
Deepspeed详解与代码使用
CUDA_VISIBLE_DEVICES 不能与DeepSpeed一起使用来控制应该使用哪些设备。,DS中的WarmupLR也就相当于HF的参数lr_scheduler_type:constant_with_warmup,参数默认。有一个问题就来了,如果两边都配置了的话,会默认使用那个呢?这个问题困扰了我很久,直到看到源码:如下所示,核心便是其Zero策略,ZeRO训练支持了完整的ZeRO Sta
Deepspeed详解与代码使用
Deepspeed训练使用已集成至git代码训练框架项目,项目包括一个每个人都可以以此为基础构建自己的开源大模型训练框架流程、支持主流模型使用deepspeed进行Lora、Qlora等训练、主流模型的chat template模版等模块:https://github.com/mst272/LLM-Dojo
原理part
首先deepspeed是一个pytorch优化库,用来加速分布式训练。本质上来说应该属于数据并行。
Zero策略
核心便是其Zero策略,ZeRO训练支持了完整的ZeRO Stages1, 2和3。
首先要明白训练模型时显存主要用在如下四个地方:
1、模型参数
2、梯度
3、优化器
4、激活值
- Zero-0:不使用所有类型的分片,仅使用DeepSpeed作为DDP,速度最快(显存够时使用)
- Zero-1:切分优化器状态,分片到每个数据并行的工作进程(每个GPU)下;有微小的速度提升。
- Zero-2:切分优化器状态 + 梯度,分片到每个数据并行的工作进程(每个GPU)下
- Zero-3:切分优化器状态 + 梯度 + 模型参数,分片到每个数据并行的工作进程(每个GPU)下
Zero各个阶段实例与参数解析
仅对Zero参数进行解析,更详细完整的配置可见git项目中的配置文件部分:ds_config_zero2.json
Zero-2
示例配置如下:
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients": true
"round_robin_gradients": true
}
}
- offload_optimizer: 减少GPU RAM使用,将优化器状态加载到CPU
- overlap_comm: 当设置为true时,会权衡增加的GPU内存使用量,以降低所有延迟。此功能使用4.5倍的allgather_bucket_size和reduce_bucket_size值。在这个例子中,它们被设置为5e8,这意味着它需要9GB的GPU内存。如果你的GPU内存为8GB或更少,可以设置false来时间换空间。
Zero-3
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}
其中详细的参数意义读者可自行查阅官网:transformers
如果不想把offload_optimizer和offload_param卸载到cpu,可以使用 none 代替 cpu。
训练实战细节
单节点
单节点情况下,即单机单卡或者单机多卡,CUDA_VISIBLE_DEVICES 不能与DeepSpeed一起使用来控制应该使用哪些设备。正确的方式如下,在localhost后选择用来训练的GPU:
deepspeed --include localhost:1
与Trainer共用时相关配置选择。
4中搭配方式
目前已经支持了4种不同的混合方式:
- 1、HF(Trainer) optimizer + HF(Trainer) scheduler: 即在
TrainingArguments中配置optimizer和lr scheduler,在ds config中不配置optimizer和lr scheduler - 2、DS config optimizer + DS config scheduler
- 3、HF scheduler + DS optimizer
- 4、DS scheduler + HF optimizer:即在
TrainingArguments中配置optimizer,在ds config中配置lr scheduler。
常用搭配
一般的搭配就是直接使用DS的AdamW优化器和DS的WarmupLR 优化器,DS中的WarmupLR也就相当于HF的参数lr_scheduler_type:constant_with_warmup,参数默认auto即可,如下所示:
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
优先级问题
有一个问题就来了,如果两边都配置了的话,会默认使用那个呢?这个问题困扰了我很久,直到看到源码:如下所示,简单讲就是模型训练时会首先看ds config中有没有相关配置,有的话就直接使用,没有的话就使用HF(Trainer)中的配置。 所以如果两边都配置了的话HF中的相关参数就失效了。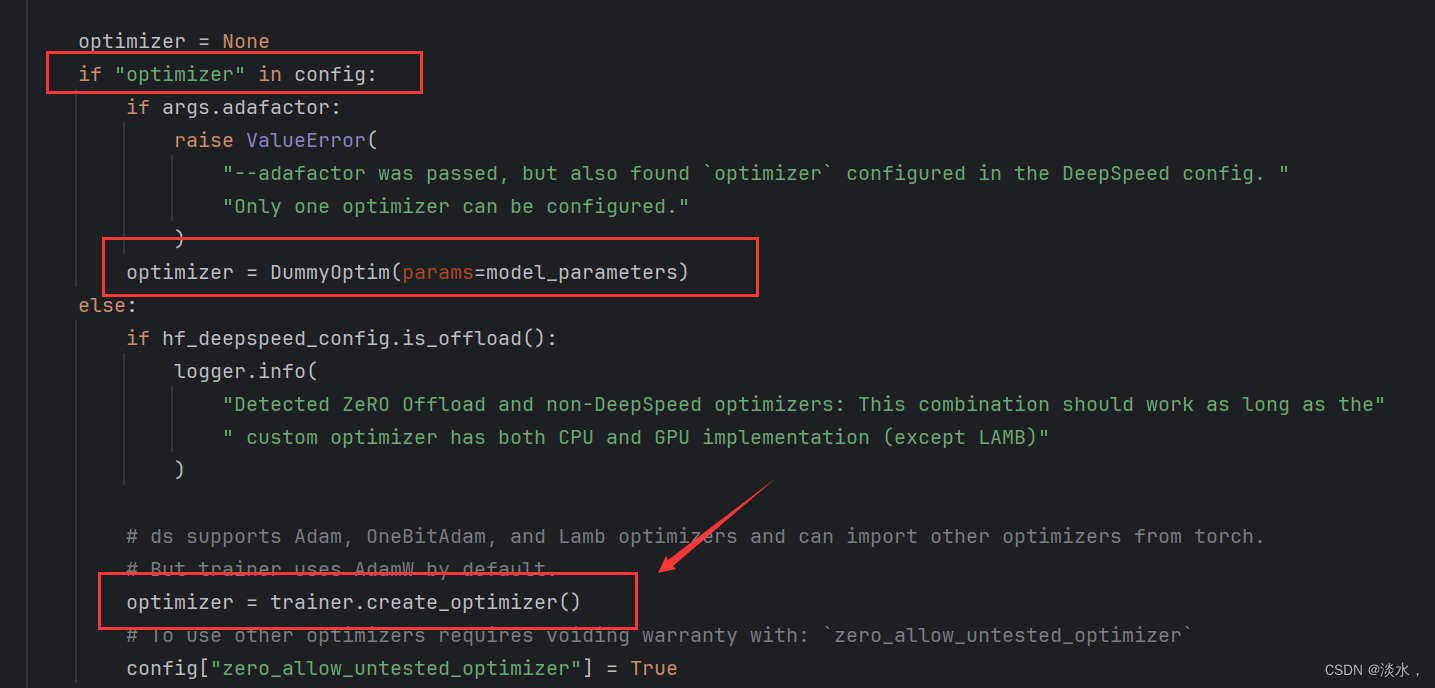
训练代码及使用
目前deepspeed已经与trainer集成了,故使用起来非常的简单,只需在TrainingArguments进行配置,然后运行即可。
训练命令可以参考如下方式,源码在此:github 训练项目,相关使用非常简洁,读者可以进行参考:
deepspeed --include localhost:6,7 main_train.py
参考推荐
1、deepspeed官方文档:https://www.deepspeed.ai/docs/config-json/
2、https://huggingface.co/docs/transformers/v4.40.2/deepspeed?pass-config=path+to+file&zero-config=ZeRO-1&opt-sched=scheduler&precision=bf16&deploy=multi-GPU&multinode=deepspeed
3、https://github.com/huggingface/transformers/issues/24359

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)