
模型batch推理会更快吗?_batch测推理速度和单张,熬夜整理小米Linux运维面试题
其实当batch size非常大时,相当于在让GPU持续工作直到计算完成,减少了等待时间,所以性能越高可以并行计算的量也就越大,加速越明显。如果单张图的计算量已经快占满计算核心(达到性能瓶颈),再增加batch size也无法多张图并行计算,尤其是在网络中间的一些层channel数特别大时,瞬时矩阵乘法运算量非常大,cuda核用满了就需要排队慢慢计算。不论你是正从事IT行业的老鸟或是对IT行业感兴
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
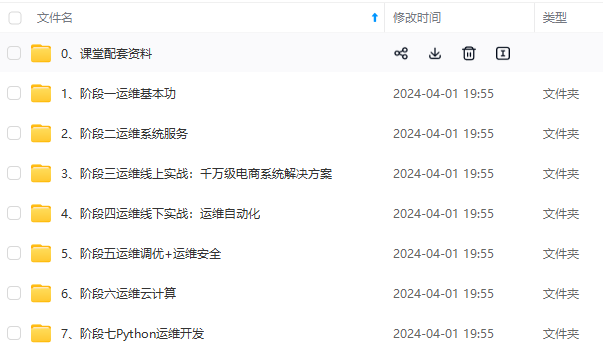
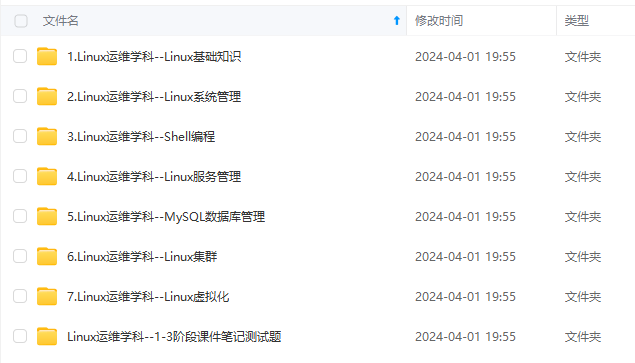
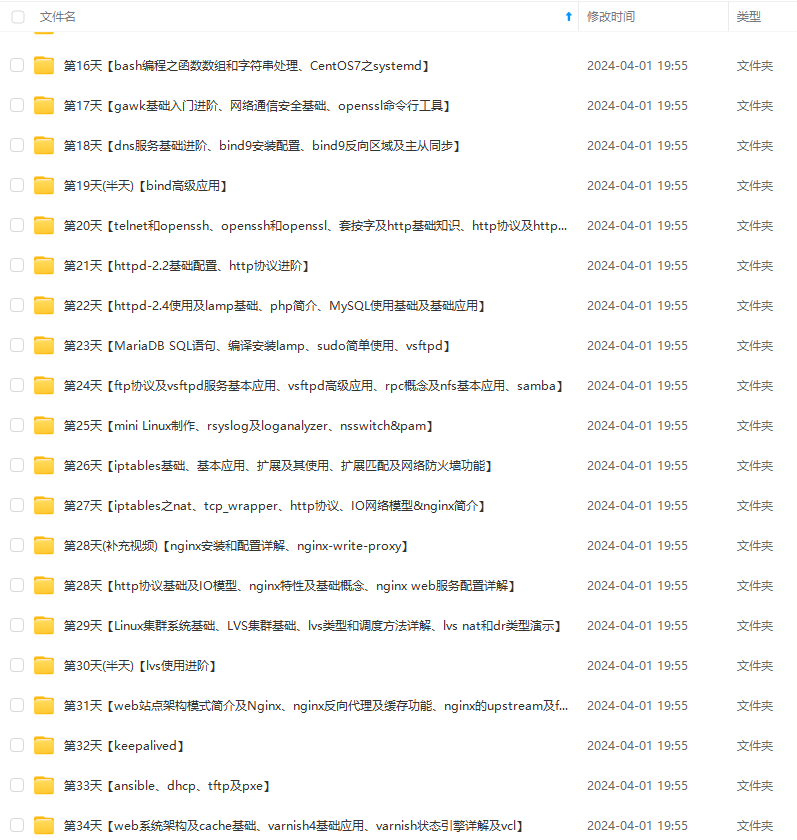
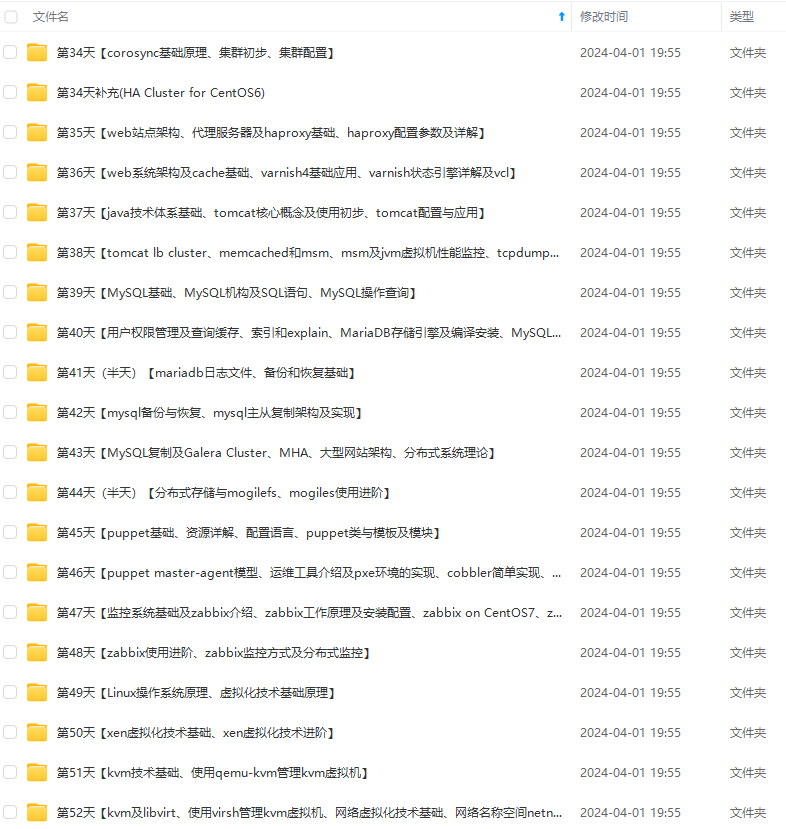
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)
正文
原因分析:
在网上搜索一番,大概定位原因,这里参考GitHub tensorrt 的 issues 1046解答【2】:
简单来说,问题在于gpu计算性能有瓶颈。如果单张图的计算量已经快占满计算核心(达到性能瓶颈),再增加batch size也无法多张图并行计算,尤其是在网络中间的一些层channel数特别大时,瞬时矩阵乘法运算量非常大,cuda核用满了就需要排队慢慢计算。
Generally, GPU computation is more efficient when the batch size is larger. This is because when you have a lot of ops, you can fully utilize the GPUs and hide some inefficiency or overhead between ops. However, if there are already a lot of ops at BS=1 and even BS=1 is able to fully utilize the GPUs, you may not see any increase in efficiency anymore.
For example, is your input size BSx3x1600x1000? This is a super large image which is expected to fully utilize even the largest GPU we have (like A100), so I don’t think increasing BS gives benefit on GPU efficiency.
In terms of N/V/K, in your case the “N” is already 1600x1000 at BS=1, so N=1600x1000 vs N=2x1600x1000 do not make too much difference in turns of GPU efficiency, compared to N=1 vs N=2.
另外一个现象就是gpu性能越高,batch inference效果提升越明显。如笔者在xavier上测试单帧推理时,GPU利用率就接近60%,所以当batch size增加时基本无增益,而yolov5作者在A100(性能天花板更高)测试时,加速效果更明显。其实当batch size非常大时,相当于在让GPU持续工作直到计算完成,减少了等待时间,所以性能越高可以并行计算的量也就越大,加速越明显。
可以尝试的优化方向:
遇到上述情况,想要加快推理速度,除了最直接的-换更高性能的设备,暂时想到如下两个方向优化:
减少计算量:
- 降低模型输入尺寸
- 优化网络结构(中间计算量非常大的某些层),思想就是大的矩阵分解计算;想简单省事的就看是否有开源的成果,如yolov5升级yolov8之类的
- 模型导trt,模型量化(fp16, int8)、剪枝等
- 升级trt版本说不定有惊喜,NVIDIA的工程师们可能对某些算子做了优化
减少cuda核等待时间:
- 异步模式(多线程等),就是不让gpu闲着,一直去计算
如有其它后续补充…
Reference
- https://docs.google.com/spreadsheets/d/1Nm3jofjdgKja0AZHV8Jk_m8TgcF7jenCSA06DuEG2C0/edit?usp=sharing
- https://github.com/NVIDIA/TensorRT/issues/1046
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)