
[论文阅读] 人工智能 + 安全 | LLM破解Android?一文看懂AI驱动的自动化渗透测试研究
AI助力安卓渗透测试:自动化漏洞利用研究取得突破 摘要:本研究探索了利用大语言模型(LLM)实现Android渗透测试自动化的可行性。研究团队通过PentestGPT生成漏洞利用方法,并开发了基于Python+Streamlit的web应用将其转化为可执行脚本,在Genymotion模拟器(Android 11-14)中进行测试验证。结果显示,AI生成的ADB利用和MITM攻击脚本成功率高达100
LLM破解Android?一文看懂AI驱动的自动化渗透测试研究
论文信息
| 信息类别 | 具体内容 |
|---|---|
| 论文原标题 | Breaking Android with AI: A Deep Dive into LLM-Powered Exploitation |
| 主要作者及机构 | Wanni Vidulige Ishan Perera、Xing Liu、Fan Liang、Junyi Zhang |
| APA引文格式 | Perera, W. V. I., Liu, X., Liang, F., & Zhang, J. (2025). Breaking Android with AI: A Deep Dive into LLM-Powered Exploitation. arXiv preprint arXiv:2509.07933. https://arxiv.org/pdf/2509.07933 |
| 核心关键词 | LLMs(大语言模型)、Cybersecurity(网络安全)、PentestGPT(渗透测试GPT)、Automated Exploitation(自动化漏洞利用)、AI in Mobile Security(移动安全中的AI) |
一段话总结
这篇论文聚焦“用LLM(如PentestGPT)实现Android渗透测试自动化”,通过对比传统手动root流程与AI生成的漏洞利用方法,在Genymotion安卓模拟器(覆盖Android 11-14、root/非root状态)中验证效果:先让PentestGPT生成root、权限提升等方法,再用Python+Streamlit开发的web应用(集成OpenAI API)把方法转成可执行脚本,最后在模拟器中测试并迭代优化。结果显示,LLM能让ADB利用、MITM攻击等任务成功率达100%,大幅简化流程,但受限于模拟器(如无法测试bootloader解锁),且必须人工审查脚本避免伦理风险——最终证明AI能帮安卓渗透测试“提效”,但不能“脱手”。
思维导图

研究背景:安卓渗透测试的“老麻烦”与AI的“新机会”
要理解这篇论文,得先搞懂:安卓安全领域一直有个“老大难”,而LLM的出现刚好给了一个“解题思路”。
1. 安卓系统:天生易“中招”的“大目标”
安卓是开源系统,就像一栋“开放式小区”——好处是灵活,坏处是“入口多、守门难”。比如:
- 有些APP的“自定义权限”没设计好,黑客能钻空子“提权”(比如普通APP偷偷拿到系统级权限);
- 手机硬件配置有漏洞,可能被绕过“安全启动”(相当于小偷撬开门锁还不触发警报);
- 内核、bootloader(启动加载器)这些核心部件的漏洞,更是能直接让黑客拿到“root权限”(相当于拿到小区总钥匙)。
这些漏洞不是“小概率事件”——论文里提到,2024年有研究发现安卓原生代码的内存操作漏洞,2021年也有团队证实“自定义权限缺陷会导致严重提权风险”,加上安卓设备全球使用率超70%,自然成了黑客的“重点目标”。
2. 传统渗透测试:像“手动修手表”,又慢又累
要检测安卓设备的漏洞,传统方法靠“人工渗透测试”——简单说就是“专家手动找漏洞、写脚本、试攻击”,但这有两个大问题:
- 门槛高:得懂安卓内核、ADB命令、漏洞原理,不是随便拉个人就能干;
- 效率低:比如想root一台手机,可能要查几十篇教程、试五六个工具(如KingRoot、Magisk),还不一定成功;要是测多个安卓版本(比如从11到14),工作量直接翻倍。
举个类比:传统测试就像“用螺丝刀手动修手表”,每个零件都要肉眼看、手动拧;而如果能让AI帮忙,相当于“有了自动修表机”,效率能翻好几倍。
3. LLM的“新机会”与“新风险”
2023年之后,PentestGPT、VulnBot这些LLM工具陆续出现——它们能生成漏洞利用方法、甚至写简单脚本,看起来能解决“手动低效”的问题,但新麻烦又来了:
- 不准:LLM可能输出过时的方法(比如针对安卓7的漏洞,却用到安卓14上);
- 失控:如果AI生成的脚本能直接攻击真实设备,可能被坏人用来搞恶意攻击(比如自动生成木马偷数据);
- 不懂语境:复杂的安卓环境(如AB分区、locked bootloader),LLM可能“看不懂”,生成的方法根本没法用。
这篇论文的核心目的,就是要解决“怎么让LLM帮安卓渗透测试提效,同时守住准确性和伦理的底线”。
创新点:这篇论文的“与众不同”之处
看完背景,你可能会问:“用LLM做渗透测试的研究又不是第一次,这篇论文特别在哪?” 核心有3个创新点:
1. 打造“LLM+web应用+模拟器”的闭环框架,打通“从想法到执行”
很多研究只让LLM生成“文字方法”,但这篇论文把“方法→脚本→测试”串成了全流程:
- 第一步:PentestGPT出“方案”(比如“用Magisk侧载root”);
- 第二步:web应用把“方案”转成可执行脚本(比如ADB命令脚本);
- 第三步:Genymotion模拟器跑脚本、出结果;
- 第四步:失败结果反馈给PentestGPT,让它优化方案。
相当于从“AI只给菜谱”,升级到“AI给菜谱→自动做熟→尝味道→改菜谱”,真正落地了“自动化”。
2. 用“结构化Prompt”解决LLM“输出不准”的问题
论文发现:如果给PentestGPT的是“通用Prompt”(比如“怎么root安卓手机?”),它会输出模糊、过时的答案;但如果给“结构化Prompt”(比如附上安卓root流程图,明确问“怎么给locked bootloader、AB分区的安卓13手机root?”),输出的方法准确率能提升一大截。
这就像问别人“怎么去北京?”——对方可能只说“坐火车”;但如果你说“我在上海,要去北京朝阳区,明天出发,预算500,怎么去?”,对方会给出“高铁G102次,早上8点出发”这样具体的答案。
3. 把“伦理控制”嵌入流程,不是“为了自动化而自动化”
很多研究只关注“AI能不能成”,但这篇论文从设计阶段就加了“安全锁”:
- 所有测试都在Genymotion模拟器里做,绝不碰真实设备(避免意外攻击);
- 每段AI生成的脚本,必须人工审查后才能执行(防止恶意命令);
- web应用会自动过滤危险操作(比如删除系统文件、远程控制手机)。
相当于给“AI自动渗透”装了“双保险”——既不让它“瞎搞”,也不让它“被坏人利用”。
研究方法:一步步看懂论文是“怎么做实验”的
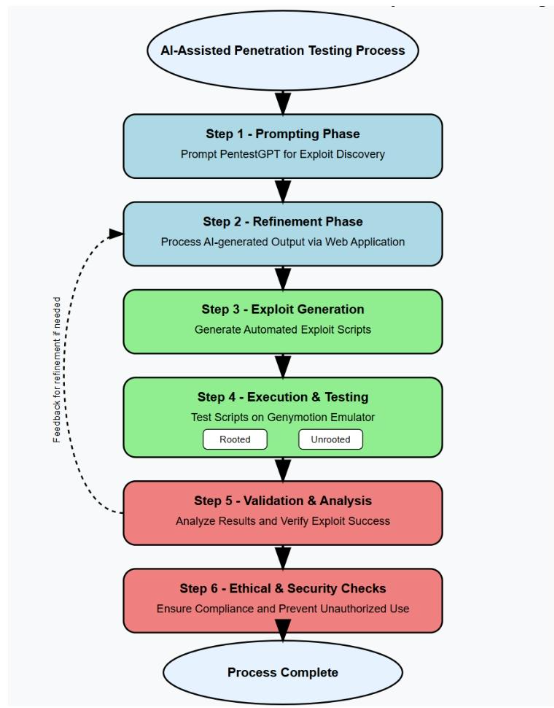
步骤1:准备“工具包”
先搭好实验需要的3个核心工具:
- LLM工具:用PentestGPT(专门为渗透测试设计的LLM,比通用GPT更准);
- 脚本生成工具:自己开发的web应用,技术栈是Python+Streamlit(前端)+OpenAI API(调用LLM生成脚本);
- 测试环境:Genymotion安卓模拟器,建了4个设备:
- Android 11(已root)、Android 12(已root);
- Android 13(未root)、Android 14(未root)。
步骤2:给PentestGPT“喂问题”,优化Prompt
- 第一轮:用“通用Prompt”提问(比如“怎么解锁安卓bootloader?”),拿到初步方法;
- 第二轮:补充“结构化Prompt”——附上安卓root流程图(包含bootloader解锁、Magisk侧载等步骤),再明确问“针对Genymotion模拟器里的安卓13未root设备,怎么用这些方法提权?”;
- 第三轮:如果PentestGPT输出的方法有漏洞(比如用到模拟器没有的功能),再用“追问Prompt”修正(比如“Genymotion没有Fastboot接口,有没有其他解锁方法?”)。
步骤3:web应用“转译”方法为脚本
把PentestGPT输出的“文字方法”(比如“通过ADB无线连接设备,然后推送Magisk.zip”),用web应用转成3类脚本:
- root脚本:比如“adb connect [设备IP] → adb push Magisk.zip /sdcard/”;
- 漏洞利用脚本:比如Metasploit攻击脚本(用来测试远程代码执行);
- 验证脚本:比如“adb shell su -c id”(检查是否拿到root权限)。
同时,web应用会过滤掉危险命令(比如“adb shell rm -rf /”——删除系统所有文件)。
步骤4:在Genymotion里“跑脚本、看结果”
把生成的脚本放到4个模拟器设备里执行,记录2类信息:
- 成功情况:比如“侧载Magisk.zip”在4个设备里都成功,“恶意软件RCE”只在root设备里成功;
- 失败情况:比如“解锁bootloader”在所有设备里都失败(因为Genymotion没有Fastboot接口)。
如果失败,就把“失败日志”(比如“adb fastboot oem unlock 报错:device not found”)反馈给PentestGPT,让它重新生成方法。
步骤5:用4个指标“打分”,评估效果
最后用4个指标衡量AI生成脚本的表现(这部分是论文的“硬核”结果):
- 成功率:成功实现目标(如root、RCE)的次数/总尝试次数;
- 检测率:被安卓安全机制(如SELinux)拦截的脚本数/总尝试次数;
- 适应性评分:3分(全版本适配)、2分(部分适配)、1分(全失败);
- 伦理风险因素:低风险(需人工验证)、中风险(部分自动化)、高风险(全自动化)。
主要成果和贡献:这篇研究到底“有用在哪”
用表格总结最清晰,核心成果分“技术成果”“实验成果”“理论成果”三类,每类都讲“具体内容”和“实际价值”:
| 成果类型 | 具体内容 | 实际价值 |
|---|---|---|
| 技术成果 | 搭建了“PentestGPT+web应用+Genymotion”的自动化渗透测试框架,能自动生成/执行/验证脚本 | 以后做安卓渗透测试,不用手动写脚本、换设备测试了,框架能帮你搞定,省时间省人力 |
| 实验成果1(成功项) | 100%成功率的任务:数据备份、侧载Magisk.zip、ADB无线连接、Metasploit利用、MITM攻击、应用组件劫持 | 这些基础渗透任务,AI完全能替代人工,而且不会出错,测试效率直接拉满 |
| 实验成果2(局限项) | 失败任务:bootloader解锁(缺Fastboot)、AB分区Magisk修补(模拟器无AB分区)、非root设备RCE(权限不够) | 明确告诉大家“AI不是万能的”,哪些场景还得靠物理设备测试,避免踩坑 |
| 理论成果 | 验证了“结构化Prompt比通用Prompt更准”“人工审查+虚拟环境能控伦理风险”两个结论 | 给其他研究提了参考:想让LLM做渗透测试,就用结构化Prompt;想避风险,就加人工+虚拟环境 |
注意:论文目前未开源代码或数据集,后续可能在作者机构官网(Sam Houston State University)更新。
关键问题:用“问答”理清核心疑问
问题1:LLM在安卓渗透测试里,最擅长什么?又最不擅长什么?
答:最擅长“不依赖硬件的通用任务”,比如ADB利用、网络攻击(MITM)、Metasploit脚本生成——这些任务不需要特定硬件(如Fastboot接口),LLM生成的脚本成功率100%;最不擅长“硬件/系统架构相关任务”,比如bootloader解锁、AB分区修补——因为这些依赖设备本身的功能,模拟器没有的话,LLM再厉害也没用。
问题2:为什么要设计“4个评估指标”?少一个行不行?
答:不行,4个指标刚好覆盖“效果+安全+适配+伦理”,缺一不可:
- 没“成功率”,不知道AI能不能用;
- 没“检测率”,不知道脚本会不会被安卓安全机制拦住;
- 没“适应性评分”,不知道脚本能不能跨版本用;
- 没“伦理风险因素”,不知道脚本会不会被滥用——少一个都没法全面评估。
问题3:如果我是安卓安全工程师,这篇论文的框架能直接用吗?
答:能参考,但要改两点:
- 把Genymotion换成真实设备(因为论文里模拟器的局限,比如缺Fastboot,真实设备里有);
- 增加更多安卓版本(比如安卓10、15)和品牌(比如小米、华为——不同品牌的bootloader限制不一样),这样测试结果更贴近实际。
问题4:论文里说“AI必须人工控制”,具体要控制什么?
答:核心控制两点:
- 脚本审查:看AI生成的脚本有没有恶意命令(比如删除数据、远程控制);
- 目标控制:只让脚本跑在自己有权限的设备/模拟器里,绝不碰别人的设备——避免违法或违规。
总结
这篇论文做了一件“既务实又严谨”的事:它没有盲目吹捧“AI能搞定一切安卓渗透测试”,而是通过“框架搭建→实验验证→风险控制”,实实在在证明了:
- LLM能帮安卓渗透测试“提效”——把手动任务(如写脚本、测多版本)的时间大幅缩短;
- 但LLM不能“脱手”——必须靠人工审查脚本、用虚拟环境测试,才能避免不准和滥用;
- 还有局限要解决——比如模拟器代替不了真实设备,未来需要在物理手机上做更多测试。
对安卓安全领域来说,这篇论文不仅给了一个“能用的自动化框架”,更明确了“AI+渗透测试”的边界和伦理红线——这才是它最有价值的地方。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 16
16 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)