
重启docker服务过于频繁触发systemd启动限制机制start-limit-hit,导致重启docker服务失败(Job for docker.service failed.)60秒3次限制
问题主要由于 systemd 的启动限制机制引起。通过合理安排重启时间间隔或调整 systemd 的配置,可以避免类似的问题再次发生。同时,建议检查 Docker 服务的详细日志,确保没有其他潜在的问题影响服务的正常运行。
文章目录
问题背景
问题
清理了docker然后等待5秒重启docker失败了?过了两分钟,再启动docker又成功了?
shell代码
echo "执行清理Docker未使用的卷和网络"
# 强制删除未使用的卷
docker volume prune -f || true
# 强制删除未使用的网络
docker network prune -f || true
echo "重启Docker服务"
# 重启Docker服务以确保所有更改生效并释放未回收的资源(注意:清理docker资源后立即重启docker似乎会导致docker重启失败,加上睡眠以避免此类问题)
sleep 5
systemctl restart docker || true
sleep 5
程序日志
执行清理Docker未使用的卷和网络
Deleted Volumes:
514fdd8b6df16098a938e59bd8f0716a7e42b9768bd43b31f6801fe8881715b9
c53ff3bfa33976284d62ad6593c0eba2f241897a051dbfd79c51c3d3da6aca28
d104be69c296ecc8737fb1c0941a5c4cea8b95914f3d545958cd874e39263801
Total reclaimed space: 0B
Deleted Networks:
kyai-java-network
重启Docker服务
Job for docker.service failed.
See "systemctl status docker.service" and "journalctl -xe" for details.
python
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
docker服务日志
Jan 09 23:23:25 shsany systemd[1]: Stopped Docker Application Container Engine.
Jan 09 23:23:25 shsany systemd[1]: docker.service: Start request repeated too quickly.
Jan 09 23:23:25 shsany systemd[1]: docker.service: Failed with result 'start-limit-hit'.
Jan 09 23:23:25 shsany systemd[1]: Failed to start Docker Application Container Engine.
解释
这个问题主要与 systemd 的启动限制(start-limit)机制有关。当在短时间内多次尝试重启 Docker 服务时,systemd 会阻止进一步的启动尝试,以防止服务进入频繁失败和重启的循环。这就是为什么在清理 Docker 后,等待 5 秒重启 Docker 失败,而等待两分钟后又能成功重启的原因。
问题解析
-
清理 Docker 资源:
您执行了清理未使用的卷和网络,但没有释放任何空间。这本身不会直接导致 Docker 服务启动失败。 -
尝试重启 Docker 服务:
- 第一次重启尝试:在清理后立即尝试重启 Docker,systemd 记录了这次重启请求。
- 失败原因:
docker.service: Start request repeated too quickly.和Failed with result 'start-limit-hit'.表明 systemd 的启动限制被触发了。
-
启动限制机制:
systemd 默认对服务的启动尝试次数和时间间隔有一定的限制(通常是 5 次启动尝试在 10 秒内)。如果超过这个限制,systemd 会暂时阻止进一步的启动尝试,以防止服务进入不稳定状态。 -
等待两分钟后重试:
经过一段时间(超过 systemd 的启动限制时间窗口)后,systemd 会重置启动限制计数器,此时再次尝试启动 Docker 服务就不会受到之前的限制影响,从而成功启动。
解决方案和建议
-
等待足够的时间再重启:
在进行多次重启尝试时,确保每次重启之间的间隔超过 systemd 的启动限制时间窗口(通常为 10 秒)。这样可以避免触发start-limit-hit错误。 -
检查 Docker 服务状态和日志:
使用以下命令查看 Docker 服务的状态和详细日志,有助于诊断问题的具体原因:systemctl status docker.service journalctl -xe -
调整 systemd 的启动限制(不推荐,除非有充分理由):
如果确实需要频繁重启 Docker 服务,可以考虑调整 systemd 的启动限制参数。编辑 Docker 服务的 systemd 配置文件(通常位于/etc/systemd/system/docker.service或/lib/systemd/system/docker.service),添加或修改以下设置:[Service] StartLimitInterval=60 StartLimitBurst=10这将允许在 60 秒内进行最多 10 次启动尝试。修改后,重新加载 systemd 配置并重启 Docker 服务:
sudo systemctl daemon-reload sudo systemctl restart docker.service注意:调整启动限制可能会掩盖潜在的问题,建议在确保服务稳定的前提下进行。
-
确保 Docker 配置和环境没有问题:
有时候,Docker 服务启动失败可能不仅仅是因为启动限制,还可能与配置文件或环境问题有关。确保 Docker 的配置文件(如/etc/docker/daemon.json)没有错误,并且相关依赖项正常工作。
总结
问题主要由于 systemd 的启动限制机制引起。通过合理安排重启时间间隔或调整 systemd 的配置,可以避免类似的问题再次发生。同时,建议检查 Docker 服务的详细日志,确保没有其他潜在的问题影响服务的正常运行。
测试
连续过快重启docker服务,发现确实如此,触发了systemd启动限制。
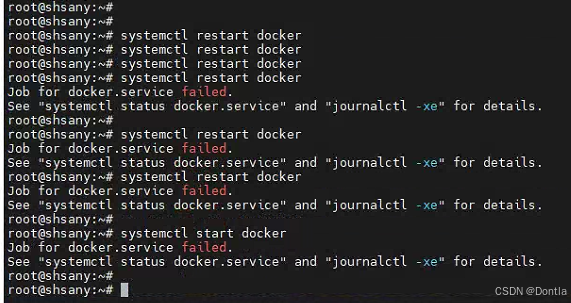
至于“多快”?这个貌似还不好确定。
查看docker服务配置文件信息
/etc/systemd/system/docker.service(没这个文件,我的操作系统是ubuntu20.04 arm)

/lib/systemd/system/docker.service ★★★★★
服务内容
root@shsany:~# cat /lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service containerd.service
Wants=network-online.target
Requires=docker.socket
Wants=containerd.service
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
# Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229.
# Both the old, and new location are accepted by systemd 229 and up, so using the old location
# to make them work for either version of systemd.
StartLimitBurst=3
# Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230.
# Both the old, and new name are accepted by systemd 230 and up, so using the old name to make
# this option work for either version of systemd.
StartLimitInterval=60s
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Comment TasksMax if your systemd version does not support it.
# Only systemd 226 and above support this option.
TasksMax=infinity
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
OOMScoreAdjust=-500
[Install]
WantedBy=multi-user.target
root@shsany:~#
主要是这两个字段(StartLimitBurst、StartLimitInterval)
# Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229.
# Both the old, and new location are accepted by systemd 229 and up, so using the old location
# to make them work for either version of systemd.
StartLimitBurst=3
# Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230.
# Both the old, and new name are accepted by systemd 230 and up, so using the old name to make
# this option work for either version of systemd.
StartLimitInterval=60s
# 请注意,在 systemd 229 中,StartLimit* 选项从 "Service" 移动到了 "Unit"。
# systemd 229 及更高版本同时接受旧位置和新位置,因此使用旧位置可以兼容不同版本的 systemd。
StartLimitBurst=3
# 请注意,在 systemd 230 中,StartLimitInterval 被重命名为 StartLimitIntervalSec。
# systemd 230 及更高版本同时接受旧名称和新名称,因此使用旧名称可以兼容不同版本的 systemd。
StartLimitInterval=60s
参数分析
当前启动限制配置
在上述 docker.service 文件中,相关的启动限制配置如下:
StartLimitBurst=3
StartLimitInterval=60s
含义解释:
- StartLimitBurst=3:在指定的时间窗口内,最多允许 3 次启动尝试。
- StartLimitInterval=60s:时间窗口为 60 秒。
这意味着,如果在 60 秒 内尝试 重启 Docker 服务超过 3 次,systemd 会触发启动限制,阻止进一步的启动尝试,导致 start-limit-hit 错误。
如何避免启动限制错误
- 限制重启次数:确保在 60 秒 内不要超过 3 次重启 Docker 服务。
- 合理安排重启间隔:例如,等待至少 20 秒 再进行下一次重启尝试。

技术共进,成长同行——讯飞AI开发者社区
更多推荐
 31
31 0
0- 0



 已为社区贡献114条内容
已为社区贡献114条内容

所有评论(0)