
python浏览器自动化完美反检测,selenium最佳反检测,playwright最佳反检测,PC自动化最佳反检测
安全过反爬反机器人的python方法,使用plarwright接管浏览器实现过检测
背景
工作需要大量抓取网页cookie,token等数据(逼问各种国内外AI模型都没结果),使用requests访问反爬千奇百怪的且设计需要耗费大量精力(尤其我抓取千牛工作台,1688工作台这种反爬力度很大,我怕头秃也没朝这个方向钻研AI也劝退我这个方向了),使用selenium直接启动浏览器需要设置大量伪装参数且还很容易很发现,playwright也有这种风险,在文章《别去送死了。Selenium 与 Puppeteer 能被网站探测的几十个特征》,也说明了
检测机器人网站
网上找到了两个检测自动化的网站,可以帮助我们验证程序是否过浏览器等机器人检测
1:Antibot
2:BrowserScan(可能要科技才能访问)
正常打开效果-基本都是全绿通过
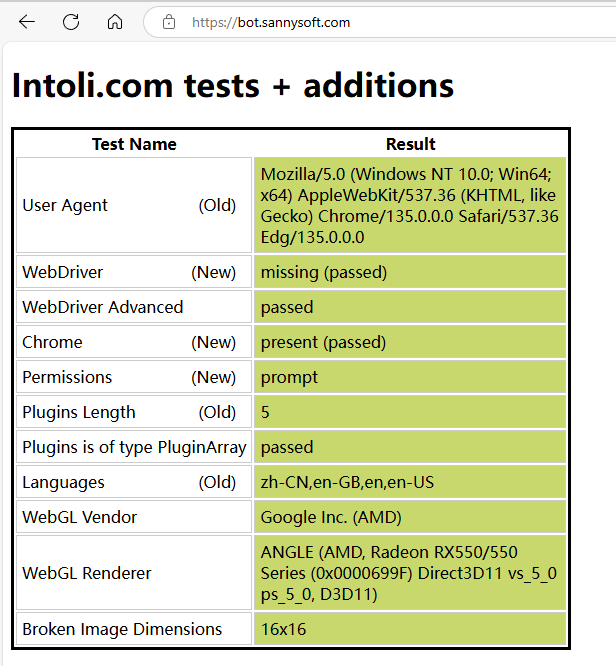


使用selenium启动浏览器效果
selenium:已经提示有异常了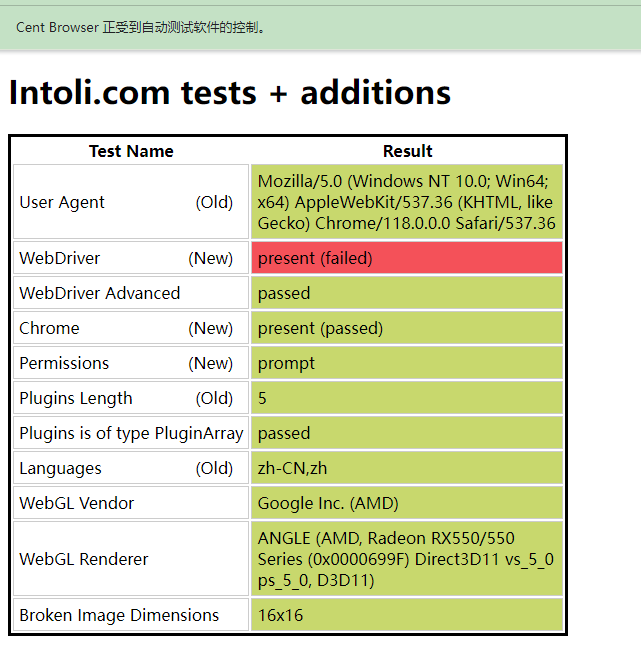
这个网站更是提示机器人要素更多


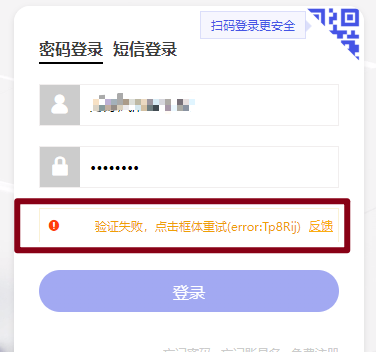
另外,我登录常用的千牛工作台,打开后,100%出现验证码,且手动拉,100%失败,必杀
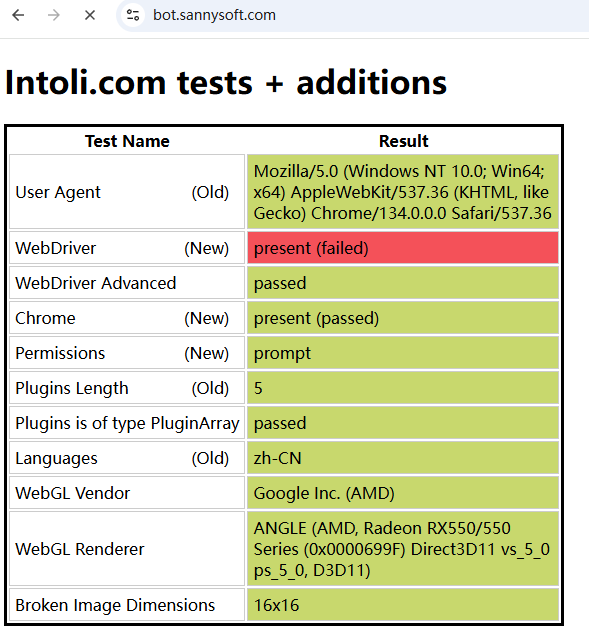
再看看playwright-也是提示



方案1:网上成功案例,且我之前用的稳如老狗的方案
使用CMD远程端口打开浏览器。用selenium接管浏览器,这样检测能过很多,第一个检测网站过的没问题
subprocess.Popen(f"{chrome_path} --profile-directory=\"Profile 12\" --remote-debugging-port=9222",
# 浏览器的启动CMD命令,带上端口为了selenium控制
shell=True,creationflags=subprocess.DETACHED_PROCESS | subprocess.CREATE_NEW_PROCESS_GROUP)
# 连接selenium
chrome_options = Options()
debugger_address = "127.0.0.1:9222" # 浏览器的调试地址
chrome_options.add_experimental_option("debuggerAddress", debugger_address) # 设置Chrome选项
driver = webdriver.Chrome(service=Service(chrome_driver), options=chrome_options) # 创建driver实例
# 进入报表页面
driver.get('https://www.browserscan.net/zh/bot-detection') # 报表页面
# driver.get('https://bot.sannysoft.com/') # 报表页面



虽然这个网站还是检测出来机器人,但!!已经!!测试能过很多检测不严格的网站了!!
方案1漏洞:,此时打开网站后,是selenium接管了,如果在账号密码框使用selenium输入账号密码,还是歇菜被检测出来,我之前用的是interception-python库结合pyautogui识别,模拟键鼠的,100%成功过(驱动级的键鼠比WIN32API还要底层),但运行期间键鼠不敢动,费劲的一批
最优方案-已经设计好稳定运行几个月
使用cmd远程端口打开浏览器,接入playwright,此时两个检测机器人网站通过,完美过变态的淘宝千牛的反检测力度
直接看检测最强的第二个网站结果
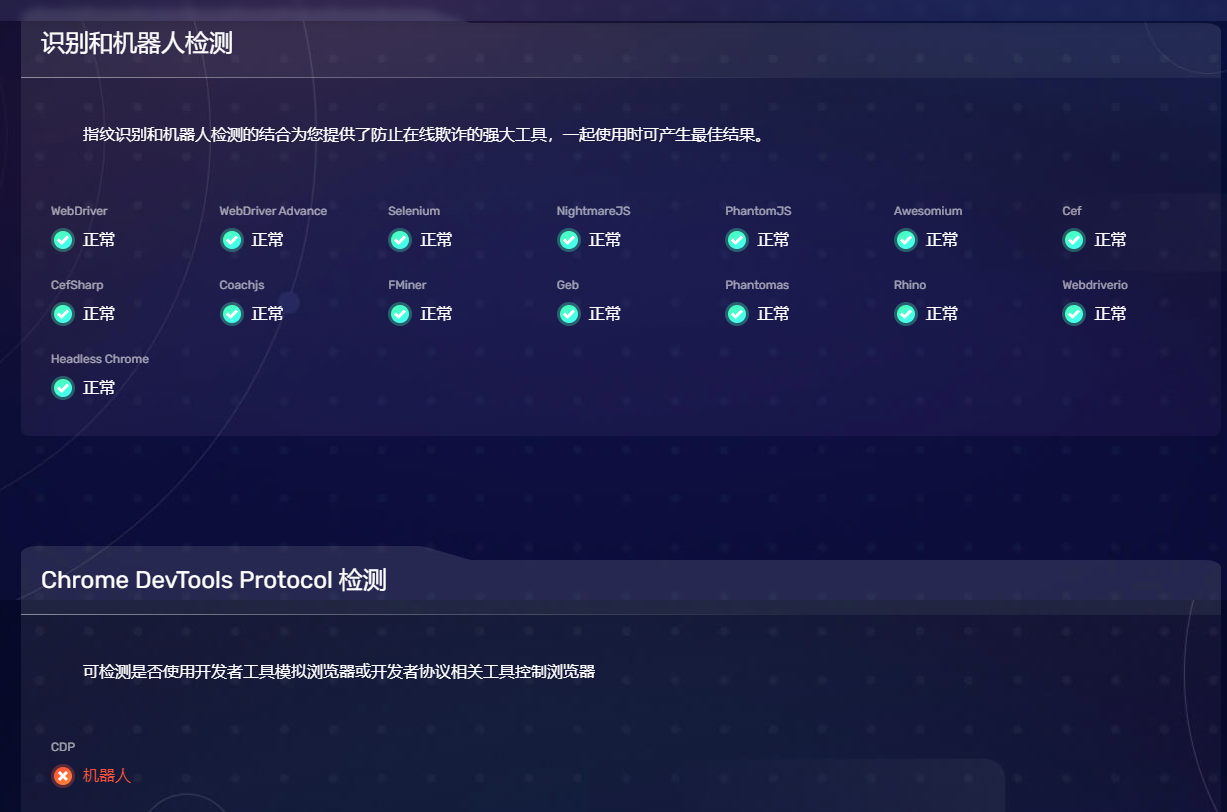
虽然提示CDP异常,但是我查了AI,这个只要程序接管浏览器,这个就比如会变,但是在淘宝千牛,1688商家工作台,稳如老狗进入,甚至playwright接管浏览器后,自动输入账号密码框,速度很快的输入也不会提示异常弹出验证码。(几个月运行每天依次抓近90个淘宝千牛1688的账号,20秒不到抓到cookie和token,很快速了,虽然比不过requests,我实在不会设计这个过爬虫)
另外也可以不显示浏览器登录,显示浏览器登录随时可以改变窗口状态切换其他程序打字聊天,丝毫不影响自动登录网站
# 输入账户密码--这是我用plarwright情况帐号框输入账号密码的频率
page.fill("#fm-login-id","") # 清空账号框
time.sleep(random.uniform(0.2, 0.5))
page.type("#fm-login-id",user_name) # 登录页面的账号框输入值
time.sleep(random.uniform(0.9, 1.3))
page.fill("#fm-login-password","") # 清空密码框
time.sleep(random.uniform(0.2, 0.5))
page.type("#fm-login-password", password) # 密码自动输入
time.sleep(random.uniform(1, 1.4))
# 点击登录按钮
page.click("#login-form > div.fm-btn > button") # 点击登录
time.sleep(random.uniform(1.4, 1.9))
甚至你可以先用playwright接管浏览器后,再用selenium接管浏览器做别的操作
playwright和selenium交替接管浏览器案例
# 上文是playwright接管浏览器操作的省略
......
page.wait_for_url("https://.......", timeout=15000) # 等待跳转
print("页面加载完成,网络请求监听结束")
browser.close() # play断开链接,selenium上
# 换selenium来接管浏览器
chrome_options = Options()
debugger_address = "127.0.0.1:9222" # 浏览器的调试地址
chrome_options.add_experimental_option("debuggerAddress", debugger_address) # 设置Chrome选项
driver = webdriver.Chrome(service=Service(chrome_driver), options=chrome_options) # 创建driver实例
# 换selenium来抓cookie
cookies = driver.get_cookies()
......
总结:
这是我工作中为了快速抓COOKIE能试出来最稳定的方法了,真就是我硬生生试出来的,如有雷同那就雷同吧,反正我这是试出来的,看到这里辛苦点个赞吧

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)