
图像文字OCR识别:Tess4J、Spire-OCR
1、Tess4J 是 Tesseract OCR 引擎的 Java JNA 封装,提供了一个能力强大的接口来实现这一功能。。开源免费。2、本文环境:Java JDK 11 + Spring boot 2.6.3 + tess4j 5.14.01、从官网下载字体库,chi_sim.traineddata 是中文字体库,eng.traineddata 是英文字体库,其它语言,不使用时,可以不用下载。2
目录
Tess4J 图像文字OCR识别
1、Tess4J 是 Tesseract OCR 引擎的 Java JNA 封装,提供了一个能力强大的接口来实现这一功能。官网:https://tess4j.sourceforge.net/。开源免费。
2、本文环境:Java JDK 11 + Spring boot 2.6.3 + tess4j 5.14.0
步骤1:引入 tess4j 依赖
<!-- https://mvnrepository.com/artifact/net.sourceforge.tess4j/tess4j -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>5.14.0</version>
</dependency>pom.xml · 汪少棠/sqliteapp3 - Gitee.com。
步骤2:下载Tessdata语言库
1、从官网下载 https://github.com/tesseract-ocr/tessdata 字体库,chi_sim.traineddata 是中文字体库,eng.traineddata 是英文字体库,其它语言,不使用时,可以不用下载。
2、下载后随便放在哪里都行,代码中使用绝对路径指向它即可。
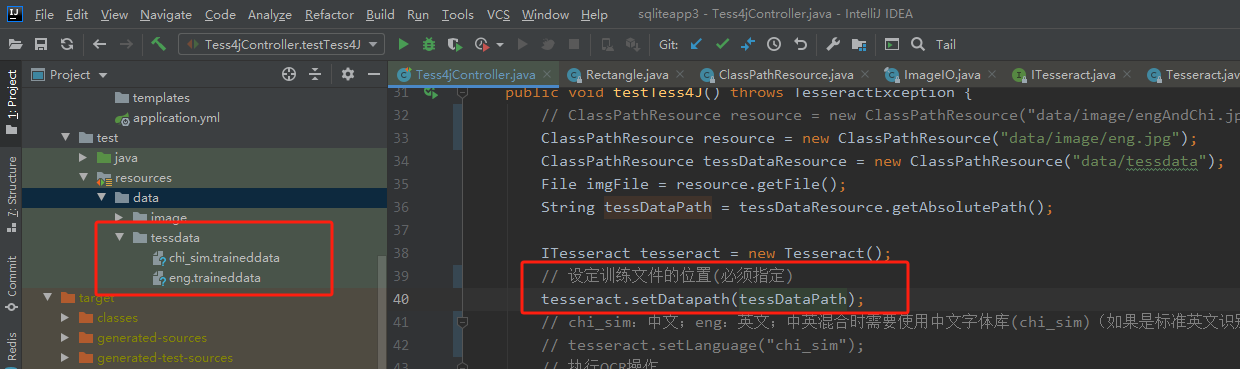
步骤3:图片OCR文字识别
1、实测效果中文并不是很理想,纯英文效果不错。
/**
* String doOCR(File imageFile):执行OCR操作,读取图片内容
* String doOCR(File imageFile, List<Rectangle> rects):读取图片中指定范围内的内容
*
* @throws TesseractException
*/
@Test
public void testTess4J() throws TesseractException {
ClassPathResource resource = new ClassPathResource("data/image/中英文.jpg");
// ClassPathResource resource = new ClassPathResource("data/image/纯英文.jpg");
ClassPathResource tessDataResource = new ClassPathResource("data/tessdata");
File imgFile = resource.getFile();
String tessDataPath = tessDataResource.getAbsolutePath();
ITesseract tesseract = new Tesseract();
// 设定训练文件的位置(必须指定)
tesseract.setDatapath(tessDataPath);
// chi_sim:中文;eng:英文;中英混合时需要使用中文字体库(chi_sim)(如果是标准英文识别(eng),此步可省略);
tesseract.setLanguage("chi_sim");
// 执行OCR操作。
String resultText = tesseract.doOCR(imgFile);
// resultText = resultText.replaceAll(" ", "");
// 读取局部位置
// Rectangle rectangle = new Rectangle(0, 0, 400, 200);
// String resultText2 = tesseract.doOCR(imgFile, Lists.list(rectangle));
System.out.println(resultText);
}src/test/java/com/wmx/sqliteapp3/tess4j/Tess4jTest.java · 汪少棠/sqliteapp3 - Gitee.com。
Spire-OCR 图像文字OCR识别
1、Spire.OCR for Java 是一款专业的用于文字识别的 Java OCR(图文识别)组件,用以读取 JPG、PNG、GIF、BMP 和 TIFF 等图片格式中的文本。利用该组件,开发人员可以在 Java 应用程序中实现 OCR 功能。
2、Spire.OCR for Java 操作简单易用,仅需一小串 Java 代码,便可轻松读取 JPG、PNG、GIF、BMP 和 TIFF 等常用图片中的文本信息。
3、此外,Spire.OCR for Java 功能非常强大, 支持识别各种常用印刷字体,如 宋体、仿宋、黑体、微软雅黑、Arial, Times New Roman, Courier New, Verdana, Tahoma 、Calibri 等;支持识别粗体、斜体、简体、繁体等字体样式;支持扫描全图,并且能识别多种语言文字,如英语,中文,法语,德语,日语及韩语等。
试用版在功能上没有任何限制,只是在结果文档中有试用提示信息。当您购买并应用 license 后,会成功移除这些提示信息。
步骤1:引入 Spire.OCR 依赖(官网)
<dependencies>
<!-- https://mvnrepository.com/artifact/e-iceblue/spire.ocr -->
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.ocr</artifactId>
<version>1.9.22</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>pom.xml · 汪少棠/sqliteapp3 - Gitee.com。
步骤2:下载语言模型
Linux(须使用 CentOS 8、Ubuntu 18 及以上版本)
下载后随便放在哪里都行,代码中使用绝对路径指向它即可。

步骤3:图片OCR文字识别
1、亲测效果非常好,和微信识别的结果一模一样。
/**
* 从图片中识别文字
*/
@Test
public void scanTextFromImage() {
try {
// OCR模型路径
String modelPath = "D:\\software\\spire-ocr-win-x64";
// 图片路径
ClassPathResource resource = new ClassPathResource("data/image/中英文.jpg");
// ClassPathResource resource = new ClassPathResource("data/image/纯英文.jpg");
String imagePath = resource.getAbsolutePath();
// 创建OcrScanner类的对象
OcrScanner scanner = new OcrScanner();
// 设置扫描器配置
ConfigureOptions configureOptions = new ConfigureOptions();
// 指定文本识别的OCR语言,支持语言包括 English, Chinese, Chinesetraditional, French, German, Japanese 和 Korean
configureOptions.setLanguage("Chinese");
// 指定模型的路径
configureOptions.setModelPath(modelPath);
// 将配置应用于扫描器
scanner.ConfigureDependencies(configureOptions);
// 识别图片中的文本
scanner.scan(imagePath);
// 获取识别出的文本
String toString = scanner.getText().toString();
System.out.println(toString);
} catch (OcrException e) {
System.out.println("OCR 文字识别时发生错误。");
e.printStackTrace();
}
}src/test/java/com/wmx/sqliteapp3/tess4j/SpireOcrTest.java · 汪少棠/sqliteapp3 - Gitee.com。

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)