
python实现KMeans算法聚类分析
KMeans算法将数据集中的数据点随机生成 k 组,把每组的均值作为 中心点。计算每个数据点与各组的中心点的相似性,根据数据点相似性的度量准 则,把每个数据点重新分组,计算每组新的均值作为中心点。不断重复上述过程,直 到中心点的均值收敛,停止迭代过程。
·
一,KMeans概述
KMeans算法将数据集中的数据点随机生成 k 组,把每组的均值作为 中心点。计算每个数据点与各组的中心点的相似性,根据数据点相似性的度量准 则,把每个数据点重新分组,计算每组新的均值作为中心点。不断重复上述过程,直 到中心点的均值收敛,停止迭代过程。
二,代码
from collections import Counter
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import random as rd
# Kmeans聚类
def Kmeans(k, data):
# 随机选取k个样本点作为初始簇心
cluster_center = data[rd.sample(list(range(len(data))), k)]
# 对每个样本进行分类,初始都归为0类
Cluster_tag = np.zeros((len(data),))
# 迭代
t = 10
while t > 0:
for i, sample in enumerate(data):
# 样本与簇心的距离_distance
_distance = distance(sample, cluster_center)
# 得到该序列最小值的索引
min_idx = np.argmin(_distance)
if Cluster_tag[i] != min_idx:
Cluster_tag[i] = min_idx
# 更新簇心坐标
for tag in range(k):
centroid = np.mean(data[Cluster_tag == tag], axis=0)
cluster_center[tag] = centroid
t = t - 1
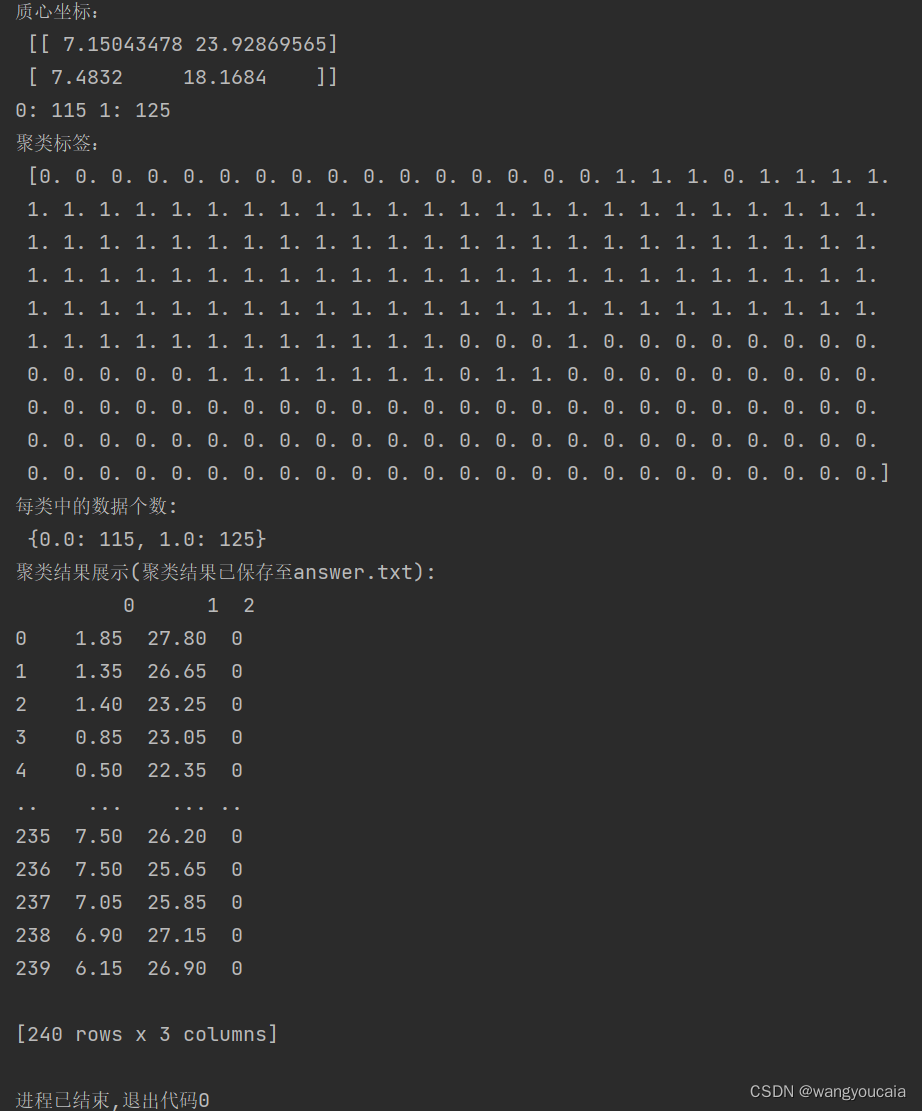
print('质心坐标:\n', cluster_center)
j = 0
while j < len(range(k)):
plt.scatter(cluster_center[j][0], cluster_center[j][1], c='red', marker='*', s=50)
j = j + 1
return Cluster_tag
# 导入数据
def Import_data():
import_data = np.array(pd.read_csv(r'D:\Desktop\kmpractise\flame.txt', sep='\t', header=None, usecols=[0, 1]))
return import_data
# 计算欧式距离
def distance(x, y):
return np.sum((x - y) ** 2, axis=1) ** 0.5
# 聚类结果可视化展示
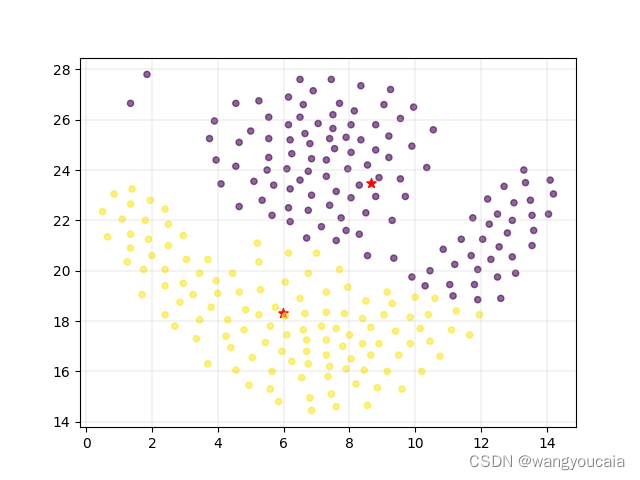
def show(data, labels):
plt.scatter(data[:, 0], data[:, 1], c=labels, alpha=0.6, s=20)
plt.grid(axis='both', linewidth=0.2)
plt.show()
# 导出聚类结果
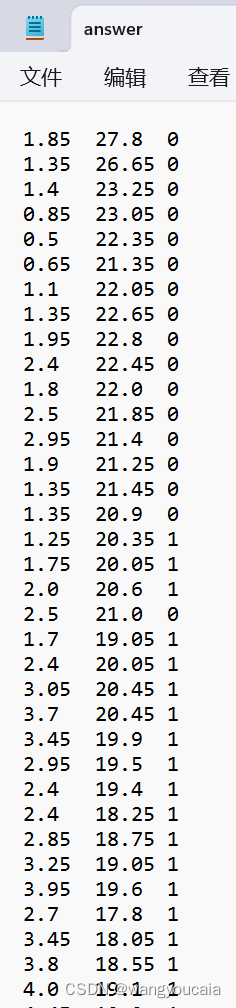
def Clustering_result(m, n):
i = -1
while i < n.shape[0] - 1:
i = i + 1
with open(r'D:\soft\PyCharm 2022.1.3\pythonproject\kms\answer.txt', 'a+', encoding='utf-8') as f:
print(m[i][0], m[i][1], int(n[i]), sep='\t', file=f)
if __name__ == '__main__':
data = Import_data()
Cluster_tag = (Kmeans(2, data))
dict1 = dict(Counter(Cluster_tag))
print('0:', list(Cluster_tag).count(0), '1:', list(Cluster_tag).count(1))
print('聚类标签:\n', Cluster_tag, '\n每类中的数据个数:\n', dict1)
Clustering_result(data, Cluster_tag)
ans = pd.read_csv(r'D:\soft\PyCharm 2022.1.3\pythonproject\kms\answer.txt', sep='\t', header=None)
print('聚类结果展示(聚类结果已保存至answer.txt):\n', ans)
show(data, Cluster_tag)
#要使用的数据集falme.txt(只展示部分数据):

三,运行结果展示

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)