
【LangChain】(四)如何使用LangChain构建强大的RAG问答应用:从入门到精通!
我们将深入探讨如何使用LangChain开发一个简单的RAG问答应用。我们将逐步介绍典型的问答架构,讨论相关的LangChain组件,并展示如何跟踪和理解我们的应用。
如何高效地获取和处理信息成为了一个重要的课题。AI大模型虽然能够处理广泛主题的文本生成,但其知识却仅限于训练时使用的公开数据。为了构建能够利用私有数据或实时数据进行推理的AI应用,我们需要用特定的信息来增强模型的知识。这就是检索增强生成(Retrieval Augmented Generation,RAG)技术的魅力所在!✨
在本文中,我们将深入探讨如何使用LangChain开发一个简单的RAG问答应用。我们将逐步介绍典型的问答架构,讨论相关的LangChain组件,并展示如何跟踪和理解我们的应用。无论你是AI领域的新手还是经验丰富的开发者,这篇文章都将为你提供宝贵的见解和实用的教程。
RAG的基本概念
RAG是一种结合了检索和生成的技术,它可以让大模型在生成文本时利用额外的数据源,从而提高生成的质量和准确性。RAG的基本流程如下:
- 用户输入:用户提出一个问题或话题,作为输入。
- 信息检索:RAG从一个数据源中检索出与用户输入相关的文本片段,这些片段称为上下文(context)。上下文可以来自网页、文档或数据库记录。
- 拼接输入:RAG将用户的输入和检索到的上下文拼接成一个完整的输入,传递给一个大模型,例如GPT。
- 生成输出:大模型处理拼接后的输入,生成相应的输出,RAG从中提取或格式化所需的信息,最终返回给用户。
这种方法的优势在于,它不仅依赖于模型的训练数据,还能实时利用外部信息,从而提高回答的准确性和相关性。
LangChain与RAG的结合
LangChain是一个专注于大模型应用开发的平台,它提供了一系列的组件和工具,帮助你轻松地构建RAG应用。以下是LangChain提供的关键组件: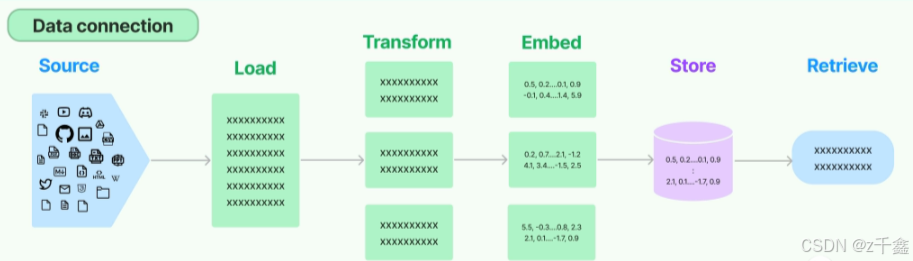
1. 数据加载器(DocumentLoader)
数据加载器负责从数据源加载数据并将其转换为文档对象。文档对象包含两个主要属性:
- page_content:文档的文本内容。
- metadata:文档的元数据,例如标题、作者、日期等。
数据加载器的选择取决于数据源的类型,例如网页、数据库或文件系统。
2. 文本分割器(DocumentSplitter)
文本分割器用于将文档对象分割成多个较小的文档对象。这是为了方便后续的检索和生成,因为大模型的输入窗口是有限的,较短的文本更容易找到相关的信息。常见的分割策略包括按段落、句子或特定字符进行分割。
3. 文本嵌入器(Embeddings)
文本嵌入器将文本转换为高维向量(embedding),这些向量用于衡量文本之间的相似度。通过计算文本的嵌入向量,可以实现高效的相似度检索。
4. 向量存储器(VectorStore)
向量存储器用于存储和查询嵌入。它通常使用一些索引技术(如Faiss或Annoy)来加速嵌入的检索。向量存储器能够快速找到与用户查询最相似的文档。
5. 检索器(Retriever)
检索器根据用户的文本查询返回相关的文档对象。向量存储器检索器(VectorStoreRetriever)是常见的实现,它利用向量存储器的相似度搜索功能来实现高效检索。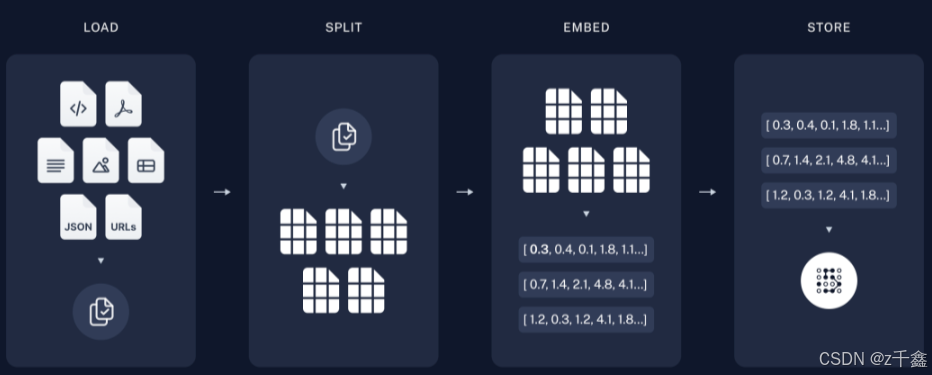
6. 聊天模型(ChatModel)
聊天模型根据输入序列生成输出消息。它通常基于大模型(如GPT-3)来实现文本生成的功能。聊天模型的选择会影响生成的质量和响应速度。
使用LangChain构建RAG应用的一般流程
构建RAG应用的流程可以分为以下几个步骤:
- 加载数据:使用数据加载器从指定的数据源加载数据。
- 分割文档:使用文本分割器将加载的文档对象分割成较小的文档对象,以便于后续的检索。
- 生成嵌入:将分割后的文档对象转换为嵌入,并存储到向量存储器中。
- 创建检索器:根据用户输入创建检索器,以便根据查询检索相关的文档对象。
- 生成输出:使用聊天模型生成输出消息,将用户输入与检索到的文档对象结合,生成最终的回答。
示例代码
以下是一个使用LangChain构建RAG应用的示例代码:
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.retrievers import VectorStoreRetriever
from langchain.chat_models import OpenAIChatModel
# 加载数据
loader = WebBaseLoader("https://example.com")
documents = loader.load()
# 分割文档
splitter = RecursiveCharacterTextSplitter()
split_docs = splitter.split_documents(documents)
# 生成嵌入
embeddings = OpenAIEmbeddings()
vector_store = Chroma.from_documents(split_docs, embeddings)
# 创建检索器
retriever = VectorStoreRetriever(vector_store=vector_store, embeddings=embeddings)
# 创建聊天模型
chat_model = OpenAIChatModel()
# 处理用户输入
user_input = "请告诉我关于AI的最新研究进展。"
context = retriever.retrieve(user_input)
response = chat_model.generate(user_input + context)
print(response)
LangChain与RAG的优势和应用场景
优势
- 灵活性:根据需求和数据源选择不同的组件和参数,定制RAG应用。
- 可扩展性:使用LangChain的云服务和分布式计算功能,轻松部署和运行RAG应用。
- 可视化:使用LangSmith可视化RAG应用的工作流程,调试和优化应用。
应用场景
- 专业问答:构建医疗、法律或金融领域的问答应用,帮助用户获取专业信息。
- 文本摘要:生成新闻摘要或论文摘要,帮助用户快速获取信息。
- 文本生成:生成诗歌、故事等创意文本,激发灵感。
【无限GPT4.omini】
【拒绝爬梯】
【上百种AI工作流落地场景】
【主流大模型集聚地:GPT-4o-Mini、GPT-3.5 Turbo、GPT-4 Turbo、GPT-4o、GPT-o1、Claude-3.5-Sonnet、Gemini Pro、月之暗面、文心一言 4.0、通易千问 Plus等众多模型】
🔥传送门:https://www.nyai.chat/chat?invite=nyai_1141439&fromChannel=csdn

结论
在本文中,我们详细介绍了如何使用LangChain开发一个简单的RAG问答应用,深入探讨了RAG的基本概念和优势,讨论了相关的LangChain组件。希望本文能够帮助你了解LangChain和RAG结合的潜力和价值。

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 13
13 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)