
2000 张人脸眼部检测数据集 | 标注规范、数据划分与应用场景
随着人工智能与计算机视觉技术的快速发展,基于人脸与眼部的检测与识别逐渐成为诸多应用的核心环节。从智能安防、智慧教育到智能驾驶、医疗辅助诊断,人的脸部特征与眼睛状态往往承载着重要的信息价值。例如,在驾驶员监测中,眼睛的闭合频率可以作为疲劳驾驶的关键指标;在教育场景中,学生的注视方向能反映注意力水平;在医疗健康领域,眼动特征又能帮助医生判断神经系统异常。
2000 张人脸眼部检测数据集 | 标注规范、数据划分与应用场景
随着人工智能与计算机视觉技术的快速发展,基于人脸与眼部的检测与识别逐渐成为诸多应用的核心环节。从智能安防、智慧教育到智能驾驶、医疗辅助诊断,人的脸部特征与眼睛状态往往承载着重要的信息价值。例如,在驾驶员监测中,眼睛的闭合频率可以作为疲劳驾驶的关键指标;在教育场景中,学生的注视方向能反映注意力水平;在医疗健康领域,眼动特征又能帮助医生判断神经系统异常。
数据集下载
链接:https://pan.baidu.com/s/1MTUtaRKLhEY8RqLIx3d65A?pwd=8gw5
提取码:8gw5 复制这段内容后打开百度网盘手机App,操作更方便哦
背景
在人机交互、智能安防、驾驶员监测、医疗辅助诊断等人工智能应用中,人脸与眼部检测 一直是计算机视觉的基础研究方向之一。尤其在近年来,随着深度学习和卷积神经网络(CNN)的飞速发展,检测算法的精度与实时性有了大幅提升。但无论算法如何先进,数据始终是驱动模型性能提升的根本。
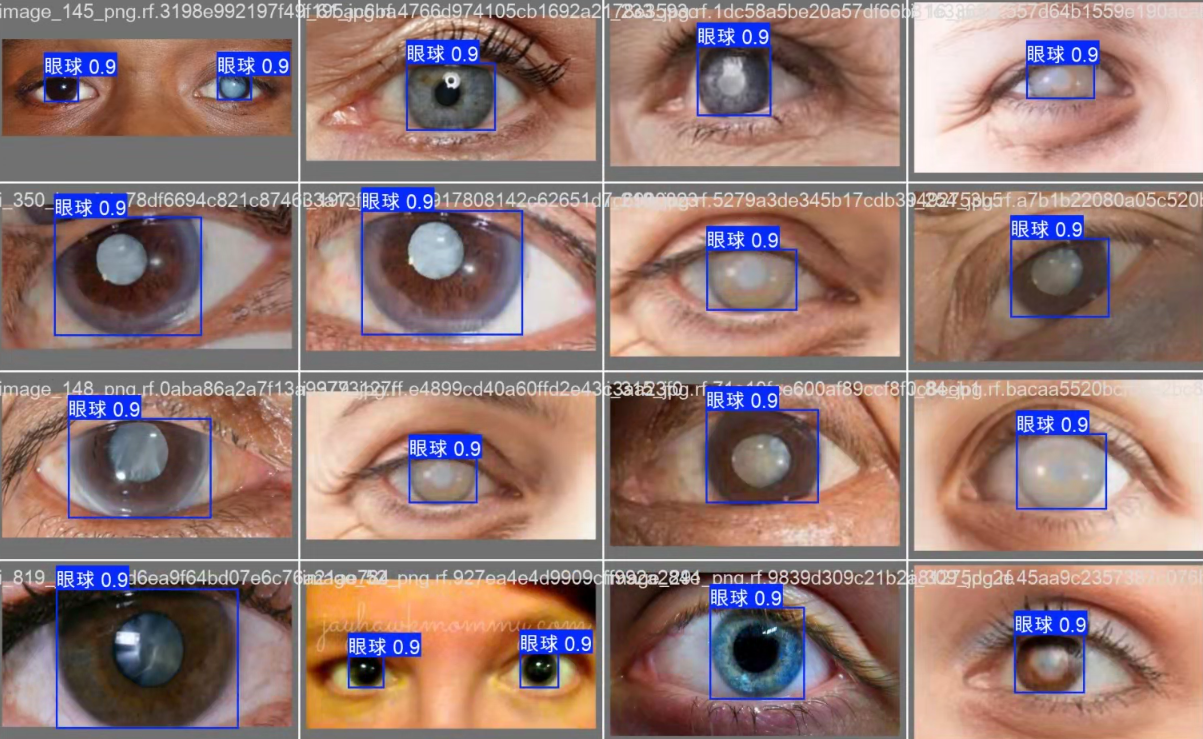
人脸眼部检测作为细粒度人脸分析的核心任务,主要目标是定位人脸区域及其关键眼部特征。眼睛在面部表情识别、疲劳驾驶监测、视线追踪、情绪分析等场景中起着决定性作用,因此针对眼部特征的检测数据集尤为重要。然而,公开的通用人脸数据集(如 WIDER FACE、CelebA)虽然包含大量样本,但往往对眼部标注不够精细,或者缺少针对性划分,难以满足小样本快速实验或定制化任务的需求。
基于此,我们构建了一个 人脸眼部检测数据集,包含 2000 张图片,数据已完成 划分与标注,可直接应用于训练与测试。该数据集兼顾 样本多样性、标注精确性与任务适配性,旨在为科研人员、开发工程师以及初学者提供一个开箱即用的高质量资源,加速眼部检测及相关领域的研究落地。
数据集概述
本数据集的设计目标是:在有限规模下,兼顾数据的代表性与可用性,既能支持学术研究中的算法验证,也能满足工程项目的快速实验需求。以下是核心概述:
-
规模与划分
- 总图片数:2000 张
- 数据划分:训练集 1400 张,验证集 400 张,测试集 200 张
- 划分方式:保证不同子集中样本分布均衡,涵盖多种性别、年龄、光照和姿态条件。
-
标注内容
- 人脸框:矩形框(Bounding Box),精确框定人脸位置
- 眼部框:独立标注双眼位置,提供左眼和右眼框坐标
- 格式:YOLO、VOC、COCO 三种标注格式均可导出,满足主流深度学习框架需求。
-
样本多样性
- 场景:室内、室外、驾驶舱、办公室、课堂、公共场所
- 光照条件:日间、夜间、逆光、强光、弱光
- 表情与状态:微笑、闭眼、皱眉、打哈欠、平视、低头、侧脸
- 人群属性:男女比例约 1:1,覆盖儿童、青少年、成人与老年群体
-
数据质量控制
- 每张图片均由人工复核,确保标注准确
- 去除模糊、遮挡严重或无效的图片
- 标注误差小于 2 像素,适合关键点检测与小目标识别任务
总的来说,本数据集在数据规模适中的同时,保持了较高的标注精度和场景覆盖度,既适合教学与研究入门,也能作为实验对比的标准数据。
数据集详情
1. 数据组织结构
数据集按照常见深度学习框架的习惯进行了文件夹组织,结构如下:
dataset/
│── images/
│ ├── train/ # 1400 张训练图片
│ ├── val/ # 400 张验证图片
│ └── test/ # 200 张测试图片
│
│── labels/
│ ├── train/ # 对应训练图片的标注文件
│ ├── val/ # 对应验证图片的标注文件
│ └── test/ # 对应测试图片的标注文件
│
│── annotations/ # 可选:VOC / COCO 格式标注文件
│
└── README.md # 数据集说明文档
这种划分方式能够保证快速上手,直接兼容 YOLOv5/YOLOv8、Detectron2、mmdetection 等主流检测框架。
2. 标注格式说明
-
YOLO 格式:
每张图片对应一个.txt文件,每行代表一个目标,格式为:class x_center y_center width height坐标均为归一化比例,类别(class)定义如下:
- 0:人脸
- 1:左眼
- 2:右眼
-
VOC 格式:
每张图片对应一个.xml文件,存储目标类别与边界框坐标。 -
COCO 格式:
提供一个统一的json文件,包含所有图片与标注信息,便于批量加载。
3. 样本多样性与覆盖度
-
光照条件
数据集中有白天室外阳光直射的样本,也有夜间光线不足的驾驶场景,还包含室内灯光偏暗或背光强烈的情况。这对模型在真实应用中的鲁棒性提升至关重要。 -
姿态变化
人脸朝向涵盖正面、半侧脸、低头、抬头等情况;眼睛则覆盖睁眼、闭眼、半闭眼、眯眼等。 -
遮挡情况
部分样本包含遮挡,如眼镜、口罩、帽子、手部遮挡,能够有效提升模型在复杂环境下的检测能力。 -
人群属性
数据覆盖不同肤色、性别、年龄段,有利于减少偏差并提升公平性。
4. 数据预处理建议
虽然数据集已完成基础清洗,但在实际使用中,仍建议进行以下处理:
-
图像增强
- 翻转、旋转、裁剪
- 光照增强(亮度、对比度调整)
- 模糊与噪声添加
可使用Albumentations或torchvision.transforms实现。
-
归一化与缩放
将图片统一到 640×640 或 416×416 等常用输入尺寸,并进行像素归一化到 [0,1] 或 [-1,1]。 -
数据均衡
在训练阶段可采用过采样或类别权重,避免模型对人脸与眼部的检测效果不平衡。
适用场景
1. 驾驶员疲劳检测
在智能驾驶领域,实时监测驾驶员的眼睛状态至关重要。通过检测驾驶员眼睛是否闭合、打哈欠等动作,可以提前预警疲劳驾驶,避免交通事故。
2. 智能安防与监控
在公共场所或监控系统中,人脸眼部检测能够用于身份确认、异常行为分析、注意力追踪等。特别是在监狱、工厂、考场等高风险场景下,眼睛注视方向的分析能辅助行为预测。
3. 人机交互与虚拟现实
在 AR/VR 设备中,眼动追踪是沉浸式体验的重要基础。数据集中的眼部标注可为眼动建模、注视点预测等提供训练样本。
4. 医疗健康
通过分析眼睛的开合频率、运动模式,可以辅助诊断如睡眠障碍、抑郁症、神经系统疾病等。眼部检测也是眼科影像智能分析的基础环节之一。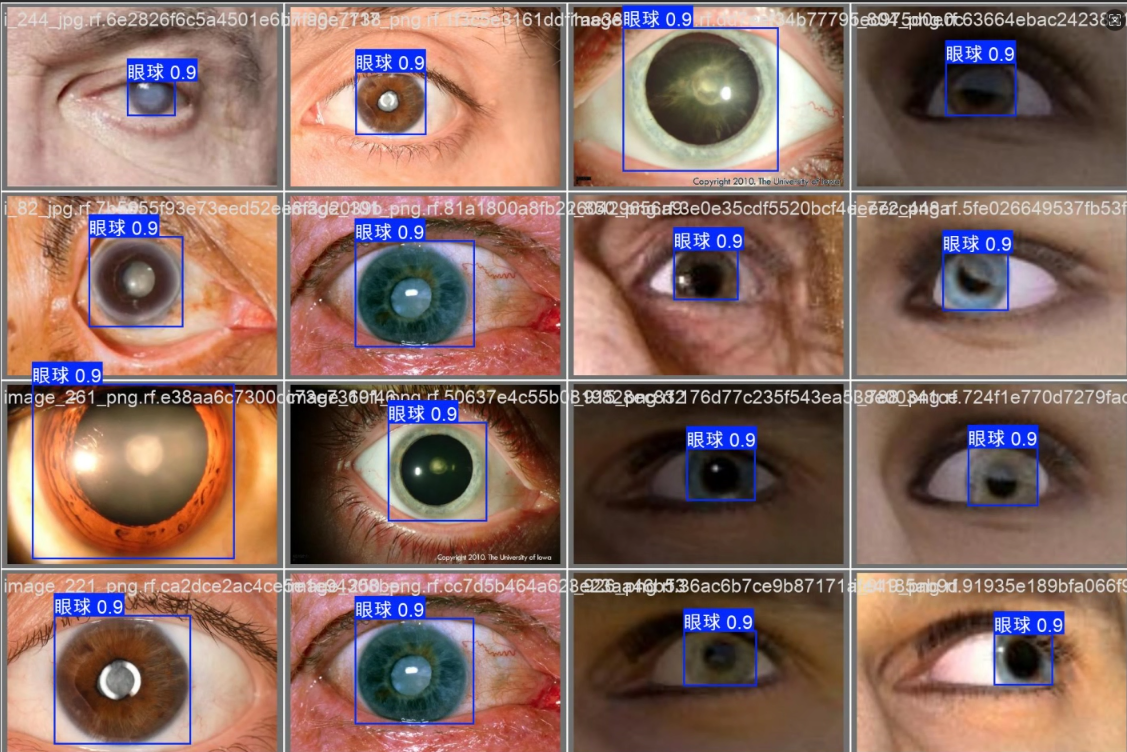
5. 教育与注意力分析
在课堂场景中,通过检测学生眼睛注视方向与眨眼频率,可以辅助教师分析课堂专注度,推动智慧教育的发展。
6. 表情与情绪识别
眼睛是情绪表达的重要窗口。通过检测眼睛的形态变化,可以进一步推断用户的情绪状态,用于情感计算、人机交互系统。
结语
本 人脸眼部检测数据集(2000 张图片已划分、已标注),以中小规模的精细化标注为核心,兼顾多样性与实用性,能够满足从学术研究到工程落地的多种需求。无论是初学者进行深度学习实验,还是科研人员做算法对比,抑或企业在产品开发阶段进行原型验证,该数据集都能提供坚实的数据支撑。
未来,数据集可以进一步扩展规模,引入更多特殊场景(如低分辨率监控视频、极端遮挡条件),并结合关键点标注与三维信息,提升其在眼动追踪、情绪识别、行为预测等方向的应用价值。
数据是人工智能的燃料,而一个高质量、适配性强的数据集,往往能够在关键环节决定模型效果的上限。我们相信,这个数据集将为人脸与眼部检测研究注入新的活力,推动计算机视觉在真实世界的落地应用。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 6
6 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)