
ChatGLM警情识别实战(七)
数据质量决定模型质量?
·
最新小结
关于项目已经进展到识别银行卡号阶段,第一次尝试的时候还是像之前一样,在答案上添加银行卡对应的四流抽取,然后还是对应的prompt,加大了训练的数据(6k条),推理数据依旧剔除null数据,第一炉子就在美好周末的开始跟着烧起来了,以下是第一炉结果
从数据上来看,添加了银行卡识别后,打分相对比单纯识别人和身份证下降一点点,不过还在可接受范围内,于是开心的开始了一些测试,随之而来的就是新的问题出现。
测试的好几条银行卡识别都不够准确,要么有遗漏;要么有的将身份证识别混乱,但是打分表现很不错,那肯定是数据出现了问题。
检查数据发现大量的数据并没有银行卡,筛选存在银行卡的条数只有843条(总条数8400+),也就是仅有10%的数据称之为“高质量数据”,大部分数据要么空,要么只有金额。
相当于训练时,模型学习到的90%的数据都是null,面对新的数据时便有可能会直接认为是null或者识别遗漏。
针对这个问题我把高质量数据拿出来训练在里面添加了大概200条“非全”数据(可能全空,可能银行卡空,可能身份证空),整个训练数据仅有1k条,验证集也仅有800条,改小模型步长(3000变成300),加大数据集的输入大小(512,高质量数据往往会比较长包含大量的数据),以及验证集大小(256,同理),新一炉在4小时就跑完了,显存占用为8g左右
结果可以看到虽然数据减少,但是高质量数据带来了更好的结果,之后也会大量的测试。
番外
查资料的时候发现一个有趣的tip
如果穷逼的电脑太垃圾怎么学编程?
我在github测试了一下
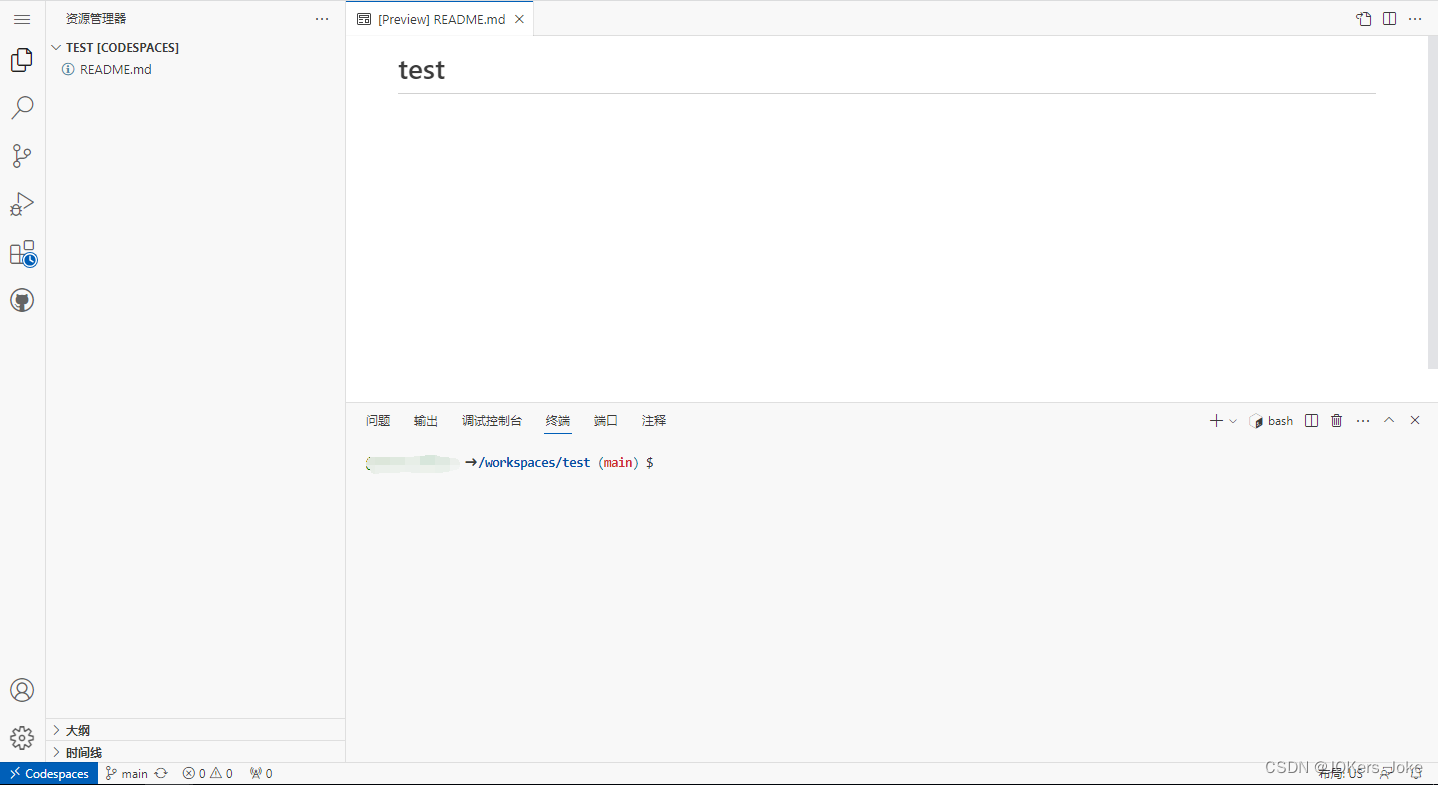
真不错!

技术共进,成长同行——讯飞AI开发者社区
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)