
生成式语音增强模型SEGAN及代码实现
存在问题:目前的语音增强技术都是在频谱域上操作和/或利用一些更高层次的特征。它们中的大多数只能处理有限数量的噪声条件,并依赖于一阶统计量。为了规避这些问题,人们越来越多地使用深度网络,由于它们具有从大量数据中学习复杂函数的能力。本研究中,我们提出使用生成对抗网络进行语音增强。本文方法:与目前的技术相比,我们是在波形级别操作,端到端训练模型,并将28个说话人和40种不同的噪声条件纳入同一模型,以便在
SEGAN(Speech Enhancement Generative Adversarial Network)
这是一篇发表在2017InterSpeech会议上的文章,目前引用量为1086次,说明还是语音增强领域比较经典的一篇文章。
内容阅读
摘要:
存在问题:目前的语音增强技术都是在频谱域上操作和/或利用一些更高层次的特征。它们中的大多数只能处理有限数量的噪声条件,并依赖于一阶统计量。为了规避这些问题,人们越来越多地使用深度网络,由于它们具有从大量数据中学习复杂函数的能力。本研究中,我们提出使用生成对抗网络进行语音增强。
本文方法:与目前的技术相比,我们是在波形级别操作,端到端训练模型,并将28个说话人和40种不同的噪声条件纳入同一模型,以便在它们之间共享模型参数。我们使用一个独立的、不可见的测试集来评估所提出的模型,该测试集有两个说话人和20个可选的噪声条件。
结果:增强后的样本证实了本模型的可行性,客观和主观评价均证实了模型的有效性。在此,我们开启了对语音增强生成架构的探索,这可能会逐步纳入进一步以语音为中心的设计选择,以提高其性能。
引言
语音增强旨在提高受加性噪声污染的语音的可懂度和质量。它的主要应用与提高噪声环境下的移动通信质量有关。然而,我们也发现了与助听器和人工耳蜗相关的重要应用,在放大之前增强信号可以显著减少不适并提高可懂度。语音增强也被成功地应用于语音识别和说话人识别系统的预处理阶段[3,4,5]。
经典的语音增强方法有谱减法[6]、维纳滤波[7]、基于统计模型的方法[8]和子空间算法[9,10]。自20世纪80年代以来,神经网络也被应用于语音增强[11,12]。近年来,降噪自编码器结构[13]得到了广泛的应用。然而,循环神经网络(rnn)也被使用。例如,循环去噪自编码器利用嵌入信号中的时间上下文信息显示出显著的性能。最近的方法将长短期记忆网络应用于去噪任务[4,14]。在[15]和[16]中,噪声特征被估计并包含在深度神经网络的输入特征中。也证明了使用dropout、后滤波和感知激励指标的有效性。
目前大多数系统都是基于短时傅立叶分析/合成框架[1]。它们只改变频谱幅度,因为短时相位对语音增强并不重要。然而,进一步的研究表明,语音质量的显著改善是可能的,特别是当一个干净的相位谱是已知的。1988年,Tamura等人提出了一种直接处理原始音频波形的深度网络,但他们使用了前馈层,在依赖于说话者和孤立词的数据库上逐帧(60个样本)工作。
深度学习生成建模领域的最新突破是生成对抗网络(GANs)[19]。Gan在计算机视觉领域已经取得了很好的成功,可以生成逼真的图像,并很好地推广到像素级的复杂(高维)分布[20,21,22]。就我们所知,Gan尚未应用于任何语音生成或增强任务,因此这是第一个使用对抗框架生成语音信号的方法。
所提出的语音增强GAN(SEGAN)的主要优点是:
- 它提供了一个快速的增强过程。不需要因果关系,因此,不像Rnn中那样存在递归操作。
- 它是在原始音频上进行端到端操作。因此,没有提取手工特征,也没有对原始数据进行明确的假设。
- 它从不同的说话人和噪声类型中学习,并将它们合并共享参数。这使得系统在这些维度上变得简单和一般化。
方法
对于损失函数,
在语音增强任务中,x表示干净语音clean,z表示来自任意随机分布的数据。
普通GAN: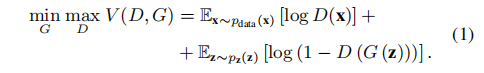
条件GAN:
为了使最终增强的语音中,能够包含输入noisy语音的信息,我们将noisy语音作为附加条件Xc,添加到GAN的损失函数中。在G和D中加入一些额外信息。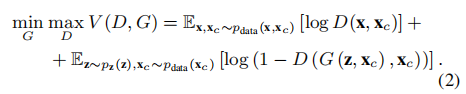
也就是利用随机数据z和noisy语音Xc,一起生成目标语音。
WassersteinGAN:
普通的GAN的损失函数 类似于交叉熵损失,训练时收敛困难,易梯度消失,因此提出了WassersteinGAN。
从原来的取log换成计算欧式距离。最小二乘GAN (LSGAN)代替交叉熵损失。
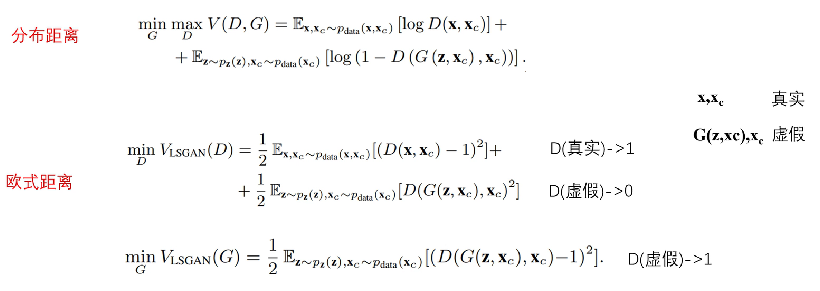
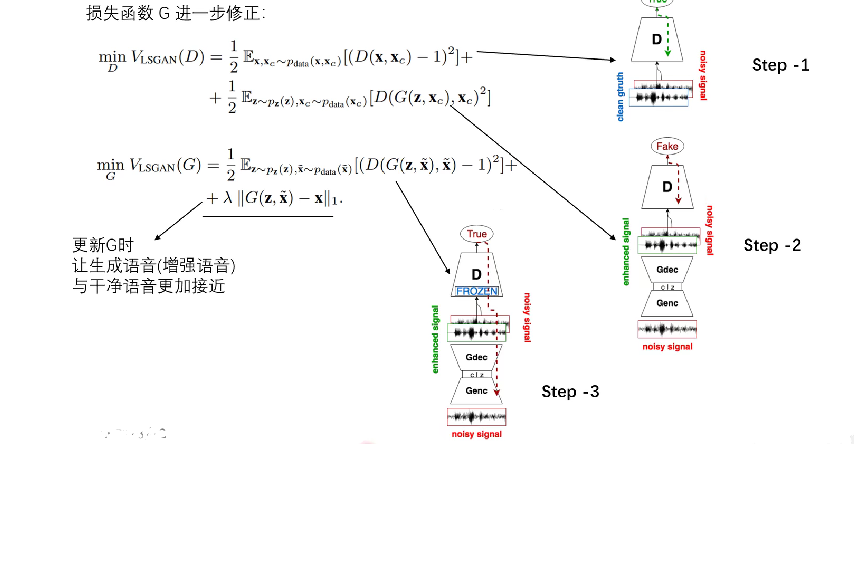
损失函式G进行进一步的修正:
多加入了后面一项,前面一项保证输出的语音分布与干净语音越相似越好,后面加的一项是为了保证输出的语音的内容与干净语音越接近越好。
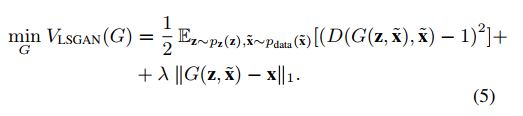
在初步的实验中,我们发现在G的损失中加入二次分量是很方便的,这样可以最小化G的生成样本与干净样本之间的距离。为了测量这个距离,我们选择了L1范数,因为它已经被证明在图像处理领域是有效的[20,26]。通过这种方式,我们让对抗损失添加更细粒度和更真实的结果。L1范数的幅度由一个新的超参数λ控制。
整个过程分为三步:
Step1: 实现minD的第一部分。输入clean和noisy语音到D,用真实数据训D,对D进行一次更新。
Step2: 实现minD的第二部分。将nosiy语音输入G,得到生成的enhance语音,把noisy和enhance的语音拼到一起,再送入D,用生成的“假”数据训D。
Step3: 实现G的训练。将D的参数冻结,更新G的参数。
SEGAN结构:
生成器G:
采用Encoder + Decoder结构。
pytorch一维CNN的输入[B,C,D]即[BatchSize, Channel, Dimension]
G由22个一维跨步卷积层组成,滤波器宽度为31,步长为N = 2。每层滤波器的数量增加,使得深度随着宽度(信号在时间上的持续时间)变窄而变大。每层的结果维度,作为它的样本特征映射,是16384×1、8192×16、4096×32、2048×32、1024×64、512×64、256×128、128×128、64×256、32×256、16×512和8×1024。
抽取完成,直到我们得到一个浓缩的表示,称为thoufgt向量c,它与潜在向量z连接。z是从正态分布N(0;I)采样得到的,和c的大小一样。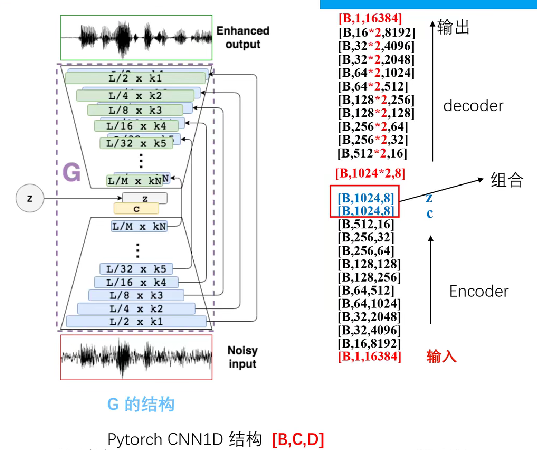
如前所述,G的解码器级是编码器的镜像,具有相同的滤波器宽度和每层相同数量的滤波器。解码阶段通过分步转置卷积(有时称为反卷积)进行反转。
G网络还具有跳跃式连接,将每个编码层连接到相应的解码层,并绕过了模型中间执行的压缩过程。这样做是因为模型的输入和输出共享相同的底层结构,即自然语音的底层结构。因此,如果我们强迫所有信息通过压缩瓶颈,可能会丢失许多低级细节来正确地重建语音波形。跳过连接直接将波形的细粒度信息传递到解码阶段(例如,相位,对齐)。此外,它们提供了更好的训练行为,因为梯度可以在整个结构中更深地流动[24]。
跳跃连接和潜在向量的添加使得每层的特征映射数量增加一倍。
判别器D: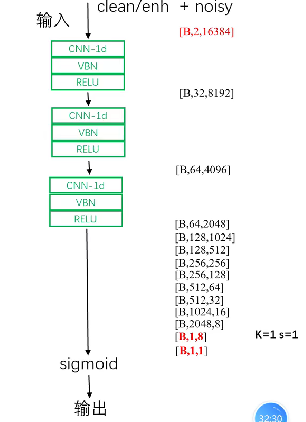
网络D遵循与G编码器级相同的一维卷积结构,符合卷积分类网络的传统拓扑结构。不同之处在于:(1)它得到16384个样本的两个输入通道,(2)它在LeakyReLU非线性之前使用虚拟批范数[31],α = 0:3,(3)在最后一个激活层中有一个一维卷积层,其中一个宽度为1的滤波器不会对隐藏的激活进行下采样(11卷积)。后者(3)减少了最终分类神经元所需的参数数量,该神经元与所有具有线性行为的隐藏激活完全连接。这意味着我们将全连接组件中所需参数的数量从8×1024 = 8192减少到8,并且在卷积的参数中可以学习1024通道合并的方式。
网络训练好后,只要取出G,就可以用来语音增强了。
实验设置
1.数据集:
数据集是从Voice Bank语料库[28]中选择的30个说话人:28个为训练集,2个为测试集。为了制作噪声训练集,我们总共考虑了40种不同的条件[27]:10种噪声(2种人为噪声,8种来自需求数据库[29]),每种噪声有4种信噪比(SNR)(15、10、5和0 dB)。每个训练说话人在每种情况下大约有10个不同的句子。为了制作测试集,总共考虑了20种不同的条件[27]:5种噪声(均来自需求数据库),每种噪声的信噪比为4(17.5,12.5,7.5和2.5 dB)。每个测试者在每种情况下都有大约20个不同的句子。测试集是完全不可见的(不同于)训练集,使用不同的说话人和噪声条件。

用于本实验的VoiceBank中的一部分数据下载:VoiceBank语料库
2.SEGAN设置
该模型训练了86个epoch, RMSprop为[30],学习率为0.0002,有效批大小为400。我们将训练样例分成两对(图3):实对,由噪声信号和干净信号(~ x和x)组成,假对,由噪声信号和增强信号(~x和^x)组成。为了使数据集文件充分满足波形生成的目的,我们将原始语音从48kHz降采样到16kHz。在训练过程中,我们以每500 ms(50%重叠)大约1秒的语音(16384个样本)滑动窗口提取波形块。在测试过程中,我们基本上在整个测试过程中滑动没有重叠的窗口,并将结果连接到流的末尾。在训练和测试中,我们对所有输入样本应用系数0.95的高频预加重操作(在测试期间,输出相应地去掉强调)。
——————————————————————————————————————————————————
注: 这里为什么是16384个样本?
窗口长度是 “approximately one second”,约1s的信号,这里假设窗口长度为 1.024 秒(通常为了方便计算,时间窗口常常选择为 2 的幂次倍数的采样点数)。采样点数=16000Hz×1.024s=16384samples。即2的14次方。
——————————————————————————————————————————————————
关于L1正则化的λ权值的设置,经过一些实验,我们将整个训练λ都设置为100。我们最初将其设置为1,但观察到G损失比对抗损失低两个数量级,因此L1对学习没有实际影响。一旦我们将其设置为100,我们就会看到L1中的最小化行为和对抗行为中的平衡行为。随着L1的降低,输出样本的质量增加,我们假设这有助于G在逼真生成方面更有效。
代码实现
代码地址
tensorflow实现版本:https://github.com/santi-pdp/segan
pytorch实现版本:https://github.com/leftthomas/SEGAN
下面以pytorch实现版本为例。
工程文件组成: (6个py文件,3个文件夹)
data_geneation.py :训练数据的准备与生成
dataset.py :构造dataloder(神经网络训练时的数据加载器)
hparams.py : 模型相关参数
model.py: 网络描述
train.py: 训练与模型保存
eval.py: 测试
save:训练模型保存文件夹
eval:测试结果保存文件夹
scp:保存训练数据描述文件的文件夹
——————————————————————
要对数据进行降采样为16KHz。
首先看data_geneation.py
import numpy as np
import librosa
import os
#语音分段,以帧长16384点,帧移8192进行每段切分
def wav_split(wav,win_length,strid):
slices = []
if len(wav)> win_length:
for idx_end in range(win_length, len(wav), strid):
idx_start = idx_end - win_length
slice_wav = wav[idx_start:idx_end]
slices.append(slice_wav)
# 拼接最后一帧,最后一帧不一定帧移strid长度
slices.append(wav[-win_length:])
return slices
# 分段语音保存
def save_slices(slices,name):
name_list = []
if len(slices) >0:
for i , slice_wav in enumerate(slices):
name_slice = name+"_"+str(i)+'.npy'
np.save(name_slice,slice_wav)
name_list.append(name_slice)
return name_list
if __name__ == "__main__":
clean_wav_path = "/data/clean_trainset_wav"
noisy_wav_path = "/data/noisy_trainset_wav/"
catch_train_clean = '/data/ctach_segan/clean'
catch_train_noisy = '/data/ctach_segan/noisy'
os.makedirs(catch_train_clean,exist_ok=True)
os.makedirs(catch_train_noisy,exist_ok=True)
win_length = 16384
strid = int(win_length/2)
# 遍历所有wav文件
with open("scp/train_segan.scp",'wt') as f:
for root, dirs, files in os.walk(clean_wav_path):
for file in files:
file_clean_name = os.path.join(root,file)
name = os.path.split(file_clean_name)[-1]
if name.endswith("wav"):
file_noisy_name = os.path.join(noisy_wav_path,name)
print("processing file %s"%(file_clean_name))
if not os.path.exists(file_noisy_name):
print("can not find file %s"%(file_noisy_name))
continue
clean_data,sr = librosa.load(file_clean_name,sr=16000,mono=True)
noisy_data,sr = librosa.load(file_noisy_name,sr=16000,mono=True)
if not len(clean_data) == len(noisy_data):
print("file length are not equal")
continue
# 干净语音分段+保存
clean_slices = wav_split(clean_data,win_length,strid)
clean_namelist = save_slices(clean_slices,os.path.join(catch_train_clean,name))
# 噪声语音分段+保存
noisy_slices = wav_split(noisy_data,win_length,strid)
noisy_namelist = save_slices(noisy_slices,os.path.join(catch_train_noisy,name))
for clean_catch_name,noisy_catch_name in zip(clean_namelist,noisy_namelist):
f.write("%s %s\n"%(clean_catch_name,noisy_catch_name))

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 23
23 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)