
数据分析案例-2025年数据科学、人工智能和机器学习职位薪资数据可视化
本文分析了2025年全球数据科学领域薪资趋势,基于Kaggle数据集(66,063条记录,11个变量)。通过Python可视化工具发现: 薪资呈右偏分布,高管薪资显著高于其他级别; 美国、瑞士、以色列薪资最高; 远程工作平均薪资更高,2020年后远程比例显著上升; 大公司薪资优势明显,尤其高管级别; 机器学习工程师和研究科学家薪资高于数据分析师。 分析揭示了经验水平、地理位置和公司规模是薪资主要决

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
随着全球数字化转型的加速推进,数据科学、人工智能和机器学习领域在2025年已成为推动经济增长和技术创新的核心驱动力。企业对于具备高级数据分析能力和AI技术专长的人才需求呈现爆发式增长,这种需求直接反映在相关职位的薪资水平上,使得该领域成为就业市场中备受关注的高价值赛道。近年来,随着大模型技术、边缘智能和联邦学习等前沿技术的商业化落地,行业对复合型技术人才的需求结构发生了显著变化,不仅要求从业者掌握传统的编程和统计学知识,还需要具备跨学科的问题解决能力和业务场景理解力。在此背景下,全球各科技中心如硅谷、北京、班加罗尔等地区纷纷通过具有竞争力的薪酬方案来争夺顶尖人才,导致不同地域、不同细分岗位的薪资差异呈现出新的特征。与此同时,远程办公模式的普及使得人才流动的地理限制减弱,进一步加剧了企业间的人才竞争,薪资数据中开始出现传统行业与科技公司薪资趋同、新兴市场薪资增速超越发达国家等有趣现象。通过对2025年最新薪资数据的可视化分析,不仅可以揭示当前技术人才市场的价值分布规律,还能为从业者的职业规划、企业的招聘策略以及教育机构的人才培养方向提供数据支撑,具有重要的实践指导意义。
2.数据集介绍
本实验数据集来源于Kaggle,原始数据集共有66063条数据,11个变量。各变量含义如下:
work_year ->报告薪水的年份。所有条目都反映了2025年的数据。
job_title ->具体的角色或职称,如数据科学家、机器学习工程师、人工智能研究员等。
job_category ->工作的更广泛的类别或专业化(例如,数据工程,NLP,计算机视觉等)。
salary_currency ->支付工资的原始货币(例如,美元,欧元,印度卢比)。
salary ->以原货币计算的报告年薪(转换前)。
salary_in_usd ->使用2025年的平均汇率将年薪转换为美元,以便进行全球比较。
employee_residence ->雇员居住或主要工作的国家。
experience_level ->该角色所需或持有的专业经验水平。共同价值观:初级、中级、高级、行政人员。
employment_type ->雇佣合同的类型。例子:全职,兼职,合同,自由职业者。
work_setting ->作业类型为Remote、Hybrid或site。
company_location—>雇主总部或主要办公室所在的国家。
company_size ->雇主组织的规模,分类如下:
规模小(1-50人)
中型(51-500人)
大型(500人以上)
2025年数据科学专业人士的实际收入是多少?
这份数据集全面展现了数据科学、机器学习和人工智能领域职位的全球薪资趋势。
该数据集通过结合市场研究和公开数据源(包括AIJobs 薪资调查(CC0 许可证)、365DataScience、Payscale、KDnuggets、ZipRecruiter等)精心整理而成,反映了全球真实的薪酬模式。
为什么这个数据集很重要
无论您是数据科学家、人工智能从业者、学生、招聘人员还是行业研究人员,此数据集都旨在支持:
- 薪资预测和机器学习建模
- 全球市场标杆
- 职业决策与谈判
- 远程工作趋势分析
- 商业智能仪表板和可视化
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
导入可视化库并加载数据集
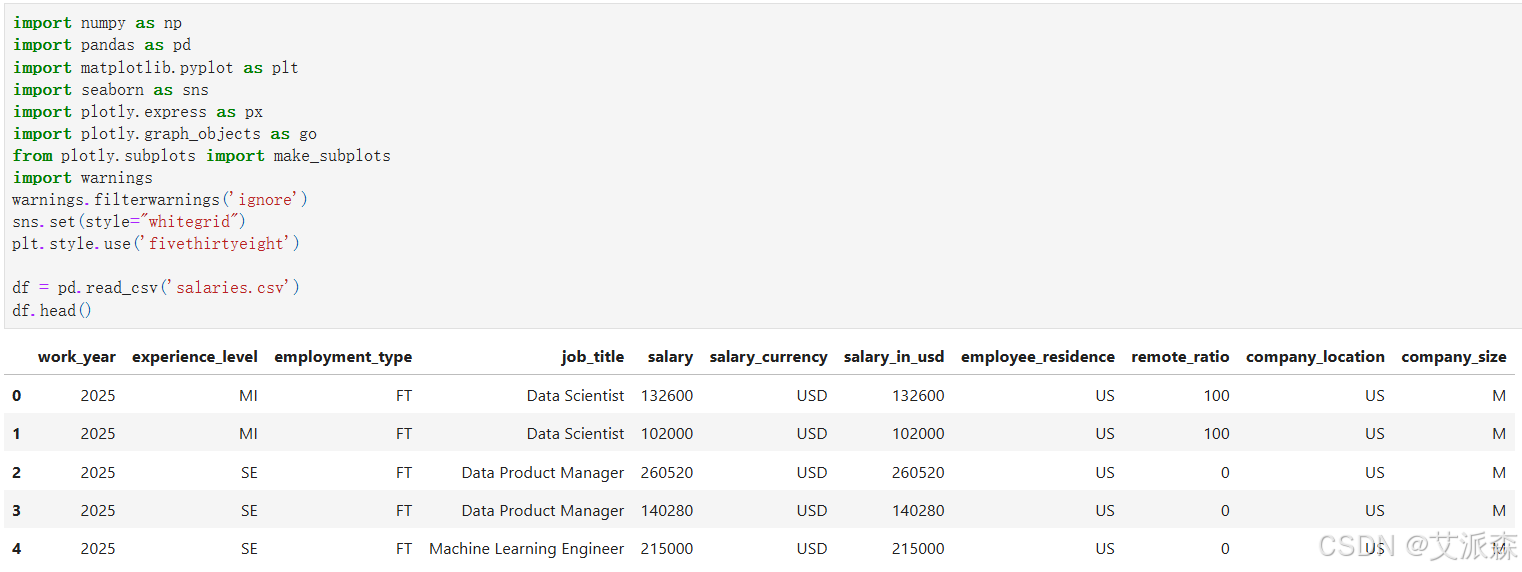
查看数据集大小
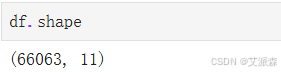
查看数据基本信息
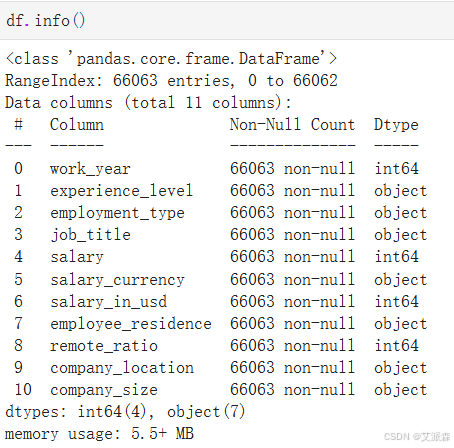
查看数值型变量的描述性统计

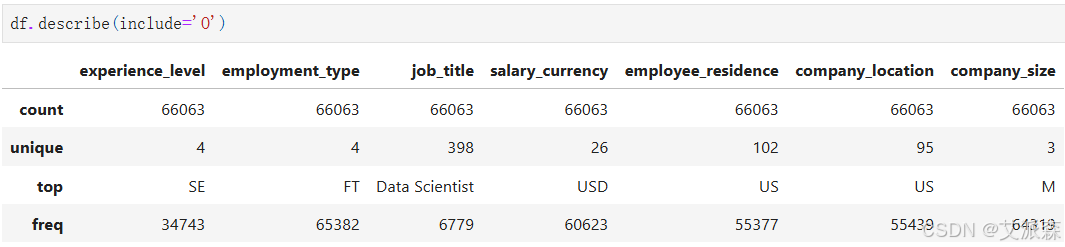
查看非数值型变量的描述性统计
统计缺失值
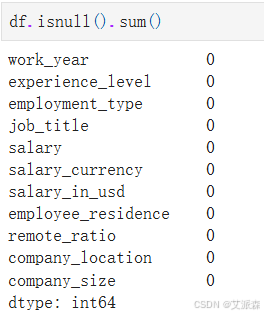
统计重复值
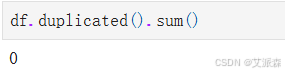
发现该数据集不存在缺失值和重复值。
5.数据可视化


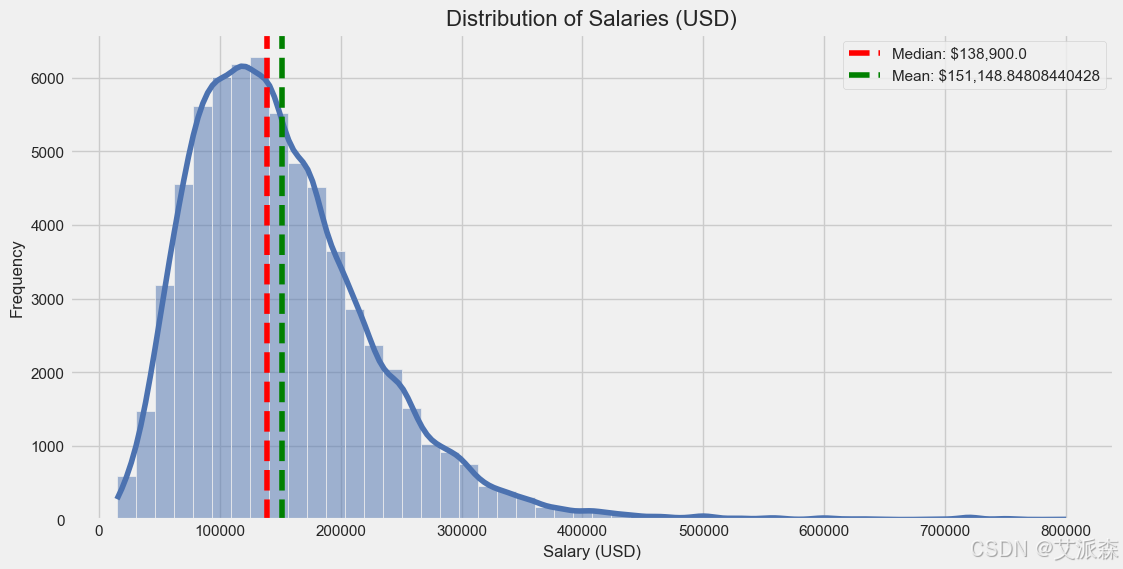

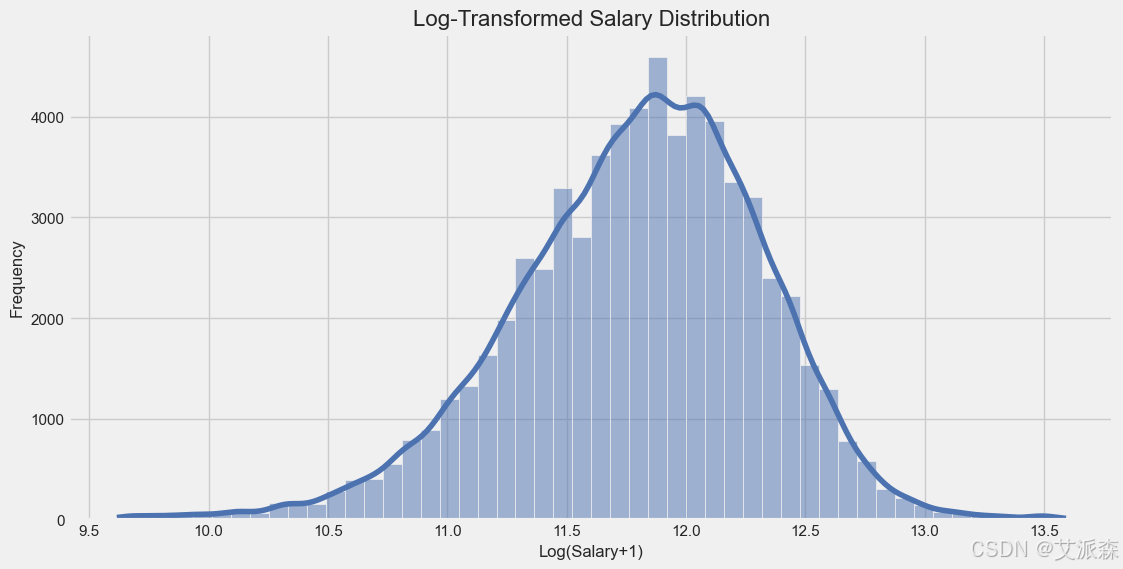
工资分布是右倾斜的,有大量的高收入异常值,这是典型的工资数据。对数变换给了我们一个更正态的分布,这对建模很有用。
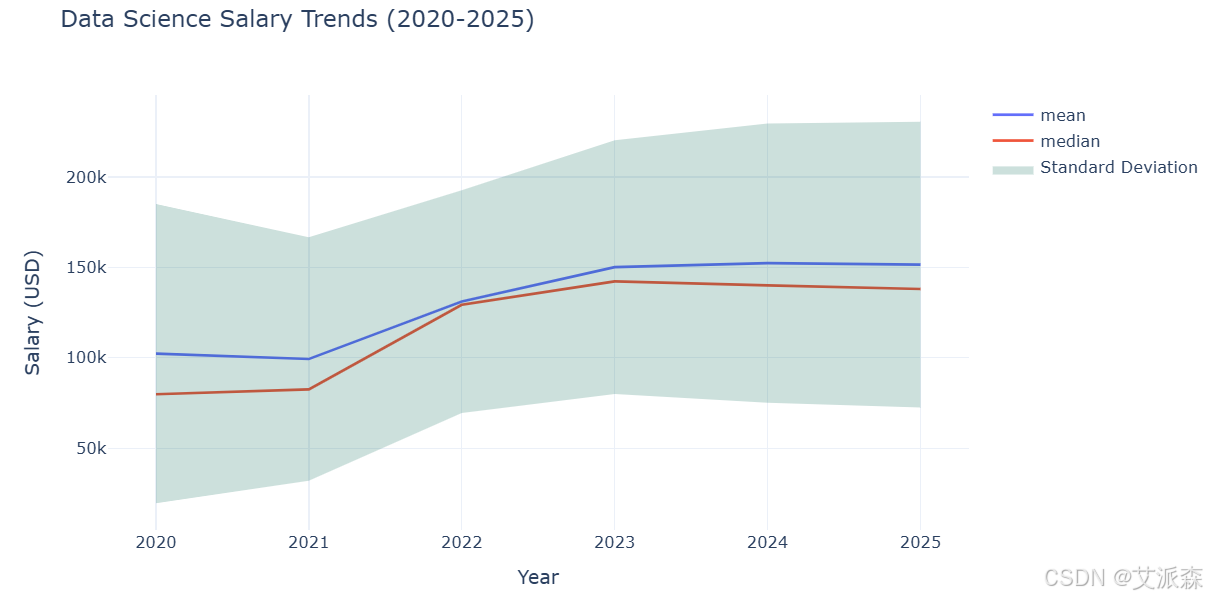
我们可以观察到,从2020年到2025年,平均工资和中位数工资都在稳步增长,两者之间的差距略有扩大,表明该领域的不平等正在加剧。

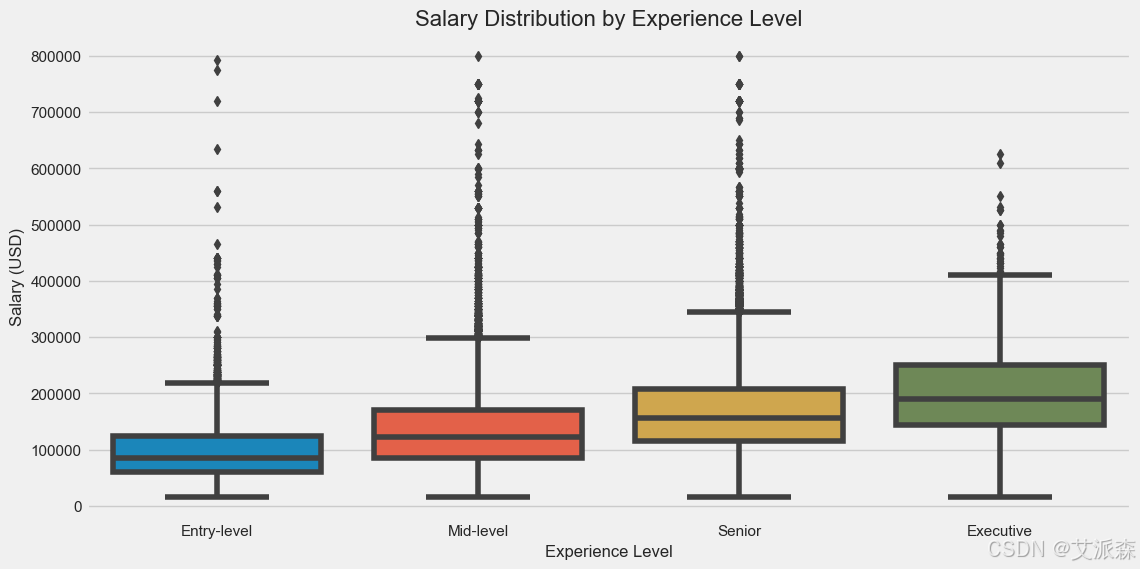

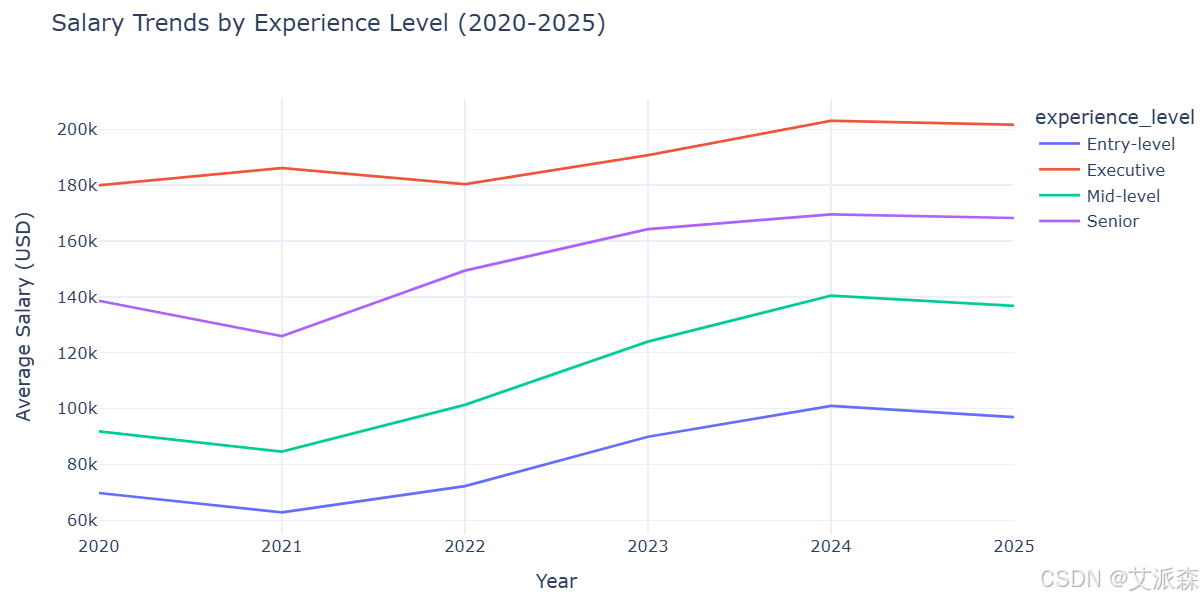
正如预期的那样,经验水平对工资有重大影响,高管的收入远远高于其他水平。高管薪酬的增长率似乎更大,表明领导职位的溢价在上升。

在最常见的职位头衔中,机器学习工程师和研究科学家往往要求最高的薪水,而数据分析师通常收入较低。软件工程师的薪酬分布最为广泛,反映了这一职位下角色的多样性。

美国、瑞士和以色列在数据科学薪酬方面处于领先地位。


完全远程工作的平均工资往往更高。我们还可以观察到2020年后远程工作的重大转变(可能是由于COVID-19大流行),这一趋势在2023-2024年左右趋于稳定,但与2020年前的水平相比,远程工作的比例仍然更高。

大公司通常对所有经验级别的员工都提供更高的薪水,其中高管级别的差距最为明显。这反映了更大的组织拥有更多的资源和收入。

美元是全球数据科学薪酬的主要货币。汇率分析显示,随着时间的推移,货币相对强势,一些货币对美元出现贬值。
相关分析显示,工资与经验水平、公司规模和某些职位等因素之间存在很强的关系。我们可以将这些见解用于模型中的特征选择。
6.总结
我们对数据科学薪酬数据集的全面分析得出了以下几点有价值的见解:
薪资决定因素:经验水平、公司位置和工作类别是数据科学领域薪资的最强预测因素。行政职位的薪水明显高于其他级别。
地理影响:美国、瑞士和以色列一直提供最高的薪水。收入最高的国家和新兴科技市场之间存在巨大差距。
远程工作溢价:完全远程的职位往往提供更高的平均工资,潜在地反映了全球对人才的竞争,无论地点如何。
职业发展:从高级管理人员到高级管理人员的晋升幅度最大,这表明领导能力得到了极大的重视。
职位区分:机器学习工程师和研究科学家比数据分析师和一般软件工程师要求更高的薪水,反映了所需的专业技能。
公司规模效应:大公司通常会为所有经验级别的员工提供更高的薪酬,这种差距在高管级别上最为明显。
文末推荐
《AI智能化办公:DeepSeek使用方法与技巧从入门到精通》

内容简介
本书系统性地介绍了人工智能大模型DeepSeek的核心技术与应用实践,聚焦于DeepSeek这一前沿工具的多场景赋能。全书共10章,内容涵盖三大维度。第1章为基础认知:深入解析人工智能与大模型的概念、技术架构及发展趋势,帮助读者构建完整的知识框架;第2章至第5章为工具精通:详细讲解了DeepSeek的功能特性、操作技巧及实战应用,包括文稿撰写、数据处理、PPT制作等高频办公场景,结合代码生成、智能公式、数据可视化等核心技术,助力效 率提升;第6章至第10章为进阶拓展:拓展至DeepSeek学术研究、AI绘图、视频创作、生活助手及逻辑推理等创新 领域应用,并通过本地部署指南,为开发者提供私有化落地方案。本书以“工具+场景+思维”为核心,全书介绍了多个行业案例,覆盖文稿创作、职场办公、科研学术、绘图设计、视频创意、生活赋能、逻辑推理等场景,步骤清晰,即学即用。本书既是DeepSeek的权威指南,也是智能化办 公的实践手册,为读者开启AI技术落地提供了全新视野。
《DeepSeek从入门到精通》

内容简介:
在AI浪潮席卷全球的今天,DeepSeek不仅能够提升工作效率,更能有力赋能行业发展。 本书从AI的历史与现状讲起,全面剖析了DeepSeek的应用。特别是在自媒体领域,无论是内容生产、热点追踪、多平台适配,还是实现商业变现,DeepSeek都产生了重大影响。书中还详细介绍了DeepSeek工具的使用方法,包括账号配置、对话技巧、内容生成等,并通过实战案例展示了如何利用AI实现爆款内容创作、热点追踪和商业变现。此外,书中还探讨了AI在知识付费、电商带货、本地生活等垂直领域的应用,以及如何通过AI构建私域流量和实现数字人直播等前沿技术的落地。
本书内容通俗易懂,适合自媒体创作者、内容运营者、电商从业者、营销人员及对AI技术感兴趣的商业人士。无论是希望提升创作效率、优化商业策略,还是探索AI在实际业务中的应用,本书都能提供实用的指导和启发。
源代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import warnings
warnings.filterwarnings('ignore')
sns.set(style="whitegrid")
plt.style.use('fivethirtyeight')
df = pd.read_csv('salaries.csv')
df.head()
df.shape
df.info()
df.describe()
df.describe(include='O')
df.isnull().sum()
df.duplicated().sum()
# 薪资分布
plt.figure(figsize=(12, 6))
sns.histplot(df['salary_in_usd'], kde=True, bins=50)
plt.title('Distribution of Salaries (USD)', fontsize=16)
plt.xlabel('Salary (USD)', fontsize=12)
plt.ylabel('Frequency', fontsize=12)
plt.axvline(df['salary_in_usd'].median(), color='red', linestyle='--', label=f'Median: ${df["salary_in_usd"].median():,}')
plt.axvline(df['salary_in_usd'].mean(), color='green', linestyle='--', label=f'Mean: ${df["salary_in_usd"].mean():,}')
plt.legend()
plt.show()
# 对数变换后的工资分布(处理偏度)
plt.figure(figsize=(12, 6))
sns.histplot(np.log1p(df['salary_in_usd']), kde=True, bins=50)
plt.title('Log-Transformed Salary Distribution', fontsize=16)
plt.xlabel('Log(Salary+1)', fontsize=12)
plt.ylabel('Frequency', fontsize=12)
plt.show()
工资分布是右倾斜的,有大量的高收入异常值,这是典型的工资数据。对数变换给了我们一个更正态的分布,这对建模很有用。
# 年薪趋势
yearly_stats = df.groupby('work_year')['salary_in_usd'].agg(['mean', 'median', 'std']).reset_index()
fig = px.line(yearly_stats, x='work_year', y=['mean', 'median'],
title='Data Science Salary Trends (2020-2025)',
labels={'value': 'Salary (USD)', 'work_year': 'Year', 'variable': 'Metric'},
template='plotly_white')
fig.update_layout(legend_title_text='', hovermode='x unified',
width=900, height=500)
# 为标准偏差添加范围
fig.add_trace(go.Scatter(
x=np.concatenate([yearly_stats['work_year'], yearly_stats['work_year'][::-1]]),
y=np.concatenate([yearly_stats['mean'] + yearly_stats['std'],
(yearly_stats['mean'] - yearly_stats['std'])[::-1]]),
fill='toself',
fillcolor='rgba(0,100,80,0.2)',
line=dict(color='rgba(255,255,255,0)'),
name='Standard Deviation'
))
fig.show()
我们可以观察到,从2020年到2025年,平均工资和中位数工资都在稳步增长,两者之间的差距略有扩大,表明该领域的不平等正在加剧。
# 经验水平薪资对比
plt.figure(figsize=(12, 6))
sns.boxplot(x='experience_level', y='salary_in_usd', data=df, order=['EN', 'MI', 'SE', 'EX'])
plt.title('Salary Distribution by Experience Level', fontsize=16)
plt.xlabel('Experience Level', fontsize=12)
plt.ylabel('Salary (USD)', fontsize=12)
plt.xticks(ticks=[0, 1, 2, 3], labels=['Entry-level', 'Mid-level', 'Senior', 'Executive'])
plt.show()
# 按工作经验划分的平均工资
exp_time = df.groupby(['work_year', 'experience_level'])['salary_in_usd'].mean().reset_index()
exp_time['experience_level'] = exp_time['experience_level'].replace({
'EN': 'Entry-level', 'MI': 'Mid-level', 'SE': 'Senior', 'EX': 'Executive'
})
fig = px.line(exp_time, x='work_year', y='salary_in_usd', color='experience_level',
title='Salary Trends by Experience Level (2020-2025)',
labels={'salary_in_usd': 'Average Salary (USD)', 'work_year': 'Year'},
template='plotly_white')
fig.update_layout(width=900, height=500, hovermode='x unified')
fig.show()
正如预期的那样,经验水平对工资有重大影响,高管的收入远远高于其他水平。高管薪酬的增长率似乎更大,表明领导职位的溢价在上升。
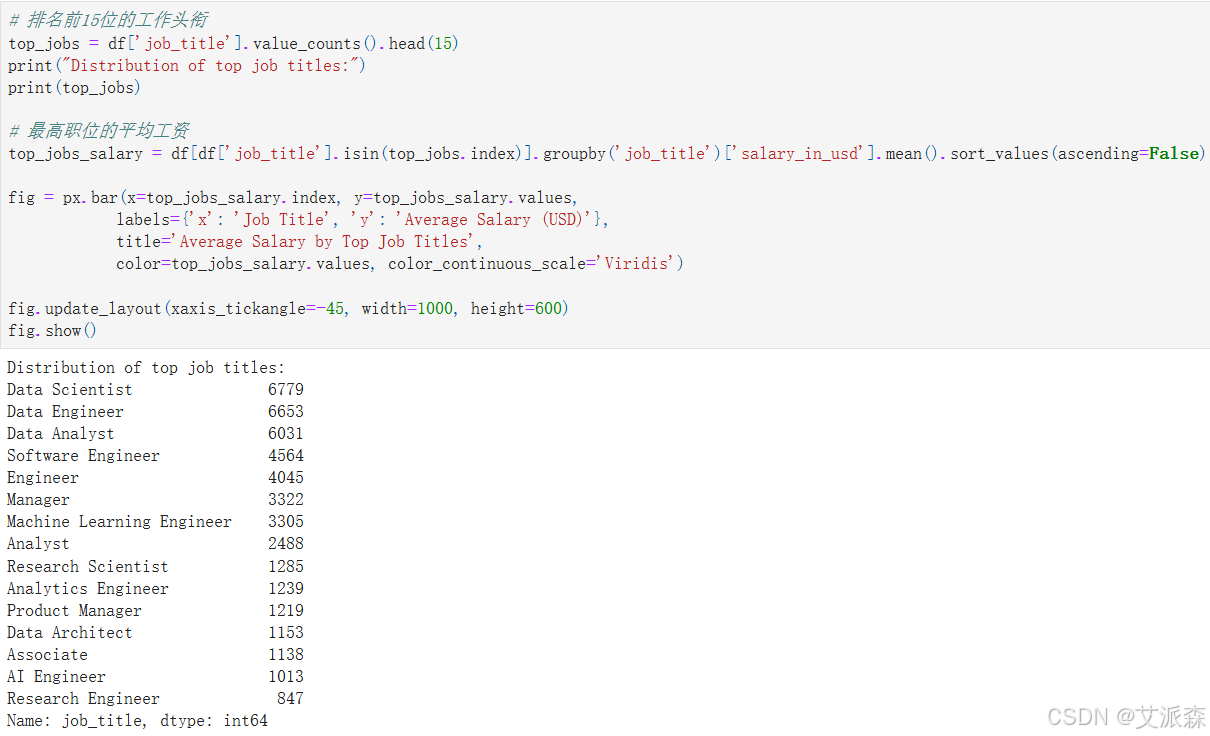
# 排名前15位的工作头衔
top_jobs = df['job_title'].value_counts().head(15)
print("Distribution of top job titles:")
print(top_jobs)
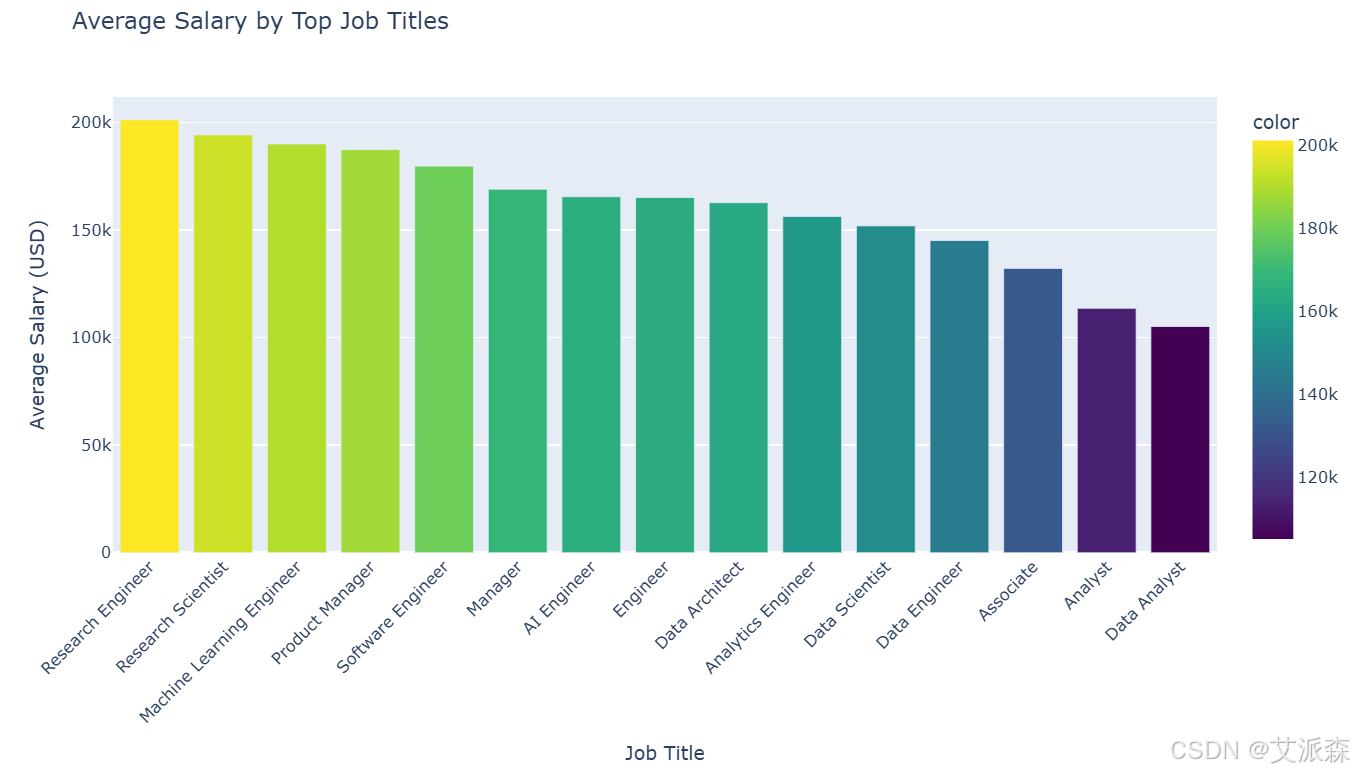
# 最高职位的平均工资
top_jobs_salary = df[df['job_title'].isin(top_jobs.index)].groupby('job_title')['salary_in_usd'].mean().sort_values(ascending=False)
fig = px.bar(x=top_jobs_salary.index, y=top_jobs_salary.values,
labels={'x': 'Job Title', 'y': 'Average Salary (USD)'},
title='Average Salary by Top Job Titles',
color=top_jobs_salary.values, color_continuous_scale='Viridis')
fig.update_layout(xaxis_tickangle=-45, width=1000, height=600)
fig.show()
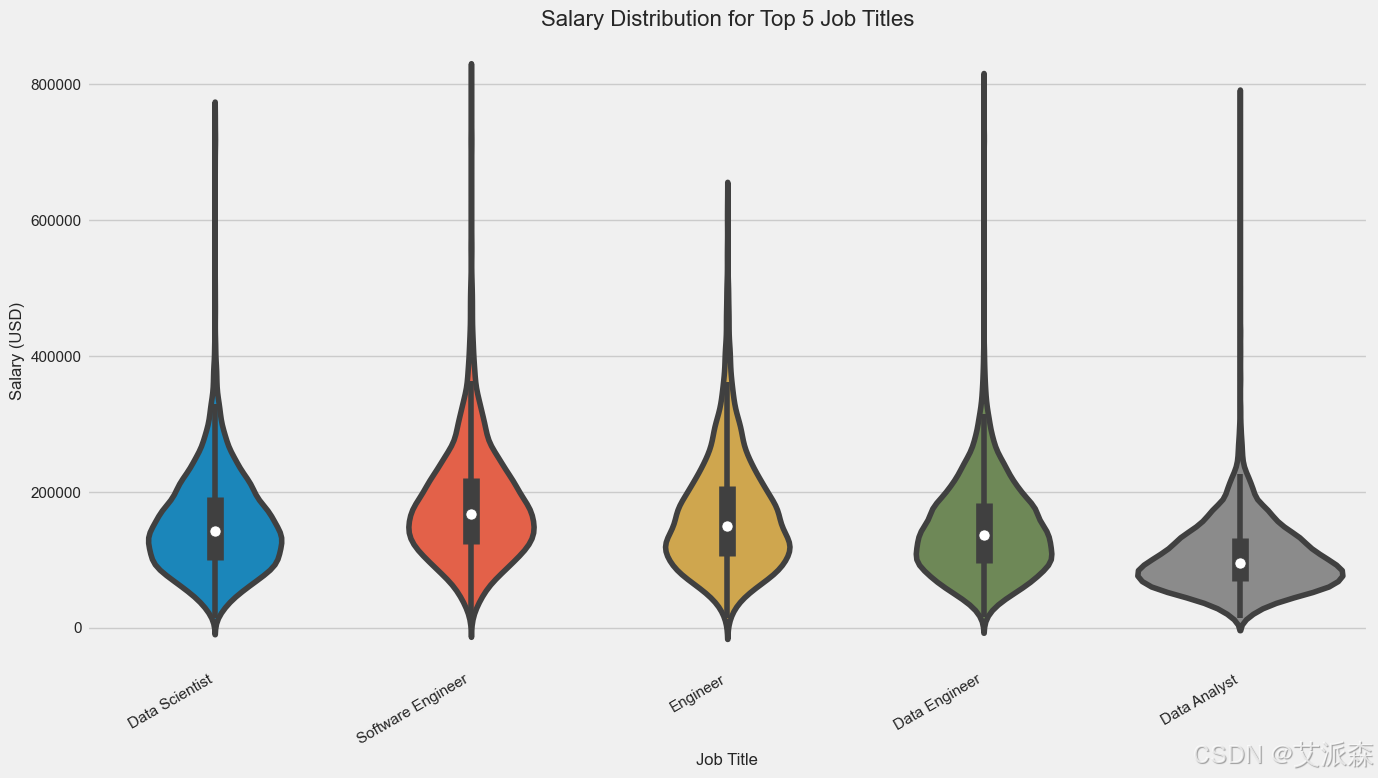
# 前5个职位的薪酬分布
plt.figure(figsize=(14, 8))
top5_jobs = top_jobs.index[:5]
sns.violinplot(x='job_title', y='salary_in_usd', data=df[df['job_title'].isin(top5_jobs)])
plt.title('Salary Distribution for Top 5 Job Titles', fontsize=16)
plt.xlabel('Job Title', fontsize=12)
plt.ylabel('Salary (USD)', fontsize=12)
plt.xticks(rotation=30, ha='right')
plt.tight_layout()
plt.show()
在最常见的职位头衔中,机器学习工程师和研究科学家往往要求最高的薪水,而数据分析师通常收入较低。软件工程师的薪酬分布最为广泛,反映了这一头衔下角色的多样性。
# 地理分析
df['adjusted_salary'] = df['salary_in_usd'] # You can modify this if there's a specific adjustment formula
# 创建从ISO-2到国家名称的映射以实现可视化
iso2_to_name = {
'US': 'United States', 'GB': 'United Kingdom', 'DE': 'Germany', 'FR': 'France',
'CA': 'Canada', 'IN': 'India', 'AU': 'Australia', 'ES': 'Spain', 'BR': 'Brazil',
'NL': 'Netherlands', 'JP': 'Japan', 'CH': 'Switzerland', 'IT': 'Italy',
'SG': 'Singapore', 'SE': 'Sweden', 'MX': 'Mexico', 'FI': 'Finland', 'DK': 'Denmark',
'PL': 'Poland', 'PT': 'Portugal', 'NZ': 'New Zealand', 'IE': 'Ireland',
'HK': 'Hong Kong', 'RU': 'Russia', 'BE': 'Belgium', 'IL': 'Israel',
'UA': 'Ukraine', 'TR': 'Turkey', 'AE': 'United Arab Emirates', 'ZA': 'South Africa',
'CO': 'Colombia', 'AR': 'Argentina', 'CL': 'Chile', 'AT': 'Austria', 'MY': 'Malaysia',
'NG': 'Nigeria', 'VN': 'Vietnam', 'KR': 'South Korea', 'TH': 'Thailand'
# 根据需要添加更多映射
}
# 按员工居住地计算平均工资
avg_salary_by_residence = df.groupby('employee_residence')['adjusted_salary'].mean().reset_index()
# 添加用于映射的国家名称
avg_salary_by_residence['country_name'] = avg_salary_by_residence['employee_residence'].map(iso2_to_name)
avg_salary_by_residence = avg_salary_by_residence.dropna(subset=['country_name']) # Drop unmapped countries
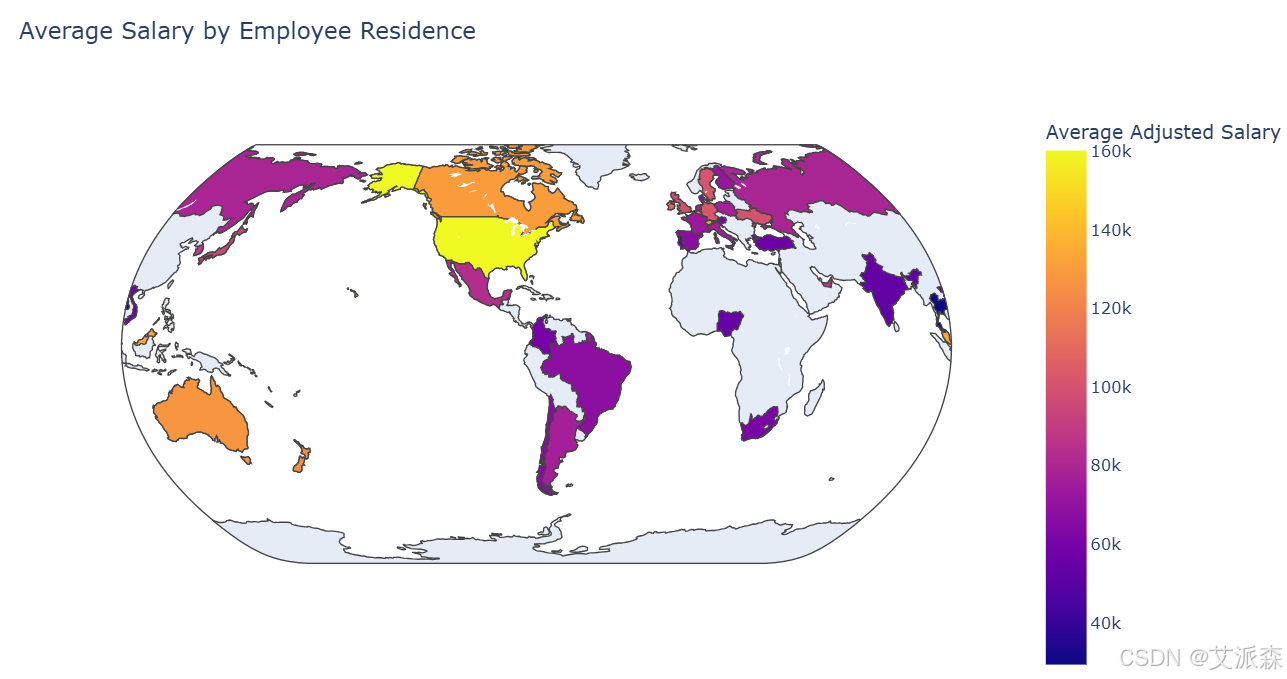
# 创建choropleth地图
fig2 = px.choropleth(avg_salary_by_residence,
locations='country_name',
locationmode='country names',
color='adjusted_salary',
hover_name='country_name',
hover_data={'employee_residence': True, 'adjusted_salary': ':,.0f'},
color_continuous_scale=px.colors.sequential.Plasma,
title='Average Salary by Employee Residence',
labels={'adjusted_salary': 'Average Adjusted Salary'},
projection='natural earth')
fig2.update_layout(width=1000, height=600)
fig2.show()
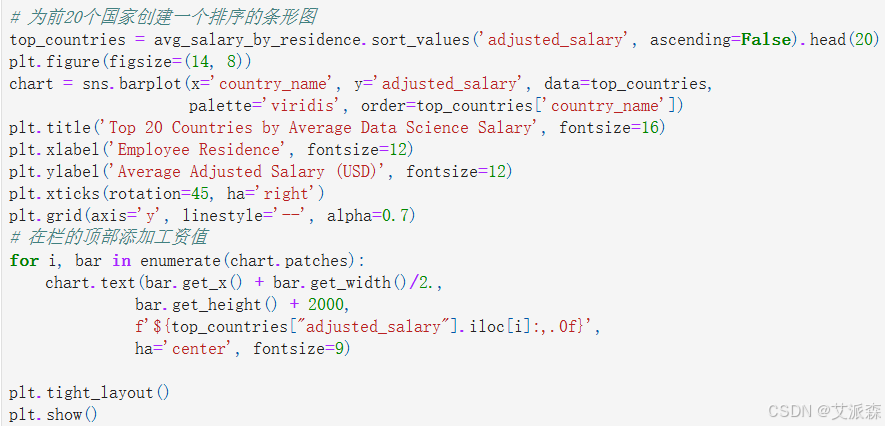
# 为前20个国家创建一个排序的条形图
top_countries = avg_salary_by_residence.sort_values('adjusted_salary', ascending=False).head(20)
plt.figure(figsize=(14, 8))
chart = sns.barplot(x='country_name', y='adjusted_salary', data=top_countries,
palette='viridis', order=top_countries['country_name'])
plt.title('Top 20 Countries by Average Data Science Salary', fontsize=16)
plt.xlabel('Employee Residence', fontsize=12)
plt.ylabel('Average Adjusted Salary (USD)', fontsize=12)
plt.xticks(rotation=45, ha='right')
plt.grid(axis='y', linestyle='--', alpha=0.7)
# 在栏的顶部添加工资值
for i, bar in enumerate(chart.patches):
chart.text(bar.get_x() + bar.get_width()/2.,
bar.get_height() + 2000,
f'${top_countries["adjusted_salary"].iloc[i]:,.0f}',
ha='center', fontsize=9)
plt.tight_layout()
plt.show()
美国、瑞士和以色列在数据科学薪酬方面处于领先地位
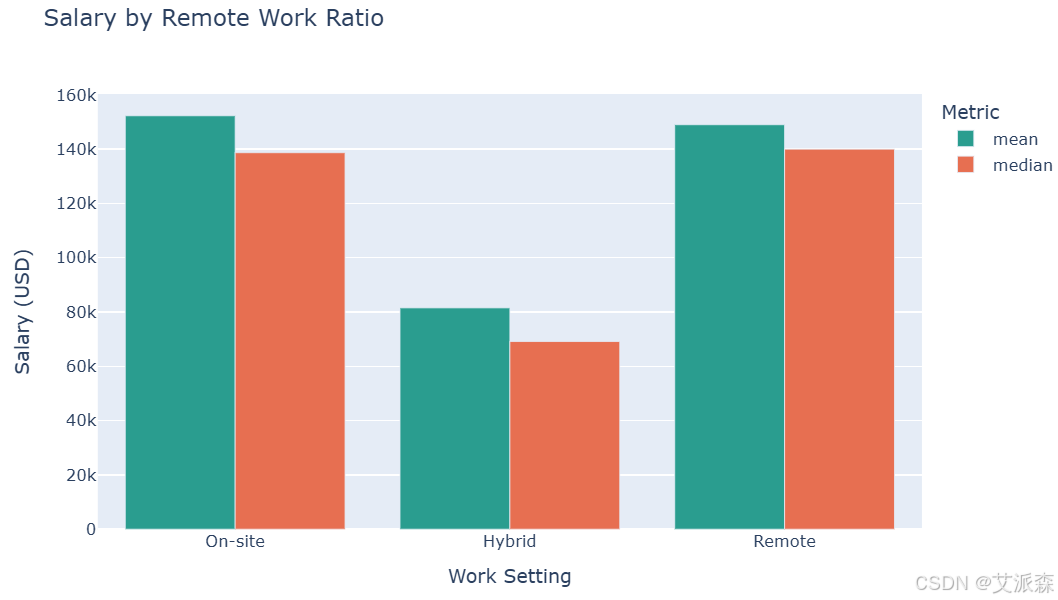
# 按远程比例计算的工资
remote_salary = df.groupby('remote_ratio')['salary_in_usd'].agg(['mean', 'median', 'count']).reset_index()
remote_salary['remote_ratio'] = remote_salary['remote_ratio'].map({0: 'On-site', 50: 'Hybrid', 100: 'Remote'})
fig = px.bar(remote_salary, x='remote_ratio', y=['mean', 'median'],
barmode='group', title='Salary by Remote Work Ratio',
labels={'value': 'Salary (USD)', 'remote_ratio': 'Work Setting', 'variable': 'Metric'},
color_discrete_sequence=['#2a9d8f', '#e76f51'])
fig.update_layout(width=800, height=500)
fig.show()
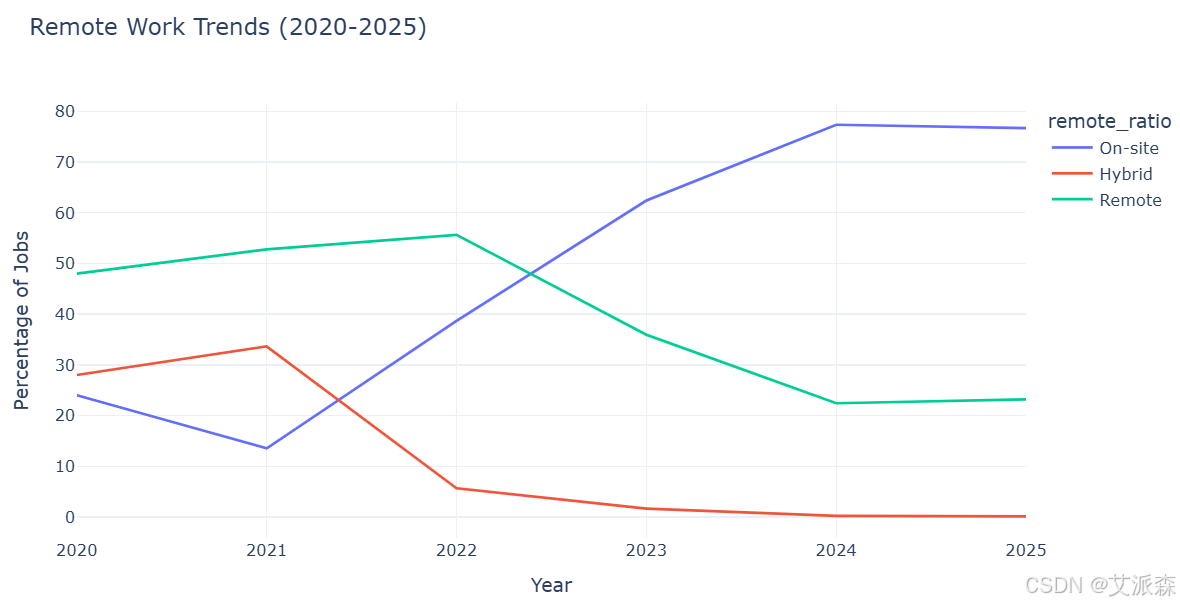
# 远程比率随时间的变化趋势
remote_time = df.groupby(['work_year', 'remote_ratio']).size().reset_index(name='count')
total_per_year = remote_time.groupby('work_year')['count'].sum().reset_index()
remote_time = remote_time.merge(total_per_year, on='work_year', suffixes=('', '_total'))
remote_time['percentage'] = (remote_time['count'] / remote_time['count_total']) * 100
remote_time['remote_ratio'] = remote_time['remote_ratio'].map({0: 'On-site', 50: 'Hybrid', 100: 'Remote'})
fig = px.line(remote_time, x='work_year', y='percentage', color='remote_ratio',
title='Remote Work Trends (2020-2025)',
labels={'percentage': 'Percentage of Jobs', 'work_year': 'Year'},
template='plotly_white')
fig.update_layout(width=900, height=500, hovermode='x unified')
fig.show()
完全远程工作的平均工资往往更高。我们还可以观察到2020年后远程工作的重大转变(可能是由于COVID-19大流行),这一趋势在2023-2024年左右趋于稳定,但与2020年前的水平相比,远程工作的比例仍然更高。
# 按公司规模划分的工资
company_salary = df.groupby(['company_size', 'experience_level'])['salary_in_usd'].median().reset_index()
company_salary['company_size'] = company_salary['company_size'].map({'S': 'Small', 'M': 'Medium', 'L': 'Large'})
company_salary['experience_level'] = company_salary['experience_level'].map({
'EN': 'Entry-level', 'MI': 'Mid-level', 'SE': 'Senior', 'EX': 'Executive'
})
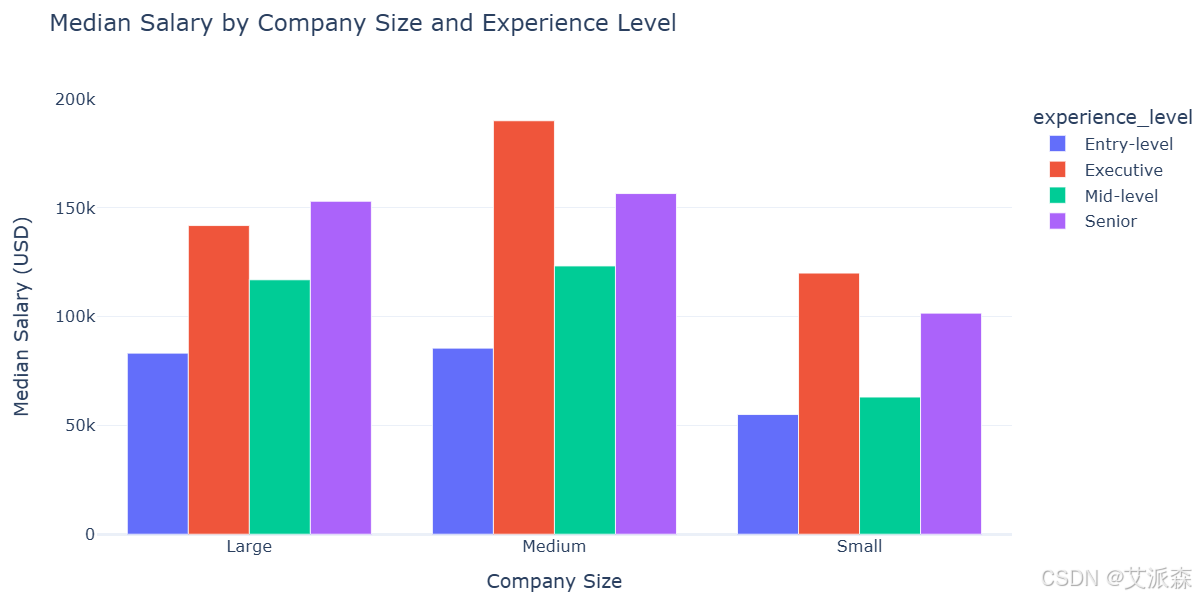
fig = px.bar(company_salary, x='company_size', y='salary_in_usd', color='experience_level',
barmode='group', title='Median Salary by Company Size and Experience Level',
labels={'salary_in_usd': 'Median Salary (USD)', 'company_size': 'Company Size'},
template='plotly_white')
fig.update_layout(width=900, height=500)
fig.show()
大公司通常对所有经验级别的员工都提供更高的薪水,其中高管级别的差距最为明显。这反映了更大的组织拥有更多的资源和收入。
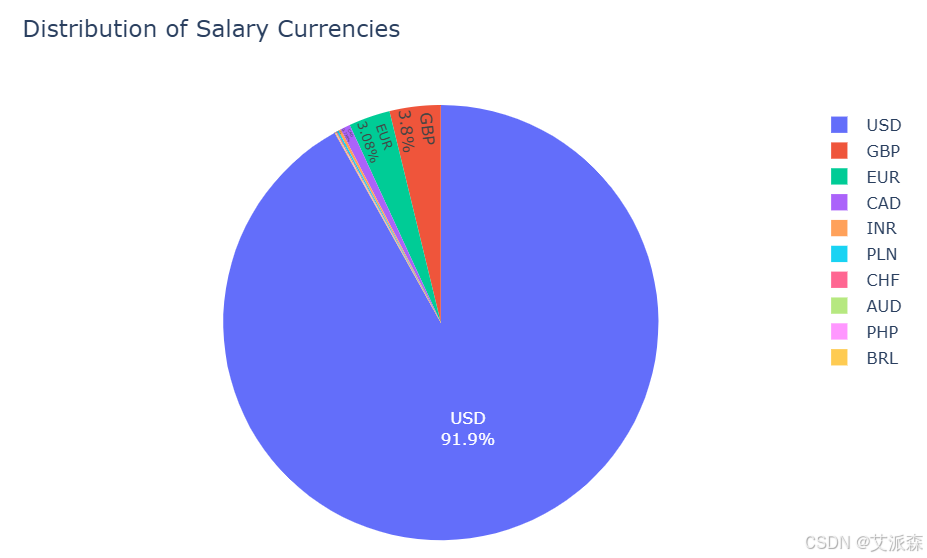
# 最高工资货币
currency_counts = df['salary_currency'].value_counts().head(10)
fig = px.pie(values=currency_counts.values, names=currency_counts.index,
title='Distribution of Salary Currencies',
template='plotly_white')
fig.update_traces(textposition='inside', textinfo='percent+label')
fig.update_layout(width=700, height=500)
fig.show()
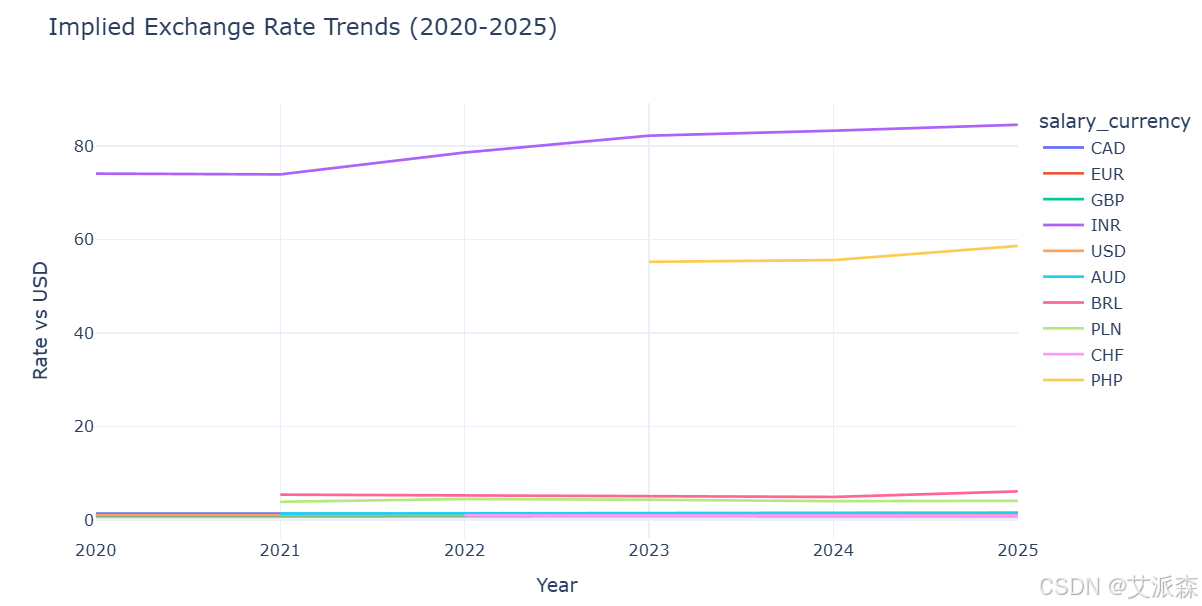
# 汇率分析(由salary和salary_in_usd得出)
df['implied_exchange_rate'] = df['salary'] / df['salary_in_usd']
top_currencies = df['salary_currency'].value_counts().head(10).index.tolist()
exchange_rates = df[df['salary_currency'].isin(top_currencies)].groupby(['work_year', 'salary_currency'])['implied_exchange_rate'].median().reset_index()
fig = px.line(exchange_rates, x='work_year', y='implied_exchange_rate', color='salary_currency',
title='Implied Exchange Rate Trends (2020-2025)',
labels={'implied_exchange_rate': 'Rate vs USD', 'work_year': 'Year'},
template='plotly_white')
fig.update_layout(width=900, height=500, hovermode='x unified')
fig.show()
美元是全球数据科学薪酬的主要货币。汇率分析显示,随着时间的推移,货币相对强势,一些货币对美元出现贬值。
# 为分类特征创建虚拟变量
categorical_cols = ['experience_level', 'employment_type', 'job_title', 'salary_currency',
'employee_residence', 'company_location', 'company_size']
numerical_cols = ['work_year', 'salary', 'salary_in_usd', 'remote_ratio']
# 选择最重要的职位进行简化的相关性分析
top_job_titles = df['job_title'].value_counts().head(5).index.tolist()
df_corr = df[df['job_title'].isin(top_job_titles)].copy()
# 虚拟变量
df_dummies = pd.get_dummies(df_corr, columns=categorical_cols, drop_first=True)
# 计算并绘制相关矩阵
corr_matrix = df_dummies.corr()
plt.figure(figsize=(20, 16))
sns.heatmap(corr_matrix, annot=False, cmap='coolwarm', center=0, linewidths=0.5)
plt.title('Correlation Matrix of Features', fontsize=18)
plt.xticks(fontsize=10, rotation=90)
plt.yticks(fontsize=10)
plt.tight_layout()
plt.show()
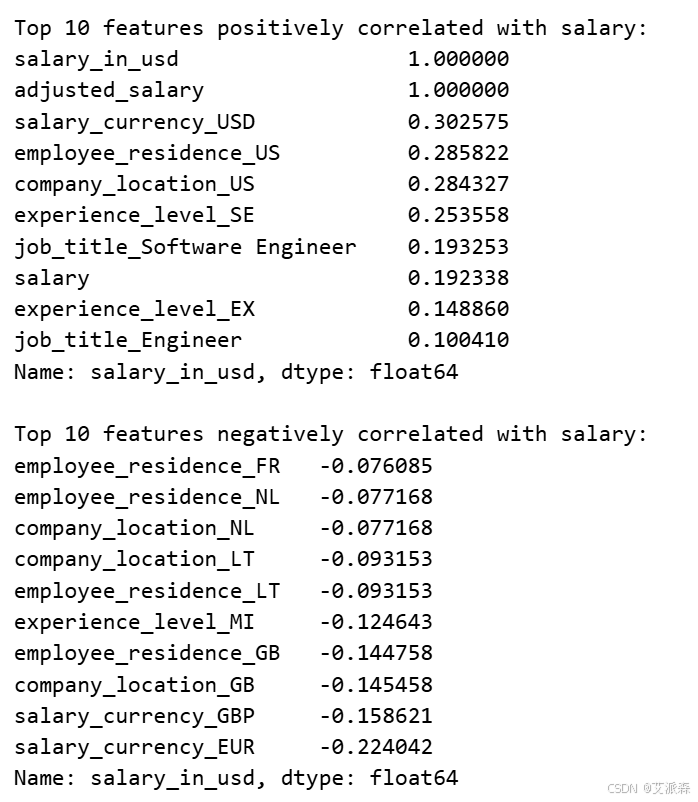
# 主要的薪酬相关性
salary_corr = corr_matrix['salary_in_usd'].sort_values(ascending=False)
print("Top 10 features positively correlated with salary:")
print(salary_corr.head(10))
print("\nTop 10 features negatively correlated with salary:")
print(salary_corr.tail(10))
相关分析显示,工资与经验水平、公司规模和某些职位等因素之间存在很强的关系。我们可以将这些见解用于模型中的特征选择。
结论和关键见解¶
我们对数据科学薪酬数据集的全面分析得出了以下几点有价值的见解:
薪资决定因素:经验水平、公司位置和工作类别是数据科学领域薪资的最强预测因素。行政职位的薪水明显高于其他级别。
地理影响:美国、瑞士和以色列一直提供最高的薪水。收入最高的国家和新兴科技市场之间存在巨大差距。
远程工作溢价:完全远程的职位往往提供更高的平均工资,潜在地反映了全球对人才的竞争,无论地点如何。
职业发展:从高级管理人员到高级管理人员的晋升幅度最大,这表明领导能力得到了极大的重视。
职位区分:机器学习工程师和研究科学家比数据分析师和一般软件工程师要求更高的薪水,反映了所需的专业技能。
公司规模效应:大公司通常会为所有经验级别的员工提供更高的薪酬,这种差距在高管级别上最为明显。
资料获取,更多粉丝福利,关注下方公众号获取


技术共进,成长同行——讯飞AI开发者社区
更多推荐
 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)