
不止综述!多模态大模型持续学习全链路(全面解析)从LLMs到MLLMs,一篇搞定,必学收藏!
多模态大模型的持续学习 是迈向人工智能通用化的重要一步。我们希望通过系统的综述、完善的 Benchmark、前沿的方法和开源的工具,能够为这一领域的研究者和应用开发者提供更多支持。未来,我们团队将继续深耕多模态大模型持续学习领域,探索更广泛的应用场景,持续推动该领域技术的发展与创新。
中科院自动化研究所系统研究了生成式AI和多模态大模型的持续学习,提出全面综述、多种Benchmark(UCIT、FCIT等)及创新方法(HiDe-LLaVA、FCIT、ModalPrompt等),解决"灾难性遗忘"问题。开源MCITlib代码库整合主流算法与评测基准,为研究者和开发者提供支持,推动多模态大模型在实际应用中的持续学习与知识积累。

MLNLP社区是国内外知名的机器学习与自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企业研究人员。
社区的愿景是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流和进步,特别是初学者同学们的进步。
来源 | PaperWeekly
近年来,生成式 AI 和多模态大模型(MLLMs)在各领域取得了令人瞩目的进展。然而,在现实世界应用中,动态环境下的数据分布和任务需求不断变化,大模型如何在此背景下实现持续学习(Continual Learning)成为了重要挑战。
为了应对这一问题,中国科学院自动化研究所联合中国科学院香港院 AI 中心系统性地研究了生成式 AI 和多模态大模型的持续学习,提出了一系列综述、方法、Benchmark 和 Codebase,为相关领域的研究者和实践者提供了全面支持。
生成式AI的持续学习综述

论文标题:
Continual Learning for Generative AI: From LLMs to MLLMs and Beyond
论文链接:
https://arxiv.org/pdf/2506.13045
项目主页:
https://github.com/Ghy0501/Awesome-Continual-Learning-in-Generative-Models
研究动机
以大模型为代表的生成式 AI 模型的快速发展让现代智能系统具备了理解和生成复杂内容的能力,甚至在部分领域达到了接近人类的表现。然而,这些模型依旧面临着“灾难性遗忘”问题,即在学习新任务时,往往会导致已学任务性能的显著下降。
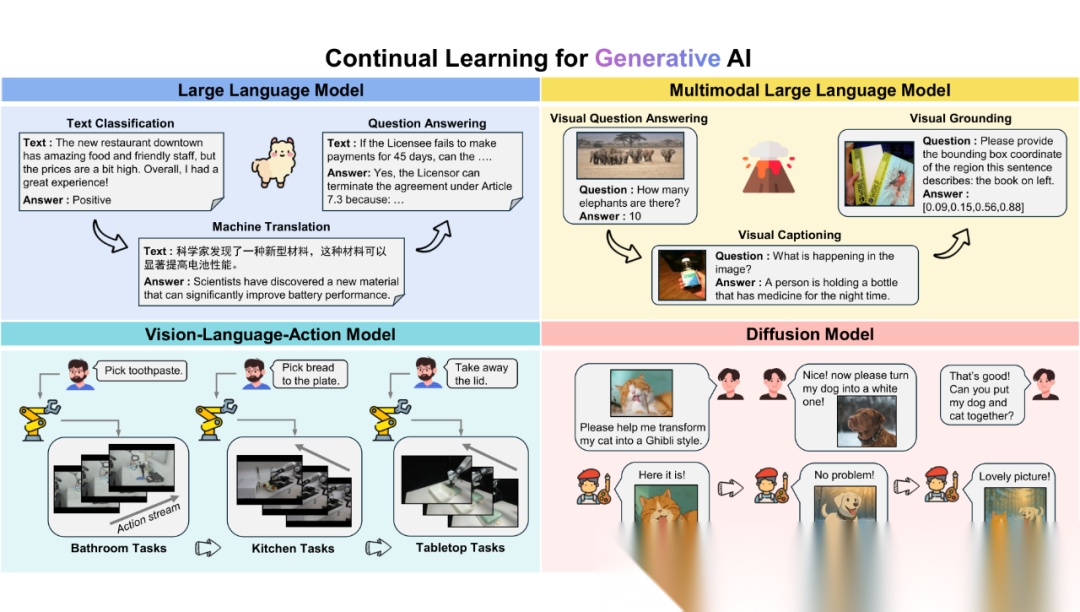
为解决这一挑战,大量的研究提出了多种方法以增强生成式AI在实际应用中的适应性和扩展性。本文系统性地综述了生成式AI的持续学习方法,涵盖大语言模型(LLMs)、多模态大语言模型(MLLMs)、视觉语言动作模型(VLA)和扩散模型(Diffusion Models)。
研究内容
本文围绕生成式 AI 的持续学习问题,系统性地综述了不同模型的训练目标、应用场景及技术方法。
研究涵盖大语言模型(LLMs)在自然语言理解与生成中的知识保留与任务适应、多模态大模型(MLLMs)处理跨模态数据时的抗遗忘能力、视觉语言动作模型(VLA)在机器人动态环境中的行为迁移与适应,以及扩散模型(Diffusion Models)针对个性化生成需求的增量学习。
这些模型的持续学习方法主要包括架构扩展(如动态网络设计)、正则化(参数或特征约束)和重放策略(历史或伪数据训练),旨在平衡新任务学习与旧任务性能的保持。
此外,研究还探讨了评估指标(整体性能、遗忘程度、泛化能力)和未来方向(高效机制、强化学习范式、多模态扩展等),为生成式 AI 的持续学习提供了全面参考。
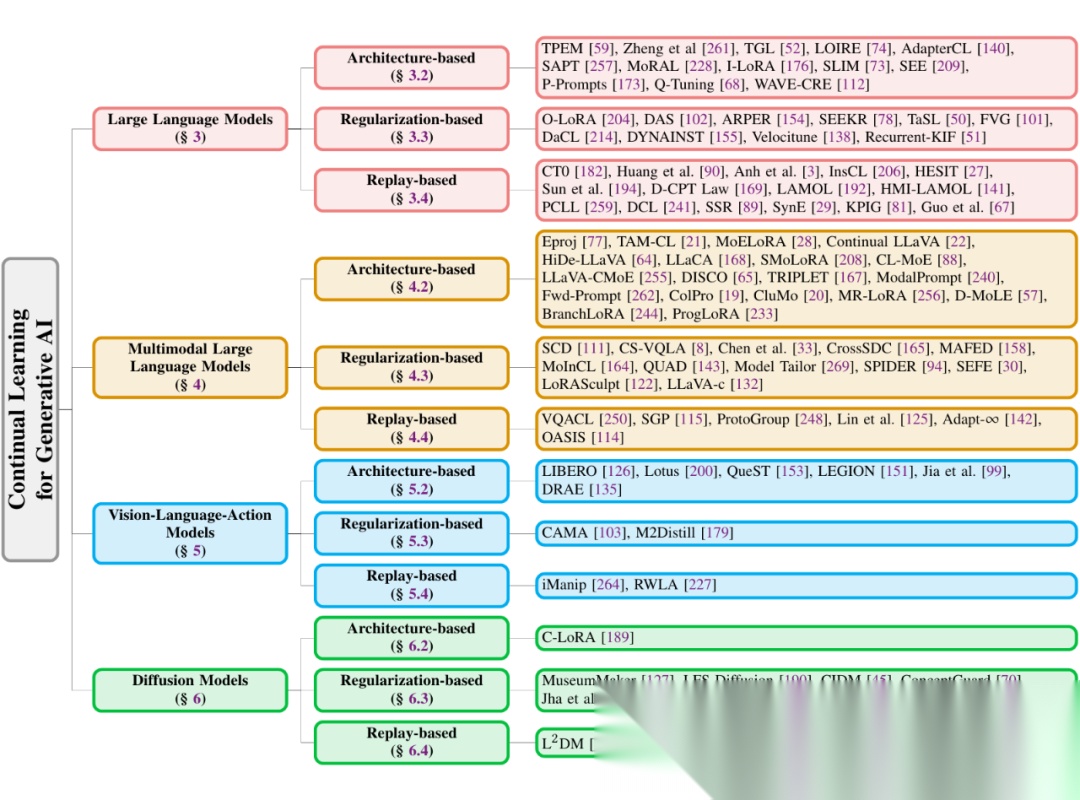
多模态大模型持续学习:Benchmark与方法
传统的持续学习任务多聚焦于单模态场景,如图像或文本分类,但随着应用需求的复杂化,多模态任务逐渐成为核心。为此,我们提出了一系列新的 Benchmark 和方法,旨在推动多模态持续学习的发展。
2.1 ACL 2025 — HiDe-LLaVA

论文标题:
HiDe-LLaVA: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model
论文链接:
https://arxiv.org/pdf/2503.12941
代码链接:
https://github.com/Ghy0501/HiDe-LLaVA
数据链接:
https://huggingface.co/datasets/HaiyangGuo/UCIT
2.1.1 研究动机
数据是多模态大模型强大性能的核心支撑,因此,在研究多模态大模型的持续学习任务前,首要问题是构建一个由多个下游任务组成,且其数据与多模态大模型的预训练语料库不重叠的评价基准。
为此,本文提出了全新的 UCIT 基准,通过模型对数据的 zero-shot 泛化性能作为筛选标准,构建了六个形式多样且避免信息泄露的数据集,用于评测连续学习任务,确保评测公平性。
同时,本文提出了一种层次化解耦策略,将模型分为任务通用层的知识融合与任务特定层的扩展,有效缓解了多模态大模型在持续指令微调中的灾难性遗忘问题。
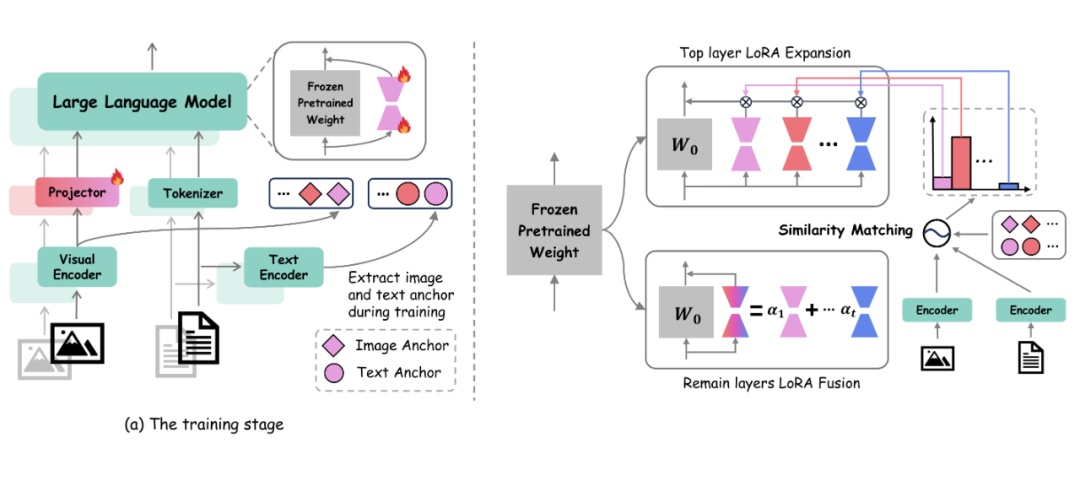
2.1.2 研究方法
本文通过 CKA 相似性分析揭示了模型不同层级的任务特性差异:顶层具有任务特异性,其余层则保持任务通用性。基于此,HiDe-LLaVA 采用分层处理机制:在顶层引入多模态锚点驱动的动态专家选择模块,实现任务自适应;在其余层采用参数融合策略保留跨任务共享知识。
实验结果表明,该方法可以有效缓解模型的灾难性遗忘现象,并且有效平衡了模型性能与计算资源效率。
目前该研究已被 ACL 2025 主会接收,相关代码及数据已全部开源。
2.2 ICCV 2025 - FCIT

论文标题:
Federated Continual Instruction Tuning
论文链接:
https://arxiv.org/pdf/2503.12897
代码链接:
https://github.com/Ghy0501/FCIT
数据链接:
https://huggingface.co/datasets/MLLM-CL/FCIT
2.2.1 研究动机
当前多模态大模型的指令微调通常需要集中收集所有任务数据进行统一训练,这种模式不仅计算成本高昂,在实际应用场景中也往往难以实现。
虽然联邦学习框架通过分布式训练为这一困境提供了潜在解决方案,但在真实动态环境中,如何使分布式系统能够持续吸收新知识而不遗忘旧知识,仍是一个亟待解决的关键挑战。
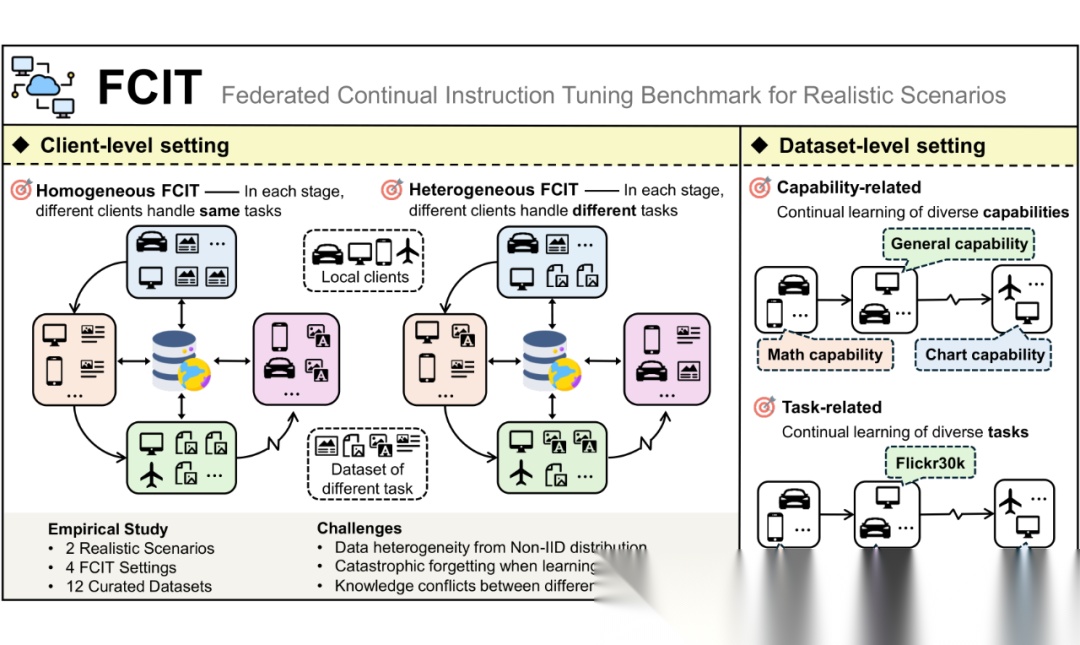
为此,本文首次提出 联邦连续指令微调(FCIT)基准,旨在模拟多模态大模型在真实世界中的联邦持续学习需求。
FCIT 包含两种现实场景:Homogeneous FCIT(同质场景)和 Heterogeneous FCIT(异质场景)。
在同质场景中,各客户端在每个阶段学习相同任务;而在异质场景中,不同客户端在同一阶段学习不同任务,要求模型在整合当前任务知识的同时,缓解遗忘问题。
FCIT 提供了 4 种设置 和 12 个精心挑选的数据集,涵盖多种任务和能力评估,全面测试模型在非独立同分布(Non-IID)数据和灾难性遗忘情况下的表现。
2.2.2 研究方法
为应对 FCIT 中的挑战,我们提出了 DISCO 框架,结合了 动态知识梳理(DKO) 和 子空间选择激活(SSA) 两种策略。
DKO 利用全局服务器的动态缓存,存储并组织任务特定的参数,减少任务间和阶段间的冲突;SSA 则通过匹配输入特征与动态缓存中的任务子空间,选择性激活相关输出,同时过滤无关信息。
实验结果表明,DISCO 在解决数据异质性和灾难性遗忘方面显著提升了模型性能,全面超越现有方法,并在 FCIT 基准上取得了最好的表现。
目前该研究已被 ICCV 2025 接收,相关代码及数据已全部开源。
2.3 EMNLP 2025 - ModalPrompt

论文标题:
ModalPrompt: Dual-Modality Guided Prompt for Continual Learning of Large Multimodal Models
论文链接:
https://arxiv.org/pdf/2410.05849
代码链接:
https://github.com/AuroraZengfh/ModalPrompt
2.3.1 研究动机
为缓解灾难性遗忘现象,现有解决方案存在显著局限性:基于数据回放的方法面临隐私泄露风险和存储成本压力,而模型扩展策略则不可避免地引发计算资源的线性增长。
值得注意的是,当前研究尚未充分探索多模态数据(图像-文本对)在持续学习中的协同监督潜力。作者提出,当前缺乏专门针对多模态特性的持续学习框架,因此需要开发一种既能利用图像-文本双重监督、又能避免计算膨胀的新方法,以实现高效且隐私安全的持续知识积累。
2.3.2 研究方法
本文提出 ModalPrompt 框架,利用多模态监督,通过构建任务特定的原型提示(Prototype features),结合双模态引导提示选择(Dual-Modality Prompt Selection)和多任务提示融合(Multi-Task Prompt Fusion),ModalPrompt 在无回放数据的情况下有效保留旧任务知识并提升新任务性能。
此外,该方法通过动态提示选择降低计算复杂度,使推理速度提升 1.42 倍,同时显著减少存储和训练成本。
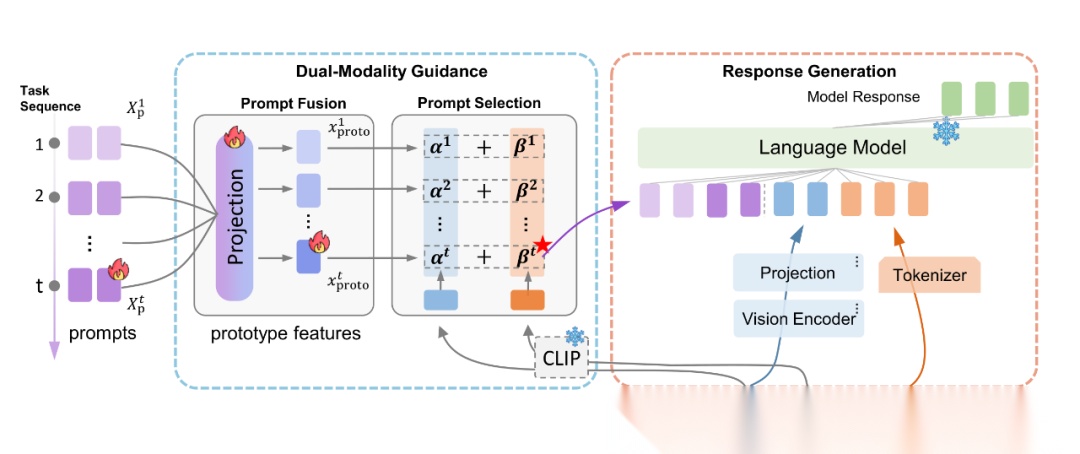
目前该研究已被 EMNLP 2025 主会接收,相关代码已全部开源。
2.4 MLLM-CL

论文标题:
MLLM-CL: Continual Learning for Multimodal Large Language Models
论文链接:
https://arxiv.org/pdf/2506.05453
代码链接:
https://github.com/bjzhb666/MLLM-CL
数据链接:
https://huggingface.co/datasets/Impression2805/MLLM-CL
2.4.1 研究动机
本文认为现有的多模态大模型连续指令微调评测基准主要关注独立同分布(IID)场景下的领域知识评估,缺乏对模型基础能力(如 OCR、数学推理等)在非 IID 场景下的系统性评测。
为此,本文提出了一个新的多模态大模型持续学习基准 MLLM-CL,涵盖领域持续学习(DCL) 和能力持续学习(ACL) 两种设置,分别针对同分布(IID)和非同分布(non-IID)场景下的领域知识和基础能力学习进行评估。
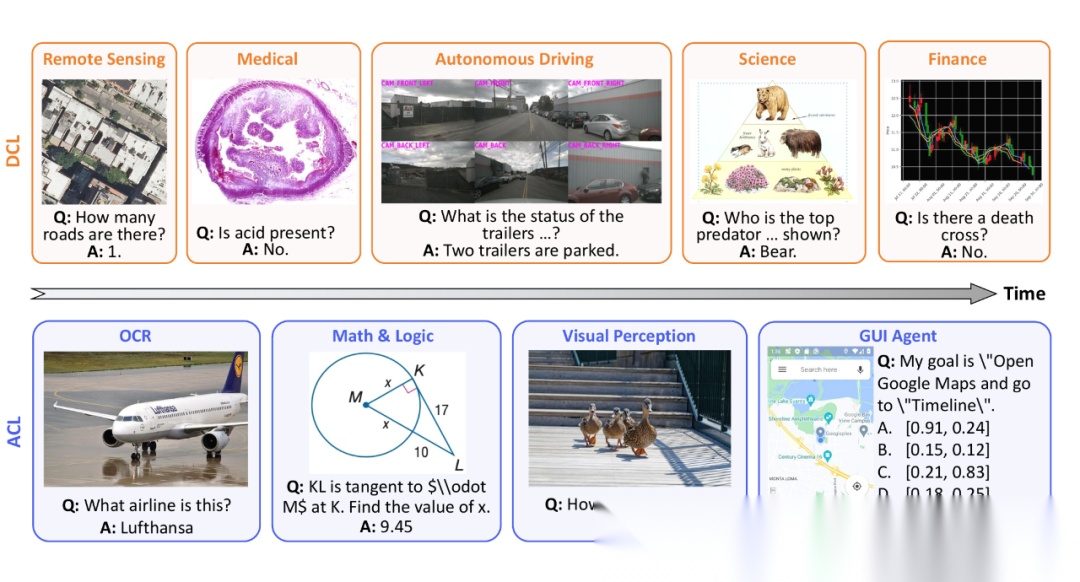
2.4.2 研究方法
为解决灾难性遗忘问题,本文提出了 MR-LoRA,通过领域或能力特定的 LoRA 模块实现参数隔离,避免任务间干扰,并设计基于 MLLM 自身的多模态理解能力的路由选择器,仅需少量样本微调即可精准匹配输入与最优专家模块。
实验表明,该方法在领域持续学习(DCL)和能力持续学习(ACL)任务上显著优于传统回放或模型扩展方法。
2.5 LLaVA-c

论文标题:
LLaVA-c: Continual Improved Visual Instruction Tuning
论文链接:
https://arxiv.org/pdf/2506.08666
2.5.1 研究动机
多模态大模型(如 LLaVA-1.5)在持续指令微调中面临的两大核心挑战:首先,传统的多任务联合训练存在任务平衡困难(需人工调整数据比例)和扩展成本高(新增任务需全量重训练)的固有缺陷。
其次,现有持续学习方法虽能增量学习新任务,但普遍存在"基础模型退化"现象——模型过度拟合任务特定指令(如强制单字回答),丧失处理多样化指令的通用能力。
2.5.2 研究方法
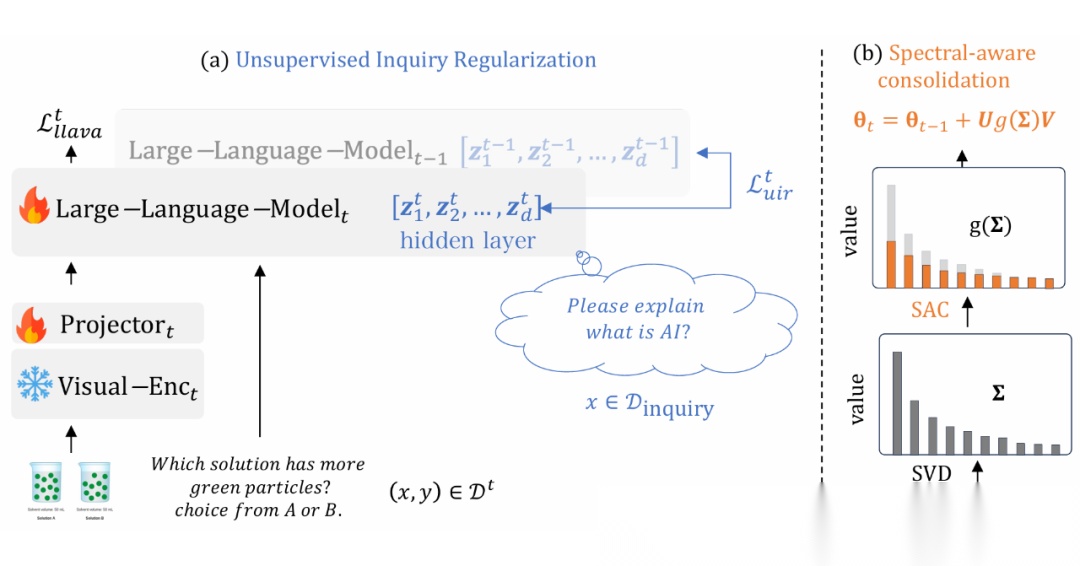
本文提出了 LLaVA-c,通过两个核心技术改进 LLaVA-1.5 模型:
1)频谱感知巩固(SAC),利用奇异值分解动态调整参数更新量,通过滑动窗口平均实现任务间知识平衡,相比传统模型混合(ModelMix)提升任务兼容性;
2)无监督查询正则化(UIR),通过约束未标注文本指令的特征空间偏移(L2 距离损失)防止基础模型退化,在零额外标注成本下保持指令跟随能力。
本文在预训练和指令微调两阶段上都验证了所提出方法的有效性,在通用评价基准和下游任务指标上均取得了最优的性能,并且首次实现持续学习效果超越多任务联合训练。
多模态大模型持续学习:代码仓库

论文标题:
MCITlib: Multimodal Continual Instruction Tuning Library and Benchmark
论文链接:
https://arxiv.org/pdf/2508.07307
代码仓库:
https://github.com/Ghy0501/MCITlib
研究动机
随着多模态大模型持续学习研究的蓬勃发展,各类创新方法和评估基准不断涌现,但研究社区始终缺乏一个系统化、标准化的开发与评测平台。
为填补这一关键空白,我们推出了 MCITlib,一个开源的多模态持续指令微调代码仓库。MCITlib 集成了当前领域内 8 种主流算法,精心挑选了两个高质量基准(UCIT 和 DCL),有效避免信息泄露,为研究者提供了一个统一、公平的实验环境,便于全面评估不同方法的优劣。
通过 MCITlib,用户可以高效开展实验,深入探索多模态持续学习的无限潜力。

未来,MCITlib 也将持续进行更新,扩展更多模型、任务和评测维度,为多模态持续学习研究提供坚实助力。
总结与展望
多模态大模型的持续学习 是迈向人工智能通用化的重要一步。我们希望通过系统的综述、完善的 Benchmark、前沿的方法和开源的工具,能够为这一领域的研究者和应用开发者提供更多支持。未来,我们团队将继续深耕多模态大模型持续学习领域,探索更广泛的应用场景,持续推动该领域技术的发展与创新。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 6
6 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)