
insert into select 结合MybaitsPlus以及自定义注解(反射), 实现 增、删、改 操作自动记流水
在日常工作中,有用到了记流水的操作。流水本质的作用就是记录数据的变动情况。一般而言流水表会多一些字段,会在原表的字段基础上新增一些字段,用于记录操作人,修改时间等等一系列信息。而流水的作用在与 增、删、改 原表的时候需要将这些操作的数据同步道流水表中。意味着有两个动作,一、操作原表。二、将原表数据同步到流水表这两个操作需要在同一个事务中。方案一、实现记流水的操作普遍有两种方式,一种是对原表和流水表
在日常工作中,有用到了记流水的操作。
流水本质的作用就是记录数据的变动情况。
一般而言流水表会多一些字段,会在原表的字段基础上新增一些字段,用于记录操作人,修改时间等等一系列信息。
而流水的作用在与 增、删、改 原表的时候需要将这些操作的数据同步道流水表中。
意味着有两个动作,一、操作原表。二、将原表数据同步到流水表
这两个操作需要在同一个事务中。
方案一、
实现记流水的操作普遍有两种方式,一种是对原表和流水表都写一套mapper、service、entity,然后当对原表操作时,使用BeanUtils等工具将数据拷贝到流水表的实体中,并且补上多的字段。
方案二、
使用insert into ..... select 原表的语句进行数据同步。
从个人喜好来说,比较喜欢 方案二,因为简单,而且不用只为了记一个流水而特意去写一套代码,冗余不说,开发效率也低。即使有代码生成器,也依然需要额外的做一些属性拷贝等操作。
为了更好的解决这个记流水问题,结合MybatisPlus的SQL注入器
MybatisPlus–SQL注入器进行自定义注入sql和方法
官方文档:https://mp.baomidou.com/guide/sql-injector.html
利用方案二,动态的形成一条sql。
通过观察,流水表比原表多了一些字段,这些字段显然是需要我们自己补上去的,流水表多了n个字段,那么insert into 流水表(原表字段...,新增字段 ) select 原表字段,待填数据 where 原表主键=主键id值
假设流水表多了3个字段,那么代填字段我们就需要补上3个值,而原表主键id在增、删、改的时候是知道主键id的。
细心的小伙伴会发现一些有用信息
一、原表的字段我们可以知道,因为实体的字段名称对应这数据库的表字段。而mybatis/mybatisPlus也是这么做的。
①于是原表字段 以及 括号里面 与原表相同的字段我们就有了。
②而括号里面是流水表的字段,会多几个字段,待填字段则是我们通过传参传来的
③主键id在增、删、改原表的操作中是可以得到的。
二、结合MybatisPlus提供的SQL注入器,我们可以得到这些字段信息,想要了解可以看上面的文章
继续挖掘,这里面因为每一张表的流水表新增的字段可能不同
举一个案例
下面是一张学生表
CREATE TABLE `student` (
`id` int(11) NOT NULL,
`name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`age` int(11) NOT NULL,
INDEX `idx_id_name_age`(`id`, `name`, `age`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
假设下面这张表是流水表,多了两个字段用于记录操作者、操作时间
CREATE TABLE `studentcopy` (
`id` int(11) NOT NULL,
`name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`age` int(11) NOT NULL,
`operator` VARCHAR(20),
`modidate` datetime,
INDEX `idx_id_name_age`(`id`, `name`, `age`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
原表如下
在执行前,看下表数据
student表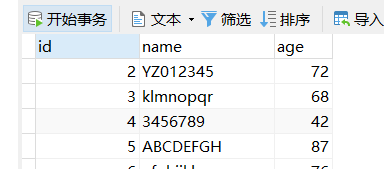
studentcopy表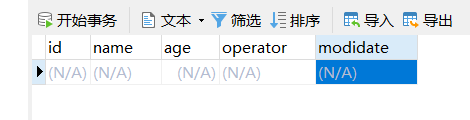
使用insert into select 插入数据,如下
INSERT INTO studentcopy (`id`, NAME,age, operator, modidate )
SELECT id,NAME,age,'张三',now() FROM student
WHERE id = 2
执行完后就会发现copy表就会将原表的数据插入进来
基于这个特点,根据这条sql的构造,以及mybaitsPlus自带的sql注入器,我们可以构造这条sql
原表的字段可以通过MybatisPlus的TableInfo得到。
通过TableInfo我们还可以得到主键的字段名称
于是下面这条sql就差(新增字段,待填)insert into 流水表(原表字段...,新增字段 ) select 原表字段,待填数据 where 原表主键字段名称=传来的主键id值
于是我想了一个办法
而在我们开发过程中sql会是这样的
insert into studentcopy(id,name,age,operator,modidate)
select id,name,age,#{operator},#{modidate}
from student where id=#{id}
其中#{}中的值是我们传进去的常量值
于是我想了一个办法,将新增字段operator、modidate 提取出来,以及对应的值在程序运行的过程中传进去
于是就有了这样的想法
@Select("insert into studentcopy(id,name,age,operator,modidate) " +
"select id,name,age,#{operator},#{modidate} " +
"from student where id=#{id}")
void asyncStudent(int operator,String modidate,int id);
//或者
void asyncStudent(Object obj);
// 但又考虑到要适用其他表,采用了JSONObject对象作为这里的对象
// 于是对于上面的方法就变成
void asyncStudent(JSONObject jsonObject);
// 如下只需要JSONObject jsonObject = new JSONObject();
jsonObject.put("operator",传来的值);
jsonObject.put("modidate",传来的值);
jsonObject.put("id",传来主键值);
为了进一步的解耦,想要让它适用更多的表
于是我将上面那条insert into select语句中的待填字段提取出来也就是,#{operator},#{modidate}
提取出来的名称刚好是我们JSONObject对象的key,而value则是我们传过来的参数值
结合java的多参数语法 …
如下,可以传多个参数
void a(String ...args)
而我们只需要
// 取出#{operator},#{modidate}得到一个数组key
for(int i=0;i<args.length;i++){
jsonObject.put(key[i],args[i])
}
于是乎我们就构造好了这个对象
再补上这个主键id
// 下面的主键值通过操作原表时(增、删、改)是可以得到的jsonObject.put("id",主键值)
为了提取这里的内容
可以通过自定义注解来实现抽取这一部分的内容。
例如
因为这里的修改时间可以调用mysql系统函数,故直接使用now()即可
@Project(appendColumn = "operator,modidate", appendVarName = " #{operator}, now()")
于是大体的设计方案就有了
如下
套一层BaseMapper,将方法insertJouyById放入,原先Mapper层的都改继承这个HcBaseMapper,每一个mapper在spring容器启动的过程中会被扫描,例如后面的StudentMapper,这些Mapper会被SQL注入器进行处理
,先得到"insert into studentcopy(id,name,age,operator,modidate) select id,name,age,#{operator},now() from student where id=#{id}"
然后经过SqlSource进行预编译。然后进行方法绑定,将其绑定到下面的HcBaseMapper中的insertJourById方法
/**
* @author jinhua
* @date 2021/6/25 14:36
* 通用Mapper,用于标识自定义的Mapper
*/
public interface HcBaseMapper<T> extends BaseMapper<T> {
/**
* ById必须传入主键
* 插入流水操作,需要将主表的主键id传入
* 为了解耦传入JSONObject对象因此通过JSONObject对象将对应的参数构造好后传入
*/
void insertJourById(JSONObject jsonObject);
}
@Project(appendColumn = "operator,modidate",appendVarName = "#{operator},now()")
public interface StudentMapper extends HcBaseMapper<Student> {
}
重点看下injectMappedStatement方法,目的是对于实现了HcBaseMapper类的mapper将编译后的sql与方法进行绑定
public class InsertJourByProjectAnnotationMethod extends AbstractMethod {
@Override
public MappedStatement injectMappedStatement(Class<?> mapperClass, Class<?> modelClass, TableInfo tableInfo) {
KeyGenerator keyGenerator = new NoKeyGenerator();
SqlMethod sqlMethod = SqlMethod.INSERT_ONE;
String columnScript = SqlScriptUtils.convertTrim(tableInfo.getAllInsertSqlColumnMaybeIf(),
LEFT_BRACKET, RIGHT_BRACKET, null, COMMA);
String valuesScript = SqlScriptUtils.convertTrim(tableInfo.getAllInsertSqlPropertyMaybeIf(null),
LEFT_BRACKET, RIGHT_BRACKET, null, COMMA);
String keyProperty = null;
String keyColumn = null;
// 表包含主键处理逻辑,如果不包含主键当普通字段处理
if (StringUtils.hasText(tableInfo.getKeyProperty())) {
if (tableInfo.getIdType() == IdType.AUTO) {
/** 自增主键 */
keyGenerator = new Jdbc3KeyGenerator();
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
} else {
if (null != tableInfo.getKeySequence()) {
keyGenerator = TableInfoHelper.genKeyGenerator(tableInfo, builderAssistant, sqlMethod.getMethod(), languageDriver);
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();
}
}
}
String insertSelectSql;
// 判断是否实现了HcBaseMapper类
if (instanceOfHcBaseMapper(mapperClass)) {
// 绑定该实现了HcBaseMapper类的方法
String methodName = "insertJourById";
// 如果是自定义,也就是
ProjectEnums projectEnum = getProjectEnum(mapperClass);
if (projectEnum != null) {
// 1、得到预编译的sql
if (projectEnum == ProjectEnums.NO_DEFINE) {
// 字段和变量名
List<String> columnAndVarName = JourUtils.getColumnVarNameByProject(mapperClass);
if (columnAndVarName != null) {
insertSelectSql = getByIdSQLScript(columnAndVarName.get(0), columnAndVarName.get(1), tableInfo);
} else {
throw new NullPointerException("请补全@Project注解信息,appendColumn 与 appendVarName都不允许为空");
}
} else {
List<String> columnVarName = ProjectEnums.COLUMN_VAR_NAME_MAP.get(projectEnum);
insertSelectSql = getByIdSQLScript(columnVarName.get(0), columnVarName.get(1), tableInfo);
}
System.out.println("编译前的sql:");
System.out.println(insertSelectSql);
// 2、进行预编译得到sqlSource对象
SqlSource sqlSource = languageDriver.createSqlSource(configuration, insertSelectSql, modelClass);
// 3、将Statement交给Mybatis管理
return addInsertMappedStatement(mapperClass, modelClass, methodName, sqlSource, keyGenerator, keyProperty, keyColumn);
}
}
// 原生的BaseMapper
String sql = String.format(sqlMethod.getSql(), tableInfo.getTableName(), columnScript, valuesScript);
SqlSource sqlSource = languageDriver.createSqlSource(configuration, sql, modelClass);
return this.addInsertMappedStatement(mapperClass, modelClass, sqlMethod.getMethod(), sqlSource, keyGenerator, keyProperty, keyColumn);
}
/**
* 获得项目枚举值
*/
private int getProjectEnumValue(Class<?> mapperClass) {
ProjectEnums projectEnum = getProjectEnum(mapperClass);
if (projectEnum != null) {
return projectEnum.getValue();
}
return 0;
}
/**
* 获取枚举类型
*/
private ProjectEnums getProjectEnum(Class<?> mapperClass) {
Project annotation = mapperClass.getDeclaredAnnotation(Project.class);
if (annotation != null) {
return annotation.projectEnum();
}
return null;
}
/**
* 拼接完整的预编译sql,后面进行编译
* 返回的预编译sql最后一个值一定是主键,为了方便统一用 id
*/
private String getByIdSQLScript(String appendColumn, String appendValue, TableInfo tableInfo) {
// 原表的表名称
String tableName = tableInfo.getTableName();
String allColumn = getAllColumn(tableInfo);
return "insert into " + tableName + "jour("
// appendColumn 追加字段
+ allColumn + "," + appendColumn + ") select "
// appendValue 追加字段对应的值,使用#{}包裹,或者写成常量,会被SqlSource编译
+ allColumn + "," + appendValue +
" from " + tableName + " where " + tableInfo.getKeyColumn() + "=#{id}";
}
/**
* 得到表格所有字段
*/
private String getAllColumn(TableInfo tableInfo) {
// 放入主键
StringBuilder stringBuilder = new StringBuilder(tableInfo.getKeyColumn());
for (TableFieldInfo tableFieldInfo : tableInfo.getFieldList()) {
stringBuilder.append(("," + tableFieldInfo.getColumn()));
}
return stringBuilder.toString();
}
/**
* 判断继承链上是否有HcBaseMapper
*/
private boolean instanceOfHcBaseMapper(Class<?> mapperClass) {
Class<?>[] interfaces = mapperClass.getInterfaces();
for (Class<?> aClass : interfaces) {
if (aClass == HcBaseMapper.class) {
return true;
}
}
return false;
}
}
下面的组件才是真正意义上的功能绑定,将其添加到MybatisPlus的方法列表中,交给容器管理
@Component
public class SqlInjectorByInsertJour extends DefaultSqlInjector {
@Override
public List<AbstractMethod> getMethodList(Class<?> mapperClass) {
List<AbstractMethod> methodList = super.getMethodList(mapperClass);//将原来的保持
// 添加插入流水的方法
methodList.add(new InsertJourByProjectAnnotationMethod());//将自定义的方法传入,这里用的是上面创建对象
return methodList;
}
}
最后这个功能我们就算实现了,当然这里面还是有一些反射操作需要自行学习啦。
进一步优化
结合renren网开源的代码生成器,可以直接生成一套自带流水的api,经过自己捣鼓
用Vue+ElementUI组件重写了前端界面,重写了模板
于是乎就有了
进一步思考
在开发的过程中,发现有些时候并不会知道主键信息,也就意味着有些时候并不是根据主键来确定信息的
笔者认为,一张表除了本身的自增主键外,有些时候需要唯一索引来额外确定一条记录。
也就是在MybatisPlus社区中曾经被提到的问题:复合主键 在原生的MybatisPlus中没有复合组件的设计
笔者认为,有些时候的确是需要复合组件的支持,因为在业务的开发过程中我的确也是遇到了这种情况。
数据库中有数据,也有主键,但是查询的时候不能根据自增主键查,只能根据其他字段进行查询。
这时候就遇到了一个问题,查到的结果可能会有多条(插入的时候也意味着多条,更新也意味着可能会被更新多条数据,除非给了自增主键id);
于是笔者就自己再加了一个注解用于使用唯一索引(复合主键的情形)
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface UniqueIdx {
}
于是乎就有了后续的优化。对于上面的逻辑
我是将主键id写死的#{id},结合复合主键,后面的where条件可以不需要主键id,也可以通过唯一索引进行操作。
后续优化中。有兴趣的话可以关注我,进行后续的更新
下一篇文章推荐:excel-import-export 导入导出框架的进一步演变

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 1
1 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)