
CADS:一种基于跨模态对齐与深度自蒸馏的自监督学习器(用于CT体积分割)|文献速递-最新医学人工智能文献
Title题目CADS: A Self-Supervised Learnervia Cross-Modal Alignment andDeep Self-Distillation for CTVolume SegmentationCADS:一种基于跨模态对齐与深度自蒸馏的自监督学习器(用于CT体积分割)01文献速递介绍3D计算机断层扫描(CT)体积语义分割相关研究内容翻译 3D计算机断层扫描(CT
Title
题目
CADS: A Self-Supervised Learnervia Cross-Modal Alignment andDeep Self-Distillation for CTVolume Segmentation
CADS:一种基于跨模态对齐与深度自蒸馏的自监督学习器(用于CT体积分割)
01
文献速递介绍
3D计算机断层扫描(CT)体积语义分割相关研究内容翻译 3D计算机断层扫描(CT)体积的语义分割对于各类计算机辅助任务至关重要,包括病灶勾勒、疾病诊断、病理分析及治疗规划。尽管依赖全监督学习的深度学习技术在具备大规模标签的情况下,已在各类图像理解任务中取得显著成果,但当标注因时间限制、人力成本及专业知识局限而不足时(尤其在3D医学图像分割领域[1]),其性能常不尽如人意。 为解决这一问题,自监督学习(SSL)已成为传统大规模监督学习的一种极具潜力的替代方案。自监督学习旨在不依赖人工标注的情况下,通过解决辅助任务(pretext task)来预训练一个性能强大的编码器或网络,以用于下游任务。近年来的研究已探索了多种可作为自监督学习目标的辅助任务,形成了三大主要类别:对比学习[2]-[8]、掩码图像建模(MIM)[9]-[14],以及前两者的结合[15]-[20]。然而,尽管这些方法应用广泛,现有用于CT体积分割的自监督学习方法仍存在两大主要局限性:其一,这些方法的辅助任务主要依赖CT数据,忽视了多模态医学影像中可获取的宝贵信息——不同模态能为同一研究对象提供互补视角;其二,自监督损失主要侧重于优化瓶颈层(bottleneck layer)的特征,这可能导致对浅层的监督不足,进而造成表征学习不充分。 为解决上述局限性,我们提出了一种名为跨模态对齐与深度自蒸馏(Cross-modal Alignment and Deep Self-distillation,CADS)的新型自监督学习模型。CADS不仅通过传统辅助任务对齐同一图像的两个增强视图,还利用对齐后的CT体积与生成的X射线图像所提供的跨模态信息,以增强表征学习效果。为克服获取大规模CT与X射线配对数据集所面临的挑战,我们采用数字重建放射影像(DRR)技术[21],为每个3D CT体积合成X射线图像(冠状面视图)。DRR是一种无需训练的方法,能保持CT体积与生成的X射线图像之间的解剖学一致性。通过DRR生成的X射线图像可提供同一研究对象的2D平面视图,展现出CT体积中较难显现的特征(如整体解剖结构)。通过整合这些多样的数据呈现形式及配对数据中固有的解剖学关联性,我们丰富并提升了模型的表征能力。 CADS设计为可接收两类输入数据:3D CT体积与2D生成X射线图像。该模型包含一个在线学生网络(online student network)和一个动量教师网络(momentum teacher network),两者均采用基于Transformer模块的相同编码器架构。Transformer的序列建模能力使CADS能够有效从CT和生成的X射线两种模态中学习。此外,我们引入了一种深度自蒸馏策略,该策略不仅覆盖瓶颈层,还延伸至浅层。通过促进网络架构内不同抽象层级间的知识迁移,这一策略实现了性能提升。同时,我们针对两个裁剪后的3D CT视图提出了一种改进的均匀采样策略:将视图划分为多个补丁块(patch),通过均匀采样丢弃其中75%后再重新组合。该策略不仅降低了图像分辨率,还生成了受损视图(corrupt view)。随后,我们采用该方法通过深度自蒸馏对基于Transformer的编码器进行预训练。 以预训练编码器为基础,我们构建了PVT-UNet模型,并在七个CT体积分割任务中对其进行评估。结果表明,PVT-UNet的性能优于MOCOv3[22]、DiRA[20]等当前主流自监督学习方法,同时也优于nnUNet[23]、CoTr[24]等常用医学图像分割方法。此外,实验结果还显示,在预训练阶段,所提出的CADS模型相较于同类自监督学习方法,计算复杂度更低,GPU内存消耗更少。 本研究的贡献主要体现在四个方面: 1. 提出了名为CADS的新型自监督学习模型,通过跨模态对齐与深度自蒸馏,为CT体积分割预训练性能强大的编码器; 2. 将CT体积与生成的X射线图像之间的跨模态对齐设计为一项具有挑战性的辅助任务,从而提升编码器的图像表征学习能力; 3. 提出深度自蒸馏策略,以增强对学生编码器浅层的表征监督; 4. 为学术界提供了一个适用于3D CT体积分割的高性能预训练模型PVT-UNet——其优越性已在七个CT分割任务中得到验证。此外,所提出的CADS模型在计算复杂度和内存需求方面还具备预训练高效性:相较于性能第二优的高效自监督学习方法,其浮点运算次数(FLOPs)、每轮次预训练时间及GPU内存使用率分别降低至约42%、60%和80%。 本研究的初步数据已在2022年医学图像计算与计算机辅助干预国际会议(MICCAI 2022)上发布[25]。本文呈现的是一个经过大幅更新的版本,主要改进包括:(1)采用先进的Transformer作为模型骨干网络,为学术界预训练出高质量的基于Transformer的3D CT体积分割模型;(2)将CT体积与生成的X射线图像均纳入自监督学习范式,实现跨模态对齐——这一过程构建了具有挑战性的多视图学习任务,有助于获取高质量表征;(3)重新设计均匀采样策略,以降低3D视图分辨率并生成受损视图,迫使模型更关注局部表征;(4)将CADS与MOCOv3、DiRA等主流自监督学习方法,以及nnUNet、CoTr等医学图像分割方法进行性能对比评估。
Aastract
摘要
Self-supervised learning (SSL) has long hadgreat success in advancing the field of annotation-efficientlearning. However, when applied to CT volume segmentation, most SSL methods suffer from two limitations,including rarely using the information acquired by different imaging modalities and providing supervision only tothe bottleneck encoder layer. To address both limitations,we design a pretext task to align the information in each3D CT volume and the corresponding 2D generated X-rayimage and extend self-distillation to deep self-distillation.Thus, we propose a self-supervised learner based onCross-modal Alignment and Deep Self-distillation (CADS)to improve the encoder’s ability to characterize CT volumes. The cross-modal alignment is a more challengingpretext task that forces the encoder to learn better imagerepresentation ability. Deep self-distillation provides supervision to not only the bottleneck layer but also shallowlayers, thus boosting the abilities of both. Comparativeexperiments show that, during pre-training, our CADS haslower computational complexity and GPU memory cost thancompeting SSL methods. Based on the pre-trained encoder,we construct PVT-UNet for 3D CT volume segmentation. Ourresults on seven downstream tasks indicate that PVT-UNetoutperforms state-of-the-art SSL methods like MOCOv3 andDiRA, as well as prevalent medical image segmentationmethods like nnUNet and CoTr.
自监督学习(SSL)相关研究内容翻译 自监督学习(SSL)在推动标注高效型学习领域发展方面长期以来成效显著。然而,将其应用于计算机断层扫描(CT)体积分割时,大多数自监督学习方法存在两大局限性:一是很少利用不同成像模态所获取的信息,二是仅对瓶颈编码器层提供监督。 为解决这两个问题,我们设计了一个 pretext任务( pretext task, pretext任务指自监督学习中用于构建伪标签、提供监督信号的辅助任务),以对齐每个三维CT体积与其对应的二维生成X射线图像中的信息,并将自蒸馏扩展为深度自蒸馏。 为此,我们提出一种基于跨模态对齐与深度自蒸馏(Cross-modal Alignment and Deep Self-distillation,CADS)的自监督学习器,旨在提升编码器对CT体积的表征能力。其中,跨模态对齐是一项更具挑战性的pretext任务,它能迫使编码器学习更优的图像表征能力;深度自蒸馏不仅对瓶颈层,还对浅层提供监督,从而同时提升这两类层的性能。 对比实验表明,在预训练阶段,我们提出的CADS方法相较于同类自监督学习方法,计算复杂度更低,GPU内存消耗更少。基于预训练编码器,我们构建了用于三维CT体积分割的PVT-UNet模型。在七个下游任务(downstream task,指利用预训练模型进一步完成的具体目标任务)中的实验结果显示,PVT-UNet模型的性能优于MOCOv3、DiRA等当前主流的自监督学习方法,同时也优于nnUNet、CoTr等常用的医学图像分割方法。
Method
方法
A. Overview
The proposed CADS model follows the two-step SSLparadigm, which consists of unsupervised representation learning and fully supervised fine-tuning. In the pre-training step,we propose a challenging pretext task, which expands thepopular SSL paradigm through two strategies. First, we generate 2D X-ray images from 3D CT volumes and leveragethe inherent anatomical relationship between paired CT volumes and generated X-ray images to perform multi-modalalignment learning. Second, we present a deep self-distillationstrategy to enhance the supervision of the model’s shallowlayers by employing additional constraints on their presentation. To benefit from the rich information provided byboth CT volumes and generated X-ray images, we adopt aTransformer-based backbone to break the dimensional barrier.In the fine-tuning stage, the pre-trained encoder followedby a randomly initialized decoder and segmentation head isfine-tuned for downstream tasks. The pipeline of our CADSwas illustrated in Fig. 1. We now delve into the details of eachpart.
A. 概述 所提出的CADS模型遵循自监督学习(SSL)的两步范式,该范式包括无监督表征学习与全监督微调两个阶段。 在预训练阶段,我们设计了一项具有挑战性的辅助任务(pretext task),并通过两种策略拓展了主流的自监督学习范式:首先,从3D CT体积中生成2D X射线图像,利用配对的CT体积与生成的X射线图像之间固有的解剖学关联,进行多模态对齐学习;其次,提出深度自蒸馏策略,通过对模型浅层表征施加额外约束,增强对浅层的监督。为充分利用CT体积与生成的X射线图像所提供的丰富信息,我们采用基于Transformer的骨干网络(backbone),以突破维度限制。 在微调阶段,将预训练好的编码器与随机初始化的解码器及分割头(segmentation head)相结合,针对下游任务进行微调。CADS的流程如图1所示,下文将详细阐述各部分内容。
Conclusion
结论
In this paper, we design a more challenging pretext task,which aims to align the information in 3D CT volumes andthe corresponding 2D generated X-ray images, and extendself-distillation to deep self-distillation to enhance to representation supervision at the shallow layers of the encoder. Thuswe propose a novel SSL model called CADS and constructPVT-UNet based on the pre-trained encoder for 3D CT volumesegmentation. Comparative experiments show that, during pretraining, our CADS has lower computational complexity andGPU memory cost than competing SSL methods. Our resultson seven downstream CT volume segmentation tasks indicatethat PVT-UNet outperforms state-of-the-art SSL methods likeMOCOv3 and DiRA, as well as prevalent medical imagesegmentation methods like nnUNet and CoTr.
在本文中,我们设计了一项更具挑战性的辅助任务(pretext task),该任务旨在对齐3D CT体积与对应的2D生成X射线图像中的信息,并将自蒸馏扩展为深度自蒸馏,以增强对编码器浅层的表征监督。基于此,我们提出了一种名为CADS的新型自监督学习(SSL)模型,并利用预训练编码器构建了用于3D CT体积分割的PVT-UNet模型。对比实验表明,在预训练阶段,我们的CADS模型相较于同类自监督学习方法,计算复杂度更低,GPU内存消耗更少。在七个下游CT体积分割任务中的实验结果显示,PVT-UNet模型的性能优于MOCOv3、DiRA等当前主流自监督学习方法,同时也优于nnUNet、CoTr等常用医学图像分割方法。
Figure
图
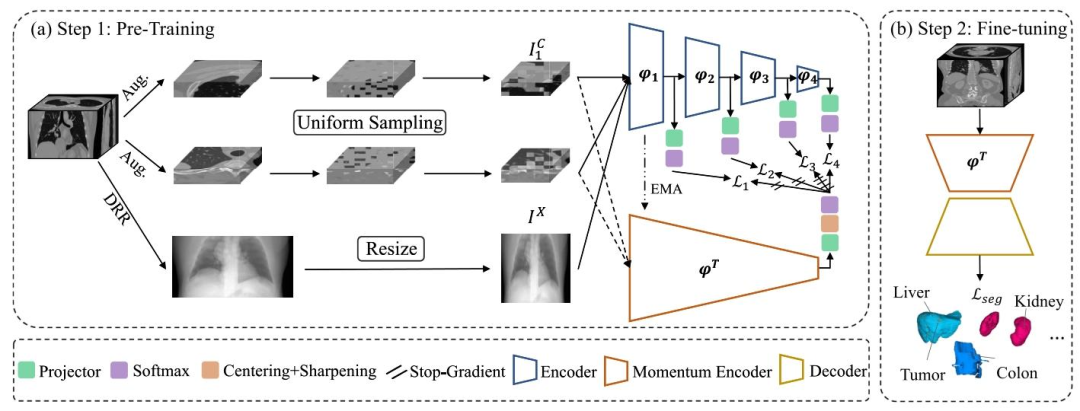
Fig. 1. Technical pipeline of our CADS model. (a) Step 1: Pre-training the encoder using the proposed challenging pretext task, which involvesdefining three views - two 3D images augmented from the same CT volume using a uniform sampling strategy and a generated 2D X-ray image - asinputs. The online encoder is decoupled into four stages, with each stage’s output encouraged to align with the output of the momentum encoder.(b) Step 2: Fine-tuning the pre-trained encoder along with a randomly initialized decoder on downstream datasets
图1 CADS模型技术流程 (a)步骤1:采用所提出的具有挑战性的辅助任务(pretext task)对编码器进行预训练。该任务将三个视图定义为输入,具体包括:通过均匀采样策略从同一CT体积增强得到的两幅3D图像,以及一幅生成的2D X射线图像。在线编码器(online encoder)被解耦为四个阶段,每个阶段的输出均需与动量编码器(momentum encoder)的输出对齐。 (b)步骤2:将预训练好的编码器与随机初始化的解码器结合,在下游数据集上进行微调。
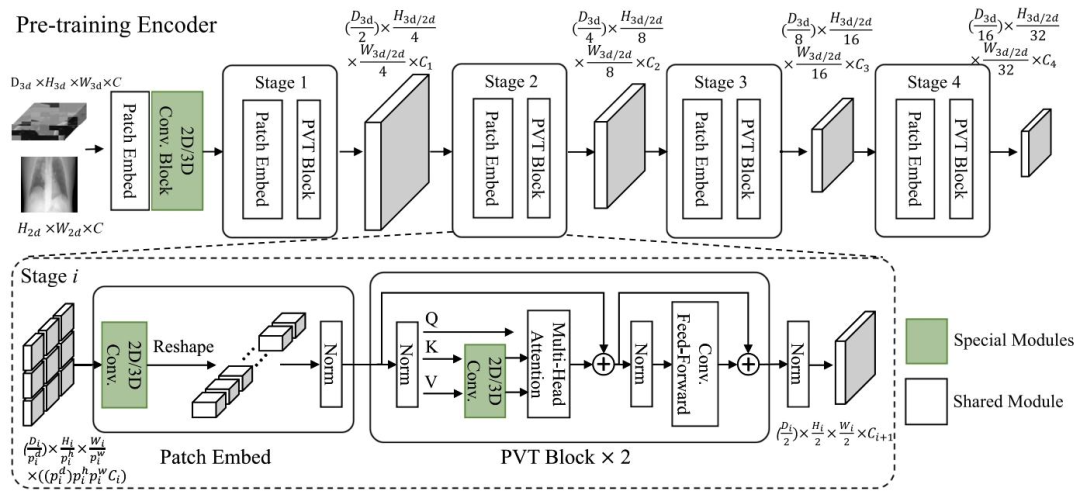
Fig. 2. Detailed architecture of our pre-training encoder. The first patch embedding is decoupled into two sub-modules, incorporating convolutionblocks to gradually reduce the resolution and mitigate rapid information loss. The dimension-sensitive modules are highlighted in green
图2 预训练编码器的详细架构 第一个补丁嵌入(patch embedding)被解耦为两个子模块,子模块中融入了卷积块(convolution blocks),以逐步降低分辨率并减缓信息的快速丢失。对维度敏感的模块(dimension-sensitive modules)用绿色突出显示。
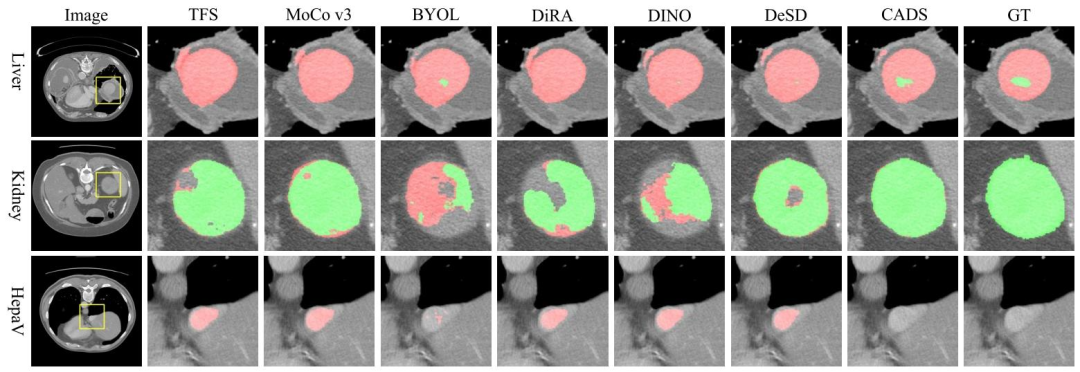
Fig. 3. Visualization of segmentation results obtained by PVT-UNet (TFS), five SSL methods, and our CADS, together with original CT slice andground truth. The regions of interest highlighted with yellow boxes in the 1 st Column are cropped from each segmentation result and ground truth,enlarged, and displayed in other columns. The organs and tumors are colored red and green, respectively
图3 PVT-UNet(TFS)、5种自监督学习(SSL)方法及我们的CADS模型所得到的分割结果可视化图,同时展示了原始CT切片与真值(ground truth)。第1列中用黄色方框突出显示的感兴趣区域(regions of interest)均从各分割结果及真值中裁剪提取,经放大后展示在其他列中。其中,器官和肿瘤分别用红色和绿色标注。
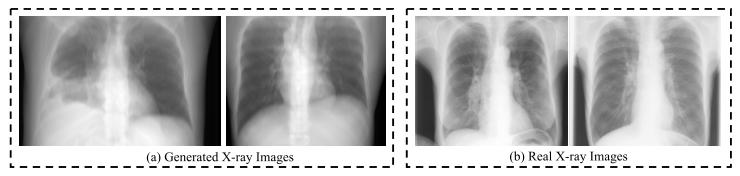
Fig. 4. Visualization of generated X-ray images from CT volumes of theDeepLesion dataset and real X-ray images from the JSRT dataset [67],[68]. Although blurrier than real ones, generated X-ray images still provideimportant anatomical information.
图4 DeepLesion数据集CT体积生成的X射线图像与JSRT数据集[67]、[68]中真实X射线图像的可视化对比 尽管生成的X射线图像比真实图像更模糊,但仍能提供重要的解剖学信息。
Table
表
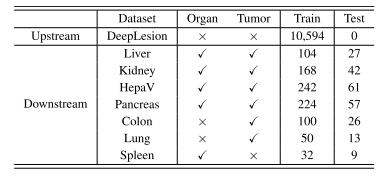
TABLE IOVERVIEW OF EIGHT DATASETS USED FOR THIS STUDY
表 1 本研究使用的 8 个数据集概述
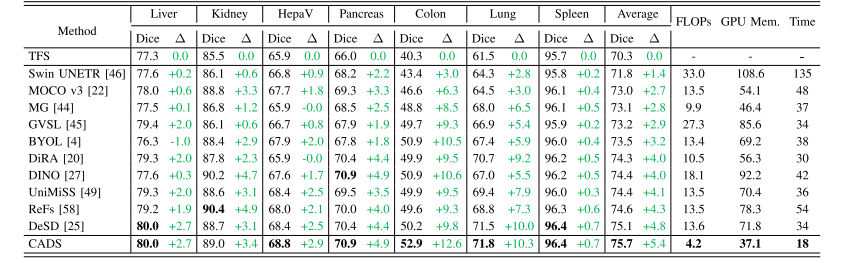
TABLE IIPERFORMANCE AND COMPLEXITY OF OUR CADS AND TEN SSL METHODS ON SEVEN 3D SEGMENTATION DATASETS. THE BEST RESULT INEACH COLUMN IS HIGHLIGHTED WITH BOLD.TFS: PVT-UNET TRAINED FROM SCRATCH;∆: PERFORMANCE GAIN OVER TFS
表2 我们的CADS模型与10种自监督学习(SSL)方法在7个3D分割数据集上的性能及复杂度对比。每列中的最佳结果以粗体突出显示。TFS:从零开始训练的PVT-UNet模型;∆:相较于TFS模型的性能提升幅度
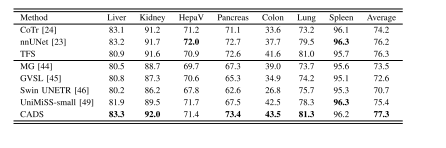
TABLE IIIPERFORMANCE OF THREE ADVANCED TRADITIONAL SEGMENTATIONMETHODS AND FIVE PRE-TRAINED SEGMENTATION METHODS ONSEVEN 3D SEGMENTATION DATASETS. TFS: PVT-UNET TRAINEDFROM SCRATCH. THE BEST RESULT IN EACH COLUMNIS HIGHLIGHTED WITH BOLD
表3 三种先进的传统分割方法与五种预训练分割方法在七个3D分割数据集上的性能对比。TFS:从零开始训练的PVT-UNet模型。每列中的最佳结果以粗体突出显示

TABLE IVPERFORMANCE OF OUR CADS, THREE SEGMENTATION METHODS (NNUNET, COTR, AND TFS), AND SSD ON SEVEN 3D SEGMENTATIONDATASETS WHEN USING 10%, 50%, OR 100% TRAINING DATA. TFS: PVT-UNET TRAINED FROM SCRATCH; SSD: SINGLESELF-DISTILLATION (OUR SSL BASELINE).THE BEST RESULT IN EACH COLUMN IS HIGHLIGHTED WITH BOLD
表4 当使用10%、50%或100%训练数据时,我们的CADS模型、三种分割方法(nnUNet、CoTr和TFS)以及SSD方法在七个3D分割数据集上的性能对比。TFS:从零开始训练的PVT-UNet模型;SSD:单一自蒸馏(我们的自监督学习基准模型)。每列中的最佳结果以粗体突出显示

TABLE VABLATION STUDIES OF PROPOSED STRATEGIES, i.e., UNIFORM SAMPLING (US), CROSS-MODAL ALIGNMENT (CMA), AND DEEPSELF-DISTILLATION LEARNING (DEEP SD). THE BEST RESULT IN EACH COLUMN IS HIGHLIGHTEDWITH BOLD. SSD: SINGLE SELF-DISTILLATION
表5 所提策略的消融实验结果,即均匀采样(US)、跨模态对齐(CMA)与深度自蒸馏学习(DEEP SD)。每列中的最佳结果以粗体突出显示。SSD:单一自蒸馏

TABLE VIPERFORMANCE OF VANILLA PVT-UNET AND PVT-UNET ON SEVEN3D SEGMENTATION DATASETS.THE BEST RESULT IN EACHCOLUMN IS HIGHLIGHTED WITH BOLD
表6 基础版PVT-UNet与(改进版)PVT-UNet在七个3D分割数据集上的性能对比。每列中的最佳结果以粗体突出显示
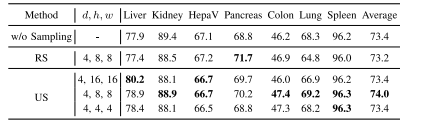
TABLE VIIPERFORMANCE OF VARIANTS OF CADS WITHOUT SAMPLING, WITHRANDOM SAMPLING (RS), OR WITH UNIFORM SAMPLING (US) ONSEVEN DATASETS. THE BEST RESULT IN EACH COLUMN ISHIGHLIGHTED WITH BOLD.d × h × w: PATCH SIZEUSED IN SAMPLING STRATEGIES
表7 无采样、随机采样(RS)及均匀采样(US)三种条件下的CADS变体模型在七个数据集上的性能对比。每列中的最佳结果以粗体突出显示。注:d × h × w 表示各采样策略中使用的补丁块(patch)尺寸。
TABLE VIIIPERFORMANCE OF BASELINE AND BASELINE WITH MULTI-CROPLEARNING, MEAN CT, GENERATED MRI, OR PROPOSED CMA ONSEVEN DOWNSTREAM DATASETS.BASELINE: SSD WITH US.THEBEST RESULT IN EACH COLUMN IS HIGHLIGHTED WITH BOLD
表8 基准模型以及融合多裁剪学习(multi-crop learning)、平均CT(mean CT)、生成磁共振图像(generated MRI)或所提跨模态对齐(CMA)策略的基准模型在七个下游数据集上的性能对比。基准模型(BASELINE):采用均匀采样(US)的单一自蒸馏(SSD)模型。每列中的最佳结果以粗体突出显示
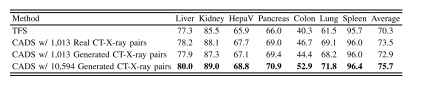
ABLE IXPERFORMANCE OF TFS, CADS USING 1,013 REAL OR GENERATEDCT-X-RAY PAIRS FROM THE COVID19-CT DATASET, AND CADSUSING 10,594 GENERATED CT-X-RAY PAIRS FROM THEDEEPLESION DATASET.THE BEST RESULT IN EACHCOLUMN IS HIGHLIGHTED WITH BOLD
表9 TFS模型、使用COVID19-CT数据集1013组真实或生成CT-X射线配对数据的CADS模型,以及使用DeepLesion数据集10594组生成CT-X射线配对数据的CADS模型的性能对比。每列中的最佳结果以粗体突出显示 (说明:原标题“ABLE IX”应为“TABLE IX”的拼写误差,已按学术表格编号规范修正为“表9”;明确区分了不同CADS模型所用的数据集来源、数据类型及数据量,清晰体现实验变量差异,符合学术表格标题的信息完整性要求。)

技术共进,成长同行——讯飞AI开发者社区
更多推荐



 6
6 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)