
python之文件操作进阶(with open 、文件复制、文件的读、写、关闭)(8)
本篇文章主要针对python的文件操作进行深入的理解,并掌握更多python操作文件的方法和技巧,其中基础知识我不会过多讲解,大家可以结合我前面的文章进行学习python之文件操作基础。
文章目录
前言
本篇文章主要针对python的文件操作进行深入的理解,并掌握更多python操作文件的方法和技巧,其中基础知识我不会过多讲解,大家可以结合我前面的文章进行学习python之文件操作基础:http://t.csdnimg.cn/Pwi2s
1、文件的本质
1.1 引言
- 一个程序运行的三大核心硬件:
从外存---》内存---》cpu---》内存---》外存 - 一个数据想要保存,首先要经过内存,然后进入外存进行永久保存
- 操作系统提供了一种保存数据的方式:
文件,文件相当于在外存上开辟的一块空间,我们通过操作文件来操作外存,所有文件本质上都是以二进制形式存在的,而在这些不同类型的文件中,有一种文件比较特殊,他就是纯文本文件,该类型文件会涉及到字符编码的问题,字符编码不匹配就会产生乱码
1.2 扩展知识
- 纯文本文件需要进行字符编码,但它依然是一个二进制文件
- 二进制文件都需要使用字符编码吗?
不是,字符编码只针对字符进行编码,而像图片、音频、视频等等不是纯文本内容的都不用编码,也不能编码(会报错);他们本质上都是以二进制流的形式写入内存的,经过处理最后存入外存
2、文件操作
2.1 文件操作步骤
分三步:
- 打开文件,得到文件对象
格式:文件对象 = open(文件路径,操作模式,encoding='编码格式')
这里文件路径和操作模式两个参数必不可少- 操作文件(读或写)
格式:
1、文件对象.write(内容),向文件写入内容
2、文件对象.read(),读取文件内容- 关闭文件,文件关闭后,数据才会从内存中写入外存,相当于保存
文件对象.close()
2.2 文件的类型与操作模式
- 文件类型
我们知道所有文件本质都是
二进制类型的,但纯文本文件相对比较特殊需要进行编码,所以为了操作方便,python将文件分为两种类型:
- 纯文本文件:
t- 二进制文件:
b通常文件的类型会在
操作模式中进行指定,用来操作不同文件,我们往后看。
- 操作模式
我们常见的操作模式有三种:
w(覆盖写)a(追加写)r(读文件)
说明:这三种模式没有指定文件类型,默认就是操作纯文本文件指定操作的文件类型,文件完整的操作模式,如下:
- 纯文本(t):操作纯文本类型的文件,如:.txt文件
1、wt(覆盖写)
2、at(追加写)
3.、rt(读文件)
说明:操作纯文本类型的文件可以省略t,直接写w、a、r,需要编码- 二进制(b):操作二进制类型的文件,如:图片、音频、视频…
1、wb(覆盖写)
2、ab(追加写)
3、rb(读文件)
说明:操作二进制类型的文件,不能省略b,必须写完整,不能编码
书写模板:
# 以覆盖写操作纯文本类型的文件文件
f1 = open('try.txt','wt')
# 以追加写操作二进制类型的文件
f2 = open('风景.png','ab')
总结:
- 纯文本(
t)模式下,只能操作字符类型的文件,不能操作二进制数据 - 二进制(
b)模式下,可以操作所有类型的文件,但是在操作纯文本类型的文件时,由于不能指定编码格式,需要对 文件数据进行编码和解码;如下:
f1 = open('风景.txt','wb') # b模式下覆盖写纯文本文件
f1.write('哈哈'.encode('utf-8')) # 因为是b模式,只能写入二进制数据,所以需要先对数据编码
f1 = open('风景.txt','rb') # b模式下读取纯文本文件
text = f1.read().decode('utf-8') # 因为是b模式,读取的数据是二进制形式的,所以需要进行解码变为字符串
print(text) # 输出结果:哈哈
f1.close()
说明:
从面可以知道虽然 二进制(b)模式可以操作所有类型的数据,但在操作纯文本类型的数据时需要进行编码和解码,相对麻烦;所以python为了方便,规定了 纯文本(t)模式用来单独对只有字符数据的文件进行操作
了解点:
通常所有操作模式在同一时间都只能对文件进行一种操作,只能读或只能写,那么如果想要对文件同时进行读和写的操作,可以通过 + 来实现,如:w+r,wb+rb 等等,但非常不建议这么做,因为这种方法在很多情况下都会出问题
2.3 文件关闭的作用
我们在打开文件写入或读取数据后,会将文件关闭,其目的是:
- 一方面是为了避免占用内存资源
- 不关闭文件,写入文件的数据就会保存在内存中,无法永久保存,关闭文件后,数据才会存入外存(硬盘)
问题案例:
f1 = open('风景.txt','w',encoding='utf-8') # 打开文件,生成f1对象
f1.write('哈哈') # 向文件中写入数据
# f1.close() 关闭文件后数据才会保存
f2 = open('风景.txt','r',encoding='utf-8') # 重新打开文件,生成f2对象
text = f2.read() # 读取文件内容
print(text) # 输出结果为空
说明:
从上面可以看出明明将数据写入了文件,但将它重新打开,却读取不到数据,就是因为前面写入数据后,没有将文件关闭,数据还在内存中,没有存入外存,所以在重新打开文件后,内存中的内容直接被覆盖掉了,导致文件为空
- 除了关闭文件可以保存文件,还有一种方法不用关闭文件,也可以保存文件,如:
格式:
文件对象.flush(),刷新内存,立即保存文件
f1 = open('风景.txt','w',encoding='utf-8')
f1.write('哈哈')
f1.flush() # 立即保存文件
f2 = open('风景.txt','r',encoding='utf-8')
text = f2.read()
print(text) # 输出结果:哈哈
2.4 with open方法操作文件(常用,推荐)
2.4.1 基本使用
这种操作文件的方法编写代码更加简洁,功能更加强大,而且会自动关闭保存文件
格式:
with open(文件路径,操作模式,encoding='编码格式') as 变量:
代码1
代码2
...
例子:
with open('123.txt','w',encoding='utf-8') as f1:
f1.write('哈哈哈') # 向文件中写入内容
print('啦啦啦') # 输出结果:啦啦啦
-
同时操作多份文件
格式: with open(文件路径,操作模式,encoding='编码格式') as 变量1,open(文件路径,操作模式,encoding='编码格式') as 变量2: 代码1 代码2 ...
with open('123.txt','w',encoding='utf-8') as f1,open('110.txt','w',encoding='utf-8') as f2:
f1.write('哈哈哈') # 第一个文件对象
f2.write('啦啦啦') # 第二个文件对象
2.4.2 基于with open 方法实现复制功能
实现对文本数据和二进制数据(图片、音频、视频)的复制,这种复制方法会占用大量内存,不推荐复制大文件
复制图片案例:
with open('2.png','rb') as f1,open('3.png','wb') as f2:
f2.write(f1.read()) # 将图片 2.png 读取出来写入 3.png
输出结果:
- 拓展:复制大文件的常用操作方法
原来的复制方法是通过将文件内容一次性读取到内存中,然后再将其写入另一个文件,这样在复制大文件时很占内存,所以为了减少内存的占用,我们可以使用循环,每次读取少量的数据,依次存入文件,这样就可以避免一次性占用大量内存;如:
with open('1213.txt','rb') as f1,open('333.txt','wb') as f2:
while True: # 重复读取写入的操作,直至文件复制完成
data = f1.read(3) # 读取三个字节,相当于一个字符
if data:
f2.write(data) # 每次写入3个字节
else:
break
2.4.3 读取操作详解
2.4.3.1 read() 的作用
- 只能配合
r模式读取文件数据- 文件刚打开时,光标在开头,而
read()表示将光标后的内容一次性读取到内存,光标移至末尾,这时若继续读取,得到的将是空字符串
案例: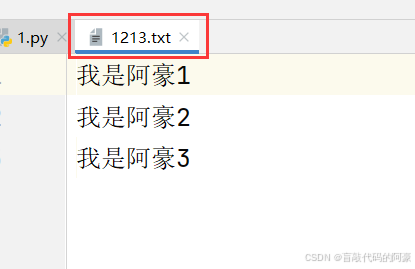
with open('1213.txt','r',encoding='utf-8') as f:
print(f.read()) # 第一次读取,光标移至末尾
print('================')
print(f.read()) # 第二次读取,结果为空字符串
print('00000000000000000000')
输出结果:
我是阿豪1
我是阿豪2
我是阿豪3
================
00000000000000000000
2.4.3.2 读取指定数量的数据
格式:
read(数字)
分为两类:
- 在
t文本模式下,表示读取多少个字符
with open('1213.txt','r',encoding='utf-8') as f:
print(f.read(3)) # 1,读取前三个字符,光标移至第三个字符末尾
print(f.read(3)) # 2,从光标开始继续读取三个字符
print(f.read(3)) # 3,继续读取3个字符
print('00000000000000000000')
输出结果:
我是阿
豪1
我是阿
00000000000000000000
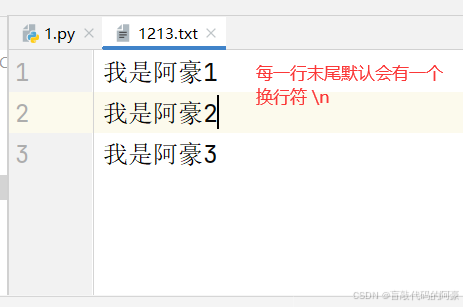
说明:
从上面的输出结果可以看到在第二次读取数据时只读出了两个字符并且进行了换行,这是因为在文件每一行末尾默认会有一个换行符 \n,只是看不到,在读取时他也会算做一个字符,并产生换行效果
- 在
b二进制模式下,表示读取多少个字节
gbk编码中,一个中文字符=2个字节,一个英文字符=1个字节
utf-8编码中,一个中文字符=3个字节,一个英文字符=1个字节
with open('1213.txt','rb') as f:
text = f.read(3) # 读取3个字节,因为是utf-8的编码格式,所以刚好等于一个字符
print(text)
print(text.decode()) # 读出来的是二进制,需要解码才能显示字符
输出结果:
b'\xe6\x88\x91'
我
注意:
读取的字节数必须刚好为完整的字符,比如:utf-8格式下,一个字符=3个字节,若读取4个字节,在解码时就会报错,必须读取3个字节或6个字节,要凑成完整的字符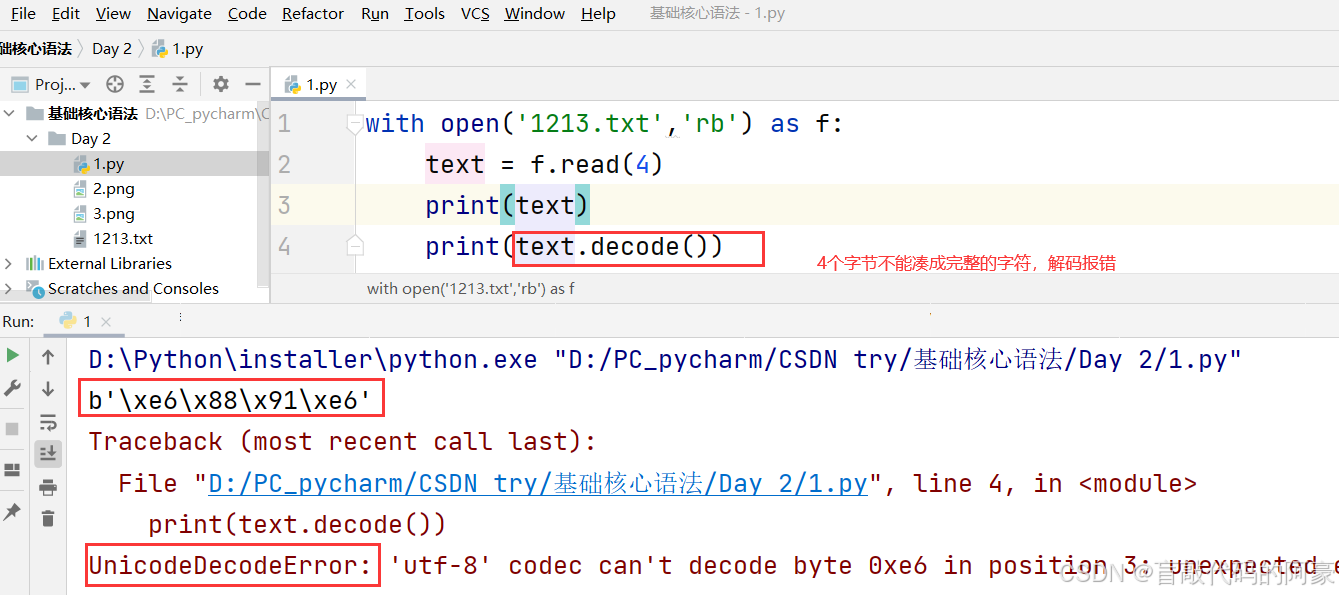
- 拓展1:每次读取一行的内容,格式:
文件对象.readline()
with open('1213.txt','r',encoding='utf-8') as f:
print(f.readline()) # 读取第一行内容,末尾有换行符,自动换行
print(f.readline()) # 读取第二行的内容
输出结果:
我是阿豪1
我是阿豪2
- 拓展2:将每行内容读取出来组成一个列表,格式:
文件对象.readlines()
with open('1213.txt','r',encoding='utf-8') as f:
print(f.readlines()) # 每行末尾默认有个换行符\n,只有最后一行末尾没有换行符
输出结果:
['我是阿豪1\n', '我是阿豪2\n', '我是阿豪3']
- 拓展3:循环之文件对象的本质
with open('1213.txt','r',encoding='utf-8') as f:
for i in f.readlines(): # 将列表遍历出来
print(i.strip('\n'))
等同于:
with open('1213.txt','r',encoding='utf-8') as f:
for i in f: # 文件对象 f 相当于用 readlines()读出的列表,输出结果相同
print(i.strip('\n')) # 由于每行结尾有换行符\n,我们将其去除,防止换行
输出结果:
我是阿豪1
我是阿豪2
我是阿豪3
2.4.4 写入操作扩展
write():只能配合w和a模式,将数据写入文件
- 拓展:一次性写入多条数据,格式:
1、文件对象.writelines(列表),将列表中的元素依次写入文件,且元素的数据类型只能为字符串
2、文件对象.writelines(字典),将字典中的键依次写入文件,且字典的键和值都只能为字符串
with open('333.txt','w',encoding='utf-8') as f1:
f1.writelines(['我是阿豪+','233333+','啦啦啦+']) # 将列表中的元素依次写入文件
f1.writelines({'姓名+':'阿豪','爱好是啥':'唱歌'}) # 将字典中的键依次写入文件
输出结果: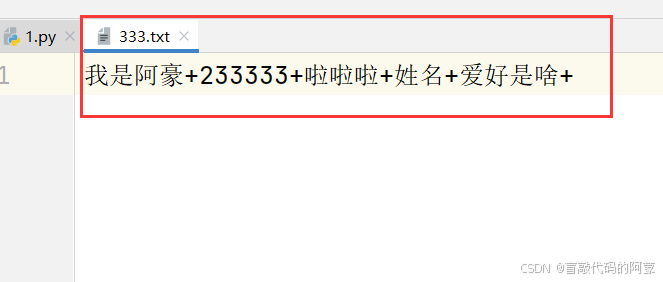
说明:
从上面可以看到,writelines()的作用是将可迭代对象(列表或字典)中的元素依次写入文件,注意:
1、列表是将每个元素写入文件,字典是将每个键写入文件,而不是值
2、列表的元素和字典的键值对的数据类型都必须为字符串,不然会报错;因为 t 模式下,只能处理字符串数据;如: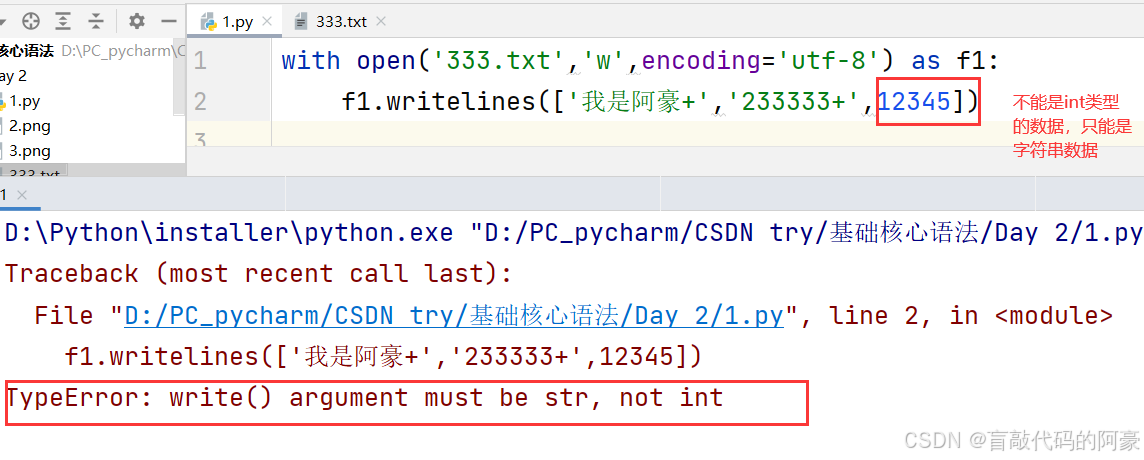
扩展点(用处不大)
格式:
文件对象.encoding,得到文件的字符编码文件对象.name,得到文件的名字
with open('1213.txt','w',encoding='utf-8') as f1:
print(f1.encoding)
print(f1.name)
输出结果:
utf-8
1213.txt
- 文件的修改方式
文件对应的是外存(硬盘),硬盘不能直接修改数据,需要传入内存中修改
两种方式:
-
将原文件的内容全部读取到内存中,修改完成后在覆盖写入原文件当中
优点:在修改过程中,只会有一个文件在使用,不会新建文件,节省外存
缺点:内存占用高,性能不佳 -
以读的方式打开原文件,在以写的方式打开一个新的文件,然后将原文件的内容一行行读取到内存中修改,在一行行的写入新文件当中,最后删除原文件,并将新文件的名字修改为原文件
优点:节省内存,提高性能
缺点:在修改文件过程中创建了一个文件,同一份数据保存了两份,导致外存增加

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 44
44 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)