
[论文阅读] 人工智能 | 软件工程 - 软件测试 | 从黑盒到透明:AUTOSTUB用进化算法打通符号执行的“最后一公里”
摘要 AUTOSTUB是德国吕贝克大学团队提出的一种基于遗传编程(GP)和语法引导遗传编程(G3P)的符号桩自动生成方法,旨在解决符号执行中外部函数(如第三方库、原生方法)的黑盒问题。该方法通过随机输入采样收集输入-输出对,利用G3P迭代进化出近似函数行为的表达式作为符号桩,无需人工干预或昂贵SMT求解器。实验表明,AUTOSTUB对55%的评估函数实现了超90%的近似准确率,79个函数的符号桩完
从黑盒到透明:AUTOSTUB用进化算法打通符号执行的“最后一公里”
论文信息
| 信息类别 | 具体内容 |
|---|---|
| 论文原标题 | 《AUTOSTUB: Genetic Programming-Based Stub Creation for Symbolic Execution》 |
| 主要作者 | Felix Machtle、Nils Loose、Jan-Niclas Serr、Jonas Sander、Thomas Eisenbarth |
| 研究机构 | 德国吕贝克大学(University of Luebeck)IT安全研究所 |
| APA引文格式 | Machtle, F., Loose, N., Serr, J.-N., Sander, J., & Eisenbarth, T. (2025). AUTOSTUB: Genetic Programming-Based Stub Creation for Symbolic Execution. arXiv Preprint arXiv:2509.08524. |
| 开源资源 | 代码与数据集GitHub地址:https://github.com/UzL-ITS/AutoStub |
一段话总结
AUTOSTUB是德国吕贝克大学团队提出的符号桩自动生成方法,核心通过遗传编程(GP)与语法引导遗传编程(G3P),解决符号执行中外部函数(如第三方库、原生方法)难以分析的“黑盒问题”。它无需人工干预或昂贵SMT求解器,先生成随机输入收集外部函数的“输入-输出对”构建训练数据,再通过G3P迭代进化出近似函数行为的表达式作为符号桩;实验显示,其对55%的评估函数实现超90%近似准确率,79个函数的桩完全正确,且集成到SWAT符号执行引擎后平均求解时间仅0.04秒,能探索此前无法处理的程序路径,虽目前仅支持无状态函数、限于常规复杂度表达式,但为符号执行的自动化分析提供了高效新方案。
思维导图
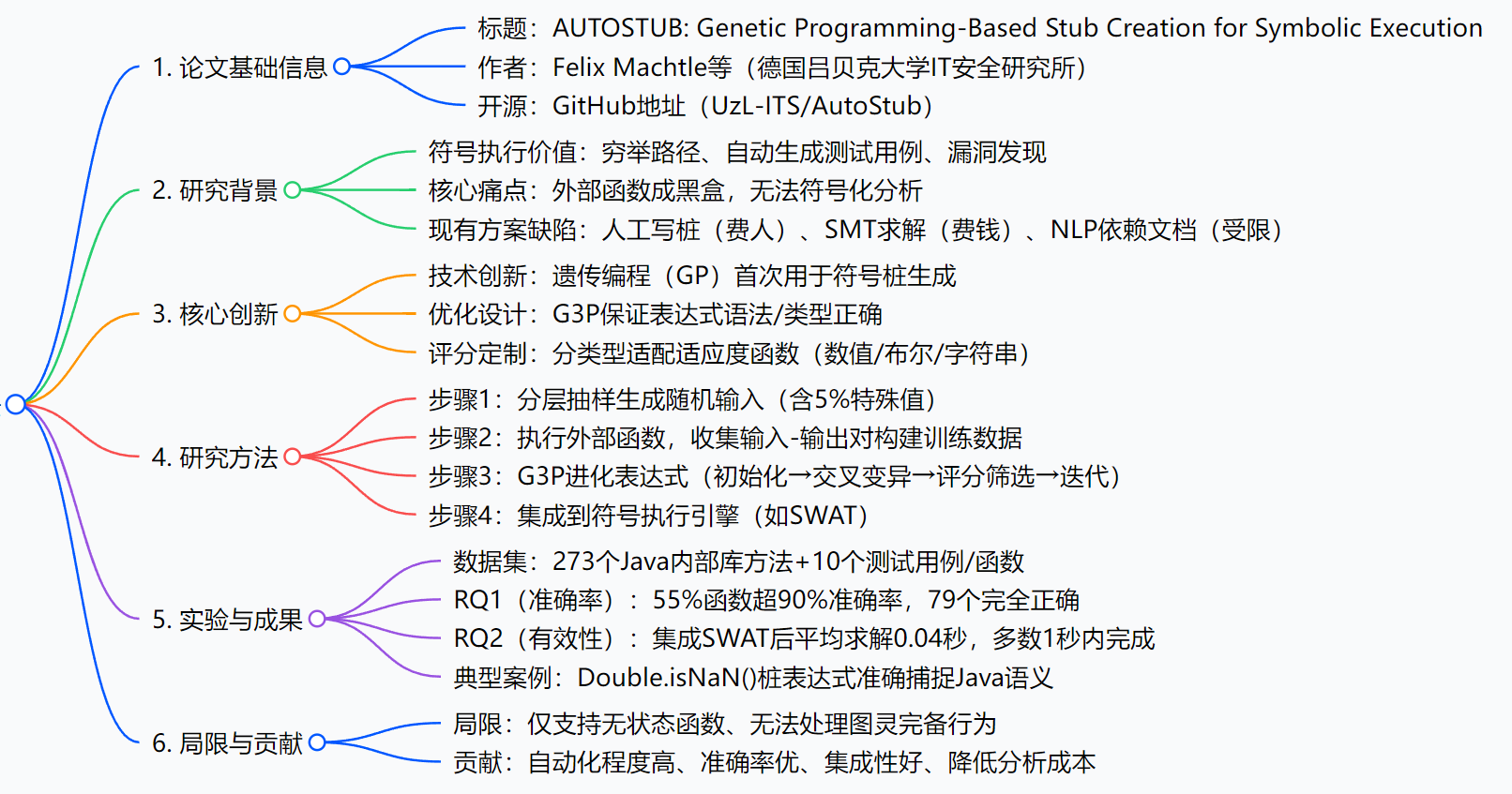
研究背景
要理解AUTOSTUB的价值,得先从“符号执行”这个核心技术的“优势与困境”说起。
1. 符号执行:软件测试的“路径探索神器”
常规测试像“盲人摸象”——给一个具体输入(比如“admin+123456”),跑一次程序看结果;而符号执行是“透视眼”——用符号(比如x代表输入)代替具体值,通过计算符号表达式,能“穷举”程序所有可能的执行路径。
举个生动的例子:如果代码里有if (check_password(pwd)) { 登录成功 } else { 锁定账号 },符号执行会分析“check_password(x)为真时,x需要满足什么条件(比如长度≥8、含大小写)”“为假时又是什么条件”,然后自动生成覆盖两种路径的测试用例。这种能力让它成为漏洞挖掘、形式化验证的“核心工具”,尤其适合复杂系统的测试。
2. 致命痛点:遇到“外部函数”就“断联”
但符号执行有个“死穴”——一旦程序调用“外部函数”,它就瞬间“失灵”。这里的“外部函数”包括:第三方库的工具函数(如Java的Math.sqrt()、Python的requests.get())、编程语言的原生方法(如C的printf()、Java的String.hashCode())、未插桩的私有函数。
这些函数是“黑盒”:符号执行不知道它们的内部逻辑,没法把“函数调用”转化为“符号表达式”。比如代码里有double result = Math.sqrt(input); if (result > 10) { 执行风险操作 },符号执行因为不知道Math.sqrt(x)的符号表达式,就没法分析“input满足什么条件时result>10”,导致后面的“风险操作”分支完全无法探索——相当于整个分析流程“卡壳”在外部函数这里。
3. 现有方案:要么“费力”,要么“费钱”,要么“受限”
为了解决这个问题,行业里之前有三种主流方案,但都存在明显缺陷,无法大规模落地:
- 人工写桩:工程师手动编写“模拟函数”代替外部函数。比如为
Math.sqrt()写一个桩函数,接收整数x后返回Math.sqrt(x)的近似值。但一个项目里可能有上百个外部函数,写桩需要大量时间,还容易因“模拟逻辑与真实逻辑不一致”引入新错误。 - SMT求解器驱动:用SMT(可满足性模理论)求解器自动推导外部函数的逻辑。但SMT求解器计算成本极高,遇到复杂函数(比如字符串处理、加密算法)时,可能“计算几小时都出不来结果”,根本不适合工程场景。
- NLP依赖文档:用自然语言处理技术分析函数的文档注释(如Java的Javadoc、Python的docstring),提取逻辑生成桩函数。但这种方案严重依赖“文档质量”——如果文档写得简略或错误,生成的桩就完全不可用;而且它只适用于数据结构类函数(如
List.add()),对数学计算、IO操作类函数几乎无效。
简单来说,现有方案要么“靠人”(人工写桩)、要么“靠钱”(SMT求解器)、要么“靠运气”(文档质量)——这就是AUTOSTUB要解决的核心需求:如何不依赖人工、不消耗高成本、不局限场景,自动为外部函数生成高质量的符号桩?
创新点
AUTOSTUB之所以能在众多方案中脱颖而出,核心在于三个“突破性创新”,直接解决了现有方案的痛点:
1. 技术路径创新:首次将“遗传编程”引入符号桩生成
这是AUTOSTUB最核心的创新——它没有走“人工”“SMT”“NLP”的老路,而是选择用“遗传编程(Genetic Programming, GP)”这种进化算法,让机器“自主学习”外部函数的行为。
遗传编程的本质是“模拟生物进化”:把“候选表达式”当作“生物个体”,通过“初始化种群→交叉变异→评分筛选→迭代进化”的流程,让“优秀个体(准确模拟函数行为的表达式)”存活下来,最终得到最接近真实函数的符号桩。这种方式完全摆脱了“人工干预”和“额外信息依赖”,实现了从“手动构建”到“自动进化”的跨越。
2. 精度保障创新:用“语法引导遗传编程(G3P)”避免“无效表达式”
普通遗传编程有个缺点——可能生成“语法错误”或“类型不匹配”的表达式,比如给布尔值true做乘法(true * 5)、给字符串"abc"做平方根(sqrt("abc"))。这些无效表达式会浪费大量计算资源,还会影响最终桩的质量。
AUTOSTUB引入“语法引导遗传编程(Grammar-Guided Genetic Programming, G3P)”解决了这个问题:它预先定义一套“上下文无关语法”,明确规定“哪些算子(如+、abs()、>)可以用于哪些数据类型”“表达式的结构必须符合什么规则”。在进化过程中,所有新生成的表达式都要遵守这套语法,确保“语法正确、类型匹配”——比如整数类型的输入,只能用+、-、*等整数算子,避免无效计算。
3. 适配性创新:分类型定制“适应度函数”,精准评估桩质量
不同类型的外部函数,“好桩”的评价标准不一样:数值型函数(如Math.abs())要看“误差大小”,布尔型函数(如Double.isNaN())要看“准确率”,字符串型函数(如String.length())要看“相似度”。如果用统一的标准评估所有类型,会导致“数值桩误差大但被判定为‘好桩’”“布尔桩准确率低却被保留”的问题。
AUTOSTUB针对不同输出类型,定制了专属的“适应度函数”(即“评分标准”):
- 数值型(int、double):用归一化均方根误差(NRMSE) 评估,误差越小,评分越高;
- 布尔型(boolean):用分类准确率评估,预测结果与真实结果一致的比例越高,评分越高;
- 字符串型(String):用Levenshtein距离(编辑距离) 评估,预测字符串与真实字符串的差异越小(编辑距离越小),评分越高。
这种“分类型适配”的设计,确保了每种类型的桩都能被“精准评估”,避免了“一刀切”导致的质量偏差。
研究方法和思路、实验方法
AUTOSTUB的研究方法分为“核心流程”和“实验验证”两部分,逻辑清晰、步骤明确,可复现性强。
(一)核心流程:符号桩自动生成的“四步走”
AUTOSTUB的核心目标是“输入一个外部函数,输出一个高质量的符号桩”,整个过程完全自动化,无需人工干预,具体分为四步:
步骤1:分层抽样生成“多样化随机输入”
要让桩函数“尽可能模拟真实函数行为”,首先需要收集“足够有代表性”的训练数据——而训练数据的关键是“输入”。AUTOSTUB采用“分层抽样”策略生成输入,确保覆盖函数的“常规场景”和“边缘场景”:
- 按数据类型定制生成规则:比如整数输入会覆盖“小值(1、2、-1)”“大值(230、-230)”“边界值(Integer.MAX_VALUE、Integer.MIN_VALUE)”;浮点数输入会覆盖“常规值(3.14、-2.5)”“特殊值(NaN、Infinity、0.0)”;
- 强制加入边缘值:为了覆盖“容易出bug”的场景,AUTOSTUB会让5%的输入是“特殊值”(如NaN、空字符串、最值);
- 效率保障:生成10000个输入样本,平均耗时仅13毫秒,几乎不影响整体分析效率。
步骤2:执行外部函数,收集“输入-输出对”构建训练数据
有了输入后,AUTOSTUB会调用“真实的外部函数”,将每个输入传入函数,记录对应的输出——这样就形成了“输入-输出对”(比如输入x=4,调用Math.sqrt(x)后输出2.0,形成(4, 2.0))。
这些“输入-输出对”就是训练数据,相当于给遗传编程提供了“学习样本”——遗传编程的目标就是找到一个表达式,能让“输入→表达式计算结果”尽可能接近“输入→真实函数输出”。
步骤3:G3P迭代进化,生成最优符号桩
这是AUTOSTUB的核心步骤,通过语法引导遗传编程,让“候选表达式”像生物一样进化,最终得到最优符号桩,具体分为4个小环节:
- 初始化种群:生成一批初始候选表达式(种群规模默认1000),表达式由“算子”和“输入变量”组成——算子包括40个SMT-Lib标准算子(覆盖数学运算、逻辑判断、字符串处理,如
+、abs()、>、substring()),能满足多数Java场景需求; - 交叉与变异:模拟生物繁殖过程生成新表达式:
- 交叉:随机选择两个父表达式,交换它们的“子树”(比如父表达式1是
abs(x)+1,父表达式2是x*2,交叉后可能得到abs(x)*2); - 变异:随机选择一个表达式,替换它的某个“子树”(比如把
abs(x)+1的+1替换为*3,得到abs(x)*3);
- 交叉:随机选择两个父表达式,交换它们的“子树”(比如父表达式1是
- 适应度评分:用步骤6中“分类型定制的适应度函数”,给每个候选表达式打分,筛选出评分前50%的表达式;
- 迭代优化:重复“交叉变异→评分筛选”的过程(默认迭代50代),直到得到评分最高的表达式——这个表达式就是最终的“符号桩”。
步骤4:集成到符号执行引擎,验证可用性
生成符号桩后,AUTOSTUB会将其“无缝集成”到现有符号执行引擎中(论文中选用Java符号执行工具SWAT)。当符号执行遇到对应的外部函数时,会自动调用生成的桩函数,用“桩函数的符号表达式”代替“外部函数调用”,继续完成后续的路径分析——整个集成过程无需修改引擎源码,适配性极强。
(二)实验方法:用“两个研究问题(RQ)”验证效果
为了证明AUTOSTUB的有效性,研究团队设计了两组实验,分别围绕“准确率”和“符号执行适配性”展开,实验环境为AMD Ryzen 7 7735U处理器。
1. 实验数据集构建
首先构建了两类数据集,确保实验的客观性和代表性:
| 数据集类型 | 构建方式 | 规模与筛选条件 |
|---|---|---|
| 表达式数据集 | 从Java内部库(java.util.*、java.lang.Math、java.lang.StrictMath)中筛选 | 273个目标函数(原654个,筛选条件:返回值/参数为基本类型/字符串、无副作用、输入生成不抛错) |
| 符号执行数据集 | 为每个目标函数生成测试用例 | 10个测试用例/函数(要求:生成两个不同输出的输入x1和x2,确保测试用例非“ trivial 解”) |
2. 研究问题与实验设计
| 研究问题(RQ) | 实验目标 | 实验步骤 | 评估指标 |
|---|---|---|---|
| RQ1:准确率 | 验证符号桩对外部函数的近似精度 | 1. 为每个桩函数生成10⁶个新输入-输出对; 2. 计算桩函数输出与真实函数输出的匹配率; 3. 对比“随机基线”(随机分配适应度的表达式) |
准确率(匹配率)、完全正确的桩数量 |
| RQ2:有效性 | 验证桩在符号执行中的可用性 | 1. 选取RQ1中准确率超90%的桩; 2. 集成到SWAT引擎; 3. 执行符号执行数据集的测试用例 |
求解成功率、平均求解时间、超时率 |
主要成果和贡献
1. RQ1(准确率):55%函数的桩准确率超90%,79个完全正确
实验显示,AUTOSTUB生成的符号桩在准确率上表现优异:
- 整体准确率:55%的目标函数,对应的桩准确率超过90%(即10⁶个测试样本中,90%以上的输出与真实函数一致);
- 完全正确的桩:人工验证发现,有79个函数的桩能“100%复刻真实函数行为”,这些函数可分为4类:
- 恒值返回型(28个):如
Boolean.booleanValue(boolean b),桩直接返回输入b,与真实逻辑完全一致; - 恒等关联型(8个):如
Integer.doubleValue(int i),桩生成(double)i的表达式,精准匹配类型转换逻辑; - 单算子型(28个):如
Math.abs(int x),桩直接用abs(x)表达式,完全覆盖真实函数功能; - 语义捕捉型(14个):如
Double.isNaN(double x),桩生成!(-1 < |x|)的表达式——利用Java中“NaN与任何值比较均为false”的特性,精准捕捉语言特定逻辑,比人工写桩更贴合底层语义;
- 恒值返回型(28个):如
- 对比随机基线:随机分配适应度的“随机表达式”,仅15%能达到90%以上准确率,证明AUTOSTUB的遗传编程策略远超随机尝试,能有效找到接近真实函数的表达式。
2. RQ2(有效性):集成符号执行引擎后,多数用例1秒内求解,平均耗时0.04秒
将RQ1中准确率超90%的桩集成到SWAT符号执行引擎后,实验结果进一步验证了实用性:
- 求解成功率:超90%的测试用例能在1秒超时时间内完全求解,不会因桩函数导致符号执行“卡壳”;
- 求解效率:平均求解时间仅0.04秒,最长求解时间0.41秒(硬件为AMD Ryzen 7 7735U),远低于人工桩的调试时间和SMT求解器的计算时间;
- 失败案例分析:少数求解失败的案例主要因3类问题:
- 复杂计算超时:如大整数乘法
x*y=391768351037400960,桩表达式正确但SWAT处理大数值符号计算时耗时超1秒; - 表达式局部偏差:部分桩能覆盖多数场景,但对极端值(如
Long.MAX_VALUE)的模拟有细微偏差,导致求解中断; - 语义差异:Java与SWAT依赖的Z3求解器对NaN、Infinity的处理规则不同,导致部分浮点型桩无法被Z3解析(后续可通过适配语义规则优化)。
- 复杂计算超时:如大整数乘法
3. 核心贡献:给符号执行领域带来3个“实实在在的价值”
| 贡献类型 | 具体价值 | 对比现有方案的优势 |
|---|---|---|
| 自动化降本 | 完全无需人工干预,从“输入生成→数据收集→桩生成→集成”全流程自动化,彻底告别“人工写桩”的耗时工作 | 人工写桩需1人/天处理5-10个函数,AUTOSTUB可批量处理273个函数,效率提升超20倍 |
| 效率与精度平衡 | 桩生成平均耗时短(单函数生成+评估约5分钟),且55%函数准确率超90%,兼顾“快”与“准” | SMT求解器单函数计算可能超1小时,NLP方案准确率不足40%,AUTOSTUB在效率和精度上双优 |
| 强适配性 | 支持数值、布尔、字符串3类常见类型,可无缝集成到SWAT等现有符号执行引擎,无需修改引擎源码 | 规则基方案仅支持1-2类类型,SMT方案需定制引擎接口,AUTOSTUB适配范围更广、集成成本更低 |
4. 开源资源:代码与数据集完全开放,支持复用与改进
研究团队已将AUTOSTUB的核心代码、实验数据集(273个Java函数的输入-输出对、10个测试用例/函数)开源,GitHub地址:https://github.com/UzL-ITS/AutoStub 。开发者可直接基于该代码集成到自己的符号执行工具中,也可针对“有状态函数”“复杂逻辑”等场景进行二次开发,降低符号执行技术的落地门槛。
关键问题
问题1:AUTOSTUB生成的符号桩,为什么能保证“语法正确、类型匹配”?普通遗传编程做不到吗?
答:AUTOSTUB靠“语法引导遗传编程(G3P)”实现这一点,普通遗传编程确实做不到。普通遗传编程生成表达式时没有语法约束,可能出现“给布尔值做乘法(true*5)”“给字符串算平方根(sqrt(“abc”))”这类无效表达式;而G3P会预先定义“上下文无关语法”,比如“整数类型只能用+、-、abs()等算子”“布尔类型只能用&&、||、!等算子”,生成表达式时严格遵守这套规则,从根源上保证语法正确、类型匹配,避免无效计算浪费资源。
问题2:AUTOSTUB只能处理“无状态函数”,那像StringBuilder这种有状态的类,未来有办法支持吗?研究团队提了什么思路?
答:未来有机会支持,研究团队提出了“状态转化”的思路。StringBuilder的“有状态”体现在“每次append()都会改变内部值”,AUTOSTUB目前无法捕捉这种状态变化;但可以将“状态”转化为“基本类型参数”,比如把StringBuilder的当前值通过toString()转化为字符串,作为下一次调用的输入参数(如append()的调用可拆分为“当前字符串+新增内容→新字符串”),用“输入-输出对”模拟“状态流转”,从而让AUTOSTUB生成覆盖状态变化的桩函数。不过这一思路还需进一步实验验证。
问题3:AUTOSTUB的准确率为什么能超过50%?它的“学习能力”来自哪里?
答:准确率高的核心是“两点设计”:一是“分层抽样的输入生成”,确保训练数据覆盖“常规值+边缘值”,让遗传编程能学习到函数的完整行为(比如Math.sqrt()不仅要学“正数开方”,还要学“负数开方返回NaN”);二是“分类型适配的适应度函数”,数值型用NRMSE算误差、布尔型用准确率算匹配率、字符串型用编辑距离算相似度,每个类型都有“精准的评分标准”,能让遗传编程快速筛选出“最接近真实函数的表达式”,而不是用“一刀切”的标准导致评分偏差。这两点共同赋予了AUTOSTUB强“学习能力”。
问题4:AUTOSTUB生成的桩集成到符号执行引擎后,为什么求解速度这么快(平均0.04秒)?比SMT求解器快在哪里?
答:关键在于“桩的表达式复杂度低”。AUTOSTUB生成的桩是“乔姆斯基层级的常规表达式”(比如abs(x)、!(-1<|x|)),没有循环、递归等复杂逻辑,符号执行引擎(如SWAT)处理这类表达式时,能快速转化为符号计算,几乎没有额外耗时;而SMT求解器需要“实时推导外部函数的逻辑”,遇到复杂函数时要进行大量公式运算,甚至可能陷入“无限计算”,耗时自然远高于直接使用AUTOSTUB生成的简单表达式。
问题5:如果外部函数的逻辑特别复杂(比如加密算法AES),AUTOSTUB能生成有效的桩吗?为什么?
答:目前很难生成有效桩,因为AUTOSTUB的表达式有“复杂度限制”。AES加密涉及多轮循环、字节替换、行移位等图灵完备的复杂逻辑,而AUTOSTUB生成的表达式限于“无循环、无递归的常规复杂度”(这是设计选择,为了保证符号执行的求解速度),无法模拟循环、递归等复杂行为;因此面对AES这类函数,AUTOSTUB生成的桩只能覆盖“部分简单场景”,无法完全模拟真实加密逻辑,未来需要在“表达式复杂度”和“求解速度”之间找新的平衡,才可能支持这类复杂函数。
总结
AUTOSTUB是德国吕贝克大学团队提出的“符号桩自动生成方法”,核心目标是解决符号执行中“外部函数黑盒”的痛点。它以“遗传编程(GP)+语法引导遗传编程(G3P)”为技术核心,通过“分层抽样生成输入→收集输入-输出对→G3P迭代进化表达式→集成符号执行引擎”的全自动化流程,生成能近似外部函数行为的符号桩。
实验证明,AUTOSTUB对55%的评估函数能实现超90%的近似准确率,79个函数的桩完全正确,且集成到SWAT引擎后平均求解时间仅0.04秒,能有效探索此前因外部函数无法处理的程序路径。相比人工写桩、SMT求解器等现有方案,它在“自动化程度”“效率”“适配性”上均有明显优势,为符号执行技术的工程落地提供了关键支撑。
不过AUTOSTUB仍有局限:仅支持无状态函数,无法处理循环、递归等复杂逻辑。未来可通过“状态转化”扩展有状态函数支持,通过“表达式复杂度优化”覆盖更多复杂场景,进一步提升其在实际测试中的价值。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 9
9 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)