
KAG LLM + 图谱的五方面增强:知识表示增强、图结构与文本互索引、符号引导的拆解和推理、知识对齐、模型,支付宝支小宝、蚂蚁集团应用算法,医疗问答指标解释准确率 > 93%
这个框架的重要性在于它为构建专业领域的知识服务提供了一个可行的方案,既保持了大语言模型的灵活性,又具备了知识图谱的精确性和可解释性。通过将结构化的知识图谱推理与传统检索相结合,KAG能够实现更准确和更有逻辑性的响应,特别是在需要多跳推理的复杂领域特定查询方面。KAG 目标是在专业领域内实现准确的事实性回答和报告生成,融合不同层级知识创建从严格到宽松的决策范式。与主要依赖向量相似度的传统RAG不同,
KAG LLM + 图谱的五方面增强:知识表示增强、图结构与文本互索引、符号引导的拆解和推理、知识对齐、模型,支付宝支小宝、蚂蚁集团应用算法,医疗问答指标解释准确率 > 93%
论文:https://arxiv.org/pdf/2409.13731
代码:https://github.com/OpenSPG/KAG
理解
KAG是一个通过结合知识图谱(KG)和检索增强生成(RAG)来增强大语言模型(LLM)的框架。
与主要依赖向量相似度的传统RAG不同,KAG集成了结构化的知识推理。
纯向量相似度检索无法很好处理需要多跳推理的问题。
- 知识表示方式:从纯文本到结构化知识图谱
- 检索策略:从单纯相似度匹配到逻辑形式引导
- 推理方法:从单次检索到多轮反思机制
- 知识对齐:从独立知识到语义关联网络
主要组件:
- 面向LLM的知识表示
- 数据/信息/知识的层次化组织
- 图结构和文本之间的互相索引
- 同时支持无模式和有模式约束的知识
- 逻辑形式求解器
- 将复杂查询分解为子问题
- 集成知识图谱推理和文本检索
- 使用反思机制进行多轮求解
- 知识对齐
- 标准化来自不同来源的知识
- 将实例链接到领域概念
- 自动完成语义关系
实验结果:
- 显著超越现有RAG方法:
- HotpotQA提升19.6% F1分数
- 2WikiMultiHopQA提升33.5% F1分数
- 成功应用于蚂蚁集团的电子政务和电子健康场景
局限性:
- 处理阶段需要多次调用LLM,导致计算开销大
- 复杂问题分解需要较高的能力
- 基于OpenIE的抽取会引入噪声,需要额外的对齐工作
关键洞见:
通过将结构化的知识图谱推理与传统检索相结合,KAG能够实现更准确和更有逻辑性的响应,特别是在需要多跳推理的复杂领域特定查询方面。
主要应用:
- 电子政务问答:帮助用户解答关于服务方法、所需材料、服务条件等问题
- 医疗健康问答:支持疾病、症状、疫苗、手术等专业医疗知识咨询
创新点:
- 引入了逻辑形式来指导检索和推理,使系统能更好地处理复杂查询
- 设计了知识对齐机制来提高知识的准确性和连通性
- 实现了图结构和文本的双向增强
这个框架的重要性在于它为构建专业领域的知识服务提供了一个可行的方案,既保持了大语言模型的灵活性,又具备了知识图谱的精确性和可解释性。
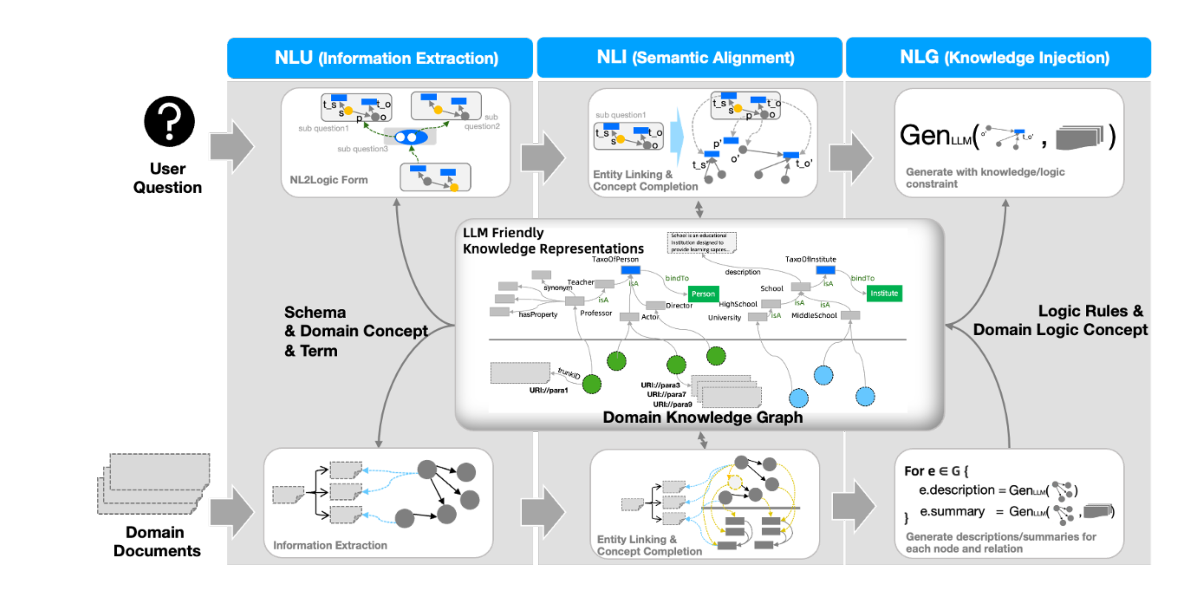
整体架构设计
KAG 由三大核心模块构成:
- KAG-Builder (知识构建器)
- 负责离线索引构建
- 进行信息抽取和结构化
- 执行知识图谱存储
- 处理语义对齐
查询是,双重检索。
先结构化图谱搜索和推理,当图谱无法回答,变成非结构化文本信息检索。
- KAG-Solver (求解器)
- 采用逻辑形式引导推理
- 结合知识图谱和语言模型推理
- 整合多种检索方法
- 支持多轮反思迭代
逻辑形式求解器:将复杂查询分解为可执行步骤,整合图检索和文本检索,多轮反思和迭代求解。
- KAG-Model (模型增强)
- 增强自然语言理解(NLU)能力
- 提升自然语言推理(NLI)能力
- 改进自然语言生成(NLG)能力
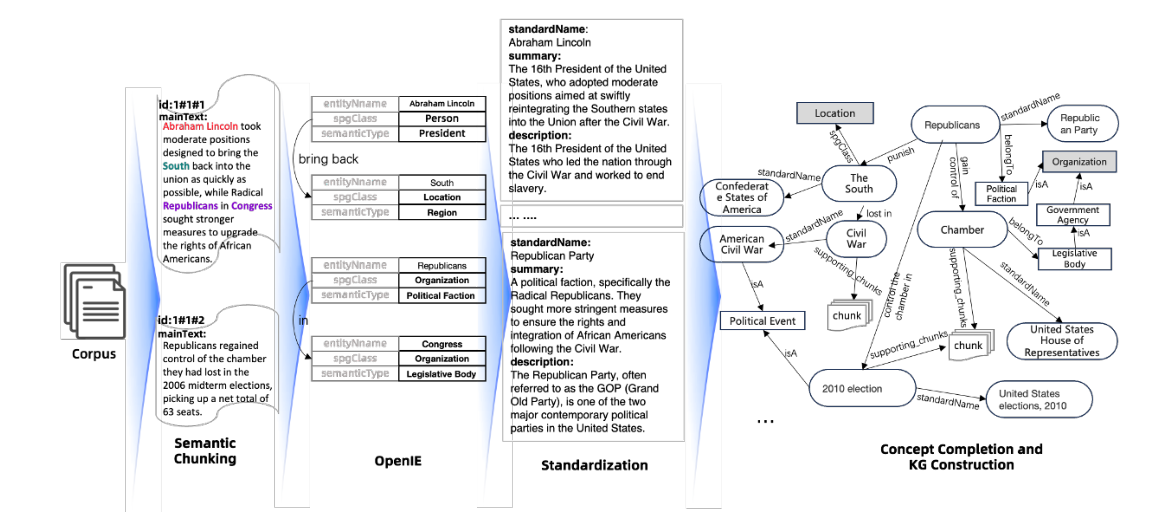
知识压缩
LLMFriSPG 框架通过三层结构压缩知识:
原始文档 -> 文本块(RC) -> 图信息(KGfr) -> 规范知识(KGcs)
- 原始文档 (医学教材/指南片段):
成年人2型糖尿病是一种以胰岛素抵抗和分泌不足为特征的代谢性疾病。
早期主要表现为多饮、多尿、多食和体重下降等症状。
诊断标准为:空腹血糖≥7.0mmol/L,或75g口服葡萄糖耐量试验2h血糖≥11.1mmol/L。
治疗上,首选二甲双胍单药治疗,建议从小剂量开始,500mg每日1-2次,随后根据耐受情况及血糖水平逐渐加量。
如单药效果不佳,可考虑联合其他降糖药物。同时要加强血糖监测,定期检查肝肾功能。
- 文本块(RC):
通过语义分块,将原文分成多个独立但相关的知识块:
[定义块]
成年人2型糖尿病是一种以胰岛素抵抗和分泌不足为特征的代谢性疾病。
[症状块]
早期主要表现为多饮、多尿、多食和体重下降等症状。
[诊断块]
诊断标准为:空腹血糖≥7.0mmol/L,或75g口服葡萄糖耐量试验2h血糖≥11.1mmol/L。
[治疗块]
治疗上,首选二甲双胍单药治疗,建议从小剂量开始,500mg每日1-2次,随后根据耐受情况及血糖水平逐渐加量。
[监测块]
要加强血糖监测,定期检查肝肾功能。
- 图信息(KGfr):
将文本块转化为实体和关系的图结构:
实体:
- 疾病: 2型糖尿病
- 症状: {多饮, 多尿, 多食, 体重下降}
- 检查指标: {空腹血糖, 口服葡萄糖耐量试验}
- 药物: 二甲双胍
- 监测项目: {血糖, 肝功能, 肾功能}
关系:
- (2型糖尿病, 特征是, 胰岛素抵抗)
- (2型糖尿病, 表现为, 多饮)
- (2型糖尿病, 诊断标准, 空腹血糖≥7.0mmol/L)
- (2型糖尿病, 治疗用药, 二甲双胍)
- (二甲双胍, 用法用量, 500mg每日1-2次)
- 规范知识(KGcs):
将图信息规范化为标准化的医学知识:
疾病本体:
- ID: T2DM_001
- 名称: 2型糖尿病
- 分类: 代谢性疾病
- ICD编码: E11
诊断规则:
IF 空腹血糖 >= 7.0mmol/L OR
OGTT_2h >= 11.1mmol/L
THEN 确诊_2型糖尿病
治疗规范:
IF 初次诊断_2型糖尿病 AND 无禁忌证
THEN 推荐_二甲双胍 {
初始剂量: 500mg/次
频次: 1-2次/日
调整原则: 根据耐受性和血糖水平
}
监测方案:
WHEN 诊断_2型糖尿病
SCHEDULE {
血糖监测: 每日,
肝功能检查: 每3月,
肾功能检查: 每3月
}
这个转化过程展示了信息是如何逐步被结构化和规范化的:
- RC层保留了原始语义但提供了更清晰的结构
- KGfr层将非结构化文本转换为可计算的图结构
- KGcs层引入了标准化的专业规范和可执行的规则
在这个过程中:
- 信息密度不断提高
- 知识结构更加规范
- 可计算性逐步增强
- 专业性持续提升
这种层次化的知识表示让系统能够:
- 在RC层处理自然语言问题
- 在KGfr层进行知识推理
- 在KGcs层执行专业决策
解法拆解
1. 知识表示解法:
子解法1 = DIKW分层表示
特征:知识有层次性和演进性
例子:医疗知识从检验数据->诊断信息->治疗方案->专家经验
之所以采用DIKW分层,是因为专业领域知识天然具有从数据到智慧的演进特性
子解法2 = 语义互联表示
特征:知识点之间存在复杂关联
例子:药品说明书中的适应症、禁忌症、用法用量等多维关联关系
之所以采用语义互联,是因为专业知识往往需要多维度联系才能准确表达
2. 互索引解法:
子解法 = 图结构倒排索引
特征:需要同时保证检索效率和语义完整性
例子:根据"青霉素过敏"能同时找到相关药品、病历和处置方案
之所以采用图结构索引,是因为需要在快速检索的同时保持知识的语义关联
3. 混合推理解法:
子解法1 = 符号推理(处理确定性规则)
特征:存在明确的专业规范和标准
例子:诊断标准的判定、处方开具的规则检查
之所以用符号推理,是因为专业决策首先要符合明确的规范要求
子解法2 = 向量检索(处理相似性问题)
特征:需要参考历史经验和类似案例
例子:寻找相似病例进行参考
之所以用向量检索,是因为专业实践中往往需要借鉴相似经验
子解法3 = 大模型推理(处理复杂综合问题)
特征:需要处理非结构化和开放性问题
例子:根据病情描述生成诊疗建议
之所以用大模型推理,是因为实际应用中常常遇到需要综合分析的复杂问题
推理过程
将复杂问题分解为基本推理模式:
问题 -> 逻辑表达式 -> {规划,推理,检索}算子组合
基本算子模式:
- 检索:(s,p,o)三元组匹配
- 排序:(集合,方向,限制)
- 数学:表达式计算
- 推导:(左项,右项,操作符)
问题:
一位45岁患者,空腹血糖8.1mmol/L,近期出现多饮多尿,BMI指数28,是否需要开始二甲双胍治疗?
逻辑表达式分解:
1. 检查是否符合糖尿病诊断
2. 评估患者风险因素
3. 确认治疗方案适用性
算子组合执行:
- 检索算子 - 诊断标准匹配:
Retrieval(
s = "2型糖尿病",
p = "诊断标准",
o = "空腹血糖值"
) -> 阈值 = 7.0mmol/L
Retrieval(
s = "2型糖尿病",
p = "症状表现",
o = ["多饮", "多尿"]
)
- 数学算子 - 判断条件:
Math(
expr = "血糖值 >= 诊断阈值"
values = {
血糖值: 8.1,
诊断阈值: 7.0
}
) -> true
Math(
expr = "18.5 <= BMI <= 24"
values = {
BMI: 28
}
) -> false // 超重
- 推导算子 - 风险评估:
Deduce(
left = ["高血糖", "超重", "多饮多尿"],
right = "2型糖尿病高风险",
op = "entailment"
) -> true
- 检索算子 - 治疗方案:
Retrieval(
s = "2型糖尿病",
p = "初始治疗方案",
o = "治疗方案"
) -> {
"药物": "二甲双胍",
"禁忌症": ["严重肝肾功能不全", "酮症酸中毒"],
"起始剂量": "500mg",
"频次": "每日2次"
}
- 排序算子 - 优先级判断:
Sort(
set = ["生活方式干预", "二甲双胍", "其他降糖药"],
direction = "优先级",
limit = 1
) -> "二甲双胍"
- 最终推导:
Deduce(
left = [
"确诊糖尿病",
"无禁忌症",
"一线用药推荐"
],
right = "开始二甲双胍治疗",
op = "equal"
) -> true
最终答案生成:
建议开始二甲双胍治疗。理由:
1. 患者空腹血糖8.1mmol/L,已超过诊断标准(7.0mmol/L)
2. 存在典型症状(多饮多尟)
3. BMI 28提示超重,属于危险因素
4. 符合二甲双胍治疗适应症
建议从500mg每日两次开始,同时加强血糖监测和生活方式干预。
这个例子展示了如何将一个复杂的医疗决策问题分解为一系列基本算子的组合:
- 检索算子用于获取相关医学知识
- 数学算子用于指标判断
- 推导算子用于风险评估
- 排序算子用于治疗方案优先级排序
整个过程体现了:
- 结构化的推理过程
- 知识的逐层应用
- 多维度的证据整合
- 专业规则的形式化表达
这种算子组合方式使得系统能够:
- 模拟医生的诊断思维过程
- 保证推理过程的可解释性
- 确保决策的专业性和规范性
- 支持复杂条件的综合判断
KAG 对比微软 GraphRAG
GraphRAG 范式的两种主要实现:微软的 GraphRAG 和 HippoRAG。
尽管微软的 GraphRAG 在摘要生成类任务上有不错表现,但在事实问答准确率上表现不佳。
核心特点:
- 重点是构建社区级和元素级摘要
- 用图谱做文档组织和摘要生成
- 偏向生成长文本回答
局限:
- 事实准确率不够高
- 专业性知识推理不足
而 HippoRAG 通过图结构构建倒排索引,显著提升了文档召回的相关性和事实问答的准确性。
核心特点:
- 用图结构构建倒排索引
- 增强了文档检索相关性
- 偏向精确的事实回答
优势:
- 提高了文档召回率
- 事实问答准确度高
KAG 目标是在专业领域内实现准确的事实性回答和报告生成,融合不同层级知识创建从严格到宽松的决策范式。
类比
传统RAG像是只有病历库的医院:
- 只能按症状模糊查找相似病例
- 无法进行系统的诊断推理
- 缺乏标准化的治疗方案
微软GraphRAG像是增加了病例总结的医院:
- 有病例摘要便于快速浏览
- 建立了疾病关联网络
- 但可能忽略关键细节
HippoRAG像是增加了精确检索系统的医院:
- 能快速定位相关病例
- 提供准确的检查结果
- 但缺乏完整的诊疗规范
KAG像是现代化的三级医院:
病历层(RC):
- 完整的病历档案
- 详细的检查记录
- 治疗过程记录
诊疗层(KGfr):
- 症状关联分析
- 检查结果关联
- 治疗方案索引
规范层(KGcs):
- 诊疗规范
- 用药指南
- 治疗流程
知识表示的增强
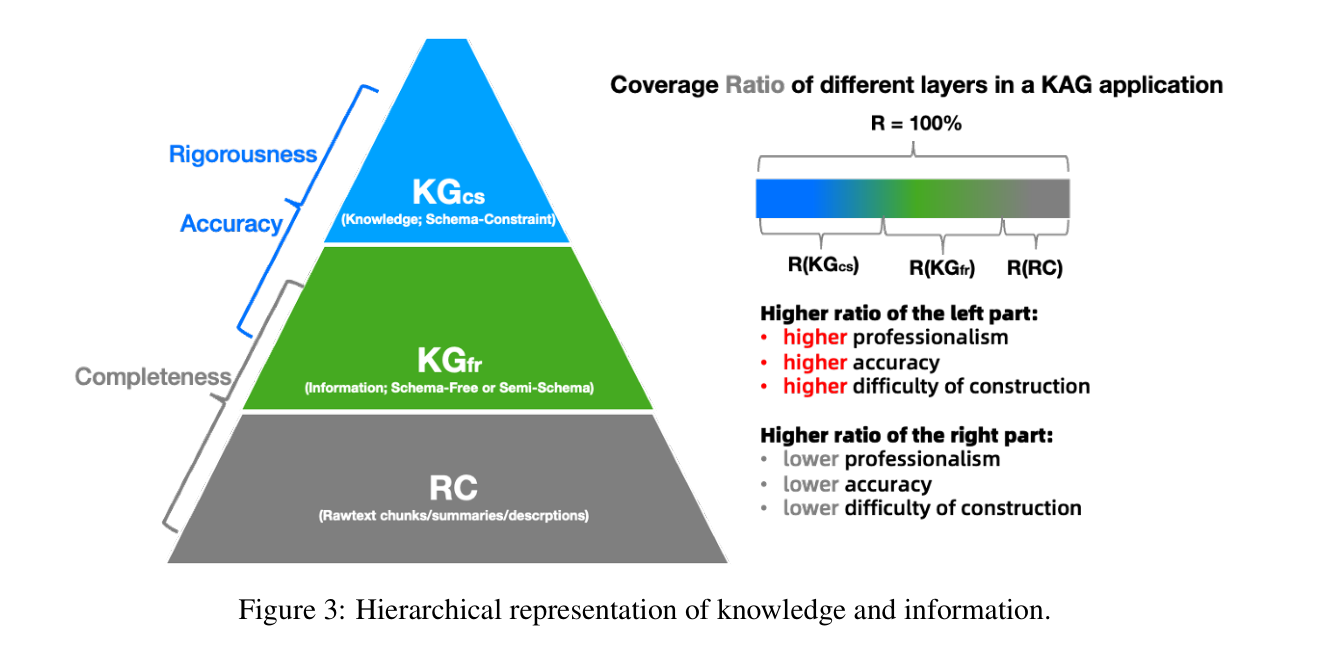
KAG 知识表示:
- 引入了LLMFriSPG框架,采用三层层次化知识结构:
- KGcs(知识层):具有严格模式约束的领域知识
- KGfr(图信息层):抽取的实体和关系
- RC(原始文本块层):原始文档片段
- 支持图结构和文本块之间的互索引
- 强调不同粒度知识之间的语义对齐
原来:经典知识图谱
- 实体-关系-实体的二元组结构
- 缺乏上下文和时序信息
- 难以适配大模型应用
现在:LLMFriSPG表示
- DIKW分层的多元组织结构
- 保留原文上下文和语义信息
- 支持Schema约束和无模式建模
1. 从静态二元到多元动态:
传统知识图谱(静态二元):
实体1 ----关系----> 实体2
例如:
糖尿病 --治疗药物--> 二甲双胍
升级后(多元动态):
实体 + 属性 + 时间 + 上下文 + 来源
例如:
{
主体: "糖尿病",
关系: "治疗药物",
客体: "二甲双胍",
时间: "2024版指南",
适用条件: "无肾功能不全",
证据等级: "A级推荐",
来源文献: "中国糖尿病防治指南"
}
2. DIKW层次表示:
数据(Data):原始数字
↓
信息(Information):有意义的数据
↓
知识(Knowledge):可复用的模式
↓
智慧(Wisdom):决策规则
医疗领域示例:
D(数据层):
"血糖值8.3mmol/L"
I(信息层):
"患者空腹血糖8.3mmol/L,高于正常范围"
K(知识层):
"空腹血糖≥7.0mmol/L是糖尿病诊断标准之一"
W(智慧层):
"对于新诊断的2型糖尿病患者,若无禁忌证,
建议首选二甲双胍单药治疗"
3. 三种建模方式的统一:
- Schema约束模式:
# 严格的专业规范
class DiabetesDiagnosis:
blood_glucose: float # 必须是数值
diagnostic_criteria: str # 必须是标准诊断项
confidence_level: str # 必须是规定的置信度级别
- 无模式建模:
# 灵活的知识扩展
{
"相关症状": ["口干", "多饮", "多尿"],
"生活建议": "控制碳水摄入",
"患者反馈": "服药后胃部不适"
}
- 文本结构:
# 原始文本保留
{
"原文": "患者王某,男,56岁,空腹血糖8.3mmol/L...",
"分段": ["病史描述", "检查结果", "诊疗方案"],
"关键片段": ["血糖持续升高", "并发高血压"]
}
4. LLM友好的知识表示:
例如描述一个医疗实体:
{
# 基础信息
"实体ID": "MED_DISEASE_001",
"名称": "2型糖尿病",
# 自然语言描述(LLM友好)
"description": "2型糖尿病是一种以胰岛素抵抗为主的代谢性疾病...",
"summary": "常见的慢性代谢性疾病,特征是血糖升高",
# 结构化信息(机器友好)
"属性": {
"ICD编码": "E11",
"疾病类别": "内分泌代谢疾病",
"诊断标准": {...}
},
# 文本上下文
"supporting_chunks": [
"来自教科书的定义",
"来自指南的诊断标准",
"来自病例的典型表现"
]
}
5. 实际应用优势:
- 知识的多维表达:
- 结构化表示:便于计算处理
- 自然语言描述:便于LLM理解
- 上下文保留:便于溯源验证
- 灵活的知识组织:
- 严格规范:专业标准
- 灵活扩展:新知识整合
- 原文保留:完整信息
- 智能处理增强:
- 支持复杂推理
- 提供知识溯源
- 便于知识更新
这种设计使得:
- LLM能更好理解和使用知识
- 系统能同时支持严格和灵活的应用场景
- 知识能持续积累和演进
特别适合:
- 医疗诊断
- 法律咨询
- 金融分析
等需要专业性和灵活性并重的领域
图结构与文本互索引:将原有的 term-based 倒排索引升级为 graph-based 倒排索引
原来:term-based检索
- 基于关键词匹配
- 检索结果离散
- 召回率和准确率不足
现在:graph-based检索
- 基于语义图的结构化检索
- 知识关联完整保留
- 准确性和可解释性提升
1. 传统的term-based倒排索引:
关键词 -> 文档列表
例如:
"糖尿病" -> [文档1, 文档3, 文档8]
"血糖" -> [文档2, 文档3, 文档7]
局限性:
- 仅基于关键词匹配
- 忽略语义关联
- 不理解上下文
2. 升级后的graph-based倒排索引:
以医疗文档为例:
原始文档片段:
"2型糖尿病患者空腹血糖≥7.0mmol/L,建议使用二甲双胍进行治疗,起始剂量500mg,每日两次。"
互索引结构:
1. 实体节点:
- 疾病: 2型糖尿病
- 指标: 空腹血糖
- 药物: 二甲双胍
- 剂量: 500mg
2. 概念关系:
疾病 -诊断标准-> 指标
疾病 -治疗方案-> 药物
药物 -用法用量-> 剂量
3. 文本块链接:
每个实体/关系都链接到原始文本块
3. 具体示例展示:
医疗诊断场景:
文本块ID: med_doc_001_block_3
内容: "2型糖尿病患者空腹血糖≥7.0mmol/L..."
互索引结构:
实体索引:
2型糖尿病 -> {
类型: 疾病,
描述: "以胰岛素抵抗为特征的代谢性疾病",
文本块: [med_doc_001_block_3, ...],
关联概念: ["代谢疾病", "慢性病"],
规范名称: "II型糖尿病"
}
指标索引:
空腹血糖 -> {
类型: 检验指标,
单位: "mmol/L",
参考值: "3.9-6.1",
文本块: [med_doc_001_block_3, ...],
上下位关系: ["血糖检测" -> "生化指标"]
}
关系索引:
诊断标准 -> {
主体: "2型糖尿病",
客体: "空腹血糖≥7.0mmol/L",
文本块: [med_doc_001_block_3],
规则类型: "诊断规则"
}
4. 检索过程对比:
传统检索:
查询:"糖尿病的诊断标准是什么?"
过程:
关键词匹配 -> 文档列表 -> 人工筛选
互索引检索:
查询:"糖尿病的诊断标准是什么?"
过程:
1. 实体识别:
- 识别"糖尿病"为疾病实体
- 识别"诊断标准"为关系类型
2. 图谱遍历:
糖尿病 -诊断标准-> 检验指标
3. 证据提取:
- 获取相关文本块
- 提取具体标准值
4. 规范验证:
- 对照专业规范
- 确认最新标准
5. 优势:
- 语义理解:
- 理解实体间关系
- 支持概念推理
- 保留上下文
- 精确定位:
- 直接定位相关实体
- 快速获取证据支持
- 准确关联相关内容
- 知识融合:
- 融合结构化知识
- 保留原始文本
- 支持规则推理
这种互索引结构实现了:
- 文本到知识的映射
- 知识到文本的溯源
- 多维度的知识关联
特别适合:
- 专业知识检索
- 证据链推理
- 知识图谱应用
混合推理:符号决策、向量检索与大模型
KAG 推理机制:
- 采用逻辑形式引导的混合推理:
- 将复杂查询分解为逻辑形式
- 集成图谱推理、语言推理和数值计算
- 支持迭代反思和改进
- 使用语义推理进行知识对齐
原来:单一推理
- 仅依赖图谱规则
- 推理能力受限
- 无法处理复杂场景
现在:三重混合推理
- 符号推理确保严谨性
- 向量检索提供相似性
- 大模型处理复杂问题
1. 混合推理的三个核心组件:
符号决策:严格的规则推理
↓
向量检索:相似案例查找
↓
大模型:复杂分析与综合
2. 案例:糖尿病诊疗决策
输入问题:
一位56岁患者,空腹血糖8.3mmol/L,有高血压病史,近期出现视物模糊,是否建议使用二甲双胍?
混合推理过程:
- 符号决策(严格规则):
IF 空腹血糖 >= 7.0mmol/L THEN
诊断 = "糖尿病"
需要_药物治疗 = TRUE
IF 有_并发症 AND 需要_药物治疗 THEN
需要_全面评估 = TRUE
- 向量检索(相似案例):
检索条件:
- 年龄相近
- 血糖水平相似
- 有并发症
- 用药情况
返回相似病例:
- 案例1: 55岁,血糖8.1,高血压,成功使用二甲双胍
- 案例2: 58岁,血糖8.5,视网膜病变,改用其他药物
- 大模型分析(综合判断):
输入:
- 符号推理结果
- 相似案例
- 专业指南
分析:
- 评估用药风险
- 考虑并发症影响
- 制定个性化方案
3. 推理流程示例:
# 第一步:符号推理
def symbol_reasoning(patient_data):
rules = {
"诊断规则": "空腹血糖>=7.0",
"用药规则": "一线用药=二甲双胍",
"禁忌规则": "肾功能不全=禁用"
}
return rules_check(patient_data)
# 第二步:向量检索
def vector_search(patient_case):
similar_cases = search_database(
age=patient_case.age,
symptoms=patient_case.symptoms,
conditions=patient_case.conditions
)
return similar_cases
# 第三步:大模型分析
def llm_analysis(
rule_results,
similar_cases,
patient_data
):
comprehensive_analysis = LLM.analyze(
context=[
rule_results,
similar_cases,
patient_data
]
)
return comprehensive_analysis
4. 各组件优势互补:
- 符号决策优势:
- 严格的逻辑规则
- 明确的诊断标准
- 可验证的推理过程
- 向量检索优势:
- 寻找相似案例
- 补充经验证据
- 发现潜在模式
- 大模型优势:
- 综合分析能力
- 处理复杂情况
- 生成解释说明
5. 实际应用场景:
医疗诊断:
符号决策:检查诊断标准
向量检索:查找相似病例
大模型:综合分析建议
法律咨询:
符号决策:检查法律条款
向量检索:查找相关判例
大模型:分析适用性
金融风控:
符号决策:验证合规规则
向量检索:查找相似案例
大模型:评估风险等级
6. 决策路径示例:
输入问题
↓
符号决策:应用专业规则
↓
向量检索:获取相关案例
↓
大模型分析:
- 规则验证结果
- 相似案例参考
- 特殊情况分析
↓
综合建议生成
这种混合推理方式:
- 保证了决策的专业性(符号规则)
- 提供了经验支持(向量检索)
- 实现了灵活应变(大模型分析)
特别适合:
- 需要严格规则的专业领域
- 存在大量历史案例的场景
- 需要灵活处理特殊情况的应用
通过这种混合推理:
- 既保证了决策的严谨性
- 又提供了足够的灵活性
- 同时保持了可解释性
符号引导的拆解和推理
传统推理方式:
1. 问题处理:
- 直接将自然语言转为查询
- 缺乏系统性的问题分解
- 容易丢失关键信息
2. 推理过程:
- 单一的图谱匹配
- 固定的推理规则
- 无法处理复杂逻辑
3. 答案生成:
- 简单的模板填充
- 缺乏证据支持
- 容易产生幻觉
4. 知识利用:
- 仅使用局部知识
- 知识孤立使用
- 难以融合多源信息
KAG符号引导方式:
1. 问题处理:
- 系统性问题分解
- 转化为逻辑表达式
- 保留问题结构信息
2. 推理过程:
- 分层递进式推理
第一层:在逻辑知识层检索
第二层:转向开放信息层
第三层:关联文档检索
- 混合推理策略
符号推理:处理确定性规则
向量检索:寻找相似案例
大模型推理:综合分析判断
3. 答案生成:
- query-focused摘要
- 基于知识图谱反馈
- 结构化生成约束
4. 知识利用:
- KGDSL/GQL转换
- 精确匹配+SPO检索
- 三元组注入增强
5. 质量控制:
- 知识图谱反馈校验
- 结构范式约束
- 幻觉率显著降低
举例:
医疗诊断场景:
传统方式:
问题:"患者头痛三天,该如何处理?"
↓
直接匹配相关症状和处理方案
↓
返回常规建议
KAG方式:
1. 问题分解:
- 症状分析:头痛性质、持续时间
- 病因排查:原发性/继发性
- 风险评估:是否需要紧急处理
- 治疗决策:用药建议/就医建议
2. 逻辑表达式生成:
Retrieval(
症状="头痛",
持续="3天",
需查属性=[
"性质",
"伴随症状",
"危险信号"
]
)
3. 分层推理:
- 规则层:匹配诊断指南
- 经验层:检索相似病例
- 综合层:生成个性化建议
4. 答案生成:
- 基于证据的分析
- 分级的处理建议
- 包含警示信息
基于概念的知识对齐
原来:简单映射
- 概念对应关系固定
- 领域知识割裂
- 更新成本高
现在:语义级对齐
- 动态知识融合
- 领域概念打通
- 更新机制灵活

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 23
23 0
0- 0



 已为社区贡献111条内容
已为社区贡献111条内容

所有评论(0)