
面向复杂决策的AI Agent深度协同与信息共享机制
在人工智能的发展过程中,AI Agent 已经逐渐从单一任务执行者演化为具备自主学习、协作和推理能力的智能体。在应对复杂决策场景(如智能制造、金融交易、灾害应急、智能交通)时,仅依赖单个 Agent 的计算与感知能力往往难以满足高效、鲁棒的决策需求。
面向复杂决策的AI Agent深度协同与信息共享机制
引言
在人工智能的发展过程中,AI Agent 已经逐渐从单一任务执行者演化为具备自主学习、协作和推理能力的智能体。在应对复杂决策场景(如智能制造、金融交易、灾害应急、智能交通)时,仅依赖单个 Agent 的计算与感知能力往往难以满足高效、鲁棒的决策需求。
因此,构建 多智能体(Multi-Agent System, MAS) 的深度协同机制,以及高效的信息共享方式,成为提升 AI Agent 在复杂环境中决策质量的重要研究方向。
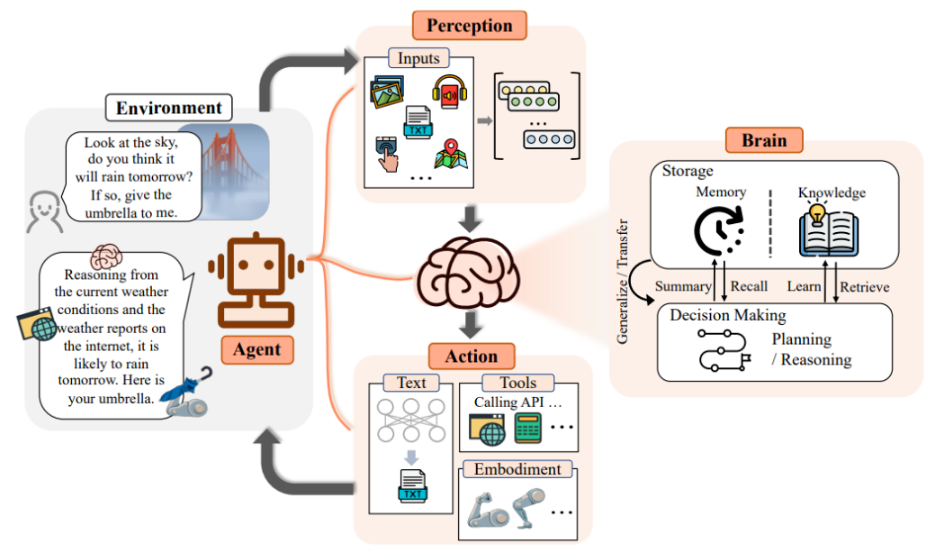
深度协同机制的理论框架
1. 多智能体复杂决策的挑战
- 异构性:不同 Agent 可能具有不同的感知能力与计算能力;
- 动态性:环境随时间变化,信息随时可能过期;
- 不完全信息:单个 Agent 难以获得全局信息,存在信息不对称;
- 冲突与博弈:Agent 间目标可能不同,存在博弈与竞争。
2. 深度协同的核心思想
深度协同机制旨在通过 策略共享、信息共享和任务分解 来提升整体系统的智能水平,主要包括:
- 共享表示学习:利用深度学习提取共享特征空间;
- 协同决策:通过联合策略梯度、分布式强化学习等方法优化全局收益;
- 信息共享协议:采用通信机制或知识图谱促进信息传递。
信息共享机制设计
1. 通信协议
多 Agent 系统需要通过通信机制共享关键信息:
- 集中式通信:通过中心节点聚合信息,但存在瓶颈;
- 去中心化通信:通过点对点消息传递,鲁棒性更强;
- 图神经网络(GNN)建模:通过图结构建模信息传递,适合动态交互。
2. 信息融合策略
- 基于加权平均:不同 Agent 的信息加权求和;
- 基于注意力机制:动态分配不同 Agent 的重要性;
- 基于知识蒸馏:将强 Agent 的知识迁移给弱 Agent。

实战案例:基于多智能体的协同路径规划
我们以 无人机编队协同路径规划 为例,展示如何通过深度协同与信息共享机制提升复杂决策性能。
代码实现(Python + PyTorch 示例)
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# ====== 定义多智能体通信网络 ======
class CommNet(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_agents):
super(CommNet, self).__init__()
self.num_agents = num_agents
self.encoder = nn.Linear(input_dim, hidden_dim)
self.comm = nn.Linear(hidden_dim, hidden_dim)
self.policy = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# x: [num_agents, input_dim]
h = torch.relu(self.encoder(x))
# 信息共享:取平均(简单实现)
comm_message = torch.mean(h, dim=0, keepdim=True).repeat(self.num_agents, 1)
h = h + torch.relu(self.comm(comm_message))
out = self.policy(h)
return out
# ====== 模拟环境与训练 ======
num_agents = 3
input_dim = 4 # (x, y, vx, vy)
hidden_dim = 32
output_dim = 2 # (ax, ay)
epochs = 200
model = CommNet(input_dim, hidden_dim, output_dim, num_agents)
optimizer = optim.Adam(model.parameters(), lr=0.01)
loss_fn = nn.MSELoss()
# 模拟目标:每个无人机都向目标点 (5, 5) 靠拢
target = torch.tensor([5.0, 5.0])
for epoch in range(epochs):
# 随机初始化无人机状态
state = torch.rand((num_agents, input_dim)) * 10 # [0,10) 范围内
actions = model(state) # 输出控制加速度
# 更新位置 (简单模拟)
new_state = state[:, :2] + actions
# 计算损失:与目标点距离
loss = loss_fn(new_state, target.expand(num_agents, -1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 50 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
代码解析
- CommNet 网络:模拟多 Agent 信息共享机制,通过通信层进行共享特征融合;
- 训练目标:无人机协同靠近目标点
(5,5); - 信息共享方式:采用简单的 平均信息聚合,在实际场景可扩展为 注意力机制 或 图神经网络。
深度协同与信息共享的优化方向
1. 基于图神经网络的通信
使用 GNN 建模多 Agent 间的动态拓扑关系,提升信息传递效率。
2. 基于强化学习的联合策略优化
在多 Agent 强化学习(MARL)框架下,利用集中训练、分散执行(CTDE)机制提升决策质量。
3. 基于知识图谱的知识共享
通过共享领域知识(如环境地图、敌我关系),提升推理与规划的效率。
多智能体深度协同的算法框架
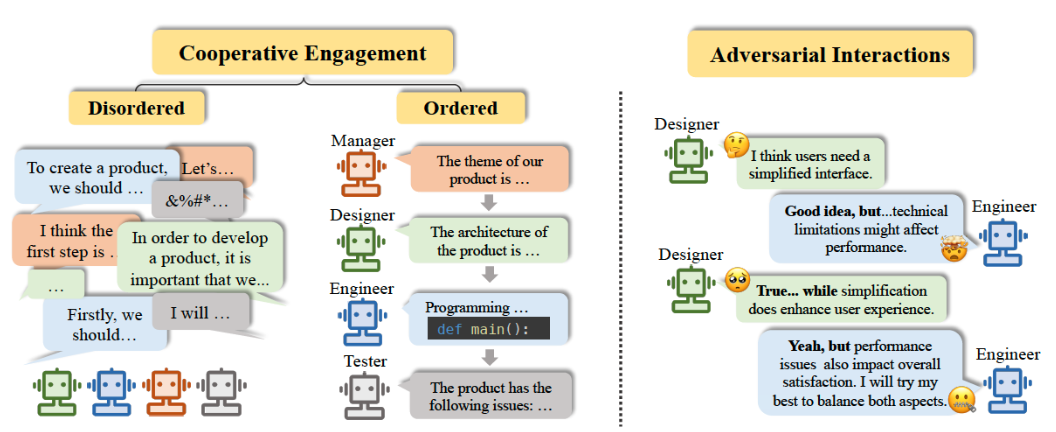
1. 集中训练、分布执行(CTDE)框架
在多智能体系统中,最常见的范式是 集中训练、分布执行(Centralized Training with Decentralized Execution, CTDE)。
- 集中训练:在训练阶段,所有 Agent 的全局状态与动作都可以用于优化;
- 分布执行:在执行阶段,每个 Agent 仅依赖于局部观测与共享信息进行决策。
这种框架避免了信息孤岛,同时确保了系统的可扩展性与鲁棒性。
典型方法:
- MADDPG(Multi-Agent Deep Deterministic Policy Gradient):多智能体的策略梯度算法;
- QMIX:基于值函数分解的协同强化学习方法;
- VDN(Value Decomposition Networks):通过加法分解实现团队奖励的共享。
2. 注意力机制在信息共享中的应用
在复杂环境下,信息量庞大,如何筛选出对决策有价值的信息是关键。
- 自注意力机制(Self-Attention):每个 Agent 根据上下文权重选择性关注其他 Agent 的信息;
- 跨 Agent 注意力(Cross-Agent Attention):不同 Agent 间的消息传递采用可学习权重,而非简单加权平均。
这种机制能避免冗余通信,提高共享信息的有效性。
下面给出一个 基于注意力的信息共享代码实例。
import torch
import torch.nn as nn
# ====== 注意力信息共享层 ======
class AttentionComm(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(AttentionComm, self).__init__()
self.query = nn.Linear(input_dim, hidden_dim)
self.key = nn.Linear(input_dim, hidden_dim)
self.value = nn.Linear(input_dim, hidden_dim)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
# x: [num_agents, input_dim]
Q = self.query(x) # [num_agents, hidden_dim]
K = self.key(x) # [num_agents, hidden_dim]
V = self.value(x) # [num_agents, hidden_dim]
# 注意力权重计算
scores = torch.matmul(Q, K.T) / (K.shape[-1] ** 0.5) # [num_agents, num_agents]
attn_weights = self.softmax(scores)
# 聚合信息
out = torch.matmul(attn_weights, V) # [num_agents, hidden_dim]
return out
这个模块可以直接替换之前 CommNet 中的简单平均聚合部分,从而让每个 Agent 在通信时能够“有选择地关注”对其决策最有帮助的其他 Agent。
深度协同在复杂场景中的应用
1. 智能交通系统
在自动驾驶场景中,不同车辆(Agent)需要共享 道路信息、交通信号、意图预测 等数据。
- 协同优势:减少交通冲突,优化交通流;
- 实现方式:基于 V2X(Vehicle-to-Everything)通信 + 多智能体强化学习。
2. 智能电网调度
在智能电网中,多个电力节点作为 Agent,需要实时协调以平衡供需。
- 协同优势:降低能耗波动,提高能源利用效率;
- 实现方式:基于图神经网络的信息共享机制。
3. 多机器人协作
在仓储物流或灾害救援中,多机器人需要协同完成复杂任务:
- 协同优势:提升覆盖率,减少重复工作;
- 实现方式:基于协作强化学习的路径规划与任务分配。
强化学习中的信息共享策略
1. 联合价值函数
在 QMIX 或 VDN 中,多个 Agent 的个体价值函数被组合成一个全局价值函数:
Qtot(s,a)=f(Q1,Q2,...,Qn) Q_{tot}(s, a) = f(Q_1, Q_2, ..., Q_n) Qtot(s,a)=f(Q1,Q2,...,Qn)
其中 fff 是分解函数,用于保证可分解性。
2. 策略共享与迁移学习
当部分 Agent 已经学会高效策略时,可以通过 策略蒸馏 或 参数共享 将其迁移给其他 Agent,从而加快整体学习效率。
3. 部分可观测马尔可夫决策过程(POMDP)
在大多数真实场景中,Agent 只能观测到局部信息,因此需要通过共享通信补充信息缺口,使得整体逼近全局可观测的 MDP 环境。
结论
本文提出并分析了 面向复杂决策的AI Agent深度协同与信息共享机制,并通过 无人机协同路径规划实验 展示了多 Agent 系统在复杂任务中的应用潜力。未来的研究可以结合 图神经网络、强化学习和知识蒸馏,进一步提升 AI Agent 在动态环境中的 鲁棒性与智能协作能力。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 7
7 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)