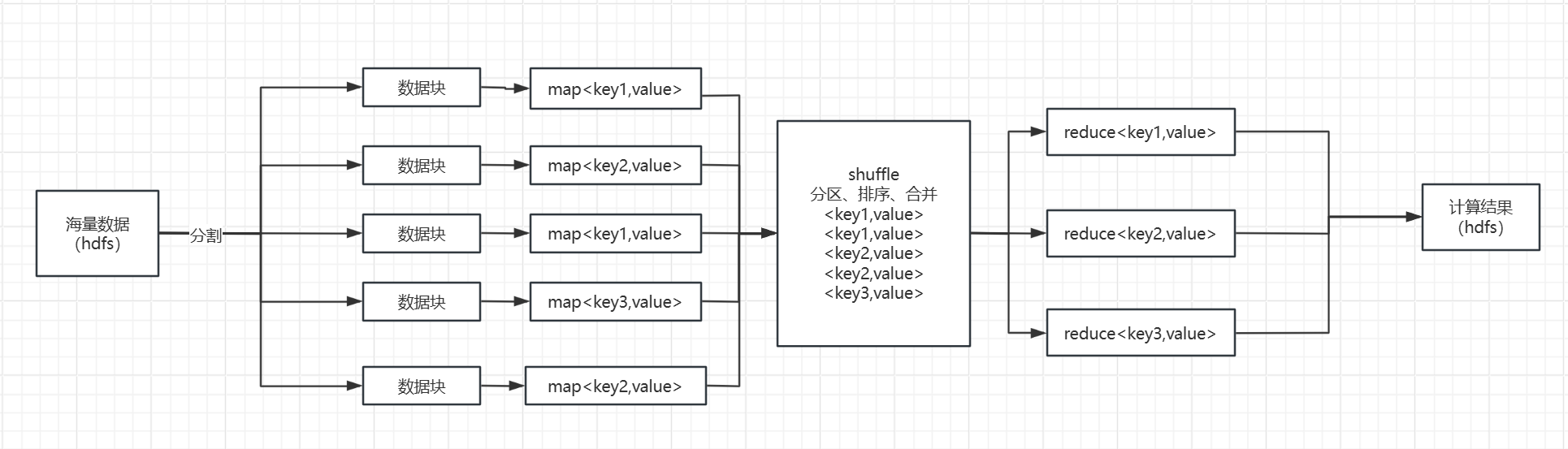
原理
数据处理过程分为Map和Reduce两个阶段
-
Map阶段:
- 输入数据被分割成多个数据块
- 每个数据块分配一个Map任务
- Map任务读取数据块中的键值对
- 调用用户自定义Map函数处理每个键值对
- 输出中间键值对到磁盘临时文件
-
Shuffle阶段(隐含阶段):
- 将Map生成的中间键值对按key进行分区、排序、合并等操作
- 为reduce阶段提供有序的输入数据。
-
Reduce阶段:
- 接收Shuffle阶段处理后的数据
- 调用用户自定义Reduce函数对每个键和一组相关的值进行处理(如聚合处理),生成一组输出键值对
- 这些输出键值对被写入到最终的输出文件中(hdfs)
局限性
频繁的磁盘I/O操作(如WordCount需要多次读写磁盘)容易形成性能瓶颈;
由于复杂算法需要串联多个Job执行,导致任务调度效率降低;
仅支持批处理模式,难以满足实时计算需求。
Join操作的两种方式
在MapReduce中实现Join操作主要有两种核心方式:Reduce Side Join(Reduce端Join) 和Map Side Join(Map端Join)。
Reduce Side Join(适用于大多数Join场景):
- Map阶段:每个Map任务读取一个数据集,并将数据转换成键值对形式输出。键通常是Join的依据(公共字段),值包含所有其他字段。不同数据集的记录需要被打上标记,以便在Reduce阶段区分它们的来源。
- Shuffle阶段:根据Map阶段输出的键(即Join键)对数据进行分区和排序。
- Reduce阶段:Reduce任务接收来自不同数据集、但拥有相同Join键的所有记录。在Reduce方法中,可以访问到所有匹配的记录,并执行Join逻辑,将它们合并成所需的输出格式。
Map Side Join(适用于跟小表join):
这种方式适用于一个小数据集可以完全装入内存的情况。它尝试在Map阶段就完成尽可能多 的关联工作,以减少Reduce阶段的压力。
- 使用DistributedCache将较小的数据集(通常称为“查找表”)预加载到所有Map任务的内存中。
- Map任务在处理大数据集的同时,可以在本地内存中查找小数据集的匹配项,直接在Map输出中完成Join操作。这样,输出的键值对已经是Join后的结果。
第二代:DAG调度引擎(Tez/Oozie)
(这个没有用过,了解不多,全靠AI编写)
-
原理:
引入有向无环图(DAG) 描述任务依赖关系,将多Job串联优化为单Job内的细粒度任务组合。例如Tez将Map拆分为Input、Processor、Sort等子步骤,减少冗余I/O。 -
突破:
-
任务调度效率提升(Hive on Tez比MR快100倍);
-
支持复杂工作流(如Oozie控制流节点)。
-
-
局限:
仍基于磁盘计算,未解决单任务执行效率问题。
第三代:内存计算引擎(Spark)
Spark是内存计算优先:通过内存缓存中间数据,减少磁盘 I/O,速度比 Hadoop MapReduce 快 10–100 倍
-
原理:
-
弹性分布式数据集(RDD):RDD 是 Spark 的底层数据结构,数据抽象为内存驻留的不可变集合,通过转换算子(如map/filter)生成新RDD,行动算子(如collect)触发计算;
-
DAG(有向无环图)调度器:将操作符按依赖关系划分为Stage,窄依赖(无Shuffle)合并执行,宽依赖(需Shuffle)分Stage;
-
微批流处理:Spark Streaming将流数据切分为小批次(如1秒窗口),转为RDD处理。
-
-
突破:
-
内存计算比磁盘I/O快100倍;
-
支持流、批、SQL、机器学习统一引擎。
-
-
局限:
-
微批处理导致流计算延迟较高(>100ms);
-
内存管理不足易OOM(全内存依赖)。
-
第四代:流批一体引擎(Flink)
Flink 是目前开源社区中唯一一套集高吞吐、低延迟、高性能三者于一身的分布式流式数据处理框架,也可以支持 Batch 的任务,以及 DAG 的运算。
批处理、流处理、SQL高层API支持自带DAG流式计算性能更高、可靠性更高。
原理
-
流处理优先:所有数据视为无界流,批处理作为有界流;
-
事件驱动:数据到达立即处理(非微批),节点间实时流水线传输,实现毫秒级延迟;
-
状态管理:内置托管状态(如窗口聚合中间值),支持精确一次(Exactly-Once) 语义。
技术架构
Flink 运行时由两类进程组成:
- JobManager
- 负责作业调度、Checkpoint 协调及故障恢复(类似 Storm 的 Nimbus)。
- TaskManager
- 执行具体任务,通过 Slot(计算槽位)分配资源,支持横向扩展至数千核心。
DataStream &SQL API
DataStream API 是一种过程式编程接口,提供了较低层次的流处理原语,如时间管理、状态管理和数据流操作。它支持 Java 和 Scala 语言,允许用户编写复杂的流处理逻辑。
SQL API是一种声明式编程接口,允许用户使用标准的 SQL 语言来处理流数据和批数据。它将数据抽象为表(Table),并支持常见的 SQL 操作,如 SELECT、JOIN、GROUP BY 等。
主要包括以下两个部分:
-
Flink SQL:这是 Flink 提供的 SQL 语言,允许用户使用标准的 SQL 语法来定义数据处理逻辑。它是 SQL API 的核心部分,支持流处理和批处理。
-
Table API:这是基于 Java/Scala 的编程接口,提供了类似 SQL 的操作,但以编程语言的形式实现。它提供了类型安全和编程灵活性,是 SQL API 的补充。
编码步骤/模型
- env-准备环境
- source-加载数据
- transformation-数据处理转换
- sink-数据输出
- execute-执行
四大基石
时间(Time)
时间是 Flink 中用于处理事件的关键概念,支持三种时间语义:
-
事件时间(Event Time):事件实际发生的时间,通常存储在事件数据中。它能够处理乱序数据和延迟数据。
Watermark:是一种特殊的标记,用于表示事件时间的进度,触发窗口计算,处理乱序 数据和延迟数据
Event Time&Watermark:比如Event Time是开单时间create_time Watermark设置:WATERMARK FOR create_time AS create_time - INTERVAL '5' SECOND" 表示允许数据延迟5秒到达,窗口计算时,仅处理水位线之前的数据(如 12:00:05水位线到达后,12:00:00窗口才会触发)
-
处理时间(Processing Time):数据到达 Flink 系统的时间,依赖于系统时钟。
-
摄入时间(Ingestion Time):数据进入 Flink 系统的时间,介于事件时间和处理时间之间。
窗口(Window)
窗口用于将无限的数据流分割成有限的数据块,以便进行计算和分析。Flink 支持多种窗口类型:
-
滚动窗口(Tumbling Window):固定大小且不重叠的窗口。
-
滑动窗口(Sliding Window):可重叠的窗口,按固定步长滑动。
-
会话窗口(Session Window):基于活动间隙划分的窗口,用于处理用户会话。
状态(State)
状态用于存储流处理过程中的中间结果,便于后续计算。Flink 提供了多种状态类型,如键控状态(Keyed State)和操作符状态(Operator State),并支持一致性语义。状态管理是 Flink 的重要特性之一,它允许用户在编程时更轻松地管理状态。
- 无状态计算:
-
- 不需要考虑历史数据, 相同的输入,得到相同的输出!
- 如:map, 将每个单词记为1, 进来一个hello, 得到(hello,1),再进来一个hello,得到的还是(hello,1)
- 有状态计算:
-
- 需要考虑历史数据, 相同的输入,可能会得到不同的输出!
- 如:sum/reduce/maxBy, 对单词按照key分组聚合,进来一个(hello,1),得到(hello,1), 再进来一个(hello,1), 得到的结果为(hello,2)
检查点(Checkpoint)
检查点是 Flink 实现容错的关键机制,通过定期保存任务状态到持久化存储(如 HDFS),确保在发生故障时可以从最近的检查点恢复,从而保证数据的一致性和可靠性。
State Vs Checkpoint
State:是Flink中某一个Operator在某一个时刻的状态,如maxBy/sum,注意State存的是历史数据/状态,存在内存中。
Checkpoint:快照点, 是Flink中所有有状态的Operator在某一个时刻的State快照信息/存档信息。Checkpoint就是State的快照,存在磁盘中。
2、Kylin与Impala
Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口和多维数据分析(OLAP)能力。它通过预计算技术将查询结果存储在立方体模型中,从而加快查询速度,实现亚秒级的查询响应时间。Kylin基于Hadoop和Spark构建,使用MVC架构,将数据预先聚合并存储在HBase中。它适合复杂的分析查询和报表生成,如财务分析和销售分析等业务场景。
Impala是Cloudera公司开发的一个高性能、实时的SQL查询引擎(基于MPP架构),用于在Hadoop集群上直接运行SQL语句,无需转换成MapReduce作业。Impala直接在HDFS上运行,使用分布式查询引擎和内存计算,提供实时查询能力。虽然Impala的查询性能受数据规模和集群性能的影响,但它适合需要快速响应的交互式查询,如实时监控和用户行为分析等场景。
区别
- 技术架构:Kylin基于Hadoop和Spark,使用MVC架构;Impala直接在HDFS上运行,使用分布式查询引擎和内存计算。
- 查询性能:Kylin通过预计算立方体提供亚秒级查询响应时间,适合复杂分析;Impala提供实时查询能力,但性能受数据规模和集群性能影响。
- 数据模型:Kylin使用立方体模型,适合多维数据分析;Impala不限制数据模型,可以直接查询HDFS上存储的数据。
- 适用场景:Kylin适用于复杂分析和报表生成,适合数据仓库场景;Impala适用于快速响应的交互式查询,适合即席查询。
二、大数据组件
Hadoop的核心组件
-
HDFS
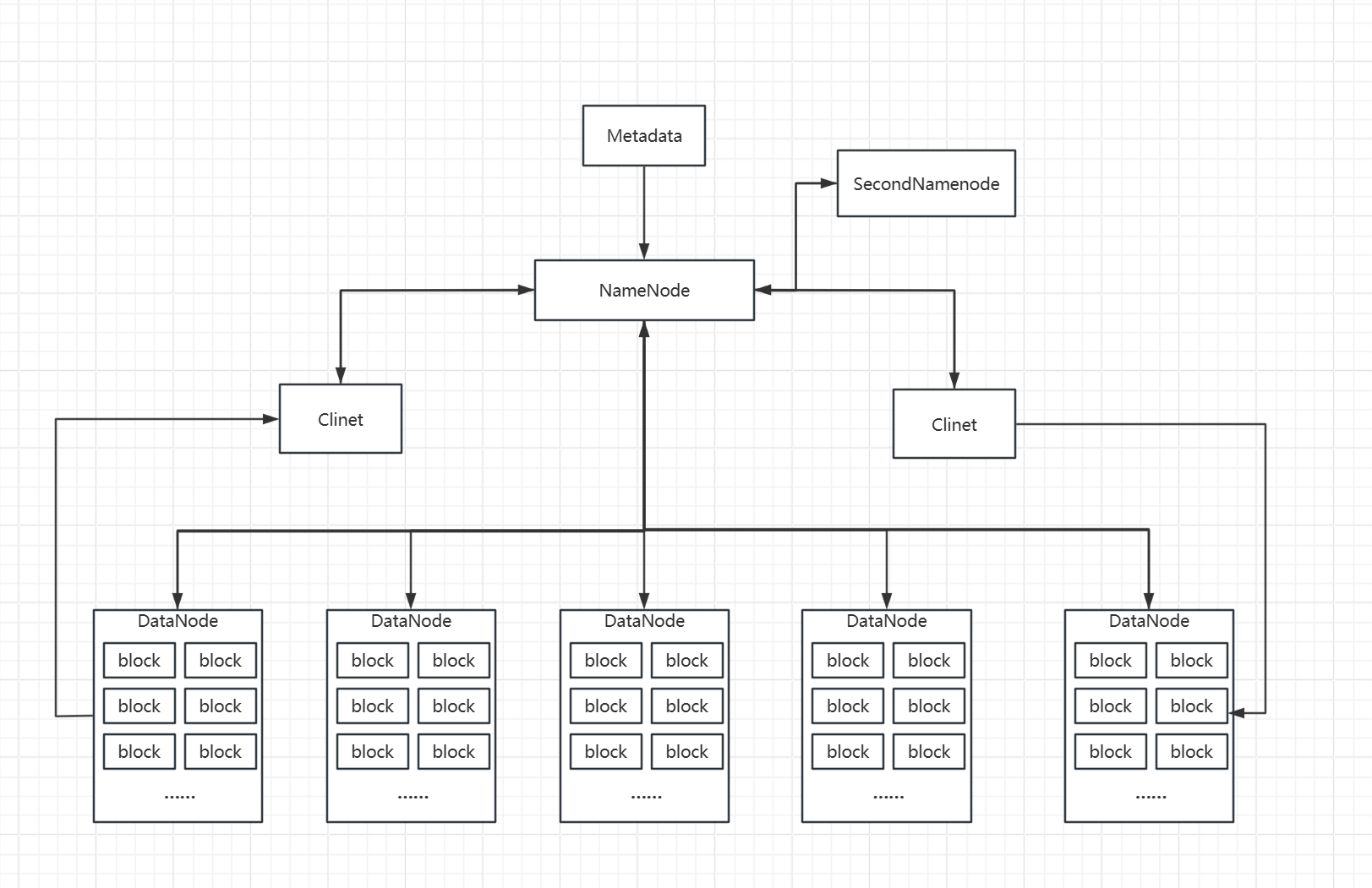
HDFS(Hadoop分布式文件系统)具有高度容错性,适合部署在低成本设备上。
其核心特性主要体现在两个方面:默认副本数配置和主从(Master/Slave)架构设计。
-
HDFS 默认副本数是 3
- HDFS采用Master/Slave架构,由一个NameNode(NN)和多个DataNode(DN)组成。NameNode 保存文件系统的所有元数据,包括目录、文件和块的信息,并维护文件在群集中的位置和文件系统的命名空间。DataNode 则负责保存文件系统的所有数据块,以及向客户端提供这些块的读写访问服务。NameNode负责管理文件系统的命名空间及客户端对文件的访问,而DataNode则负责管理所在节点上的存储。大文件被切分成多个数据块(Block),这些块分散存储在多个DataNode上,每个数据块根据配置会复制成多个副本,以提高数据的可靠性和容错性。一个数据块默认128M.
-
MAPREDUCE
MAPREDUCE是分布式计算框架,上面介绍过了,这里不做过多叙述。
-
YARN
YARN是Hadoop的资源管理层,它将资源管理和作业调度/监控功能拆分为独立的守护进程
- 功能:负责资源的管理和任务调度。
- 工作原理:YARN由全局的ResourceManager(RM)和每个应用的ApplicationMaster(AM)共同完成资源管理和任务调度。ResourceManager负责全局资源管理和任务调度,NodeManager(NM)则负责单个节点上的资源管理。容器(Container)是资源分配的基本单位,包含了CPU、内存等计算资源。当一个应用程序提交到YARN时,ResourceManager会分配一个Container,并由对应的NodeManager启动该任务,ApplicationMaster负责监控整个应用的执行。
HIVE
Hive是一个构建在 Hadoop 生态系统之上的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
关键组成以及功能
用户接口与 HiveQL 提交:
- 用户通过命令行工具 (hive 或 beeline)、JDBC/ODBC 驱动、Web UI(hue) 或其他客户端工具连接到 Hive。
- 用户提交 HiveQL 查询(如 SELECT, INSERT, CREATE TABLE, JOIN 等)。HiveQL 语法高度类似于 SQL,但也有一些针对 Hadoop 环境的扩展。
元数据存储(Metastore)
这是 Hive 的“大脑”或“目录服务”。它是一个关键的独立组件(通常是关系型数据库,目前支持 mysql(主流)、derby(单机开发/测试)、PostgreSQL(需单独安装配置,运维复杂), Oracle(大型企业级高并发环境但成本较高))。
- Hive 的元数据包括数据库、表、分区的定义(名称、结构),表的模式(Schema - 列名、数据类型),表的分区信息,表数据在 HDFS 上的物理存储位置,表的属性(如文件格式、序列化/反序列化方式 SerDe),视图定义,用户权限信息(如果集成 Sentry/Ranger)。
- 编译器在解析、验证和优化查询时,严重依赖 Metastore 中的元数据来确定表是否存在、列类型是什么、数据在哪里等。
- Metastore 的分离使得 Hive 的元数据可以被其他工具(如 Spark SQL, Presto, Impala,Doris)共享访问,这是构建统一数据湖分析平台的基础之一。
解释器、编译器、优化器
- 完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
存储与执行
- Hive的数据存储在 HDFS 中,计算由MapReduce(传统)|Tez|Spark 完成。

表类型
内部表
也称为管理表,其数据存储由Hive进行管理。当创建一个管理表时,Hive会将数据存储在默认的数据仓库目录(通常是HDFS中的一个目录)下,并且对数据的生命周期进行管理,包括数据的加载、删除等操作。(建表语句:CREATE TABLE……)
外部表
其数据存储位置是由用户自己定义的,Hive只是对这些外部数据进行映射。数据的所有权和管理不属于Hive,即使在Hive中删除外部表,数据仍然保留在原来的存储位置。(建表语句:CREATE EXTERNAL TABLE……)
存储格式
以下是 Hive 中主要和常用的存储格式,分为两大类:
行式存储格式
数据按行组织存储。读取一行数据时,会读取该行所有列的值(即使你只需要其中几列)。适合需要频繁访问整行数据的场景(如 OLTP),但在大数据分析场景(通常只访问部分列)中效率较低。
TextFile
原理: 最基础、最简单的格式。数据以纯文本形式存储(如 CSV、TSV、JSON 每行一条)。
优点: 人类可读、通用性强(任何工具都能打开)、易于生成和处理。
缺点: 无压缩或压缩率低(需额外指定压缩编解码器如 Gzip, Bzip2)、解析开销大(需按分隔符拆分字符串并转换数据类型)、存储效率低、查询性能最差(需扫描整个文件或大量无关数据)。
适用场景: 数据导入/导出的中间格式、原始日志文件、对性能要求极低或需要直接查看文件内容的场景。生产环境分析性能敏感场景强烈不推荐。
SequenceFile(实际项目中少见)
原理: Hadoop 生态系统的一种二进制键值对格式。Hive 在存储时,Key 通常是行号(或空),Value 是整个行的内容。
优点: 二进制格式(比 TextFile 解析快)、支持块级压缩(压缩率比 TextFile 好)、可分割(支持并行处理)。
缺点: 仍然是行式存储,只访问部分列时仍需读取整行数据。压缩率不如列式格式高。非Hive/SQL 生态工具支持较少,不能使用LOAD方式加载数据
适用场景: 作为 MapReduce 任务的中间输出格式、需要比 TextFile 更好性能但暂时无法使用列式格式的场景。在 ORC/Parquet 普及后,重要性已大大降低。
列式存储格式
数据按列组织存储。同一列的值连续存储在一起。读取数据时,可以只读取查询需要的列,大大减少 I/O 量。特别适合分析型工作负载(OLAP),即查询通常只涉及表的部分列。
ORC
原理: 由 Hortonworks 主导开发(现属于 Cloudera),高度优化的 Hive 原生列式存储格式。
压缩: 采用高效的压缩算法(如 Zlib, Snappy),并在列级应用(同列数据类型相似,压缩率高)。支持不同列使用不同压缩算法。
ACID 支持: 从 Hive 0.14 开始,ORC 是 Hive 实现完整 ACID 事务的主要存储格式。
向量化查询: 支持 Hive 的向量化查询引擎,一次处理一批行(通常是1024 行),减少虚函数调用和分支预测开销,显著提升CPU 效率。
优点: 极高的压缩率、卓越的查询性能(尤其对 Hive)、内置高效索引和谓词下推、原生支持 ACID、向量化查询友好。
缺点: 相比 Parquet,在非 Hive 生态(如 Spark, Presto, Impala)中的支持曾经稍弱(但现在已很好),但仍是 Hive 生态首选,不能使用LOAD。
适用场景: Hive 数据仓库的核心推荐格式,特别是需要复杂分析、高性能查询、ACID 事务保证的场景。
Parquet
原理: 由 Cloudera 和 Twitter 共同开发(现为 Apache 顶级项目),与语言和平台无关的列式存储格式。设计目标就是成为 Hadoop 生态系统的通用列式存储。
Schema 演进: 对 Schema 变更(添加/重命名/删除列)支持非常好。
高效的编码与压缩: 采用如 RLE, Dictionary Encoding, Bit-Packing 等高效编码方式,再结合压缩算法(Snappy, Gzip, LZO)。同列数据类型相似,压缩率高。
优点: 极高的压缩率、卓越的查询性能(跨引擎)、优秀的 Schema 演进支持、广泛的多引擎支持(Spark, Hive, Presto, Impala, Drill, Pig 等)、对嵌套数据处理高效。
缺点: 原生 ACID 支持不如 ORC 在 Hive 中成熟(通常依赖上层框架如 Delta Lake,Iceberg),同样不能使用LOAD。
适用场景: 跨引擎分析的首选格式(尤其在 Spark 生态中非常流行),处理包含复杂嵌套结构数据的理想选择,需要良好 Schema 演进支持的场景。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)