
【效率提升】使用 StopWatch 统计代码中的耗时操作
在Java开发中,对于需要做性能优化的接口,可以通过StopWatch优雅的实现各个节点的耗时监控,根据获取到的监控数据再针对性的进行优化。方法的调用,相对于背景中的两个时间相减,语义会更加明确一点。如果想要计算两个阶段之间的耗时的话,可以写一个新的StopWatch来继承Apache的StopWatch,并拓展对应方法。,由于Sleep的精确性,可能会有几号秒的误差,但实际上,这个工具并没有这么
1.背景
在成功开发出一个具有一定复杂性的接口之后,很有可能需要针对接口的性能展开优化工作。而在着手优化之前,必须明晰接口里每个细分方法的执行所耗费的时间,从而精准判定接口的“性能瓶颈”所在。只有完成瓶颈的确定,才能够具有针对性地实施优化操作。
在之前的工作中,通常会选择使用下面这种方法来统计耗时:
public static void main(String[] args) throws InterruptedException {
long start = System.currentTimeMillis();
Thread.sleep(1000);
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) + "ms");
}
在需要统计耗时的点较多的时候,这种方式会显得有点繁琐,经过一些调研之后发现,可以使用StopWatch来处理统计代码中的耗时操作。
2.StopWatch的使用
这里说的StopWatch是一些三方包中的工具类,其底层还是通过记录每个节点的时间戳来实现的耗时计算。本篇文章中有两种StopWatch的使用方式,可以选择自己喜欢的那一种来使用。
2.1.Apache Lang3中的StopWatch
先引入jar包:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
修改一下上面记录耗时的方法,就变成了:
import org.apache.commons.lang3.time.StopWatch;
public static void main(String[] args) throws InterruptedException {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Thread.sleep(1000);
stopWatch.stop();
// 输出结果
System.out.println("Total time: " + stopWatch.getTime() + " ms");
}
可以看到的是,使用这种方式来做统计,start()和stop()方法的调用,相对于背景中的两个时间相减,语义会更加明确一点。但是还有体现出更多的优势,接下来继续看,如果需要记录多个时间应该怎么做。
public static void main(String[] args) throws InterruptedException {
StopWatch stopWatch = new StopWatch();
// 开始计时
stopWatch.start();
// 第一阶段
Thread.sleep(1000);
stopWatch.split();
System.out.println("First part took: " + stopWatch.getSplitTime() + " ms");
// 第二阶段
Thread.sleep(2000);
stopWatch.split();
System.out.println("Second part took: " + stopWatch.getSplitTime() + " ms");
// 停止计时
stopWatch.stop();
System.out.println("Total time: " + stopWatch.getTime() + " ms");
}
我们可以看到的是,在每个阶段里面使用了split()方法来做分割,并且通过getSplitTime()来获取当前阶段的执行时间。
如果预计的没有错的话,三次打印应该分别打印出1000ms,2000ms,3000ms,由于Sleep的精确性,可能会有几号秒的误差,但实际上,这个工具并没有这么打印,下面看一下运行结果。
First part took: 1001 ms
Second part took: 3008 ms
Total time: 3009 ms
我们发现,第二阶段打印的时间是3000ms,也就是说第二阶段并没有从第一阶段的结束开始计时,而是从start() 开始计时的。为此,我翻看了一下源码做一下确认: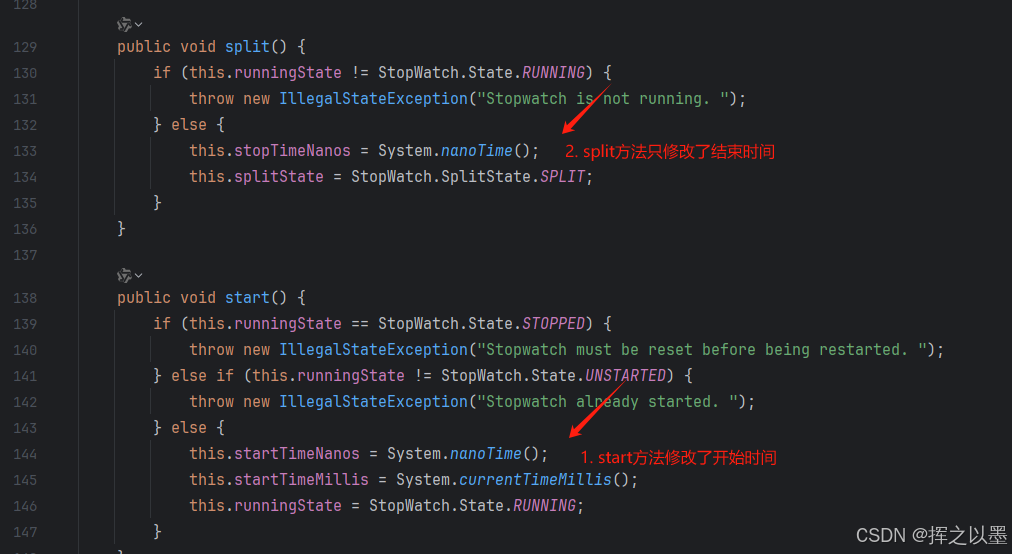
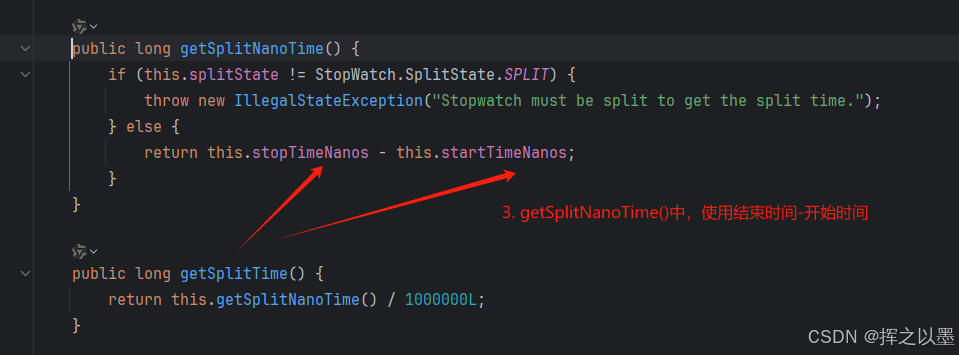
看这个结果确实和猜测的一致,也就是说,如果要使用这个工具的话,需要注意split后并不是计算的两个阶段之间的耗时,而是从start()到当前阶段的耗时。
如果想要计算两个阶段之间的耗时的话,可以写一个新的StopWatch来继承Apache的StopWatch,并拓展对应方法。
但既然有现成的工具,能不重新造轮子就不要重新造轮子,于是我发现了HuTool中的StopWatch工具。
2.2.Hutool 中的StopWatch
HuTool中的StopWatch使用方式与Apache中的大同小异,不过它实现了阶段之间的计数功能,下面直接看代码:
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.31</version>
</dependency>
import cn.hutool.core.date.StopWatch;
import java.util.concurrent.TimeUnit;
/**
* 耗时监控
*
* @author liushuang
* @date 2024/8/23 14:54
*/
public class TimeCost {
public static void main(String[] args) throws InterruptedException {
StopWatch stopWatch = new StopWatch();
stopWatch.start("第一阶段");
Thread.sleep(1000);
stopWatch.stop();
stopWatch.start("第二阶段");
Thread.sleep(2000);
stopWatch.stop();
stopWatch.start("第三阶段");
Thread.sleep(500);
stopWatch.stop();
System.out.println(stopWatch.prettyPrint(TimeUnit.MILLISECONDS));
}
}
和Apache不同的是,这里的start可以定义描述,stop表示的是当前Task停止,所以在每个阶段都定义了一个start()和一个stop()。最后通过prettyPrint打印出监控信息,可以传入一个TimeUnit,在结果中就会按这个时间单位打印,最终得到的结果如下: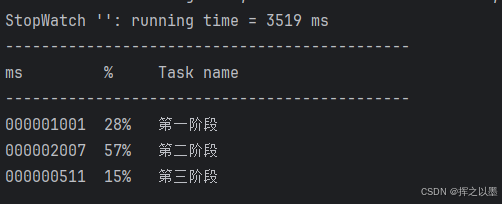
总运行时间:3519ms
下面打印出了每个阶段的耗时,及其实践占用的百分比。
有了这个结果之后,就可以定位到相对比较耗时的代码的位置,做出针对性的优化。
3.结论
在Java开发中,对于需要做性能优化的接口,可以通过StopWatch优雅的实现各个节点的耗时监控,根据获取到的监控数据再针对性的进行优化。
这里强烈推荐HuTool的工具包,可以节省不少力气。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)