
【记录】Python|爬虫Playwright获取shadowRoot(close)的内容(附完整代码)
考虑到网上没有比较方便的代码,我把我的探索结果发出来,方便自己也方便别人用。
【记录】Python|Playwright获取shadowRoot(close)的内容
这些年网页设计变化很大,爬虫技术也跟着更新换代了,以前最火的是selenium这种模拟执行的,现在也都变成playwright这种倾向于直接模拟开发者工具的东西了。但这是好事,这让这个技术更加纯粹干净了,省去了很多无用的垃圾操作。
对于shadowroot的问题,它是一个类似于网页注释块的东西,用来隐藏一部分网页代码,保持网页内容大体上整洁干净,但当它被标记为close的时候,就是不希望别的程序能看见并获取。虽然这并不影响查看程序的时候还是能看到其完整内容。这其实和robot.txt一样都属于君子约定。
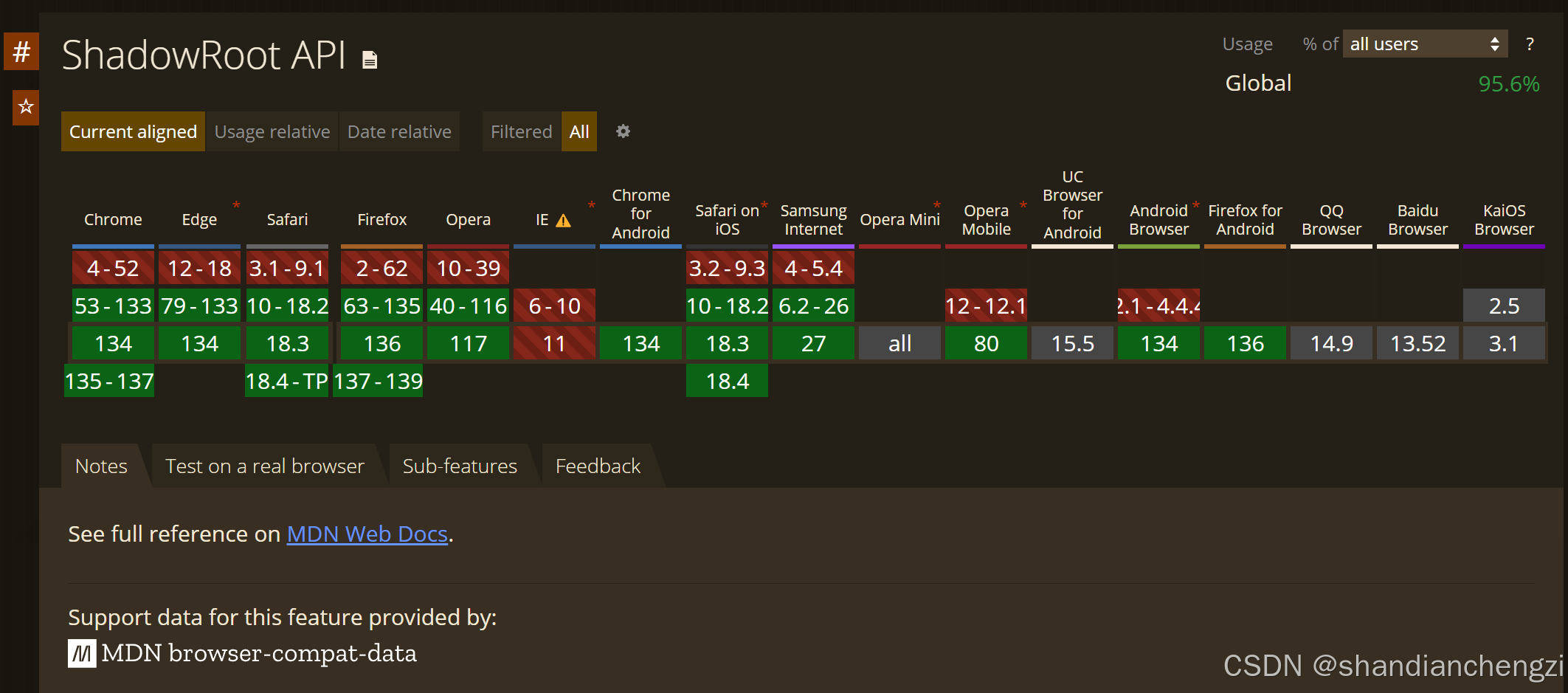
这是一个比较新的特性,不是所有版本的浏览器都支持,支持的浏览器版本如下图所示。
图源:“shadowroot” | Can I use… Support tables for HTML5, CSS3, etc
caniuse.com这个网站是一个很好的检查某个前端API的兼容性的网站,它用的是别人的数据但是它的可视化做得最漂亮。
其真实应用场景如下图所示。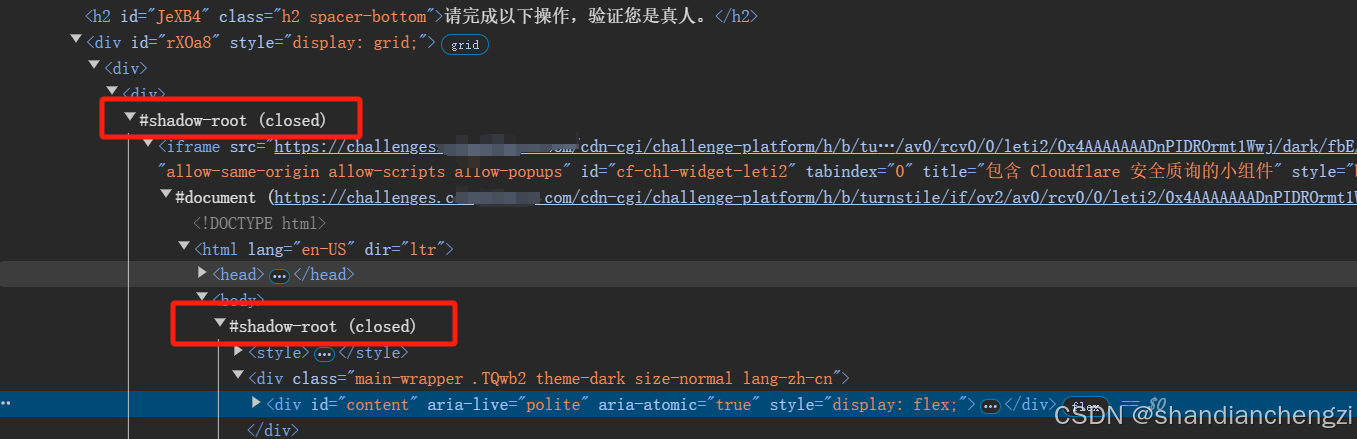
这个东西常常出现在cloudflare防御体系中,绕过人家的防御体系并不是什么友好的事情,但是仅仅是读取这个信息的话还是情有可原。
既然点开了这篇文章,估计也是不想遵循这个君子约定了,但是也希望你们不要用它干坏事,最多是个人学习使用,或者为自己的某些操作增加一点便捷性,方便自己,而不是大规模入侵搞破坏。
网上方法其实已经给得很明白了,但一般就只讲一下方法没给代码,我给一下代码也汇总一下大家的方法。
文章目录
方法一:修改Chrome源码(无代码)
参考:028.爬虫专用浏览器-抓取#shadowRoot(closed)下的内容_网页影子根如何从closed变为open-CSDN博客(于 2024-11-04 15:39:47 修改)
这篇博客讲了怎么直接改掉浏览器源码,让所有close都直接无条件open。我也没有尝试,因为我个人感觉chrome内核更新太快了,这个方法不一定到现在还适用。
具体步骤见下。
修改源码
1.定位源码:
- 打开文件:
\third_party\blink\renderer\core\dom\element.cc - 查找以下代码:
ShadowRoot* Element::attachShadow(const ShadowRootInit* shadow_root_init_dict, ExceptionState& exception_state) {
DCHECK(shadow_root_init_dict->hasMode());
String mode_string = shadow_root_init_dict->mode();
2.进行替换:
ShadowRoot* Element::attachShadow(const ShadowRootInit* shadow_root_init_dict, ExceptionState& exception_state) {
DCHECK(shadow_root_init_dict->hasMode());
//String mode_string = shadow_root_init_dict->mode();
mode_string = "open";
3.编译代码:
ninja -C out/Default chrome
编译完成后,所有的
shadowRoot状态将变为open。
进一步优化
- 针对某些网站的反爬虫检测机制,当检测到
shadowRoot返回非null值时,可能会返回错误信息。为规避这一问题,可以考虑给Element添加一个修改后的shadowRoot2属性。这样,网站继续检测shadowRoot时不会发现问题。
在决定新增属性后,上述的attachShadow()函数就不再需要了。以下是添加shadowRoot2属性的步骤。
1.修改文件 \third_party\blink\renderer\core\dom\element.cc
ShadowRoot* Element::OpenShadowRoot() const {
ShadowRoot* root = GetShadowRoot();
return root && root->GetMode() == ShadowRootMode::kOpen ? root : nullptr;
}
// 追加内容 ===================
ShadowRoot* Element::OpenShadowRoot2() const {
ShadowRoot* root = GetShadowRoot();
return root;
}
// 结束追加内容 ===================
2.修改文件:\third_party\blink\renderer\core\dom\element.h
// 追加内容
ShadowRoot Element::OpenShadowRoot2() const;
// 结束追加内容
3.修改文件:thirdpartyblinkrenderercoredomelement.idl
[RaisesException, MeasureAsElementAttachShadow] ShadowRoot attachShadow(ShadowRootInit shadowRootInitDict);
[PerWorldBindings, ImplementedAsOpenShadowRoot] readonly attribute ShadowRoot? shadowRoot;
// 追加内容
[PerWorldBindings, ImplementedAsOpenShadowRoot2] readonly attribute ShadowRoot? shadowRoot2;
// 结束追加内容
4.编译:
ninja -C out/Default chrome
注意:编译过程可能较为耗时。
通过上述步骤,您可以在Chromium中修改shadowRoot的模式,从而获取原本以Closed模式存储的数据。这种方法适用于特定的开发需求,例如创建高效的爬虫浏览器。在实施这些更改时,请确保您对源代码的修改符合法律法规和道德标准。
方法二:Playwright写程序直接改(附Python代码)
参考: html #shadow-root closed 节点下的dom 如何访问? - 知乎
我这个方法本身是大模型直接给到我的,我自己写的代码,但是后来再仔细搜了一下发现知乎上也提到了,不知道最早是谁提出来的了,反正是能用。

代码的思路就是在page.goto之前添加一个script,内容就是知乎这个回答这个内容,在页面加载之前就执行一遍就可以了。具体代码见下,注意事项我都写在注释里了:
from playwright.sync_api import sync_playwright
class ShadowDOMHelper:
def __init__(self):
self.playwright = sync_playwright().start()
self.browser = self.playwright.chromium.connect_over_cdp('http://localhost:9999')
self.context = self.browser.new_context()
self.page = self.context.new_page()
# 强制开启Shadow DOM访问的核心注入脚本
self.page.add_init_script('''
Element.prototype._attachShadow = Element.prototype.attachShadow;
Element.prototype.attachShadow = function(arg) {
return this._attachShadow({ ...arg, mode: "open" });
};
''')
def __del__(self):
"""资源清理"""
try:
self.page.close()
self.context.close()
if self.browser.is_connected():
self.browser.close()
self.playwright.stop()
except Exception as e:
print(f"清理异常: {str(e)}")
def demo_execution(self):
"""演示访问Shadow DOM的示例"""
try:
# 填你自己的页面的链接
self.page.goto("https://element.eleme.io/#/zh-CN", timeout=10000)
# 填你自己的页面的元素selector
component = self.page.wait_for_selector('.demo-shadow-dom', timeout=5000)
# 在这一步执行结束之后你可以打开chrome看一下自己的开发者工具,看一下那个页面的close是不是变成open了,如果没有变那就很诡异,要再找找原因的。
# 找一下你自己的shadow块的父节点的路径,再对应去找shadowRoot这个Node以及其中的内容
shadow_content = self.page.evaluate('''(el) => {
const shadowRoot = el.shadowRoot;
return shadowRoot.querySelector('.content').innerText;
}''', component)
print("提取到的Shadow DOM内容:", shadow_content)
except Exception as e:
print(f"执行异常: {str(e)}")
if __name__ == "__main__":
helper = ShadowDOMHelper()
helper.demo_execution()
为了让这个代码可以运行,需要以下两步:
- 安装Playwright包:
pip install playwright - 在9999端口运行chrome(路径可能大家的都不一样,自己去找一下自己的exe路径就行):
"C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9999
本账号所有文章均为原创,欢迎转载,请注明文章出处:https://shandianchengzi.blog.csdn.net/article/details/146512892。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 28
28 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)