
LangChain RAG 系统实战(Qwen3 Embedding&Reranker)
LangChain 框架,并结合了业界领先的 Qwen3 Embedding 和 Reranker 模型,构建了一个功能完善、性能RAG优异的知识库问答系统
一、技术背景
近年来,大语言模型(LLM)如 GPT 系列、Qwen系列、DeepSeek 系列等在自然语言处理领域取得了革命性的突破。然而,它们并非完美无缺。LLM 存在一些固有的挑战,例如:
-
知识幻觉:在回答其知识库范围外或不确定的问题时,模型可能会“一本正经地胡说八道”,编造看似合理但完全错误的信息。
-
知识截断:模型的知识是静态的,通常截止到其训练数据的最后日期,无法获取最新的信息。
-
数据隐私与专业性:对于企业或个人而言,如何让模型根据私有的、专业的领域知识进行回答,是一个巨大的挑战。
为了解决这些问题,**检索增强生成(Retrieval-Augmented Generation, RAG)**技术应运而生。RAG 的核心思想是,不完全依赖模型自身的内部知识,而是在回答问题前,先从一个外部知识库(如文档、数据库等)中检索出相关的上下文信息,然后将这些信息连同问题一起提供给大模型,让其“参考”这些资料来生成答案。
随着阿里巴巴通义千问(Qwen)团队等优秀贡献者开源了系列高性能模型,构建一个专业、高效的 RAG 系统变得前所未有的容易。本文将详细介绍如何使用强大的 LangChain 框架,结合 Qwen3 Embedding 和 Qwen3 Reranker 模型,从零开始构建一个能够准确、可靠地回答中国古典小说相关问题的 RAG 应用。
二、技术介绍
2.1 LangChain介绍
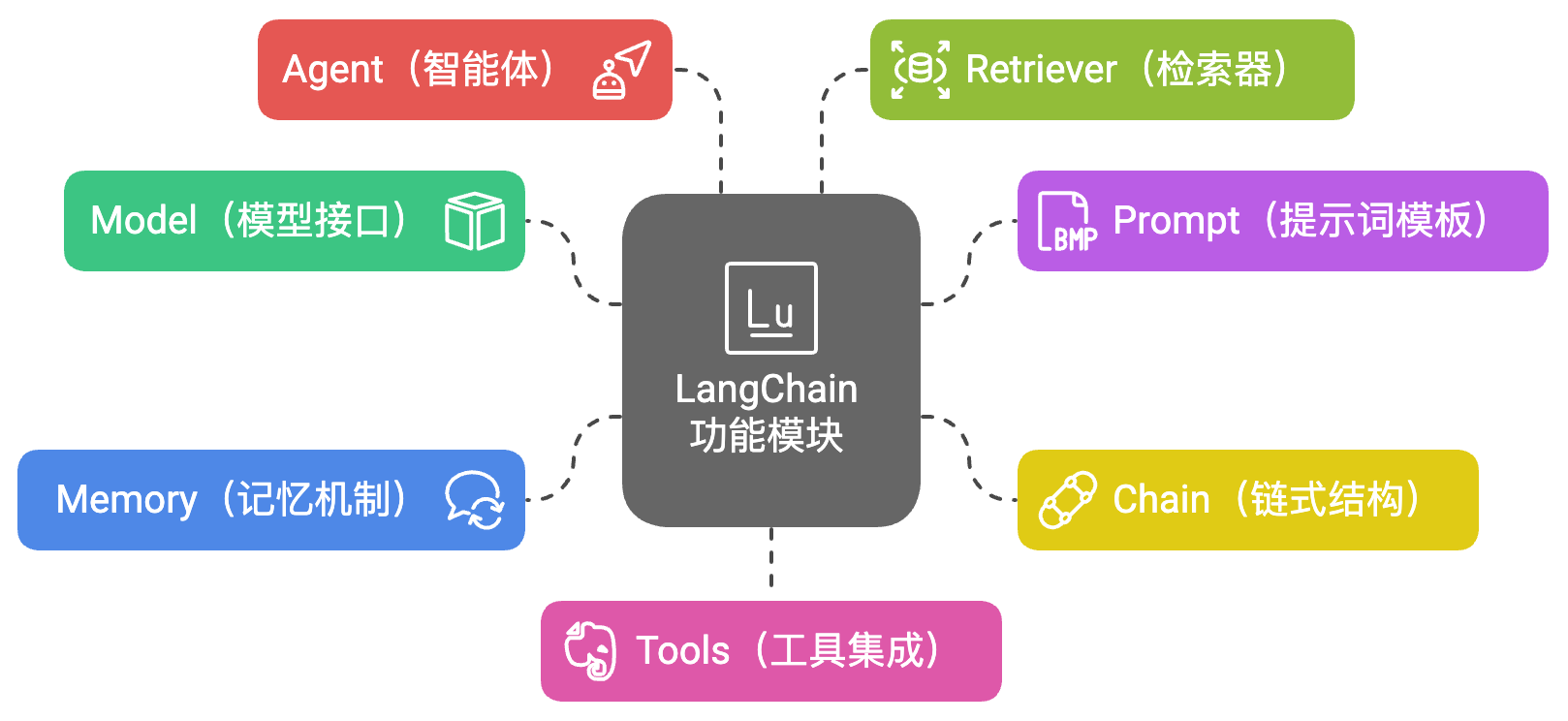
LangChain 是一个用于构建基于大语言模型(LLM,Large Language Models)应用程序的开源框架。它极大地简化了开发者集成和扩展 LLM 的过程,支持将语言模型与各种数据源、工具以及外部系统相结合,打造强大的智能应用,比如智能问答、聊天机器人、自动文档摘要、智能搜索等。
LangChain 的核心思想是:“链式思维”(Chain of Thought)和“链式组件”。即把复杂的 LLM 应用拆分成一个个可复用的模块,然后通过“链”串联起来,形成完整的流程。
2.2 RAG 介绍
RAG 是“Retrieval-Augmented Generation”的缩写,中文常译为检索增强生成。 它是一种结合了信息检索(IR)和生成式模型(如大语言模型 LLM)的人工智能技术框架,主要目的是让大模型不仅仅依靠训练时获得的知识,还能“实时”利用外部知识库、文档或数据库,提升回答的准确性和实时性。
-
索引(Indexing):将私有知识库(如我们的四大名著
.txt文件)进行加载、分块(Chunking),然后使用 Embedding 模型 将每个文本块转换为向量(Vector),并存入向量数据库(如 FAISS)。 -
检索(Retrieval):当用户提问时,同样使用 Embedding 模型将问题转换为向量。
-
召回(Recall):在向量数据库中,用问题的向量去搜索最相似的
k个文本块向量。这个阶段也被称为“粗召回”。 -
精排(Re-ranking):为了提高上下文的“信噪比”,可以使用一个 Reranker 模型 召回的
k个文本块进行重新排序,筛选出与问题最相关的n个(n < k)文本块。 -
生成(Generation):将经过精排的
n个文本块作为上下文,连同原始问题一起,通过一个精心设计的提示(Prompt),交给大语言模型(LLM),生成最终的、有理有据的答案。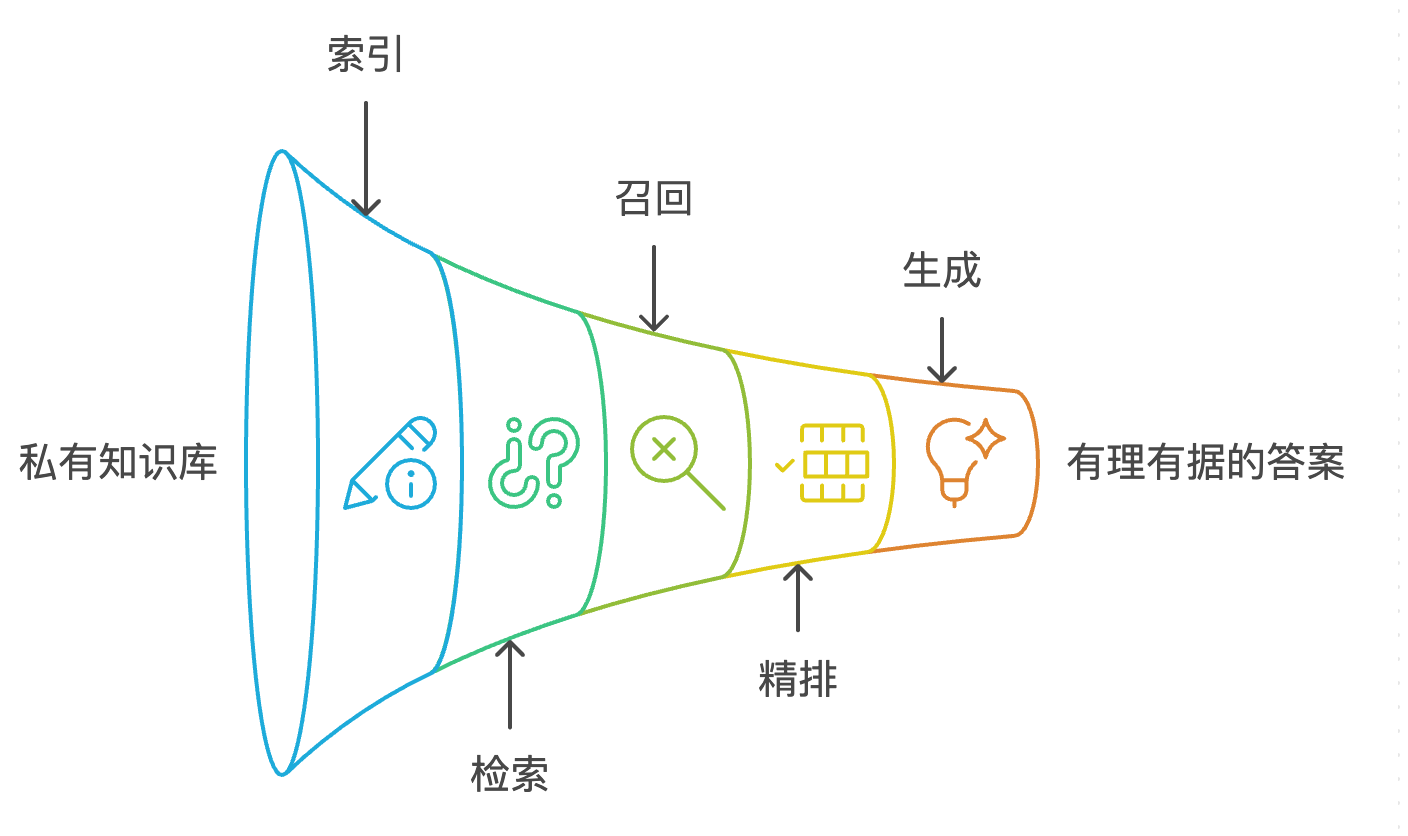
2.3 Qwen3 Embedding 介绍
Qwen/Qwen3-Embedding-4B 是由阿里巴巴通义千问团队开源的高性能文本向量化模型。Embedding 模型的核心作用是将任何文本(单词、句子、段落)映射到一个高维的数学向量空间中。在这个空间里,语义相近的文本其向量也更接近。Qwen3-Embedding-4B 在 MTEB (Massive Text Embedding Benchmark) 等权威评测中名列前茅,是构建 RAG 系统“粗召回”阶段的理想选择。
2.4 Qwen3 Reranker 介绍
Qwen/Qwen3-Reranker-4B 是一个专门用于精排的判别式模型。与 Embedding 模型不同,它不旨在将文本转换为独立的向量,而是直接对一个“问题-文档”对(Query-Document Pair)进行打分,判断该文档与问题的相关性。在我们的 RAG 系统中,它扮演了“优中选优”的关键角色,能够从 Embedding 模型初步筛选的候选中,进一步过滤掉不相关或相关性较弱的文本,将最精华的上下文交给 LLM。
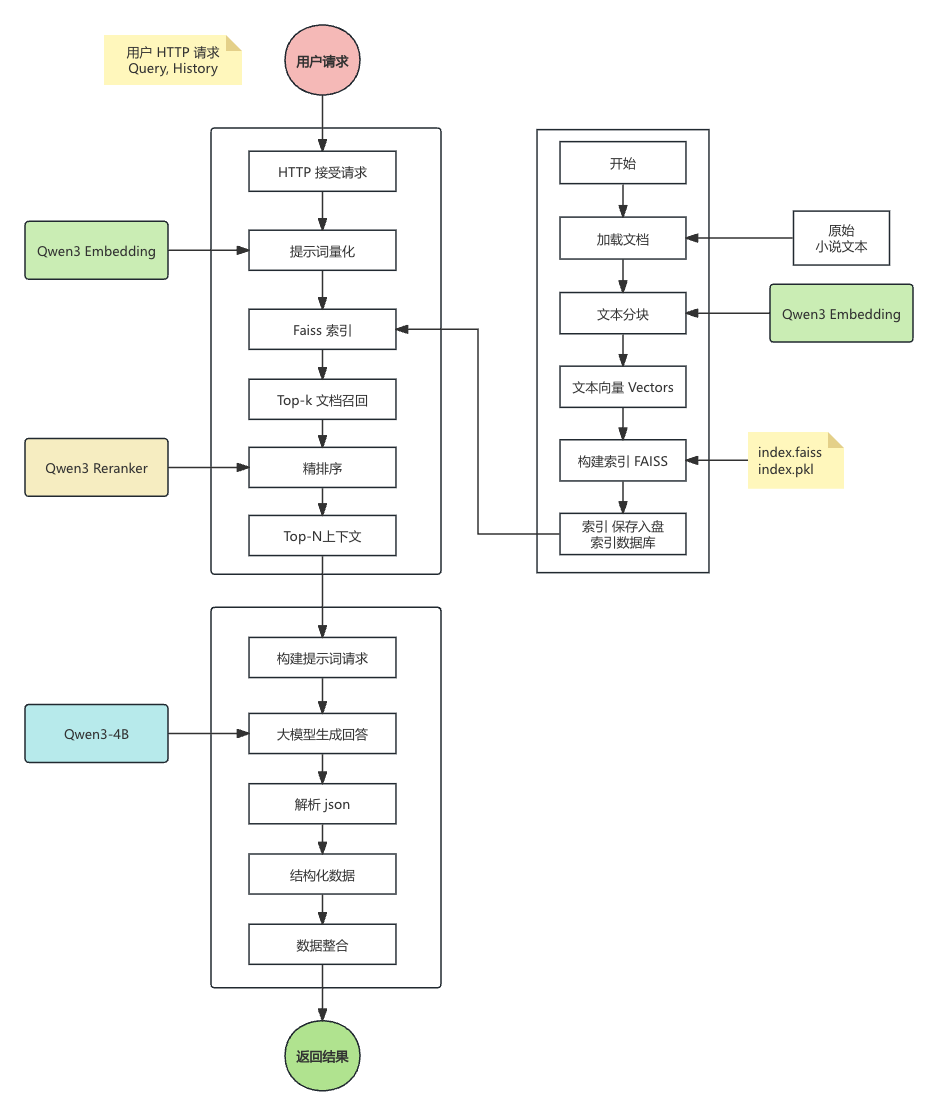
三、RAG 系统实战
3.1 基础环境准备 / 代码工程
参考代码: https://github.com/497429018/langchain-demo.git
langchain
langchain-core
langchain-community
langchain-text-splitters
fastapi
uvicorn[standard]
pydantic
gradio
requests
transformers
torch
sentencepiece
accelerate
faiss-cpupip install -r requirements_lc.txt3.2 构建索引知识库
将小说文本索引化
python -m scripts_lc.build_knowledge_base_lc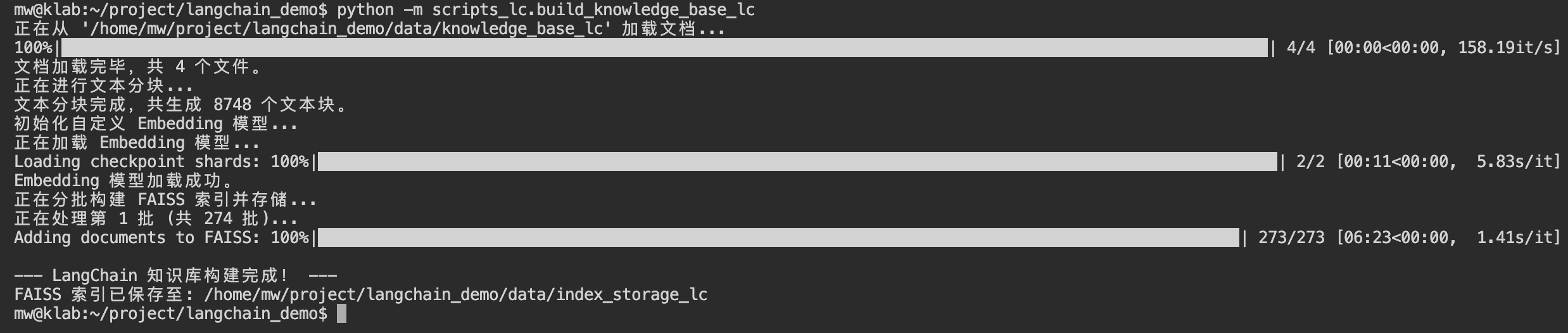
3.3 构建推理模型服务
nohup bash -c '
uvicorn scripts_lc.app_lc:app --host 0.0.0.0 --port 8000
' > logs/app_lc.log 2>&1 &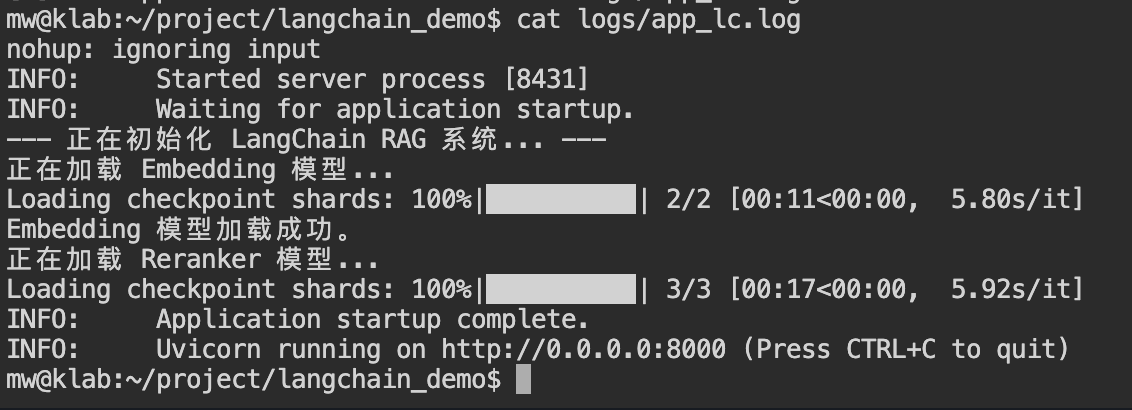
3.4 简单测试
curl -X 'POST' \
'http://127.0.0.1:8000/chat' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query": "孙悟空的师父是谁?",
"history": []
}' | jq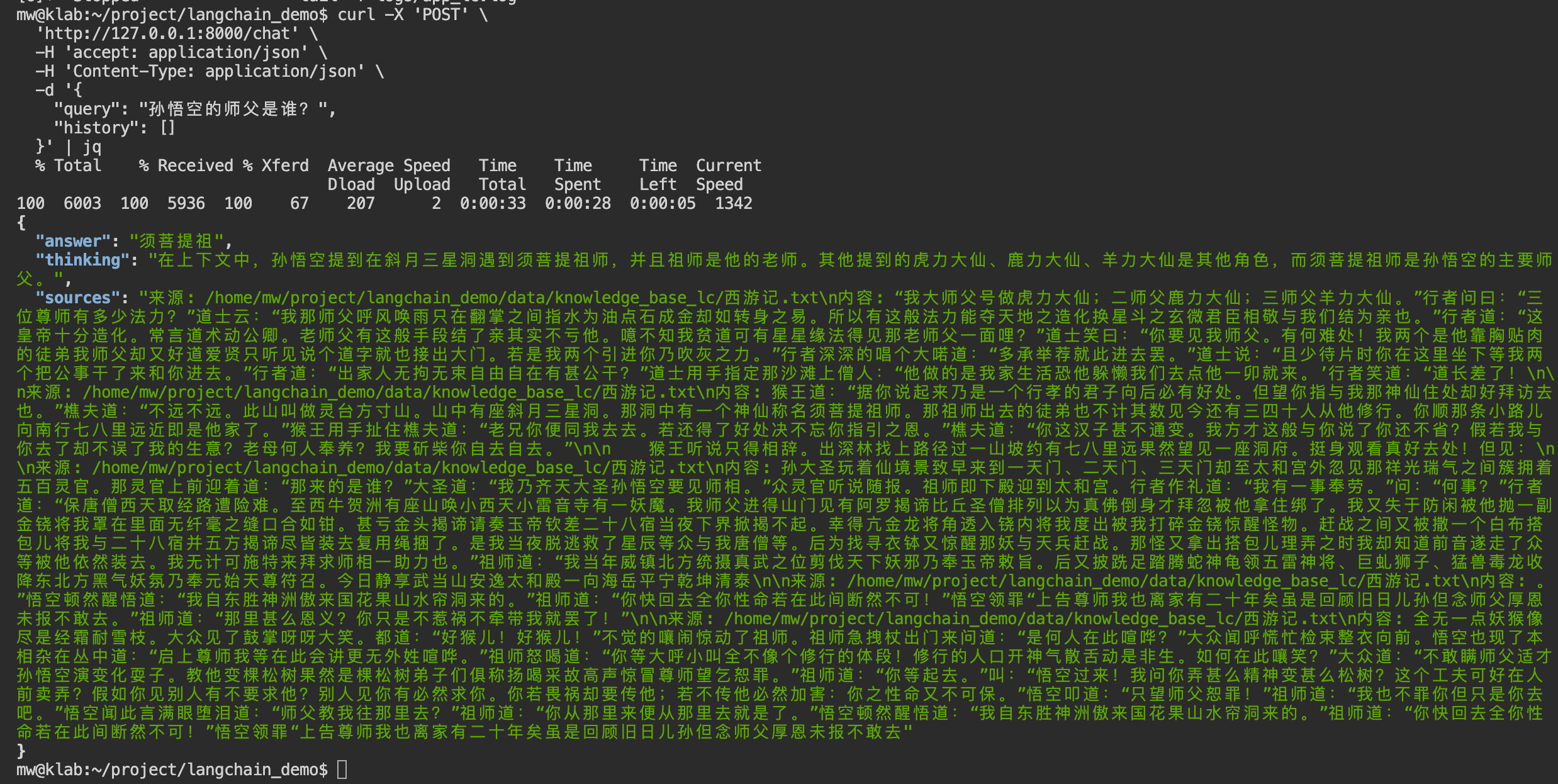
curl -X 'POST' \
'http://127.0.0.1:8000/chat' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query": "刘备、关羽、张飞在何处结义?",
"history": []
}' | jq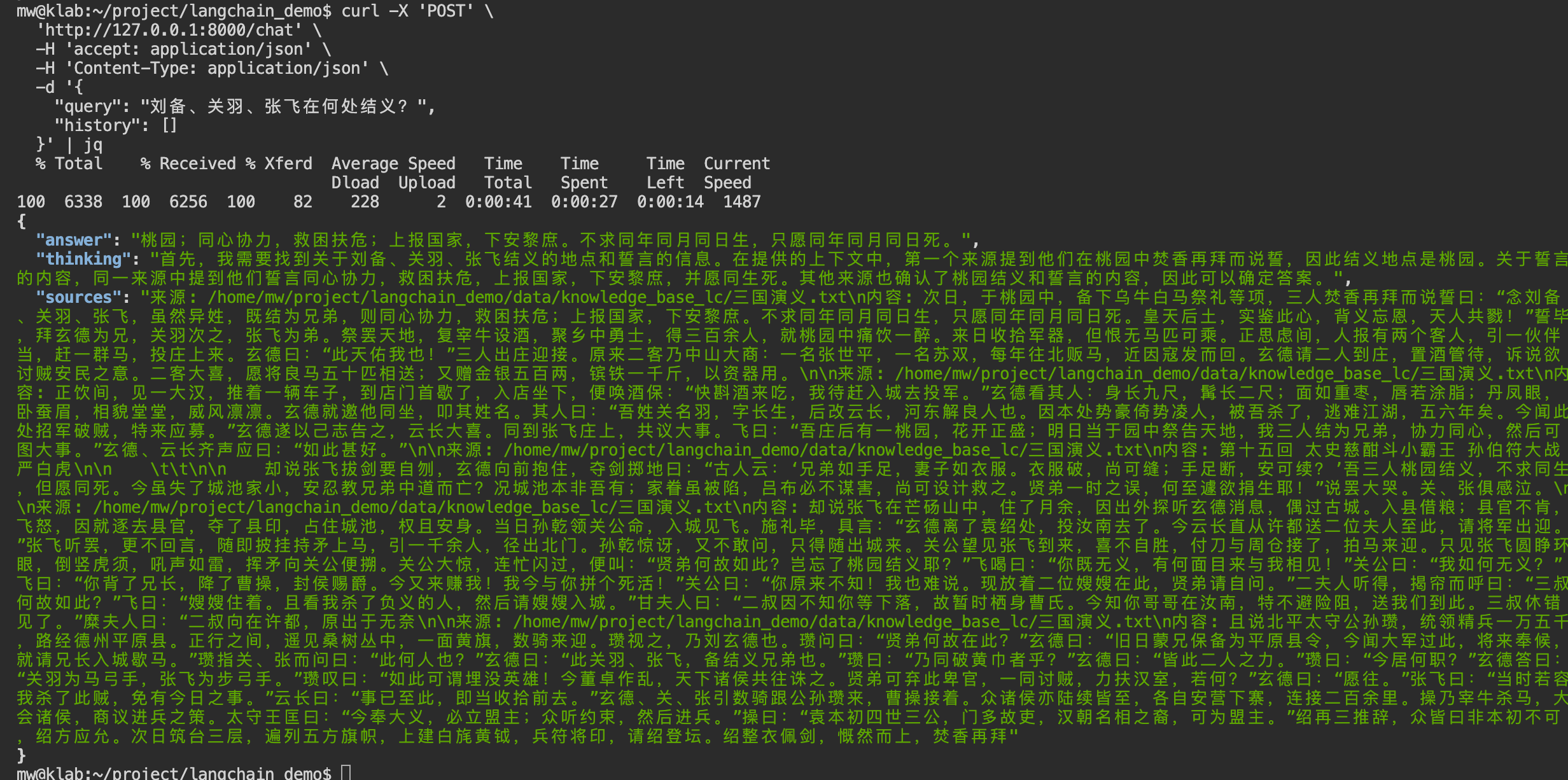
curl -X 'POST' \
'http://127.0.0.1:8000/chat' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query": "武松在景阳冈打死了什么?",
"history": []
}' | jq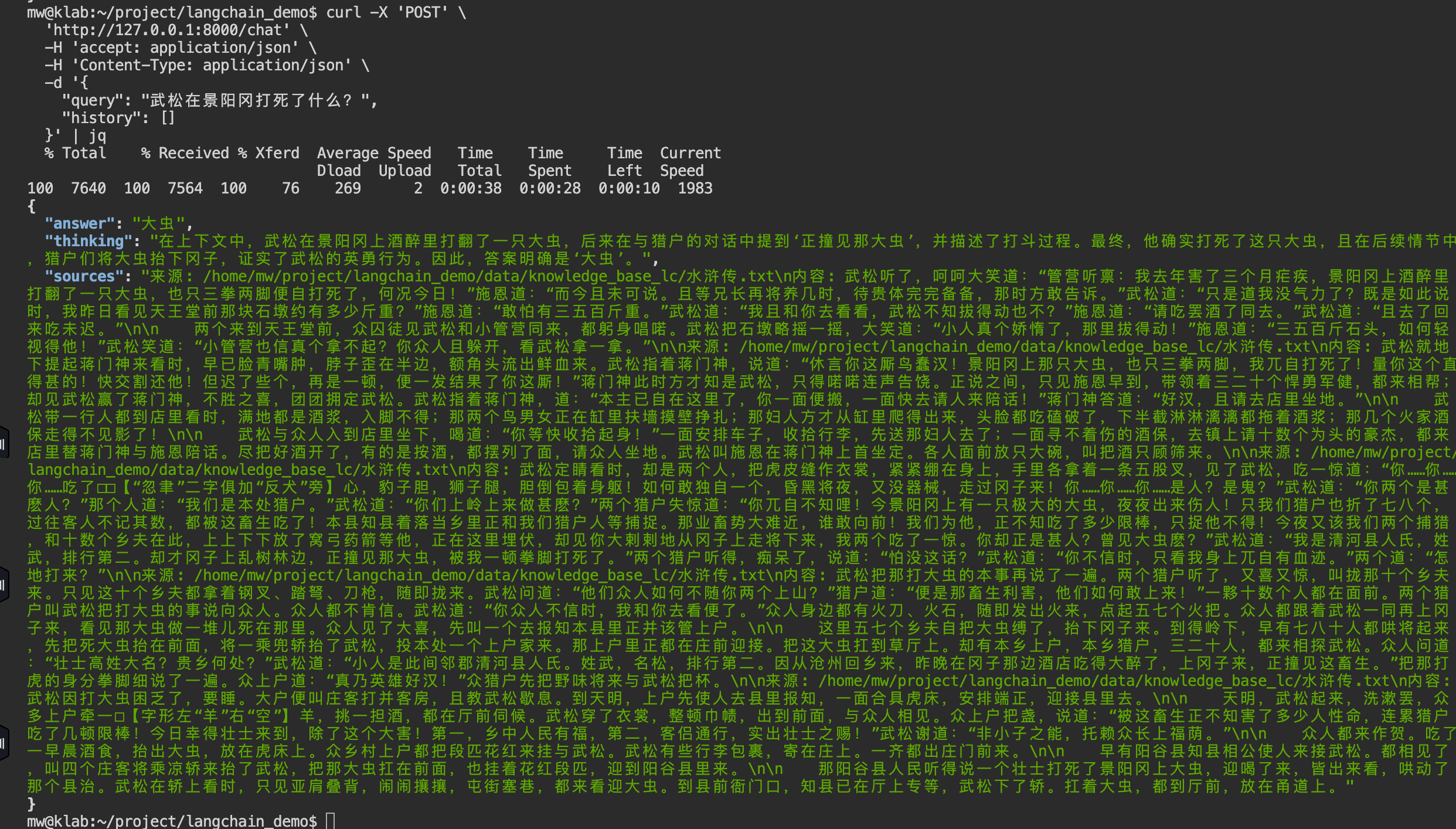
curl -X 'POST' \
'http://127.0.0.1:8000/chat' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query": "林黛玉的性格怎么样?",
"history": []
}' | jq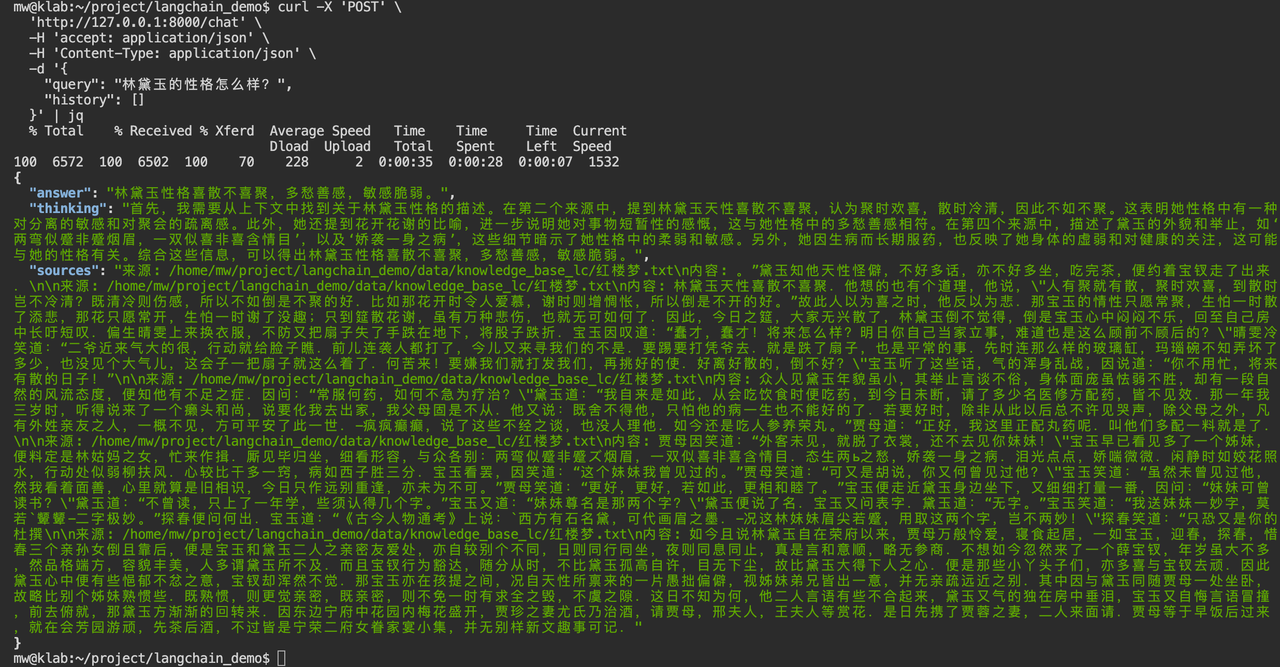
四、小结
通过本次实战,我们成功使用 LangChain 框架,并结合了业界领先的 Qwen3 Embedding 和 Reranker 模型,构建了一个功能完善、性能优异的知识库问答系统。
我们实现的核心架构是 “粗召回(Embedding)+ 精排序(Reranker)+ 结构化生成(LLM with JSON Parser)”,这套组合拳有效地解决了大模型幻觉问题,使得系统能够基于我们提供的私有知识(四大名著)给出精准、可靠且可验证的回答。
参考
Introduction | 🦜️🔗 LangChainLangChain is a framework for developing applications powered by large language models (LLMs).![]() https://python.langchain.com/docs/introduction/https://huggingface.co/Qwen/Qwen3-Embedding-4B
https://python.langchain.com/docs/introduction/https://huggingface.co/Qwen/Qwen3-Embedding-4B![]() https://huggingface.co/Qwen/Qwen3-Embedding-4Bhttps://huggingface.co/Qwen/Qwen3-Reranker-4B
https://huggingface.co/Qwen/Qwen3-Embedding-4Bhttps://huggingface.co/Qwen/Qwen3-Reranker-4B![]() https://huggingface.co/Qwen/Qwen3-Reranker-4B
https://huggingface.co/Qwen/Qwen3-Reranker-4B

技术共进,成长同行——讯飞AI开发者社区
更多推荐


 26
26 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)