
Kmeans算法代码详解(Python)
可以看到,当K=3时,产生了“肘点”,从K=3到K=4,SSE的下降速度明显变缓,因此最佳的K取值应为3。可以看到输出了所有样本的聚类标签,包括0-2,一共三个簇,同时输出了聚类平方误差总和。最后设置标签、添加图例,通过参数指定图例的位置,在这里表示将图例放在左上角。SSE是指每个数据点到其簇中心的距离的平方和,用于衡量聚类的紧密度。然后分别绘制各个簇的样本以及每个簇的中心点坐标。分别表示获取所有
·
主要部分代码
首先使用KMeans()对数据集建模
model = KMeans(n_clusters=3)
model.fit(data)
- 创建一个KMeans对象,指定聚类数为3,意味着算法将数据分成3个簇
- 使用数据拟合了KMeans模型。在这一步,算法会尝试找到最优的簇中心,使得数据点到其对应簇中心的距离之和最小
获取聚类标签
label_pred = model.labels_
- 这行代码获取了每个数据点的聚类标签。每个数据点被分配到一个簇,输出是一个数组,包含每个数据点所属的簇的标签。
获取聚类平方误差总和SSE
inertia = model.inertia_
SSE是指每个数据点到其簇中心的距离的平方和,用于衡量聚类的紧密度。SSE越小,表示数据点越靠近它们的簇中心,聚类效果越好。
结合例子
以鸢尾花数据集为例,首先将数据导入
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
iris = load_iris() #导入sklearn自带的鸢尾花数据集
data = pd.DataFrame(iris.data, columns=iris.feature_names)
开始建模
和上面分析的步骤一样
model = KMeans(n_clusters=3)
model.fit(data)
label_pred = model.labels_
print(label_pred)
inertia = model.inertia_
print("聚类平方误差总和为: ",inertia)
输出结果如下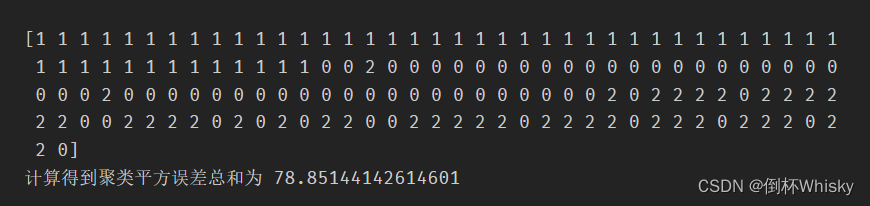
可以看到输出了所有样本的聚类标签,包括0-2,一共三个簇,同时输出了聚类平方误差总和
查看聚类结果
最后可以将聚类的结果绘制出来:
先分别取出每一簇的样本
x0 = data[label_pred == 0]
x1 = data[label_pred == 1]
x2 = data[label_pred == 2]
然后分别绘制各个簇的样本以及每个簇的中心点坐标
最后一行代码中,model.cluster_centers_[:, 0]和model.cluster_centers_[:, 1]分别表示获取所有簇中心的X坐标和Y坐标,marker='s'表示正方形
plt.scatter(x0["sepal length (cm)"], x0["sepal width (cm)"], c = "red", marker='o', label='label0')
plt.scatter(x1["sepal length (cm)"], x1["sepal width (cm)"], c = "green", marker='*', label='label1')
plt.scatter(x2["sepal length (cm)"], x2["sepal width (cm)"], c = "blue", marker='+', label='label2')
plt.scatter(model.cluster_centers_[:,0],model.cluster_centers_[:,1], c = "black", marker='s',label='centroids')
最后设置标签、添加图例,通过参数指定图例的位置,在这里表示将图例放在左上角
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
得到下图结果
如何选择合适的K值
讲完了建模,现在来讲讲在建模之前我们如何选择最佳的K值——画肘部图
from scipy.spatial.distance import cdist
plt.plot()
colors = ['b','g','r']
markers = ['o','v','s']
#生成一个字典保存每次的代价函数
distortions = []
#从1~9判断合适的K值
K = range(1,10)
for k in K:
#分别构建各种K值下的聚类器
Model = KMeans(n_clusters=k).fit(data)
#计算各个样本到其所在簇类中心欧式距离(保存到各簇类中心的距离的最小值)
distortions.append(sum(np.min(cdist(data, Model.cluster_centers_, 'euclidean'), axis=1)) / data.shape[0])
#绘制各个K值对应的簇内平方总和,即代价函数SSE
plt.plot(K,distortions,'bx-')
#设置坐标名称
plt.xlabel('optimal K')
plt.ylabel('SSE')
plt.show()
可以看到,当K=3时,产生了“肘点”,从K=3到K=4,SSE的下降速度明显变缓,因此最佳的K取值应为3

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)