
ByteBuf使用详解:ByteBuff组成、扩容、retain、release、零拷贝(slice、duplicate、compositeByteBuf、unpolled)、深拷贝。
ByteBuf是对字节数据的封装。是netty的Server与Client之间通信的数据传输载体(Netty的数据容器),它提供了一个byte数组(byte[])的抽象视图,既解决了JDK API的局限性,又为网络应用程序的开发者提供了更好的API。ByteBuf使用详解:ByteBuff组成、扩容、retain、release、零拷贝(slice、duplicate、compositeByteB
ByteBuf是对字节数据的封装。是netty的Server与Client之间通信的数据传输载体(Netty的数据容器),它提供了一个byte数组(byte[])的抽象视图,既解决了JDK API的局限性,又为网络应用程序的开发者提供了更好的API。
创建
// 创建ByteBuf
ByteBuf byteBufHeap = ByteBufAllocator.DEFAULT.heapBuffer();
ByteBuf byteBufDirect = ByteBufAllocator.DEFAULT.directBuffer();
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer();
log.info("{}", byteBufHeap.getClass());
log.info("{}", byteBufDirect.getClass());
log.info("{}", byteBuf.getClass());控制台输出结果如下:

创建结果:基于池化的堆ByteBuf、基于池化的直接内存ByteBuf、基于池化的直接内存ByteBuf。
直接内存和堆内存的对比
-
直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用
-
直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放
参考ByteBuffer中其他优质博客回答:

池化VS非池化
池化的意义在于可以重用ByteBuf。
-
没有池化,则每次都得创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力。
-
有了池化,则可以重用池中 ByteBuf 实例。高并发时,池化功能更节约内存,减少内存溢出的可能。
可以通过设置虚拟机参数-Dio.netty.allocator.type={unpooled|pooled}来开启或关闭池化技术。Netty4.1之后windows平台默认开启池化技术,关闭池化技术操作如下:

ByteBuf的组成
ByteBuf主要由四部分组成:废弃字节、可读字节、可写字节、可扩容字节。已经读取过的部门成为废弃字节。
与ByteBuffer内部只有一个指针控制读写不同(通过读写切换控制读写),ByteBuf内部有一个读指针和一个写指针,分别控制读写的位置。从而省去了读写切换。
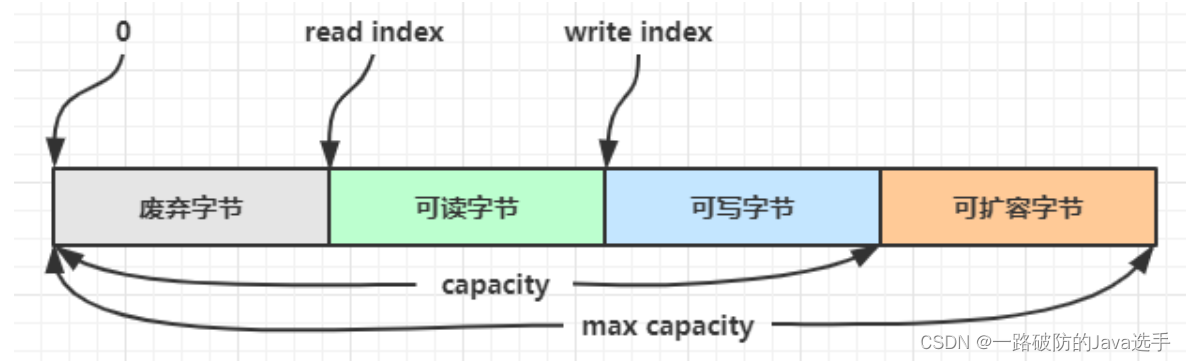
新创建的ByteBuf读写指针均在0位置。

 ByteBuf创建时若不指定字节数,则默认创建字节大写为256;若指定字节数,则依据指定的字节大小创建。ByteBuf能够创建的最大字节数为整型的最大值,约20亿个字节。
ByteBuf创建时若不指定字节数,则默认创建字节大写为256;若指定字节数,则依据指定的字节大小创建。ByteBuf能够创建的最大字节数为整型的最大值,约20亿个字节。
ByteBuf的扩容
- 如果写入后数据大小未超过512,则选择下一个16的整数倍。
- 如果写入后数据大小超过512,则选择下一个2^n。
- 且扩容不能超过max capacity。
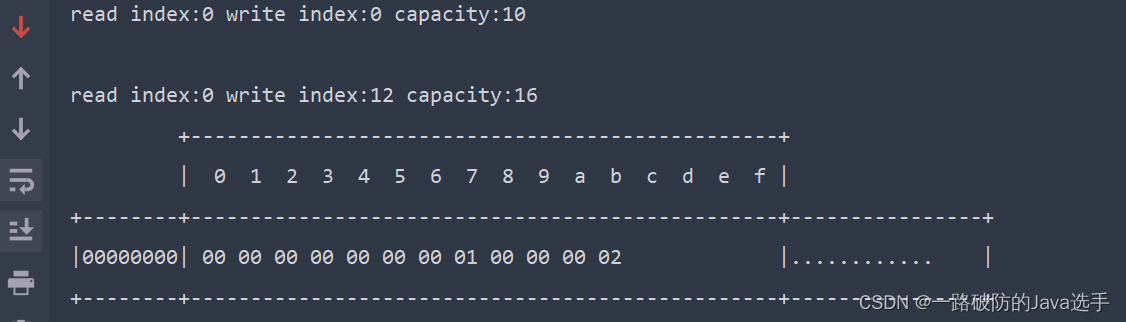
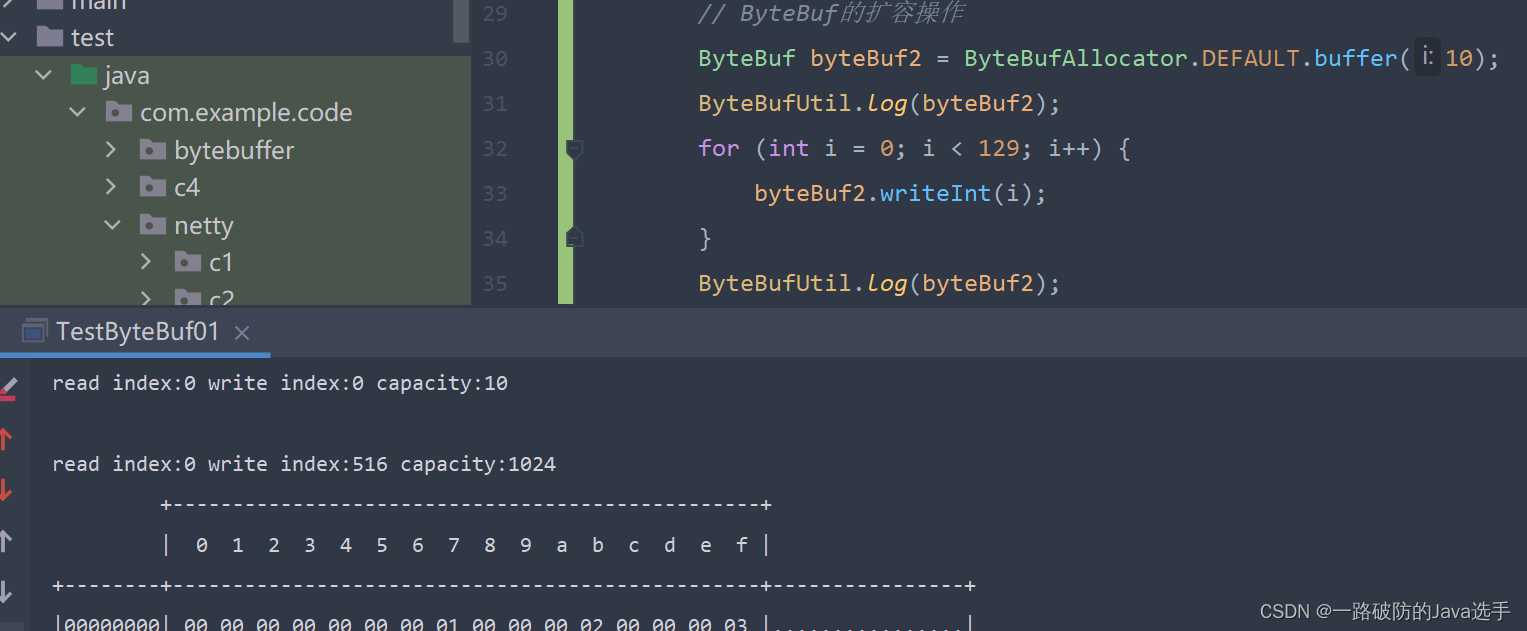
例:创建一个ByteBuf初始容量为10,写入后大小为12,则会将其扩容为16。
例:创建一个ByteBuf初始容量为10,写入后大小为516,则会将其扩容为1024。
ByteBuf的retain和release
由于 Netty 中有堆外内存的 ByteBuf 实现,堆外内存最好是手动来释放,而不是等 GC 垃圾回收。
-
UnpooledHeapByteBuf 使用的是 JVM 内存,只需等 GC 回收内存即可
-
UnpooledDirectByteBuf 使用的就是直接内存了,需要特殊的方法来回收内存
-
PooledByteBuf 和它的子类使用了池化机制,需要更复杂的规则来回收内存
Netty采用了引用计数法来控制回收内存,每个ByteBuf都实现了ReferenceCounted接口。
- 初始每个ByteBuf对象的计数为1。
- 调用release方法计数减1,如果计数为0,ByteBuf内存被回收。release的基本规则:哪个ChannelHandler是最后的使用者,谁负责release。
- 调用retain方法计数加1,如果调用者没用完之前,其他hander即时调用了release也不会造成回收。
- 当计数为0时,底层内存会被回收,即时ByteBuf对象还在,其各个方法均无法正常使用。当使用slice及duplicate等操作时需要及时调用retain方法,防止各个方法均无法正常使用。
ByteBuf中的零拷贝
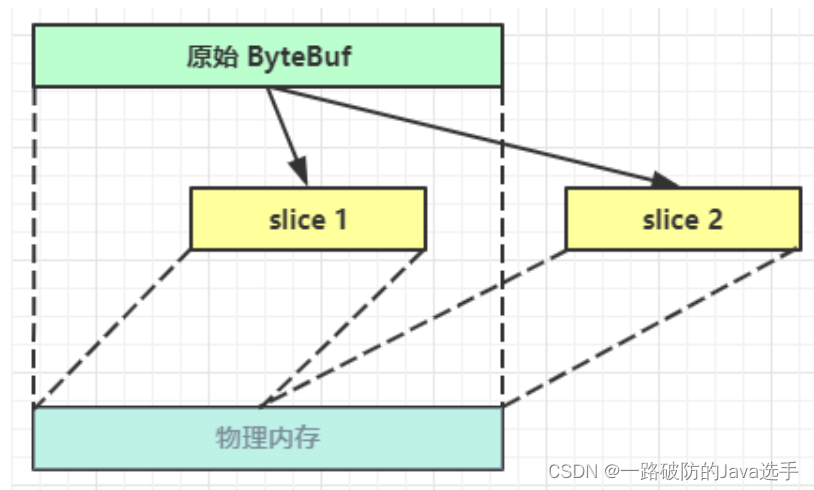
slice
slice对原始ByteBuf切片成多个ByteBuf,切片后的ByteBuf并没有发生内存复制,还是使用原始 ByteBuf 的内存,切片后的 ByteBuf 维护独立的 read,write 指针。
测试代码如下:用于验证ButeBuf的slice没有发生内存复制。
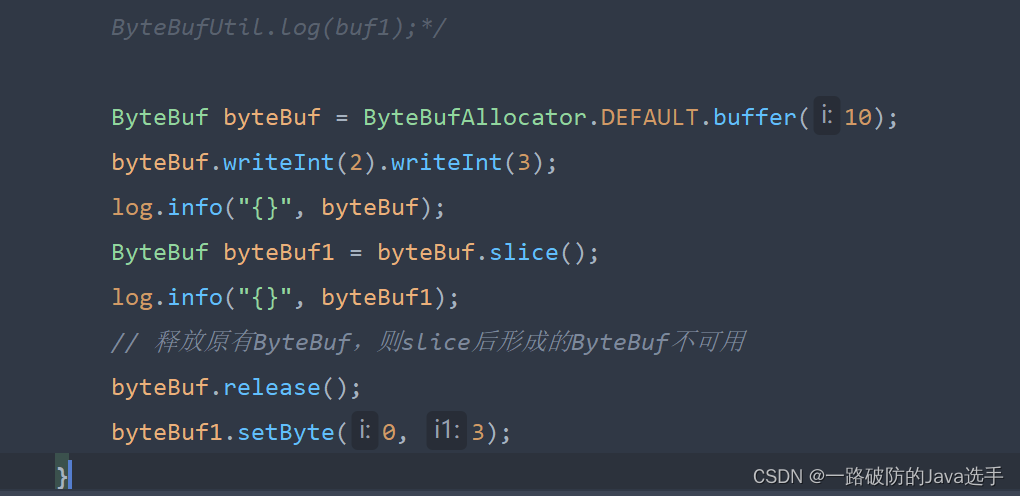
public class TestSlice {
public static void main(String[] args) {
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer(10);
buf.writeBytes("abcdefghig".toString().getBytes());
ByteBufUtil.log(buf);
ByteBuf buf1 = buf.slice(0, 5);
ByteBuf buf2 = buf.slice(5, 5);
ByteBufUtil.log(buf1);
ByteBufUtil.log(buf2);
System.out.println("=========================");
// 验证slice切片后的ByteBuf没有发生内存复制,还是使用原始ByteBuf的内存
buf1.setByte(0, 'g');
ByteBufUtil.log(buf);
ByteBufUtil.log(buf1);
}
}- 对原始ByteBuf使用slice形成新的切片后的ByteBuf,其大小受到限制,如果没有指定起始下标以及切片大小,则切片大小为read指针至write指针之间的区域;若指定切片大小,则按照指定大小进行划分。
- 形成的新的ByteBuf由于容量固定,故不能继续写入元素,只能修改原有下标对应的元素值。
- 如果释放原有ByteBuf,则切片后形成的ByteBuf也不能使用了。
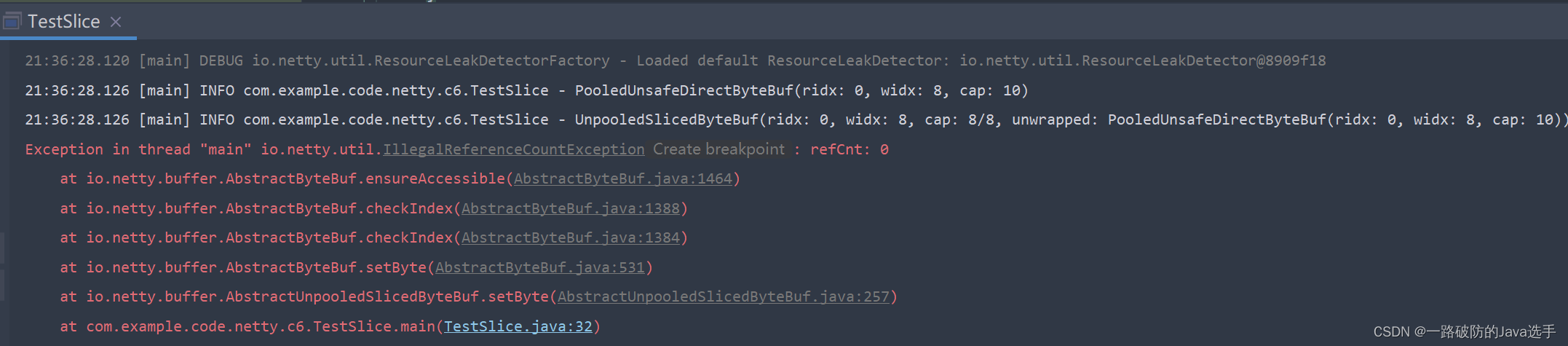 解决上述问题:切片后对新的ByteBuf使用retain()函数,增加其引用计数,当切片后的ByteBuf使用完毕后及时调用release()方法释放其引用计数。
解决上述问题:切片后对新的ByteBuf使用retain()函数,增加其引用计数,当切片后的ByteBuf使用完毕后及时调用release()方法释放其引用计数。
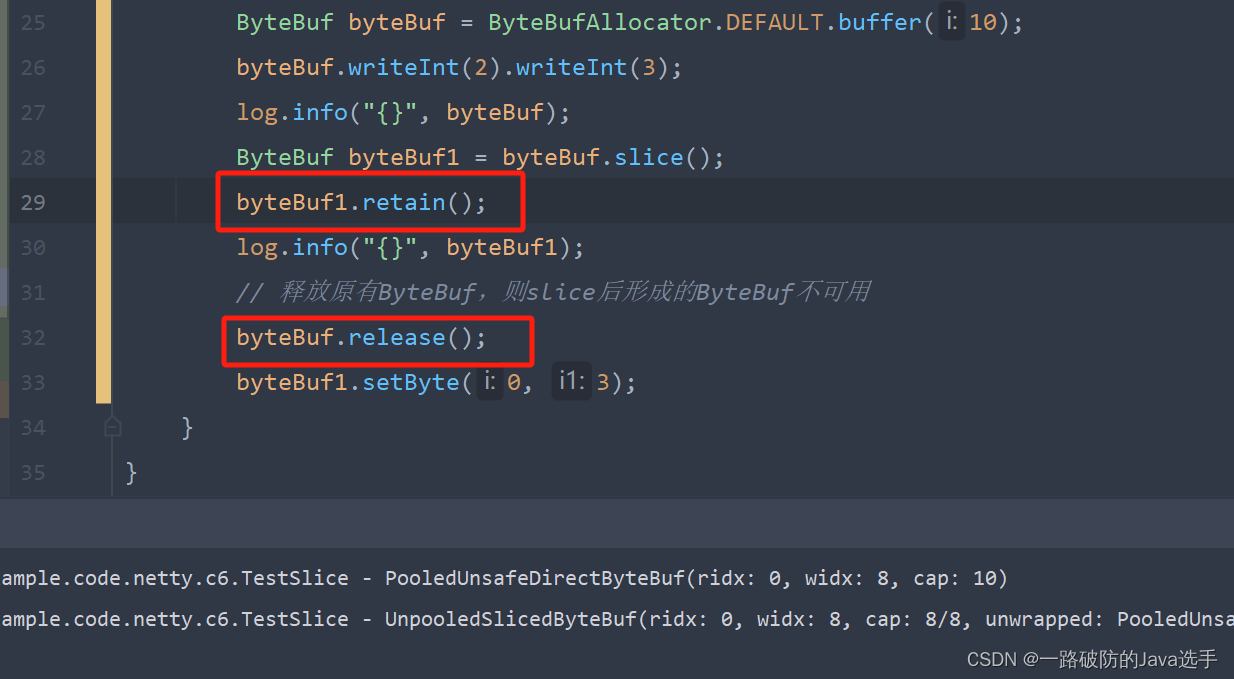
修复后代码不再报错,可以正确执行,但需要注意,子ByteBuf调用retain()方法后,不再使用时必须主动调用release()方法,否则原ByteBuf调用release()后无法释放其内存。
duplicate
相较于slice()截取原ByteBuf部分内容而言,duplicate是截取了原ByteBuf的所有内容,并且没有max capacity的限制,也是与原始ByteBuf共同使用同一块底层内存,只是读写指针是独立的。
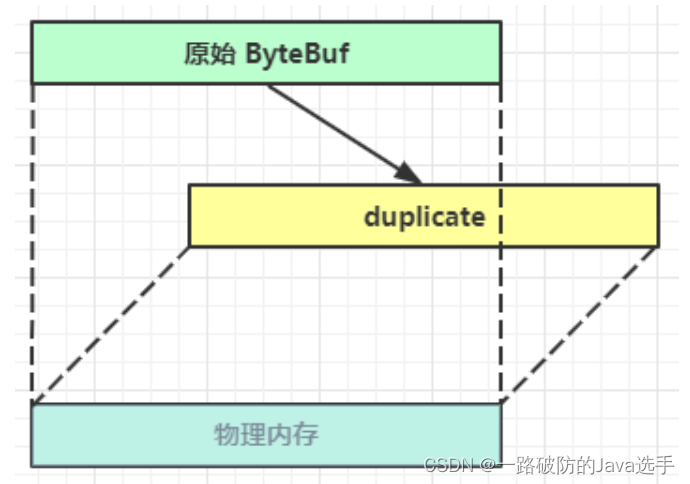
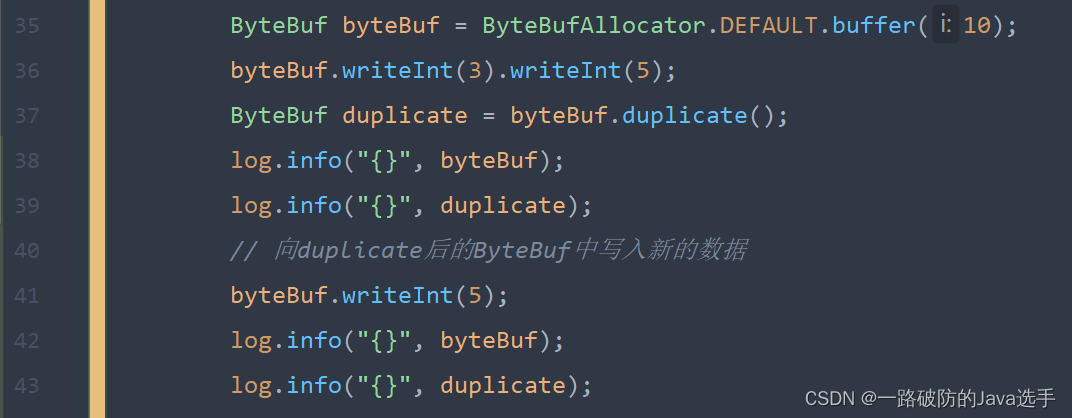
 duplicate使用的是非池化的计数。随着原ByteBuf的release而release。
duplicate使用的是非池化的计数。随着原ByteBuf的release而release。
compositeByteBuf
compositeByteBuf可以将多个ByteBuf合并为一个ByteBuf,避免了底层内存的拷贝操作。
public class TestCompositeByteBuf {
public static void main(String[] args) {
ByteBuf byteBuf1 = ByteBufAllocator.DEFAULT.buffer(10);
ByteBuf byteBuf2 = ByteBufAllocator.DEFAULT.buffer(10);
byteBuf1.writeInt(2).writeInt(4);
byteBuf2.writeInt(5).writeInt(3);
// 第二种方式使用compositeByteBuf创建,避免底层数据的复制
CompositeByteBuf byteBuf3 = ByteBufAllocator.DEFAULT.compositeBuffer();
byteBuf3.addComponents(true, byteBuf1, byteBuf2);
ByteBufUtil.log(byteBuf3);
System.out.println("=================================");
// 第一种方式创建新的ByteBuf进行数据复制
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer(byteBuf1.readableBytes() + byteBuf2.readableBytes());
byteBuf.writeBytes(byteBuf1).writeBytes(byteBuf2);
ByteBufUtil.log(byteBuf);
}
}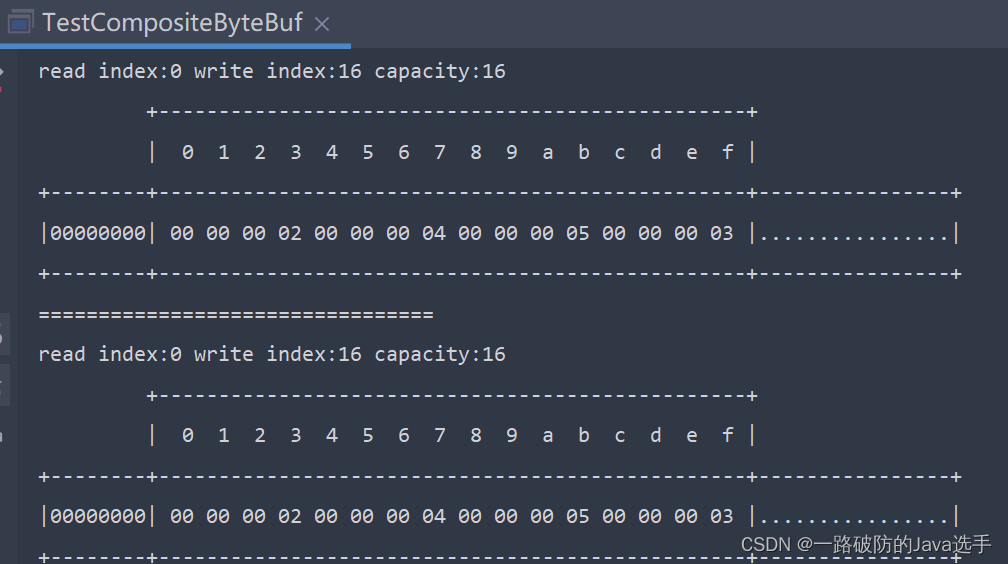
CompositeByteBuf 是一个组合的 ByteBuf,它内部维护了一个 Component 数组,每个 Component 管理一个 ByteBuf,记录了这个 ByteBuf 相对于整体偏移量等信息,代表着整体中某一段的数据。对外是一个虚拟视图,组合这些 ByteBuf 不会产生内存复制。
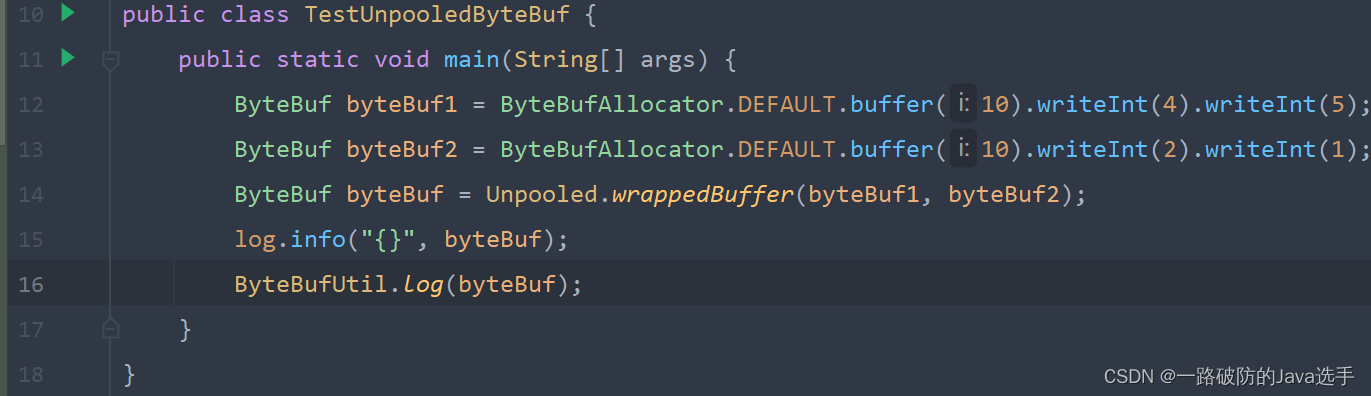
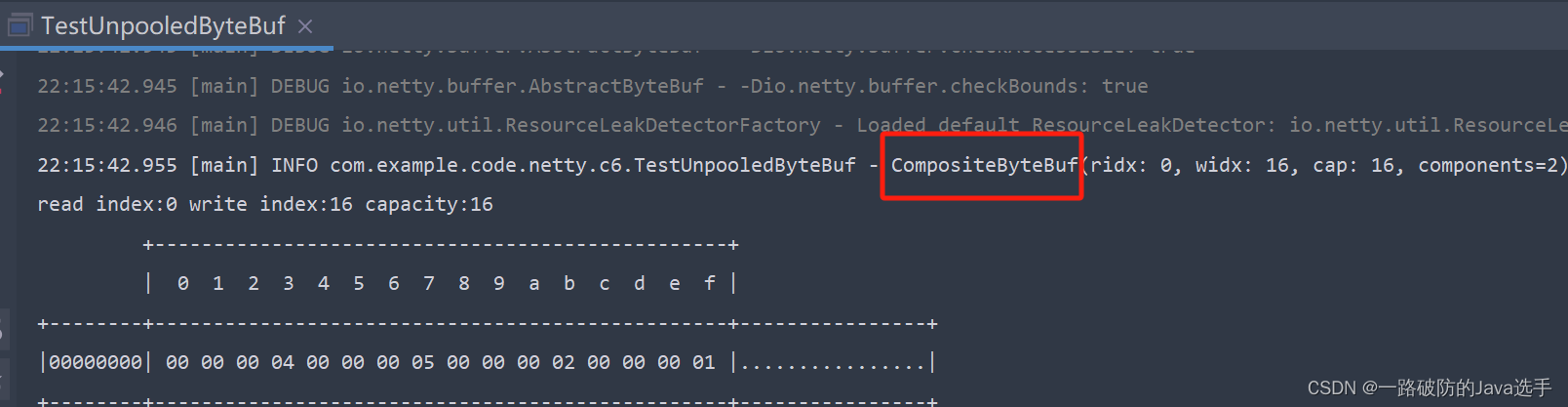
Unpooled
Unpooled是一个工具类,提供了非池化的ByteBuf的创建、组合、复制等操作。其中wrappedBuffer 方法,可以用来包装 ByteBuf。当ByteBuf个数超过一个时,底层使用了compositeByteBuf。
 ByteBuf中的深拷贝
ByteBuf中的深拷贝
copy会将底层内存数据进行深拷贝,因此无论读写,都与原始 ByteBuf 无关。
ByteBuf的优势
- 池化 - 可以重用池中 ByteBuf 实例,更节约内存,减少内存溢出的可能
- 读写指针分离,不需要像 ByteBuffer 一样切换读写模式
- 可以自动扩容
- 支持链式调用,使用更流畅
- 很多地方体现零拷贝,例如 slice、duplicate、CompositeByteBuf

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)