
500篇参考文献100页综述!大语言模型的进化之路,从文本生成到自主决策的五大跃迁与六大核心能力!
本文系统梳理了智能体强化学习(Agentic RL)如何让大语言模型从"文本生成器"进化为"自主决策智能体"。通过五大维度的范式跃迁和六大核心能力(规划、工具使用、记忆、自我改进、推理、感知),Agentic RL使LLMs能在搜索、代码开发、数学推理等真实场景中自主解决问题。尽管面临可信度、训练规模化和环境规模化三大挑战,Agentic RL正引领大模型向通用人工智能伙伴迈进,是通往AGI的关键
简介
本文系统梳理了智能体强化学习(Agentic RL)如何让大语言模型从"文本生成器"进化为"自主决策智能体"。通过五大维度的范式跃迁和六大核心能力(规划、工具使用、记忆、自我改进、推理、感知),Agentic RL使LLMs能在搜索、代码开发、数学推理等真实场景中自主解决问题。尽管面临可信度、训练规模化和环境规模化三大挑战,Agentic RL正引领大模型向通用人工智能伙伴迈进,是通往AGI的关键一步。
当你向大模型提出“写一份2024年全球AI产业调研报告”的需求时,你是否想过:如果模型能自主打开浏览器搜索最新数据、筛选权威来源、整合多领域信息,甚至根据你的反馈迭代修改报告结构,而无需你逐一步骤指导——这样的“自主AI助手”离我们还有多远?
事实上,人工智能领域正朝着这个方向加速迈进。过去两年,大语言模型(LLMs)的发展经历了从“文本续写”到“指令跟随”的跨越,但传统的强化学习方法(如RLHF)仍将LLMs束缚在“被动输出”的框架中:模型只能根据人类给定的prompt生成单轮回答,无法主动与环境交互、规划长期任务、修正自身错误。这种局限性,让LLMs在复杂真实场景中难以发挥更大价值。
近期,来自20余所顶尖机构的研究者,联合发布了一篇重磅综述。这篇长达100页的综述,不仅整合了2023-2025年间500余篇最新研究成果,更首次清晰界定了**智能体强化学习(Agentic RL)**这一新兴领域的核心范式,为LLMs从“文本生成器”向“自主决策智能体”的进化,绘制了完整的技术地图。

- 论文标题:The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
- 论文链接:https://arxiv.org/pdf/2509.02547
对于Agent开发者而言,这篇综述是把握领域前沿的“导航手册”——它系统梳理了Agentic RL与传统LLM-RL的本质差异,从“核心能力”与“任务场景”双重视角构建理论框架,并指出了通向通用AI智能体的关键挑战;对于工程师而言,它是技术落地的“工具箱”——汇总了开源环境、RL框架与典型案例,降低了从理论到实践的门槛;而对于关注AI未来的普通人而言,这篇综述揭示了一个重要趋势:LLMs正在突破“工具属性”,逐步具备“自主思考、主动行动”的能力,未来的AI助手将不再是“被动响应者”,而是能与人类协同解决复杂问题的“合作伙伴”。
接下来,笔者将从范式跃迁、核心能力、任务落地、技术挑战四个维度,总结这篇综述的核心内容,带领大家全面理解Agentic RL如何重塑LLM的未来。
点击下方卡片,关注“大模型之心Tech”公众号
范式跃迁:从“单步对齐”到“多步决策”,LLM角色彻底重构
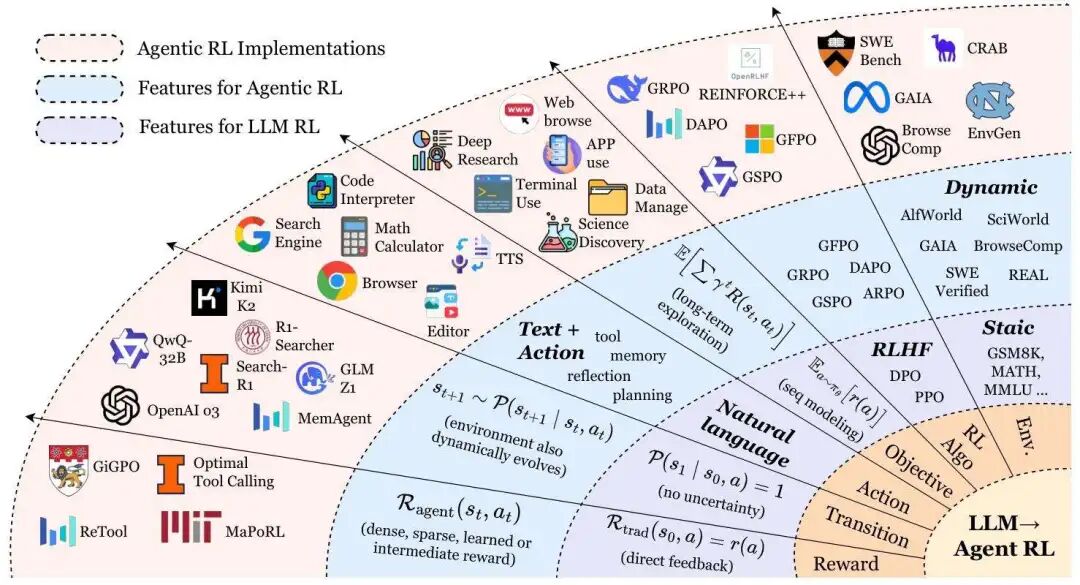
从大语言模型强化学习(LLM-RL)到智能体强化学习(Agentic RL)的范式转变
在ChatGPT、Claude等模型风靡全球后,研究者逐渐发现传统LLM-RL(如RLHF)的局限性——这类方法本质上是将LLMs视为“静态序列生成器”,仅优化单轮输出与人类偏好的对齐,比如让回答更符合伦理规范或更流畅。但在真实世界中,人类解决问题往往需要多步推理、工具调用与环境交互,例如“写一份调研报告”需要搜索资料、整合信息、逻辑梳理等一系列操作,传统LLM-RL根本无法应对。
正是这种需求催生了Agentic RL的诞生。综述将这一转变定义为“从退化MDP到POMDP的范式跃迁”,其中的核心差异可通过五个关键维度清晰区分:
1. 状态空间(State Space):从“单一提示”到“动态世界”
传统LLM-RL的状态空间极为简单,通常只有“初始提示(s₀)”这一个状态——模型接收一个问题,输出一个回答后,交互立即终止,对应“任务 horizon T=1”。例如在RLHF中,模型仅需根据用户输入的单条prompt,生成符合偏好的回复即可。
而Agentic RL则将LLM置于一个动态、部分可观测的环境中,状态会随时间不断演进。以“网页搜索调研”任务为例,初始状态是“用户需求+空白搜索页面”,当LLM调用搜索工具获取信息后,状态会更新为“用户需求+搜索结果页面”,后续每一步操作(如点击链接、二次搜索)都会推动状态变化,任务 horizon T远大于1。此时,LLM需要根据不断变化的环境状态调整决策,而非仅依赖初始prompt。
2. 动作空间(Action Space):从“纯文本”到“文本+交互”
传统LLM-RL的动作空间仅限于“生成文本序列”,模型的输出无法直接与外部环境交互。而Agentic RL将动作空间扩展为“文本动作(A_text)+结构化动作(A_action)”的集合:
- A_text:生成自然语言,用于沟通或记录,如“总结当前搜索到的关键信息”;
- A_action:通过特殊Token(<action_start>/<action_end>)界定的可执行指令,如调用搜索工具(call(“search”, “2024全球AI市场规模”))、控制GUI界面(click(“下载报告按钮”))、操作机器人(move(“north”))。
这种扩展让LLM从“只能说话”进化为“既能说话又能做事”,真正具备了影响外部世界的能力。例如在代码生成任务中,LLM不仅能输出代码文本(A_text),还能调用编译器执行代码、获取报错信息(A_action),进而迭代优化代码。
3. 奖励函数(Reward Function):从“单标量反馈”到“分步多维度奖励”
传统LLM-RL的奖励通常是“单标量评分”,例如人类标注者对模型回答的打分(1-5分),或AI反馈模型给出的单一数值,且奖励仅在生成最终输出后给予,中间过程无反馈。这种“延迟且单一”的奖励信号,难以引导模型学习复杂的多步决策。
Agentic RL则设计了更精细的分步奖励机制,综述中将其总结为:
任务完成时(如报告生成成功)步骤级进度(如搜索到关键数据)无进展时
例如在数学推理任务中,模型每完成一步正确的公式推导会获得“子目标奖励(r_sub)”,最终解出题目会获得“任务奖励(r_task)”。这种“稠密奖励”能更精准地引导模型学习正确的决策路径,避免因奖励稀疏导致的训练效率低下。
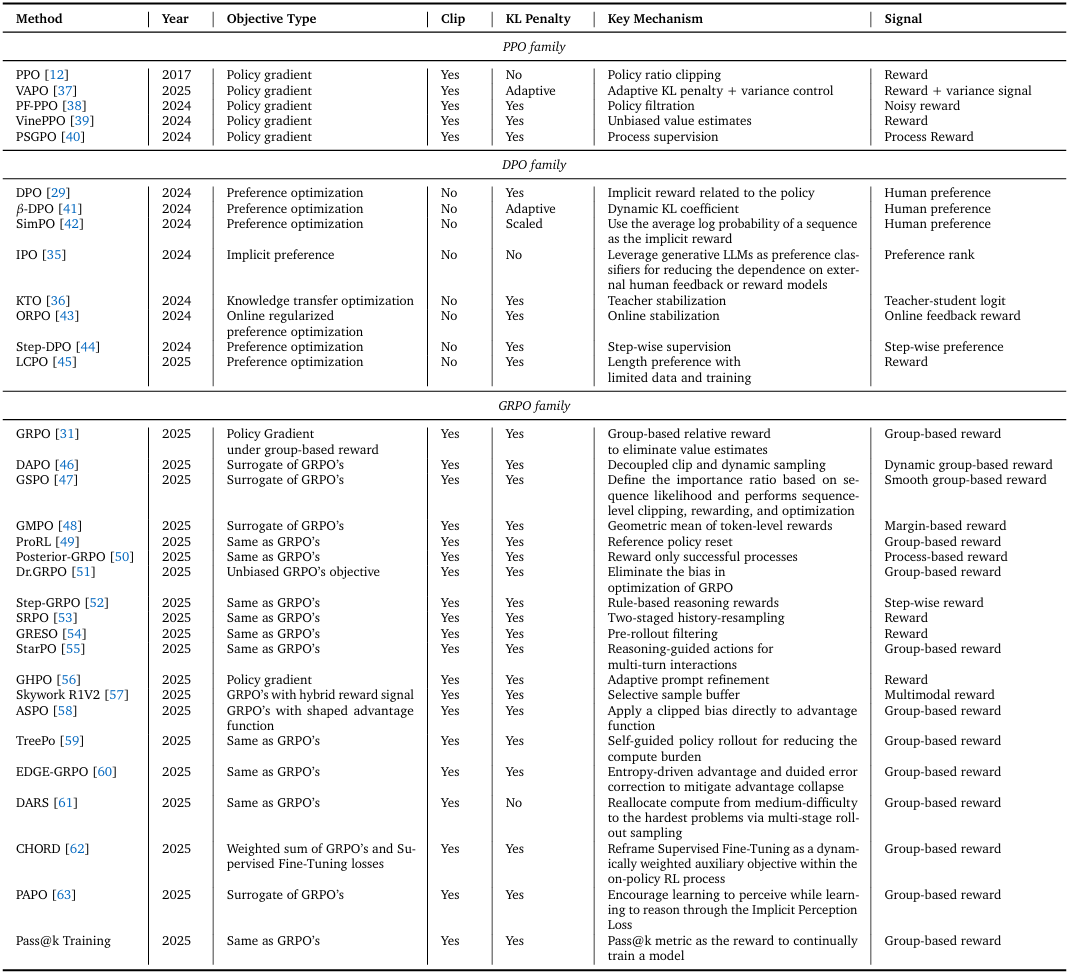
PPO、DPO 和 GRPO 系列主流变体对比。其中,“裁剪(Clip)” 指通过限制策略比率(policy ratio)使其不偏离 1 过远,以确保更新稳定;“KL 惩罚(KL penalty)” 指通过惩罚学习到的策略与参考策略之间的 KL 散度(KL divergence),以确保两者对齐。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

4. 学习目标(Learning Objective):从“单步期望奖励”到“长期折扣奖励”
传统LLM-RL的目标是最大化单步动作的期望奖励,即:
这意味着模型仅关注当前输出的质量,无需考虑长期影响。
而Agentic RL的目标是最大化“长期折扣奖励总和”,公式为:
其中γ是“折扣因子”,用于平衡短期收益与长期收益。例如在多轮对话任务中,模型可能需要在某一轮“牺牲短期流畅性”(如追问用户关键信息),以换取后续更精准的回答,这种“延迟满足”的能力正是通过长期折扣奖励实现的。
5. 环境交互:从“确定性”到“不确定性”
传统LLM-RL的环境交互是“确定性”的——一旦模型生成动作,后续状态是固定的。例如模型根据prompt生成回答后,不会有任何环境反馈改变这一结果。
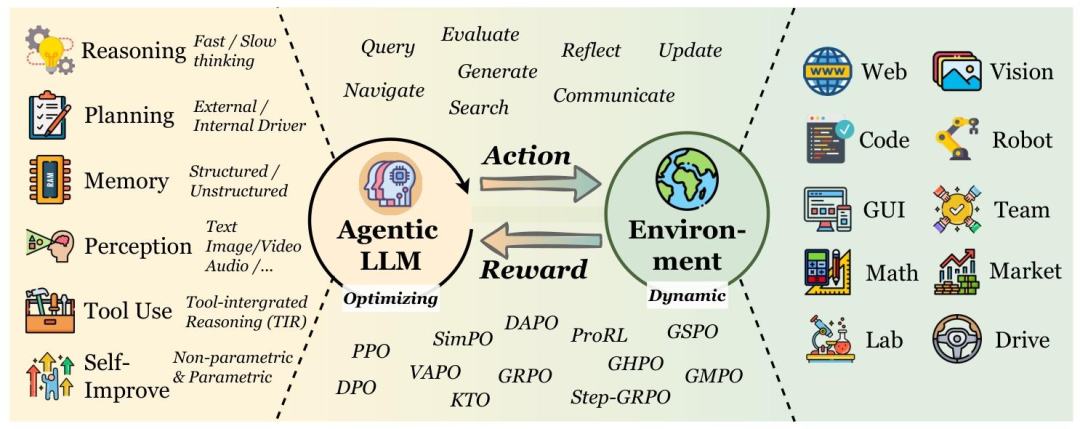
Agentic LLMs与环境的动态交互过程
Agentic RL的环境则充满“不确定性”,状态转移遵循概率分布:
例如LLM调用搜索工具时,可能因网络问题获取失败,或因关键词不当得到无关结果;控制机器人时,可能因物理干扰导致动作偏差。这种不确定性要求模型具备“鲁棒性”与“适应性”,能通过试错学习应对复杂场景。
核心能力拆解:RL如何让LLM拥有“自主智能”?
综述的核心贡献之一,是从“智能体能力”视角出发,系统分析了Agentic RL如何将规划、工具使用、记忆等“静态模块”转化为“自适应行为”。这六大核心能力,共同构成了LLM从“文本生成器”到“自主决策体”的技术基石。
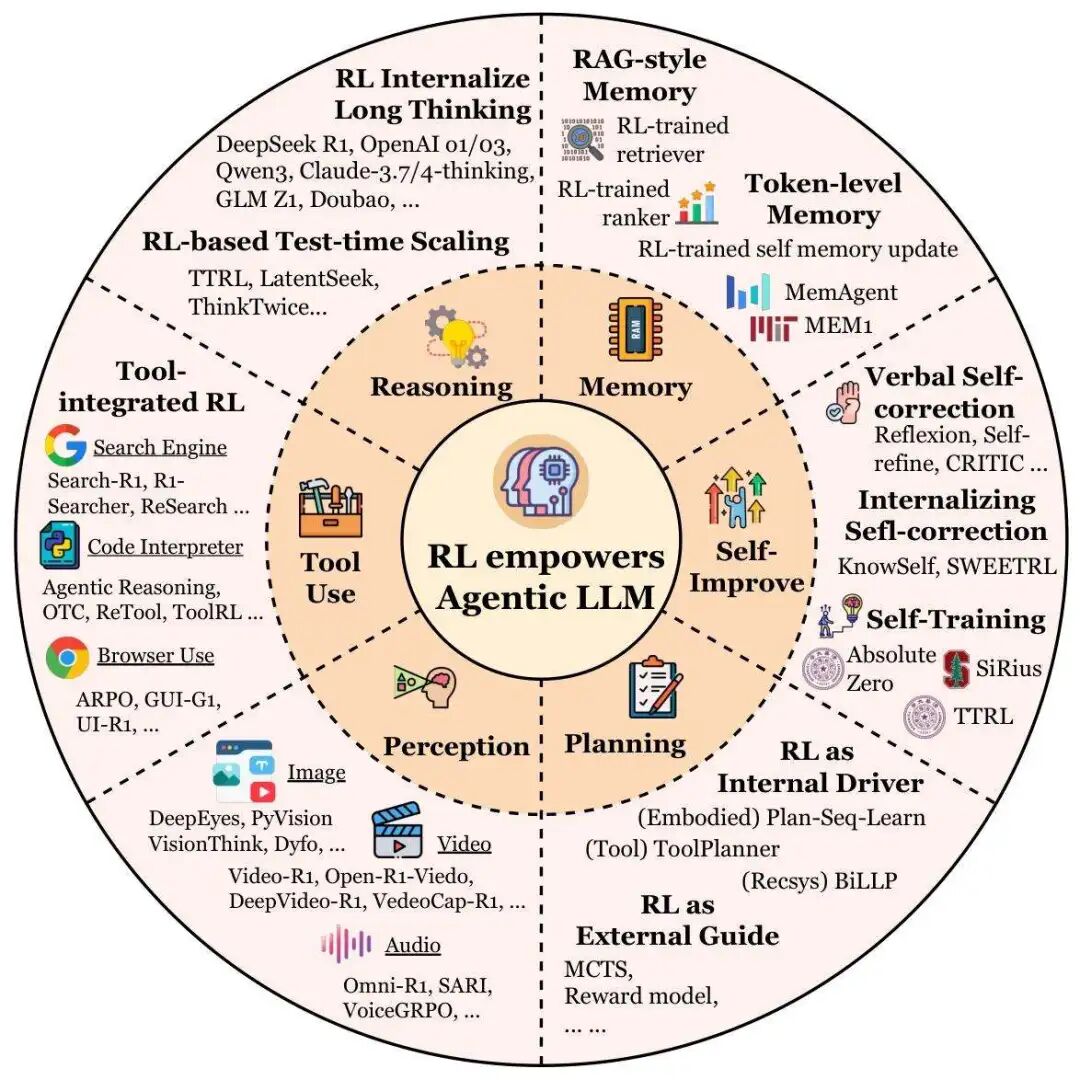
强化学习赋能 Agentic LLMs 的六大核心维度总结。
1. 规划能力:从“固定步骤”到“动态调整”
规划是智能体的核心能力,指“为实现目标设计动作序列”的过程。传统LLM的规划依赖prompt工程(如ReAct提示),只能遵循固定模板,无法根据环境反馈调整。而Agentic RL通过两种范式赋予LLM动态规划能力:
- RL作为外部引导:不直接微调LLM的生成能力,而是训练一个“奖励/启发函数”,引导经典搜索算法(如MCTS)优化规划轨迹。例如RAP、LATS等方法,利用RL模型评估LLM生成的每一步规划质量,将更优的轨迹纳入搜索范围,提升复杂任务的规划效率。
- RL作为内部驱动:将LLM直接视为“规划策略模型”,通过环境反馈微调其参数。例如Voyager在《Minecraft》中,通过RL迭代构建“技能库”,从“不会合成工具”逐步进化为“能规划复杂建筑流程”;AdaPlan则通过“全局规划引导+渐进式RL”,让LLM在文本游戏中更好地协调长期目标与短期动作。
综述指出,未来规划能力的发展方向是“深思与直觉的融合”——让LLM既能快速生成直觉性规划,又能通过慢速 deliberation(深思)优化关键步骤,同时学习“何时该探索新路径、何时该剪枝无效分支”的元策略。
2. 工具使用能力:从“模仿调用”到“策略优化”
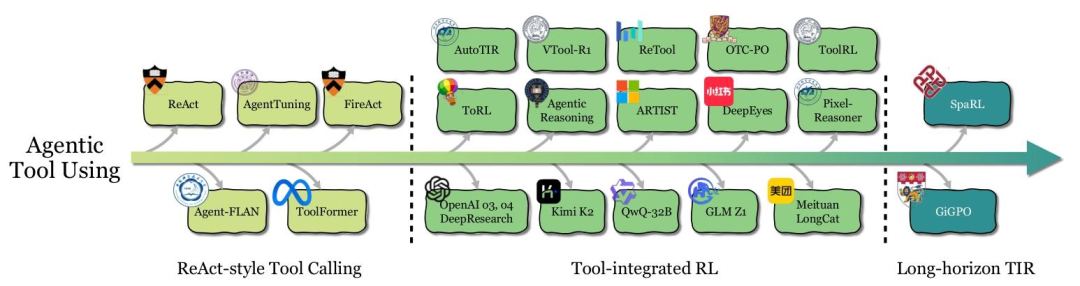
智能体工具使用的发展历程
工具使用是LLM扩展能力边界的关键,但早期方法(如Toolformer的监督微调)本质上是“模仿人类工具调用模式”,无法应对未见过的场景。Agentic RL则将工具使用从“模仿学习”升级为“结果驱动优化”,其演进可分为三个阶段:
- 阶段1:ReAct式工具调用:依赖prompt工程或监督微调,让LLM在“思考-动作-观察”循环中调用工具。例如ReAct通过少样本示例,引导LLM生成“先思考是否需要搜索,再调用搜索工具,最后根据结果回答”的流程。但这种方法的局限性在于,工具调用模式固定,无法适应新工具或复杂任务。
- 阶段2:工具集成推理(TIR):通过RL将工具调用与推理深度融合,让LLM自主决定“何时调用、调用哪个工具、如何处理工具反馈”。例如ToolRL在无监督微调的情况下,通过RL让LLM学会“发现代码错误后调用编译器调试”“多工具组合解决复杂问题”;OpenAI o3则通过RL优化工具调用的时机与顺序,在调研、代码生成等任务中实现“工具与推理的无缝衔接”。
- 阶段3:长周期TIR:当前的关键挑战是“长期信用分配”——在多步工具调用中,如何判断哪一步操作对最终结果起关键作用。例如在“写调研报告”任务中,可能需要10+次搜索,传统RL难以区分“某次无效搜索”与“某次关键搜索”的影响。为此,GiGPO、SpaRL等方法尝试通过“turn-level优势估计”“分步奖励建模”解决这一问题,但目前仍处于探索阶段。
3. 记忆能力:从“被动存储”到“主动管理”
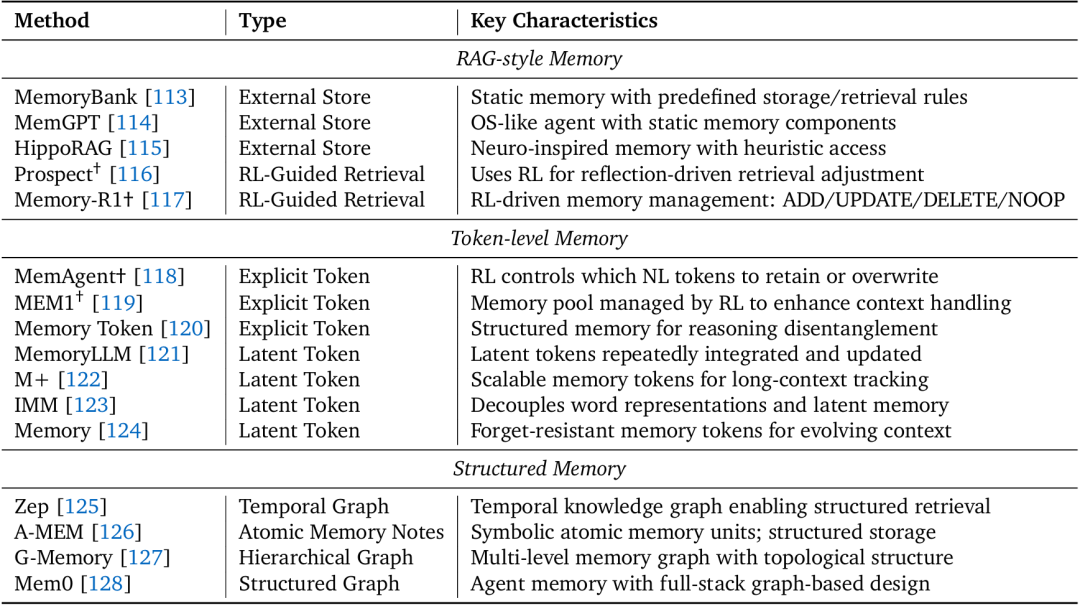
智能体记忆的三大经典类别概述;标有†的研究成果直接采用了强化学习(RL)。此处列出的内容并非详尽无遗
人类解决问题依赖“短期记忆(如当前任务状态)”与“长期记忆(如过往经验)”,LLM的记忆能力同样至关重要。传统方法(如RAG)将记忆视为“静态数据库”,而Agentic RL则让LLM学会“主动管理记忆”,其演进可分为三个阶段:
- 阶段1:RAG式记忆:记忆是外部数据库,RL仅控制“何时检索”。例如MemoryBank、MemGPT等系统,通过固定规则(如语义相似度)存储/检索信息,RL仅在“是否需要调用检索工具”上做决策。
- 阶段2:Token级记忆:LLM拥有“可训练的记忆控制器”,能自主决定“存储什么、删除什么”。例如MemAgent通过RL控制“哪些文本Token需要保留”,将长上下文压缩为简洁摘要;MemoryLLM则通过“潜在记忆Token”(非人类可读的向量)存储长期信息,避免遗忘关键内容。
- 阶段3:结构化记忆(未来方向):当前记忆多为“扁平Token序列”,难以捕捉复杂关系(如时间、因果)。综述指出,未来需通过RL优化“结构化记忆”(如知识图谱、层级图),例如让LLM学会“将调研数据组织为知识图谱”“根据任务需求动态更新记忆结构”,但这一领域目前仍缺乏成熟的RL方案。
4. 自我改进能力:从“依赖外部数据”到“自主迭代”
传统LLM的改进依赖“新数据集微调”,而Agentic RL让LLM具备“从自身错误中学习”的能力,其核心是“迭代反馈循环”,可分为三个层次:
- 语言自我修正:无需参数更新,通过“生成-反思-修正”的文本交互实现自我改进。例如Reflexion让LLM生成回答后,用自然语言反思“可能的错误”,再生成修正版本;Self-refine则通过三个prompt(生成、反馈、修正)实现多轮迭代,但这种改进仅局限于单任务会话,无法长期保留。
- 内部化修正能力:通过RL将“自我修正”的能力嵌入模型参数。例如KnowSelf利用DPO(直接偏好优化),在文本游戏中让LLM学会“反思错误决策并调整策略”;DuPo则通过“双任务反馈RL”,在翻译、推理任务中实现“无标注数据的自我优化”。
- 迭代自训练:无需人类数据,通过“自我生成任务-验证结果-优化策略”实现持续改进。例如Absolute Zero让LLM“自己生成数学题-尝试解答-用计算器验证-根据结果微调”;R-Zero则通过MCTS(蒙特卡洛树搜索)探索推理树,用搜索结果训练“策略LLM”与“价值LLM”,实现从0到1的推理能力提升。
5. 推理能力:从“快速直觉”到“慢速深思”
根据“双过程认知理论”,人类推理分为“快速推理(直觉式、低延迟)”与“慢速推理(多步验证、高准确性)”,LLM的推理能力同样可做此区分:
- 快速推理:对应“System 1认知”,模型直接生成结论,无需中间步骤。例如传统LLM解答“2+3=?”时,直接输出“5”,优势是效率高,但易出现逻辑错误、 hallucination(幻觉)。
- 慢速推理:对应“System 2认知”,模型生成多步推理过程,例如“2+3=5,因为2+2=4,4+1=5”。Agentic RL通过两种方式优化慢速推理:
- 过程监督:对每一步推理给予奖励,而非仅关注最终结果。例如PSGPO(过程监督引导策略优化)利用“中间错误轨迹”“步骤注释”设计稠密奖励,让模型学习正确的推理路径;
- 自适应推理:让模型自主决定“何时用快速推理、何时用慢速推理”。例如o1模型在简单任务中快速响应,在数学推理等复杂任务中生成详细步骤,这种“动态切换”能力正是通过RL优化实现的。
综述指出,当前的关键挑战是“避免过度思考”——部分模型在简单任务中也生成冗长推理步骤,导致效率低下。未来需通过RL训练“推理粒度控制策略”,平衡准确性与效率。
6. 感知能力:从“被动识别”到“主动认知”
在多模态场景中,LLMs需要结合视觉、音频等信息,Agentic RL让LVLMs(大视觉语言模型)从“被动识别图像”进化为“主动认知环境”,其核心路径包括:
- 接地驱动(Grounding):将文本推理与视觉区域绑定。例如GRIT让LLM在生成推理步骤时,同步输出“ bounding box(边界框)”,标注推理对应的图像区域;DeepEyes通过RL让LLM“反复查看图像关键区域”,再生成结论,提升视觉推理的准确性。
- 工具驱动:调用视觉工具增强感知能力。例如VTool-R1通过RL让LLM学会“使用图像裁剪工具聚焦关键区域”“用标注工具标记物体”;OpenThinkIMG则提供标准化工具集,让LLM在“思考-工具调用-观察”循环中提升视觉理解。
- 生成驱动:通过生成图像/草图辅助感知。例如Visual Planning让LLM“先想象任务相关的图像(如设计图),再根据图像生成推理步骤”;T2I-R1则将推理分为“语义级规划(生成图像描述)”与“Token级生成(生成像素)”,通过RL联合优化两个阶段,提升文本-图像生成的一致性。
任务场景落地:Agentic RL如何解决真实世界问题?
除了核心能力,综述还从“任务视角”出发,详细梳理了Agentic RL在许多关键领域的应用。这些场景覆盖了“信息获取”“代码开发”“数学推理”“环境交互”等核心需求,展示了技术从理论到实践的落地路径。
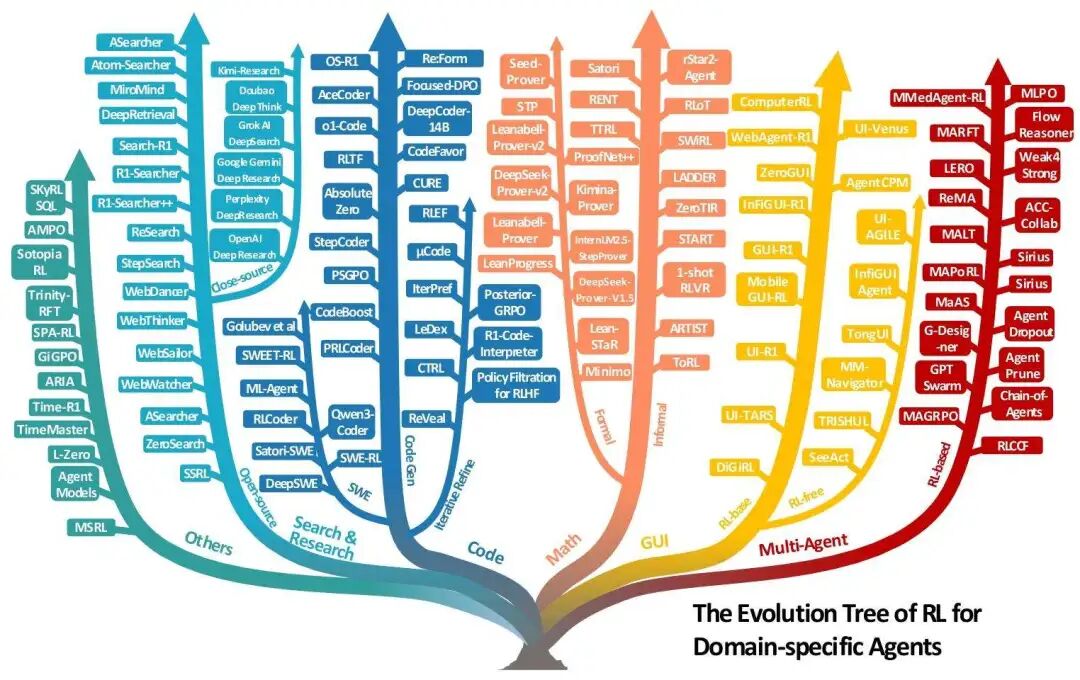
面向特定领域智能体的强化学习(RL)进化树
1. 搜索与研究智能体:从“关键词匹配”到“深度调研”
传统搜索引擎依赖用户输入准确关键词,而Agentic RL让搜索智能体具备“自主调研能力”:
- 开源方案:Search-R1通过“检索Token掩码”“结果相关性奖励”,让LLM学会“生成精准搜索词”“整合多轮搜索结果”;R1-Searcher++则引入“内部知识奖励”,避免重复搜索已知信息,提升调研效率;
- 闭源方案:OpenAI DeepResearch在BrowseComp benchmark(难寻信息定位任务)上实现51.5% pass@1,能自主导航网页、验证信息来源、生成结构化报告;Perplexity DeepResearch则支持“多模态搜索”,可整合图像、表格数据。
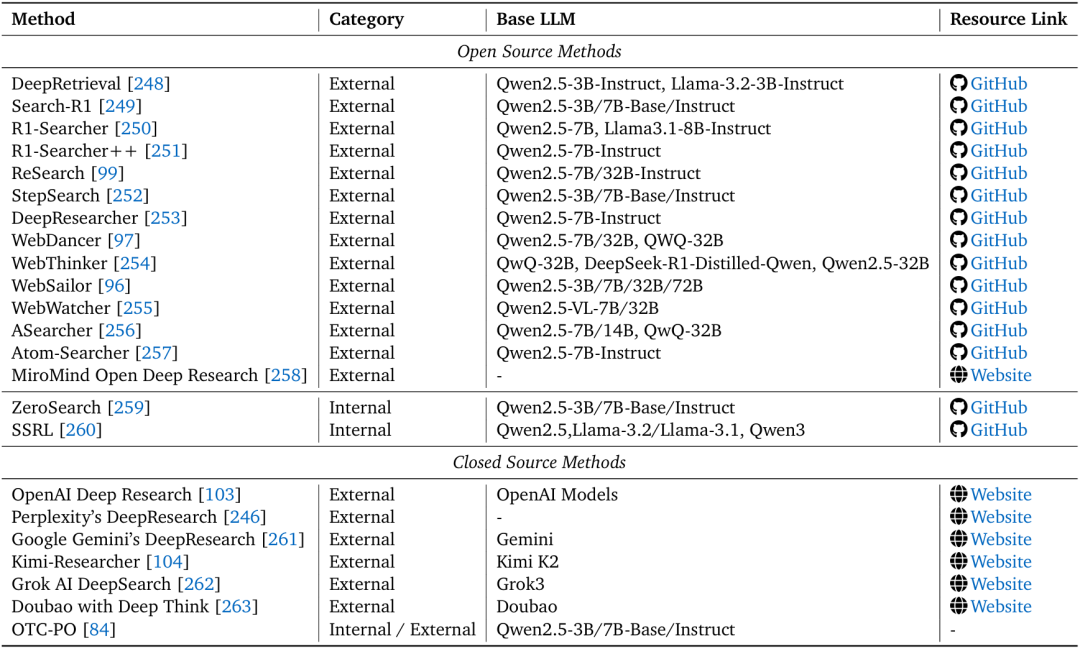
面向搜索与研究智能体的基于强化学习(RL)的方法总结
这类智能体的核心价值在于,将“用户提出需求”到“获取最终答案”的过程自动化,无需人类干预中间步骤。
2. 代码智能体:从“代码生成”到“全流程开发”
代码任务是Agentic RL的理想测试床——执行结果可验证(如编译是否通过、单元测试是否通过),奖励信号明确。其应用可分为三个层次:
- 代码生成:优化单段代码的正确性。例如DeepCoder-14B通过“分布式RL”,以“单元测试通过率”为奖励,在LiveCodeBench上实现60.6% Pass@1,性能接近闭源模型;
- 迭代优化:根据执行反馈修正代码。例如IterPref从“调试轨迹”中提取“局部偏好对”,通过RL让模型学习“如何修改错误代码”;LeDex则结合“错误解释”与“修正建议”设计奖励,提升代码自我修复能力;
- 自动化软件工程:处理全流程开发任务。例如DeepSWE通过RL训练智能体“阅读代码库-定位bug-修改代码-验证功能”,在SWE-bench(真实GitHub问题修复任务)上取得开源模型最佳性能;SWE-RL则从GitHub提交历史中提取“代码改进模式”,让模型学习真实开发中的迭代策略。
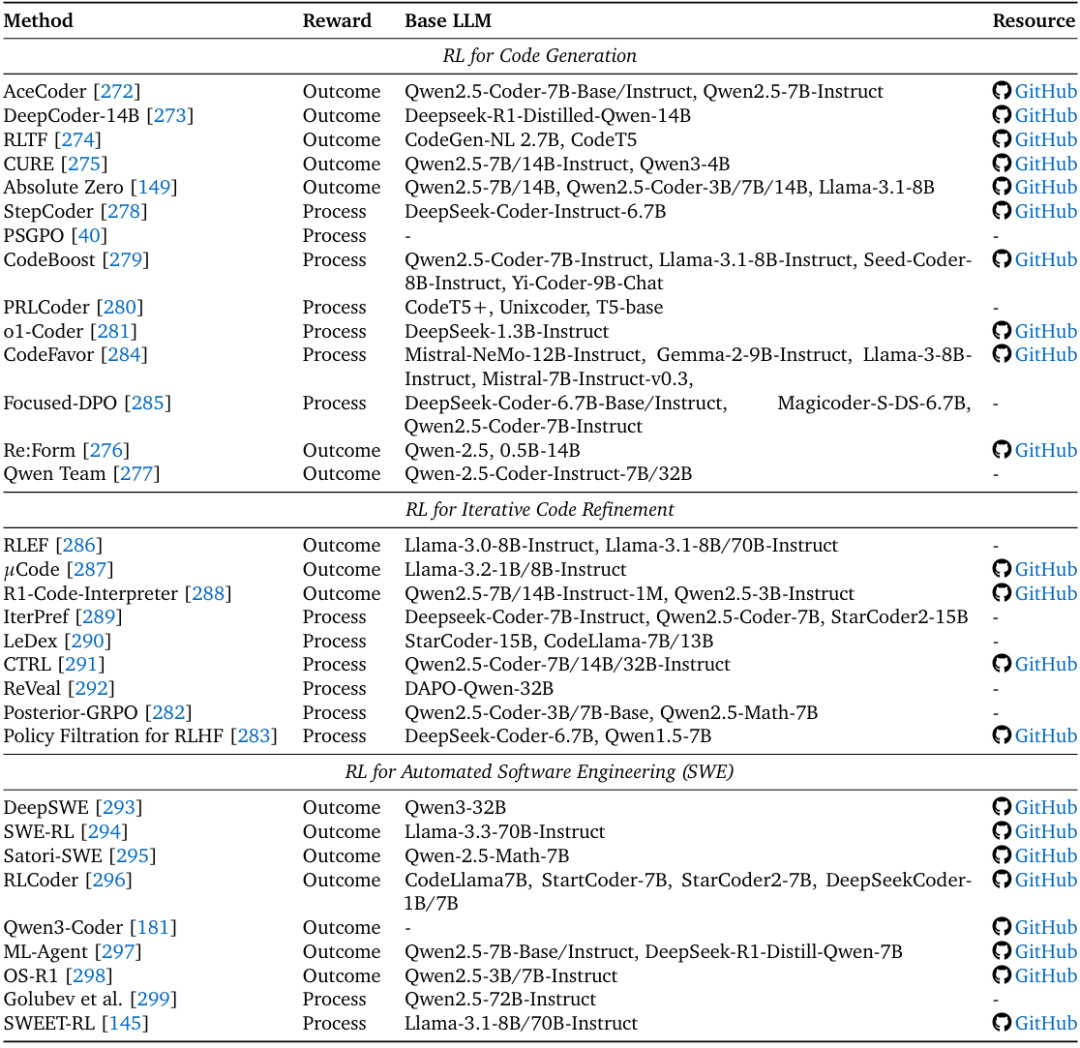
面向代码与软件工程智能体的强化学习(RL)方法总结
3. 数学推理智能体:从“简单计算”到“定理证明”
数学推理要求“逻辑严谨性”与“步骤完整性”,Agentic RL在该领域的应用分为两类:
- 非形式推理:自然语言+符号表达,无需机器验证。例如ARTIST通过RL让LLM“调用计算器验证步骤”“组合数学工具(如积分、矩阵计算)”,在MATH数据集上提升15%+准确率;TTRL(测试时RL)则通过“多数投票奖励”,在无标注数据的情况下优化推理策略;
- 形式推理:基于证明助手(如Lean、Isabelle),生成机器可验证的证明。例如DeepSeek-Prover-v1.5通过RL利用“证明助手的二进制反馈(通过/失败)”优化策略,在miniF2F(数学竞赛题证明任务)上提升证明成功率;Leanabell-Prover则整合“非形式推理草图”与“形式证明代码”,通过RL让LLM学会“将自然语言推理转化为严谨证明代码”。
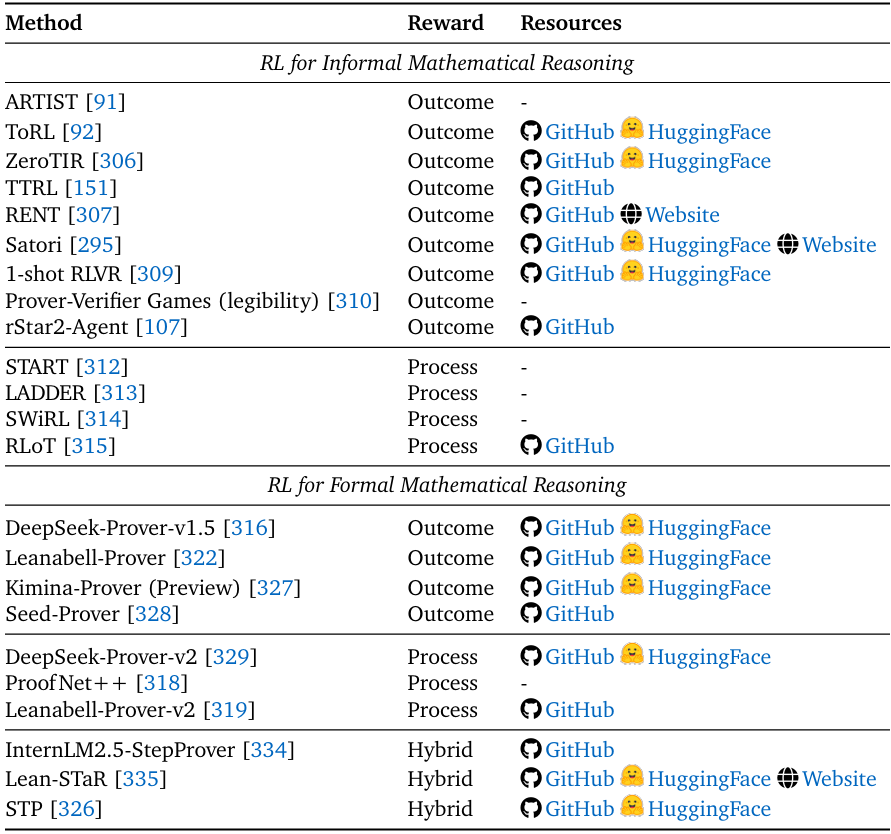
面向数学推理智能体的强化学习(RL)方法总结
4. GUI智能体:从“手动操作”到“自动导航”
GUI(图形用户界面)智能体可自动操作桌面/移动端应用,Agentic RL的应用分为静态与动态场景:
- 静态GUI:界面元素固定,任务流程可预测。例如GUI-R1通过“格式正确性奖励”“操作准确性奖励”,让LLM学会“点击按钮”“输入文本”等基础操作;AgentCPM-GUI则通过GRPO优化“长序列GUI操作”,在办公软件自动化任务中提升效率;
- 动态GUI:界面元素随操作变化,如网页加载新内容。例如WebAgent-R1通过“异步轨迹生成”“group-wise优势估计”,让LLM学会“处理网页弹窗”“等待页面加载”;ZeroGUI则通过“自动生成任务+视觉评估奖励”,在无人工标注的情况下训练GUI智能体,降低数据依赖。
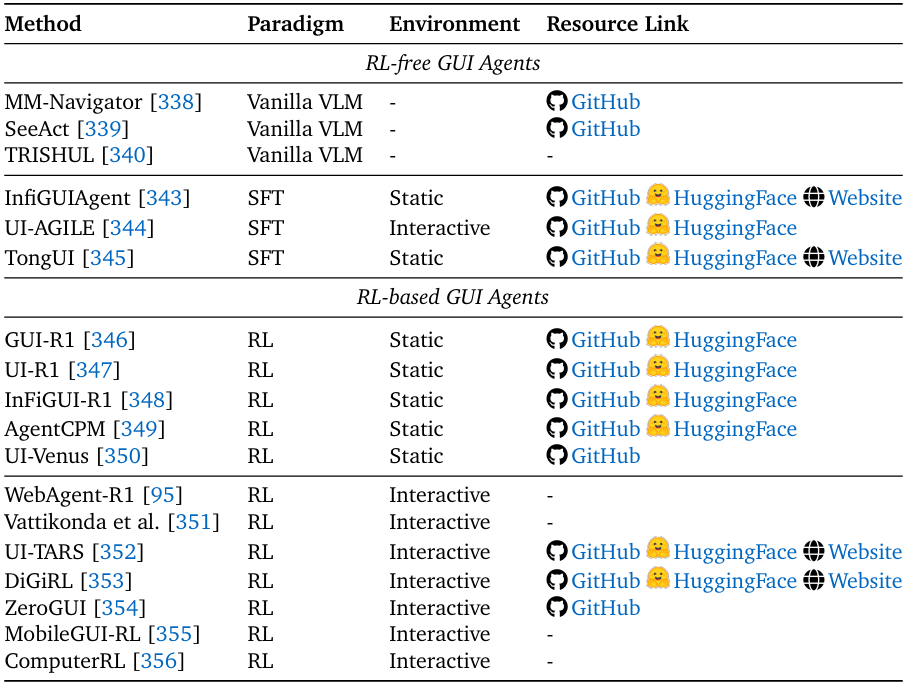
面向图形用户界面(GUI)智能体的方法总结,按训练范式与环境复杂度分类。
5. 其他关键场景
除上述领域外,Agentic RL还在视觉智能体(如3D场景理解、视频生成)、具身智能体(如机器人导航、物体操作)、多智能体系统(如协作决策、零和游戏)、时序分析(如股票预测、日志分析)等场景中展现出潜力。
例如在多智能体系统中,MAGRPO将多LLM协作建模为Dec-POMDP(分布式部分可观测MDP),通过RL让智能体学会“分工”“信息共享”;在具身智能体中,VLA-RL(视觉-语言-动作RL)让机器人“根据自然语言指令规划运动轨迹”,提升人机交互的自然性。
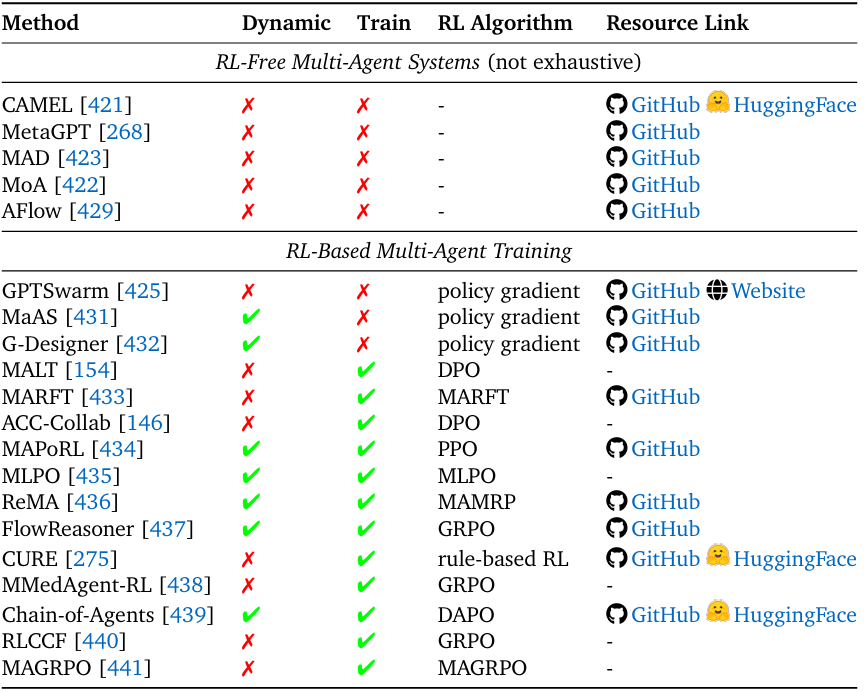
基于大语言模型(LLM)的多智能体系统(LLM-based Multi-Agent Systems)中强化学习与进化范式总结。“动态性(Dynamic)” 指多智能体系统是否具备任务动态适配性,即能否针对不同的任务查询,采用不同的配置(智能体数量、拓扑结构、推理深度、提示词等)进行处理。“训练性(Train)” 指该方法是否涉及对智能体的大语言模型主干(LLM backbone)进行训练。
技术框架与挑战:通向通用AI智能体的必经之路
为了让研究者更好地开展工作,综述还整理了Agentic RL的“环境与框架”工具链,并指出了三大核心挑战:
1. 环境与框架:降低技术落地门槛
- 环境模拟器:涵盖网页(WebShop、Mind2Web)、GUI(AndroidWorld、OSWorld)、代码(Debug-Gym、SWE-bench)、游戏(Crafter、Factorio)等场景,提供标准化的交互接口与奖励信号。例如WebArena是一个可本地部署的网页环境,支持“电商购物”“论坛发帖”等任务,研究者可直接用于训练搜索智能体;
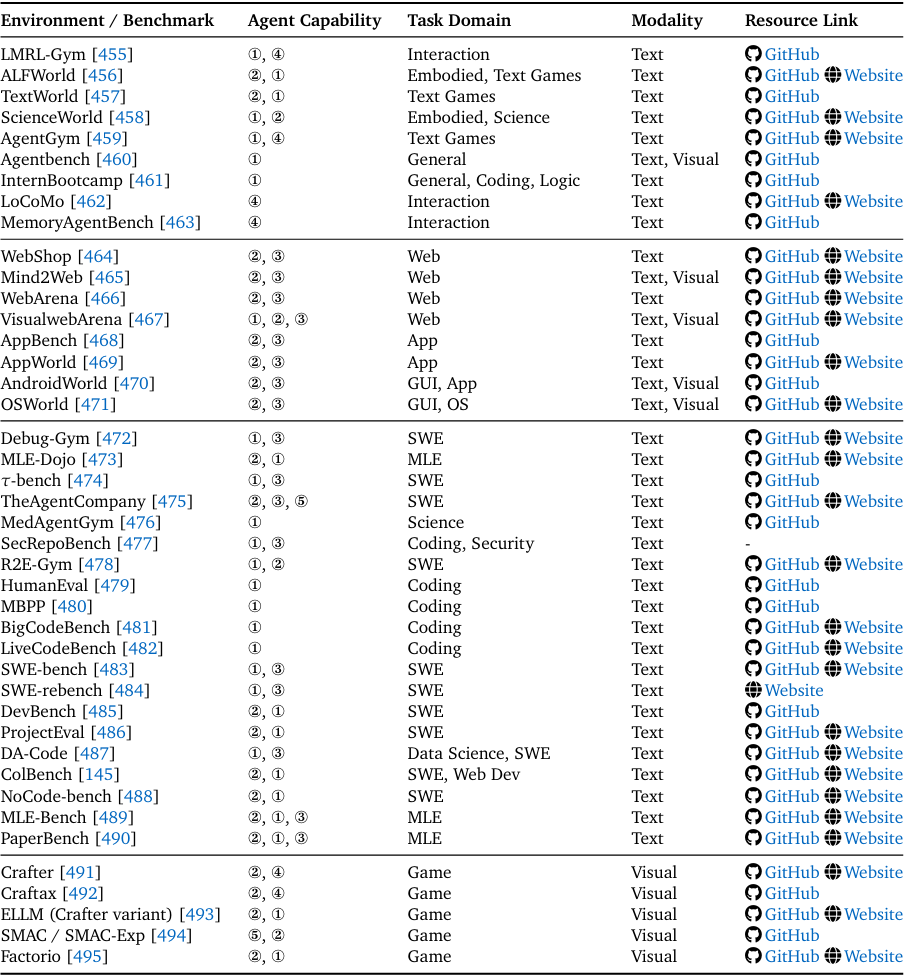
智能体强化学习(Agentic Reinforcement Learning)的环境与基准总结,按智能体能力、任务领域和模态分类。其中,智能体能力标注说明如下:①推理(Reasoning)、②规划(Planning)、③工具使用(Tool Use)、④记忆(Memory)、⑤协作(Collaboration)、⑥自我改进(Self-Improve)。
- RL框架:分为三类——Agentic RL框架(如AWorld的分布式训练、AgentFly的异步执行)、RLHF/LLM微调框架(如OpenRLHF、TRL)、通用RL框架(如RLlib、Tianshou)。其中,AWorld通过“集群并行rollout(轨迹生成)”实现14.6倍训练加速,大幅降低长周期任务的计算成本。
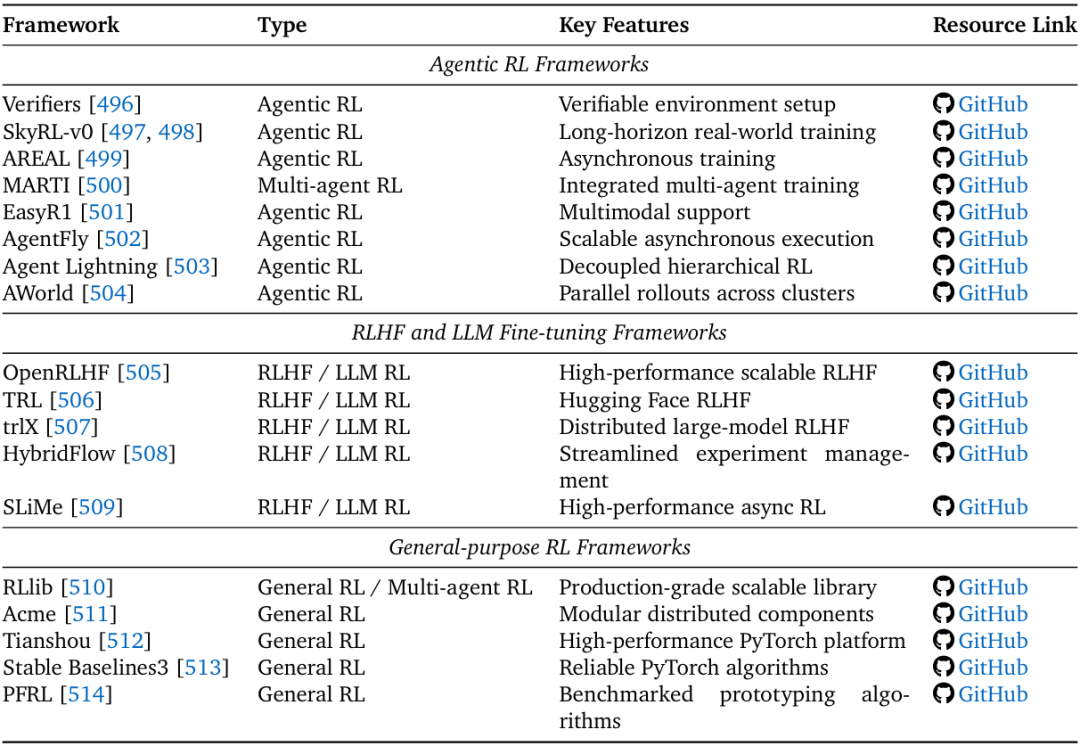
强化学习框架总结,按类型与关键特征分类。
2. 三大核心挑战:阻碍通用智能体的关键瓶颈
尽管Agentic RL发展迅速,但综述指出,通向通用AI智能体仍需解决三大挑战:
- 可信度问题:包括安全漏洞(如工具调用被劫持、多智能体系统中某一智能体被污染)、幻觉(生成未验证信息)、谄媚性(迎合用户错误偏好)。解决方案包括“沙盒环境限制工具权限”“过程监督奖励减少幻觉”“多智能体交叉验证避免谄媚”;
- 训练规模化:当前Agentic RL的计算成本极高,例如ProRL需要数周训练才能提升推理能力;同时,跨领域训练易出现“能力冲突”(如数学RL会影响代码能力)。未来需通过“高效RL算法(如GRPO的轻量化评估)”“领域自适应训练”解决;
- 环境规模化:现有环境多为静态或简单动态,无法模拟真实世界的复杂性。解决方案包括“自动环境生成(如EnvGen通过LLM生成任务场景)”“动态奖励设计(让环境根据智能体能力调整难度)”,构建“智能体-环境协同进化”的训练闭环。
五、总结:LLM智能体的未来已来
这篇综述通过500+研究的系统梳理,清晰地展现了Agentic RL的技术脉络——它不仅是“LLM+RL”的简单结合,更是将LLMs从“文本生成工具”重构为“自主决策智能体”的范式革命。
从核心能力上看,规划、工具使用、记忆等模块通过RL实现了“从静态到动态”的跨越;从任务场景上看,搜索、代码、数学推理等领域的落地,证明了Agentic RL解决真实问题的价值;从未来方向上看,可信度、规模化、环境复杂度三大挑战,则指明了通用AI智能体的研发路径。
对于研究者而言,这篇综述提供了完整的技术框架与文献索引;对于工程师而言,它展示了技术落地的具体场景与工具链;而对于整个AI领域而言,Agentic RL的发展意味着——LLM不再仅是“被动响应”的工具,而是有望成为“主动解决问题”的伙伴,这无疑是通向通用人工智能的关键一步。
未来,随着技术的不断突破,我们或许将见证AI智能体真正融入人类生活,在科研、医疗、教育等领域成为不可或缺的协作伙伴——而这篇综述,正是这场革命的“第一份完整技术蓝图”。
六、AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


技术共进,成长同行——讯飞AI开发者社区
更多推荐


 13
13 0
0- 0



 已为社区贡献197条内容
已为社区贡献197条内容

所有评论(0)