
Python 验证码识别(使用pytesseract库)
Tesseract是一个高度精确的开源OCR(光学字符识别)系统,广泛应用于文本识别项目中。结合Python的pytesseract库,实现图片文字的提取。
·
摘要
python中使用pytesseract库进行ocr识别,需要安装Tesseract-OCR,通过指定pytesseract.tesseract_cmd路径,可以将esseract-OCR集成到pytho程序中,避免客户端电脑的依赖。
1、安装Tesseract-OCR
Tesseract是一个高度精确的开源OCR(光学字符识别)系统,广泛应用于文本识别项目中。
- 下载地址:
https://digi.bib.uni-mannheim.de/tesseract/
选择最新的稳定版下载 - 安装程序:下载后安装程序
- 中文包下载:
地址:https://gitcode.com/open-source-toolkit/90e2f
下载了最新版本的chi-sim.traineddata文件,复制到Tesseract的tessdata目录下
通常,路径类似于C:\Program Files\tesseract\tessdata(Windows)
或 /usr/share/tesseract-ocr/4.00/tessdata(Linux)。
2、在python中使用
pip install pytesseract
3、本地图片识别
import pytesseract
from PIL import Image
# 获取文件的绝对路径
def get_abspath(filename):
try:
current_dir = os.getcwd()
filename = os.path.normpath(os.path.join(current_dir, filename))
# print(f"get_abspath文件路径:{filename}")
return filename
except Exception as e:
print(f"获取文件绝对路径时出现错误: {e}")
return ""
# 手动指定路径(Windows常见) Tesseract 系统路径
driver_path = r"Tesseract-OCR\\tesseract.exe"
pytesseract.pytesseract.tesseract_cmd = get_abspath(driver_path)
#使用示例
if __name__ == "__main__":
# 1 识别本地图片
# 英文识别
current_dir = os.getcwd()
filename = os.path.normpath(os.path.join(current_dir, f"code.jpg"))
file = Image.open(filename)
text = pytesseract.image_to_string(file, lang="eng")
print(text)
#中文识别,需要下载语言包
filename = os.path.normpath(os.path.join(current_dir, f"sushi.png"))
file = Image.open(filename)
text = pytesseract.image_to_string(file, lang='chi_sim')
print(f"识别结果:{text}")
识别结果示例: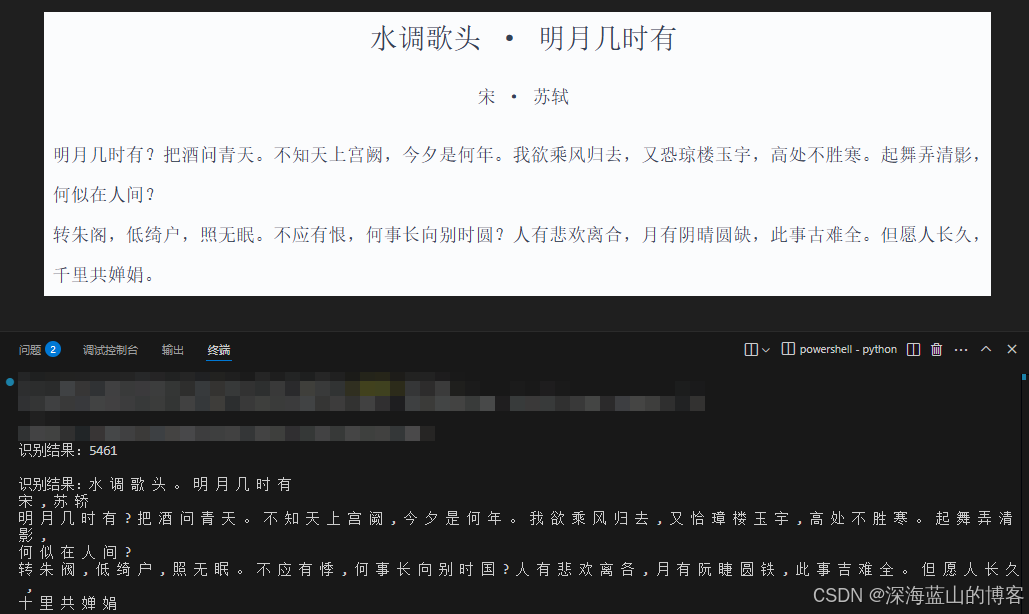
4、结合playwright动态识别网站验证码
import os
import pytesseract
from PIL import Image
from playwright.sync_api import Playwright
import tools.pwHander as pwHander
from PIL import Image
# 获取文件的绝对路径
def get_abspath(filename):
try:
current_dir = os.getcwd()
filename = os.path.normpath(os.path.join(current_dir, filename))
# print(f"get_abspath文件路径:{filename}")
return filename
except Exception as e:
print(f"获取文件绝对路径时出现错误: {e}")
return ""
# 手动指定路径(Windows常见) Tesseract 系统路径
driver_path = r"Tesseract-OCR\\tesseract.exe"
pytesseract.pytesseract.tesseract_cmd = get_abspath(driver_path)
# 验证码图片识别
def get_captcha(page: Playwright, element_selector="img#captcha", file_name="code.jpg"):
try:
current_dir = os.getcwd()
filename = os.path.normpath(os.path.join(current_dir, f"{file_name}"))
# 通过class选择器获取img元素
code_img = page.locator(element_selector)
if not code_img:
raise ValueError("验证码元素未找到!")
# 刷新验证码
# code_img.click()
# 下载验证码图片
code_img.screenshot(path=filename)
file = Image.open(filename)
text = pytesseract.image_to_string(file, lang="eng")
print("验证码识别结果:", text)
return text.strip()
except Exception as e:
print(f"获取验证码 失败:{str(e)}")
return ""
#使用示例
if __name__ == "__main__":
# 2 动态识别网站验证码
with sync_playwright() as p:
browser = p.chromium.launch(headless=False, slow_mo=1000)
context = browser.new_context()
page = context.new_page()
page.goto("测试网址")
# 验证码图片下载
imgText = get_captcha(page, "img#jcaptcha")
print(f"验证码:{imgTest}")

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)